ARM嵌入式Linux系统开发(完整版).pdf
1.GNU make
GNU make 最初是Unix 系统下的一个工具,设计之初是为了维护C 程序文件不必要的
重新编译,它是一个自动生成和维护目标程序的工具。在使用GNU的编译工具进行开发时,
经常要用到GNU make工具。使用make工具,我们可以将大型的开发项目分解成为多个更
易于管理的模块,对于一个包括几百个源文件的应用程序,使用make 和Makefile 工具就可
以高效的处理各个源文件之间复杂的相互关系,进而取代了复杂的命令行操作,也大大提高
了应用程序的开发效率,可以想到的是如果一个工程具有上百个源文件时,但是采用命令行
逐个编译那将是多么大的工作量。
使用make工具管理具有多个源文件的工程,其优势是显而易见的,举一个简单的例子,
如果多个源文件中的某个文件被修改,而有其他多个源文件依赖该文件,采用手工编译的方
法需要对所有与该文件有关的源文件进行重新编译,这显然是一件费时费力的事情,而如果
采用make工具则可以避免这种繁杂的重复编译工作,大大地提高了工作效率。
make 是一个解释Makefile 文件中指令的命令工具,其最基本的功能就是通过Makefile
文件来描述源程序之间的相互关系并自动维护编译工作,它会告知系统以何种方式编译和链
接程序。一旦正确完成Makefile 文件,剩下的工作就只是在Linux 终端下输入make 这样的
一个命令,就可以自动完成所有编译任务,并且生成目标程序。通常状况之下GNU make的
工作流程如下。
① 查找当前目录下的Makefile文件
② 初始化文件中的变量
③ 分析Makefile中的所有规则
④ 为所有的目标文件创建依赖关系
⑤ 根据依赖关系,决定哪些目标文件要重新生成
⑥ 执行生成命令
为了比较形象地说明make 工具的工作原理,举一个简单的例子来介绍。假定一个项目
中有以下一些文件。
· 源程序:Main.c、test1.c、test.c。
· 包含的头文件:head1.h、head2.h、head3.h。
· 由源程序和头文件编译生成的目标文件:
Main.o、test1.o、test2.o。
· 由目标文件链接生成的可执行文件:test。
这些不同组成部分的相互依赖关系如图3.9
所示。
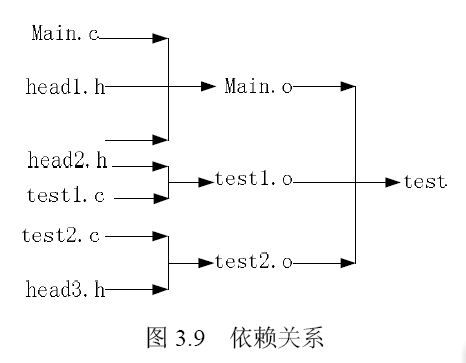
在该项目的所有文件当中,目标文件Main.o的依
赖文件是Main.c、head1.h、head2.h;test1.o的依赖文
件是head2.h、test1.c;目标文件test2.o的依赖文件是head3.h、test2.c;最终的可执行文件的
依赖文件是Main.o、test1.o和test2.o。执行make命令时,会首先处理test程序的所有依赖文
件(.o 文件)的更新规则,对于.o 文件,会检查每个依赖程序(.c 和.h 文件)是否有更新,
判断有无更新的依据主要看依赖文件的建立时间是否比所生成的目标文件要晚,如果是,那
么会按规则重新编译生成相应的目标文件,接下来对于最终的可执行程序,同样会检查其依
赖文件(.o 文件)是否有更新,如果有任何一个目标文件要比最终可执行的目标程序新,则
重新链接生成新的可执行程序,所以,make工具管理项目的过程是从最底层开始的,是一个
逆序遍历的过程。从以上的说明就能够比较容易理解使用make 工具的优势了,事实上,任
何一个源文件的改变都会导致重新编译、链接生成可执行程序,使用者不必关心哪个程序改
变、或者依赖哪个文件,make工具会自动完成程序的重新编译和链接工作。
执行make 命令时,只需在Makefile 文件所在目录输入make 指令即可,事实上,make
命本身可带有这样的一些参数:【选项】、【宏定义】、【目标文件】。其标准形式如下。
Make [选项] [宏定义] [目标文件]
Make命令的一些常用选项及其含义如下。
· -f file:指定Makefile的文件名。
· -n:打印出所有执行命令,但事实上并不执行这些命令。
· -s:在执行时不打印命令名。
· -w:如果在make执行时要改变目录,则打印当前的执行目录。
· -d:打印调试信息。
· -I
· -h:help文档,显示Makefile的help信息。
举例来讲,在使用make 工具的时候,习惯把makefile 文件命名为Makefile,当然也可
以采用其他的名字来命名makefile 文件,如果要使用其他文件作为Makefile,则可利用带-f
选项的make命令来指定Makefile文件。
举例来讲,在使用make 工具的时候,习惯把makefile 文件命名为Makefile,当然也可
以采用其他的名字来命名makefile 文件,如果要使用其他文件作为Makefile,则可利用带-f
选项的make命令来指定Makefile文件。
# make –f Makefilename
参数【目标文件】对于make命令来说也是一个可选项,如果在执行make命令时带有该
参数,可以输入如下的命令。
# make target
target 是用户Makefile 文件中定义的目标文件之一,如果省略参数target,make 就将生
成Makefile文件中定义的第一个目标文件。因此,常见的用法就是经常把用户最终想要的目
标文件(可执行程序)放在Makefile文件中首要的位置,这样用户直接执行make命令即可。
2.Makefile规则语法
简单地讲,Makefile 的作用就是让编译器知道要编译一个文件需要依赖哪些文件,同时
当那些依赖文件有了改变,编译器会自动的发现最终的生成文件已经过时,而重新编译相应
的模块。Makefile 的内容规定了整个工程的编译规则。一个工程中的许多源文件按其类型、
功能、模块可能分别被放在不同的目录中,Makefile 定义了一系列的规则来指定,比如哪些
文件是有依赖性的,哪些文件需要先编译,哪些文件需要后编译,哪些文件需要重新编译。
Makefile有其自身特定的编写格式并且遵循一定的语法规则。
#注释
目标文件:依赖文件列表
...............
...............
格式的说明如下。
· 注释:和Shell脚本一样,Makefile语句行的注释采用“#”符号。
· 目标:目标文件的列表,通常指程序编译过程中生成的目标文件(.o文件)或最终的
可执行程序,有时也可以是要执行的动作,如“clean”这样的目标。
· 依赖文件:目标文件所依赖的文件,一个目标文件可以依赖一个或多个文件。
· “:”符号,分隔符,介于目标文件和依赖文件之间。
· 命令列表:make 程序执行的动作,也是创建目标文件的命令,一个规则可以有多条
命令,每一行只能有一条命令。
每一个命令行必须以[Tab]键开始,[Tab]告诉make程序该行是一个命令行,make按照命令完成
相应的动作。
从上面的分析可以看出,Makefile 文件的规则其实主要有两个方面,一个是说明文件之
间的依赖关系,另一个是告诉make 工具如何生成目标文件的命令。下面是一个简单的
makefile文件例子。
#Makefile Example
test:main.o test1.o test2.o
gcc –o test main.o test1.o test2.o
main.o:main.c head1.h head2.h
gcc –c main.c
test1.o:test1.c head2.h
gcc –c test1.c
test2.o:test2.c head3.h
gcc –c test2.c
install:
cp test /home/tmp
clean:
rm –f *.o
在这个makefile文件中,目标文件(target)即为:最终的可执行文件test和中间目标文
件main.o、test1.o、test2.o,每个目标文件和它的依赖文件中间用“:”隔开,依赖文件的列
表之间用空格隔开。每一个.o文件都有一组依赖文件,而这些.o文件又是最终的可执行文件
test的依赖文件。依赖关系实质上就是说明了目标文件是由哪些文件生成的。
在定义好依赖关系后,在命令列表中定义了如何生成目标文件的命令,命令行以Tab键
开始。Make 工具会比较目标文件和其依赖文件的创建或修改日期,如果所依赖文件比目标
文件要新,或者目标文件不存在的话,那么,make就会执行命令行列表中的命令来生成目标
文件。
3.Makefile文件中变量的使用
Makefile 文件中除了一系列的规则,对于变量的使用也是一个很重要的内容。Linux 下
的Makefile 文件中可能会使用很多的变量,定义一个变量(也常称为宏定义),只要在一行
的开始定义这个变量(一般使用大写,而且放在Makefile文件的顶部来定义),后面跟一个=
号,=号后面即为设定的变量值。如果要引用该变量,用一个$符号来引用变量,变量名需要
放在$后的()里。
make工具还有一些特殊的内部变量,它们根据每一个规则内容定义。
· $@:指代当前规则下的目标文件列表。
· $<:指代依赖文件列表中的第一个依赖文件。
· $^:指代依赖文件列表中所有依赖文件。
· $?:指代依赖文件列表中新于对应目标文件的文件列表。
变量的定义可以简化makefile的书写,方便对程序的维护。例如前面的Makefile例程就
可以如下书写。
#Makefile Example
OBJ=main.o test1.o test2.o
CC=gcc
test:$(OBJ)
$(CC) –o test $(OBJ)
main.o:main.c head1.h head2.h
$(CC)–c main.c
test1.o:test1.c head2.h
$(CC) –c test1.c
test2.o:test2.c head3.h
$(CC) –c test2.c
install:
cp test /home/tmp
clean:
rm –f *.o
从上面修改的例子可以看到,引入了变量OBJ 和CC,这样可以简化makefile 文件的编
写,增加了文件的可读性,而且便于修改。举个例子来说,假定项目文件中还需要加入另外
一个新的目标文件test3.o,那么在该Makefile 中有两处需要分别添加test3.o;而如果使用变
量的话只需在OBJ 变量的列表中添加一次即可,这对于更复杂的Makefile程序来说,会是一
个不小的工作量,但是,这样可以降低因为编辑过程中的疏漏而导致出错的可能。
一般来说,Makefile文件中变量的应用主要有以下几个方面。
1.代表一个文件列表
Makefile文件中的变量常常存储一些目标文件甚至是目标文件的依赖文件,引用这些文件
的时候引用存储这些文件的变量即可,这给Makefile编写和维护者带来了很大的方便。
2.代表编译命令选项
当所有编译命令都带有相同编译选项时(比如-Wall -O2等),可以将该编译选项赋给一
个变量,这样方便了引用。同时,如果改变编译选项的时候,只需改变该变量值即可,而不
必在每处用到编译选项的地方都做改动。
在上面的Makefile例子中,还定义了一个伪目标clean,它规定了make应该执行的命令,
即删除所有编译过程中产生的中间目标文件。当make处理到伪目标clean时,会先查看其对
应的依赖对象。由于伪目标clean没有任何依赖文件,所以make命令会认为该目标是最新的
而不会执行任何操作。为了编译这个目标体,必须手工执行如下命令。
# make clean
此时,系统会有提示信息:
rm -f *.o
另一个经常用到的伪目标是install。它通常是将编译完成的可执行文件或程序运行所需的其
他文件拷贝到指定的安装目录中,并设置相应的保护。例如在上面的例子中,如果用户执行命令:
# make install
系统会有提示信息:
cp test1 /home /tmp
也即是将可执行程序test1 拷贝到系统/home/tmp 下。事实上,许多应用程序的Makefile
文件也正是这样写的,这样便于程序在正确编译后可以被安装到正确的目录。
Linux_C编程一站式学习_最新版.pdf
1. 基本规则
只要执行了命令列表就算更新了目标,即使目标并没有生成也算
命令前面加@和-字符的效果:
如果make执行的命令前面加了@字符,则不显示命令本身而只显示它的结果;
通常make执行的命令如果出错(该命令的退出状态非0)就立刻终止,不再执行后续命令,但如果命令前面加了-号,即使这条命令出错,make也会继续执行后续命令。
通常rm命令和mkdir命令前面要加-号,因为rm要删除的文件可能不存在,mkdir要创建的目录可能已存在,这两个命令都有可能出错,但这种错误是应该忽略的。
如果存在clean这个文件,clean目标又不依赖于任何条件,make就认为它不需要更新了。而我们希望把clean当作一个特殊的名字使用,不管它存在不存在都要更新,可以添一条特殊规则,把clean声明为一个伪目标:
.PHONY: clean
这条规则没有命令列表。类似.PHONY这种make内建的特殊目标还有很多,各有不同的用途,详见[
GNUmake]。在C语言中要求变量和函数先声明后使用,而Makefile不太一样,这条规则写在clean:规则的后面也行,也能起到声明clean是伪目标的作用
gcc处理一个C程序分为预处理和编译两个阶段,类似地,make处理Makefile的过程也分为两个阶段:
1. 首先从前到后读取所有规则,建立起一个完整的依赖关系图,
2. 然后从缺省目标或者命令行指定的目标开始,根据依赖关系图选择适当的规则执行,执行Makefile中的规则和执行C代码不一样,并不是从前到后按顺序执行,也不是所有规则都要执行一遍,例如make缺省目标时不会更新clean目标,因为从上图可以看出,它跟缺省目标没有任何依赖关系。
clean目标是一个约定俗成的名字,在所有软件项目的Makefile中都表示清除编译生成的文件,类似这样的约定俗成的目标名字有:all,执行主要的编译工作,通常用作缺省目标。install,执行编译后的安装工作,把可执行文件、配置文件、文档等分别拷到不同的安装目录。clean,删除编译生成的二进制文件。distclean,不仅删除编译生成的二进制文件,也删除其它生成的文件,例如配置文件和格式转换后的文档,执行make distclean之后应该清除所有这些文件,只留下源文件。
只要符合本章所描述的语法的文件我们都叫它Makefile,而它的文件名则不一定是Makefile。事实上,执行make命令时,是按照GNUmakefile、makefile、Makefile的顺序找到第一个存在的文件并执行它,不过还是建议使用Makefile做文件名。除了GNU make,有些UNIX系统的make命令不是GNU make,不会查找GNUmakefile这个文件名,如果你写的Makefile包含GNU make的特殊语法,可以起名为GNUmakefile,否则不建议用这个文件名。
2. 隐含规则和模式规则
一个目标依赖的所有条件不一定非得写在一条规则中,也可以拆开写,如果一个目标拆开写多条规则,其中只有一条规则允许有命令列表,其它规则应该没有命令列表,否则make会报警告并且采用最后一条规则的命令列表。
如果一个目标在Makefile中的所有规则都没有命令列表,make会尝试在内建的隐含规则(Implicit Rule)数据库中查找适用的规则。make的隐含规则数据库可以用make -p命令打印,打印出来的格式也是Makefile的格式,包括很多变量和规则,其中和我们这个例子有关的隐含规则有:
# default
OUTPUT_OPTION = -o $@
# default
CC = cc
# default
COMPILE.c = $(CC) $(CFLAGS) $(CPPFLAGS) $(TARGET_ARCH) -c
%.o: %.c
# commands to execute (built-in):
$(COMPILE.c) $(OUTPUT_OPTION) $<
#号在Makefile中表示单行注释,就像C语言的//注释一样。CC是一个Makefile变量,用CC = cc定义和赋值,用$(CC)取它的值,其值应该是cc。Makefile变量像C的宏定义一样,代表一串字符,在取值的地方展开。cc是一个符号链接,通常指向gcc,在有些UNIX系统上可能指向另外一种C编译器。
$ which cc/usr/bin/cc$ ls -l /usr/bin/cclrwxrwxrwx 1 root root 20 2008-07-04 05:59 /usr/bin/cc -> /etc/alternatives/cc
$ ls -l /etc/alternatives/cclrwxrwxrwx 1 root root 12 2008-11-01 09:10 /etc/alternatives/cc -> /usr/bin/gcc
CFLAGS这个变量没有定义,$(CFLAGS)展开是空,CPPFLAGS和TARGET_ARCH也是如此。这样$(COMPILE.c)展开应该是cc空空空-c,去掉所有的“空”得到cc-c,注意中间留下4个空格,所以%.o: %.c规则的命令$(COMPILE.c)$(OUTPUT_OPTION)$<展开之后是cc-c-o$@$<,和上面的编译命令已经很接近了。
$@和$<是两个特殊的变量,$@的取值为规则中的目标,$<的取值为规则中的第一个条件。%.o:%.c是一种特殊的规则,称为模式规则(Pattern Rule)。现在回顾一下整个过程,在我们的Makefile中以main.o为目标的规则都没有命令列表,所以make会查找隐含规则,发现隐含规则中有这样一条模式规则适用,main.o符合%.o的模式,现在%就代表main(称为main.o这个名字的Stem),再替换到%.c中就是main.c。所以这条模式规则相当于:
main.o: main.c
cc -c -o main.o main.c
随后,在处理stack.o目标时又用到这条模式规则,这时又相当于:
stack.o: stack.c cc -c -o stack.o stack.c
maze.o也同样处理。这三条规则可以由make的隐含规则推导出来,所以不必写在Makefile中。
先前我们写Makefile都是以目标为中心,一个目标依赖于若干条件,现在换个角度,以条件为中心,Makefile还可以这么写:
main: main.o stack.o maze.o
gcc main.o stack.o maze.o -o main
main.o stack.o maze.o: main.h
main.o maze.o: maze.h
main.o stack.o: stack.h
clean:
-rm main *.o
.PHONY: clean
我们知道,写规则的目的是让make建立依赖关系图,不管怎么写,只要把所有的依赖关系都描述清楚了就行。对于多目标的规则,make会拆成几条单目标的规则来处理,例如
target1 target2: prerequisite1 prerequisite2
command $< -o $@
这样一条规则相当于:
target1: prerequisite1 prerequisite2
command prerequisite1 -o target1
target2: prerequisite1 prerequisite2
command prerequisite1 -o target2
注意两条规则的命令列表是一样的,但$@的取值不同。
3. 变量
这一节我们详细看看Makefile中关于变量的语法规则。先看一个简单的例子:
foo = $(bar)
bar = Huh?
all:
@echo $(foo)
我们执行make将会打出Huh?。当make读到foo = $(bar)时,确定foo的值是$(bar),但并不立即展开$(bar),然后读到bar = Huh?,确定bar的值是Huh?,然后在执行规则all:的命令列表时才需要展开$(foo),得到$(bar),再展开$(bar),得到Huh?。因此,虽然bar的定义写在foo之后,$(foo)展开还是能够取到$(bar)的值。
这种特性有好处也有坏处。好处是我们可以把变量的值推迟到后面定义,例如:
main.o: main.c
$(CC) $(CFLAGS) $(CPPFLAGS) -c $<
CC = gcc
CFLAGS = -O -g
CPPFLAGS = -Iinclude
编译命令可以展开成gcc -O -g -Iinclude -c main.c。通常把CFLAGS定义成一些编译选项,例如-O、-g等,而把CPPFLAGS定义成一些预处理选项,例如-D、-I等。用=号定义变量的延迟展开特性也有坏处,就是有可能写出无穷递归的定义,例如CFLAGS = $(CFLAGS) -O,或者:A = $(B) B = $(A)
当然,make有能力检测出这样的错误而不会陷入死循环。有时候我们希望make在遇到变量定义时立即展开,可以用:=运算符,例如:
x := foo
y := $(x) bar
all:
@echo "-$(y)-"
当make读到y := $(x) bar定义时,立即把$(x)展开,使变量y的取值是foo bar,如果把这两行颠倒过来:
y := $(x) bar
x := foo
那么当make读到y := $(x) bar时,x还没有定义,展开为空值,所以y的取值是bar,注意bar前面有个空格。一个变量的定义从=后面的第一个非空白字符开始(从$(x)的$开始),包括后面的所有字符,直到注释或换行之前结束。如果要定义一个变量的值是一个空格,可以这样:
nullstring :=
space := $(nullstring) # end of the line
nullstring的值为空,space的值是一个空格,后面写个注释是为了增加可读性,如果不写注释就换行,则很难看出$(nullstring)后面有个空格。
还有一个比较有用的赋值运算符是?=,例如foo ?= $(bar)的意思是:如果foo没有定义过,那么?=相当于=,定义foo的值是$(bar),但不立即展开;如果先前已经定义了foo,则什么也不做,不会给foo重新赋值。
+=运算符可以给变量追加值,例如:
objects = main.o
objects += $(foo)
foo = foo.o bar.o
object是用=定义的,+=仍然保持=的特性,objects的值是main.o $(foo)(注意$(foo)前面自动添一个空格),但不立即展开,等到后面需要展开$(objects)时会展开成main.o foo.o bar.o。
再比如:
objects := main.o
objects += $(foo)
foo = foo.o bar.o
object是用:=定义的,+=保持:=的特性,objects的值是main.o $(foo),立即展开得到main.o (这时foo还没定义),注意main.o后面的空格仍保留。
如果变量还没有定义过就直接用+=赋值,那么+=相当于=。
上一节我们用到了特殊变量$@和$<,这两个变量的特点是不需要给它们赋值,在不同的上下文中它们自动取不同的值。常用的特殊变量有:
$@,表示规则中的目标。
$<,表示规则中的第一个条件。
$?,表示规则中所有比目标新的条件,组成一个列表,以空格分隔。
$^,表示规则中的所有条件,组成一个列表,以空格分隔。
例如前面写过的这条规则:
main: main.o stack.o maze.o
gcc main.o stack.o maze.o -o main
可以改写成:
main: main.o stack.o maze.o
gcc $^ -o $@
这样即使以后又往条件里添加了新的目标文件,编译命令也不需要修改,减少了出错的可能。
$?变量也很有用,有时候希望只对更新过的条件进行操作,例如有一个库文件libsome.a依赖于几个目标文件:
libsome.a: foo.o bar.o lose.o win.o
ar r libsome.a $?
ranlib libsome.a
这样,只有更新过的目标文件才需要重新打包到libsome.a中,没更新过的目标文件原本已经在libsome.a中了,不必重新打包。
在上一节我们看到make的隐含规则数据库中用到了很多变量,有些变量没有定义(例如CFLAGS),有些变量定义了缺省值(例如CC),我们写Makefile时可以重新定义这些变量的值,也可以在缺省值的基础上追加。以下列举一些常用的变量,请读者体会其中的规律。
AR
静态库打包命令的名字,缺省值是ar。
ARFLAGS
静态库打包命令的选项,缺省值是rv。
AS
汇编器的名字,缺省值是as。
ASFLAGS
汇编器的选项,没有定义。
CC
C编译器的名字,缺省值是cc。
CFLAGS
C编译器的选项,没有定义。
CXX
C++编译器的名字,缺省值是g++。
CXXFLAGS
C++编译器的选项,没有定义。
CPP
C预处理器的名字,缺省值是$(CC) -E。
CPPFLAGS
C预处理器的选项,没有定义。
LD
链接器的名字,缺省值是ld。
LDFLAGS
链接器的选项,没有定义。
TARGET_ARCH
和目标平台相关的命令行选项,没有定义。
OUTPUT_OPTION
输出的命令行选项,缺省值是-o $@。
LINK.o
把.o文件链接在一起的命令行,缺省值是$(CC) $(LDFLAGS) $(TARGET_ARCH)。
LINK.c
把.c文件链接在一起的命令行,缺省值是$(CC) $(CFLAGS) $(CPPFLAGS) $(LDFLAGS)$(TARGET_ARCH)。
LINK.cc
把.cc文件(C++源文件)链接在一起的命令行,缺省值是$(CXX) $(CXXFLAGS) $(CPPFLAGS)$(LDFLAGS) $(TARGET_ARCH)。
COMPILE.c
编译.c文件的命令行,缺省值是$(CC) $(CFLAGS) $(CPPFLAGS) $(TARGET_ARCH) -c。
COMPILE.cc
编译.cc文件的命令行,缺省值是$(CXX) $(CXXFLAGS) $(CPPFLAGS) $(TARGET_ARCH) -c。
RM
删除命令的名字,缺省值是rm -f。
4. 自动处理头文件的依赖关系
现在我们的Makefile写成这样:
all: main
main: main.o stack.o maze.o
gcc $^ -o $@
main.o: main.h stack.h maze.h
stack.o: stack.h main.h
maze.o: maze.h main.h
clean:
-rm main *.o
.PHONY: clean
按照惯例,用all做缺省目标。现在还有一点比较麻烦,在写main.o、stack.o和maze.o这三个目标的规则时要查看源代码,找出它们依赖于哪些头文件,这很容易出错,一是因为有的头文件包含在另一个头文件中,在写规则时很容易遗漏,二是如果以后修改源代码改变了依赖关系,很可能忘记修改Makefile的规则。为了解决这个问题,可以用gcc的-M选项自动生成目标文件和源文件的依赖关系:
$ gcc -M main.c
main.o: main.c /usr/include/stdio.h /usr/include/features.h \ /usr/include/sys/cdefs.h /usr/include/bits/wordsize.h \ /usr/include/gnu/stubs.h /usr/include/gnu/stubs-32.h \ /usr/lib/gcc/i486-linux-gnu/4.3.2/include/stddef.h \ /usr/include/bits/types.h /usr/include/bits/typesizes.h \ /usr/include/libio.h /usr/include/_G_config.h /usr/include/wchar.h \ /usr/lib/gcc/i486-linux-gnu/4.3.2/include/stdarg.h \ /usr/include/bits/stdio_lim.h /usr/include/bits/sys_errlist.h main.h \ stack.h maze.h
-M选项把stdio.h以及它所包含的系统头文件也找出来了,如果我们不需要输出系统头文件的依赖关系,可以用-MM选项:
$ gcc -MM *.c
main.o: main.c main.h stack.h maze.hmaze.o: maze.c maze.h main.hstack.o: stack.c stack.h main.h
接下来的问题是怎么把这些规则包含到Makefile中,GNU make的官方手册建议这样写:
all: main
main: main.o stack.o maze.o
gcc $^ -o $@
clean:
-rm main *.o
.PHONY: clean
sources = main.c stack.c maze.c
include $(sources:.c=.d)
%.d: %.c
set -e; rm -f $@; \
$(CC) -MM $(CPPFLAGS) $< > $@.$$$$; \
sed 's,\($*\)\.o[ :]*,\1.o $@ : ,g' < $@.$$$$ > $@; \
rm -f $@.$$$$
sources变量包含我们要编译的所有.c文件,$(sources:.c=.d)是一个变量替换语法,把sources变量中每一项的.c替换成.d,所以include这一句相当于:
include main.d stack.d maze.d
类似于C语言的#include指示,这里的include表示包含三个文件main.d、stack.d和maze.d,这三个文件也应该符合Makefile的语法。如果现在你的工作目录是干净的,只有.c文件、.h文件和Makefile,运行make的结果是:
$ make
Makefile:13: main.d: No such file or directory
Makefile:13: stack.d: No such file or directory
Makefile:13: maze.d: No such file or directory
set -e; rm -f maze.d; \ cc -MM maze.c > maze.d.$$; \ sed 's,\(maze\)\.o[ :]*,\1.o maze.d : ,g' < maze.d.$$ > maze.d; \ rm -f maze.d.$$
set -e; rm -f stack.d; \ cc -MM stack.c > stack.d.$$; \ sed 's,\(stack\)\.o[ :]*,\1.o stack.d : ,g' < stack.d.$$ > stack.d; \ rm -f stack.d.$$
set -e; rm -f main.d; \ cc -MM main.c > main.d.$$; \ sed 's,\(main\)\.o[ :]*,\1.o main.d : ,g' < main.d.$$ > main.d; \ rm -f main.d.$$
cc -c -o main.o main.c
cc -c -o stack.o stack.c
cc -c -o maze.o maze.c
gcc main.o stack.o maze.o -o main
一开始找不到.d文件,所以make会报警告。但是make会把include的文件名也当作目标来尝试更新,而这些目标适用模式规则%.d: %c,所以执行它的命令列表,比如生成maze.d的命令:
set -e; rm -f maze.d; \ cc -MM maze.c > maze.d.$$; \ sed 's,\(maze\)\.o[ :]*,\1.o maze.d : ,g' < maze.d.$$ > maze.d; \ rm -f maze.d.$$
注意,虽然在Makefile中这个命令写了四行,但其实是一条命令,make只创建一个Shell进程执行这条命令,这条命令分为5个子命令,用;号隔开,并且为了美观,用续行符\拆成四行来写。执行步骤为:
1. set -e命令设置当前Shell进程为这样的状态:如果它执行的任何一条命令的退出状态非零则立刻终止,不再执行后续命令。
2. 把原来的maze.d删掉。
3. 重新生成maze.c的依赖关系,保存成文件maze.d.1234(假设当前Shell进程的id是1234)。注意,在Makefile中$有特殊含义,如果要表示它的字面意思则需要写两个$,所以Makefile中的四个$传给Shell变成两个$,两个$在Shell中表示当前进程的id,一般用它给临时文件起名,以保证文件名唯一。
4. 这个sed命令比较复杂,就不细讲了,主要作用是查找替换。maze.d.1234的内容应该是maze.o: maze.c maze.h main.h,经过sed处理之后存为maze.d,其内容是maze.o maze.d:maze.c maze.h main.h。
5. 最后把临时文件maze.d.1234删掉。
#####################################################################################
$*
这个变量表示目标模式中"%"及其之前的部分。如果目标是"dir/a.foo.b",并且目标的模式是"a.%.b",那么,"$*"的值就是"dir/a.foo"。这个变量对于构造有关联的文件名是比较有较。如果目标中没有模式的定义,那么"$*"也就不能被推导出,但是,如果目标文件的后缀是make所识别的,那么"$*"就是除了后缀的那一部分。例如:如果目标是"foo.c",因为".c"是make所能识别的后缀名,所以,"$*"的值就是"foo"。这个特性是GNU make的,很有可能不兼容于其它版本的make,所以,你应该尽量避免使用"$*",除非是在隐含规则或是静态模式中。如果目标中的后缀是make所不能识别的,那么"$*"就是空值。
Now let's look at the metacharacters that allow us to select any individual portion of a string that is
matched and recall it in the replacement string. A pair of escaped parentheses are used in sed to enclose
any part of a regular expression and save it for recall. Up to nine "saves" are permitted for a single line.
"\n" is used to recall the portion of the match that was saved, where n is a number from 1 to 9
referencing a particular "saved" string in order of use.
sed中 \(\)用于选择表达式中的任意部分,保存以供后用,单行可用9个保存区域。
\n用于调用保存区的内容。
s/\(See Section \)\([1-9][0-9]*\.[1-9][0-9]*\)/\1\\fB\2\\fP/
Two pairs of escaped parentheses are specified. The first captures "See Section " (because this is a
fixed string, it could have been simply retyped in the replacement string). The second captures the
section number. The replacement string recalls the first saved substring as "\1" and the second as "\2,"
which is surrounded by bold-font requests.
$ cat test1
first:second
one:two
$ sed 's/\(.*\):\(.*\)/\2:\1/' test1
second:first
two:one
The larger point is that you can recall a saved substring in any order, and multiple times, as you'll see in
the next example.
其他sed替换用法参见下面文章:
sed替换的基本语法
作者:RISEBY
链接:https://www.imooc.com/article/50039
来源:慕课网
Linux sed 命令字符串替换使用方法详解
#######################################################################################
不管是Makefile本身还是被它包含的文件,只要有一个文件在make过程中被更新了,make就会重新读取整个Makefile以及被它包含的所有文件,现在main.d、stack.d和maze.d都生成了,就可以正常包含进来了(假如这时还没有生成,make就要报错而不是报警告了),相当于在Makefile中添了三条规则:
main.o main.d: main.c main.h stack.h maze.h
maze.o maze.d: maze.c maze.h main.h
stack.o stack.d: stack.c stack.h main.h
如果我在main.c中加了一行#include "foo.h",那么:
1、main.c的修改日期变了,根据规则main.o main.d: main.c main.h stack.h maze.h要重新生成main.o和main.d。生成main.o的规则有两条:
main.o: main.c main.h stack.h maze.h%.o: %.c# commands to execute (built-in): $(COMPILE.c) $(OUTPUT_OPTION) $<
第一条是把规则main.o main.d: main.c main.h stack.h maze.h拆开写得到的,第二条是隐含规则,因此执行cc命令重新编译main.o。生成main.d的规则也有两条:
main.d: main.c main.h stack.h maze.h%.d: %.c set -e; rm -f $@; \ $(CC) -MM $(CPPFLAGS) $< > $@.$$$$; \ sed 's,\($*\)\.o[ :]*,\1.o $@ : ,g' < $@.$$$$ > $@; \ rm -f $@.$$$$
因此main.d的内容被更新为main.o main.d: main.c main.h stack.h maze.h foo.h。
2、由于main.d被Makefile包含,main.d被更新又导致make重新读取整个Makefile,把新的main.d包含进来,于是新的依赖关系生效了。
以上说法不是很准确:
更改了一下Makefile
all: main
main: main.o stack.o maze.o
gcc $^ -o $@
clean:
-rm main *.o
.PHONY: clean
sources = main.c stack.c maze.c
include $(sources:.c=.d)
maze.o: maze.c maze.h main.h
@echo "maze"
gcc -c maze.c
%.d: %.c
set -e; rm -f $@; \
$(CC) -MM $(CPPFLAGS) $< > $@.$$$$; \
sed 's,\($*\)\.o[ :]*,\1.o $@ : ,g' < $@.$$$$ > $@; \
cat $@
rm -f $@.$$$$
几个要点:
1. 首先从前到后读取所有规则,建立起一个完整的依赖关系图
比如上面这个Makefile:
all: main
main: main.o stack.o maze.o
gcc $^ -o $@
clean:
-rm main *.o
.PHONY: clean
sources = main.c stack.c maze.c
#如果三个.d文件不存在,这就是空
main.o main.d: main.c main.h stack.h maze.h
maze.o maze.d: maze.c maze.h main.h
stack.o stack.d: stack.c stack.h main.h
maze.o: maze.c maze.h main.h
@echo "maze"
gcc -c maze.c
%.d: %.c
set -e; rm -f $@; \
$(CC) -MM $(CPPFLAGS) $< > $@.$$$$; \
sed 's,\($*\)\.o[ :]*,\1.o $@ : ,g' < $@.$$$$ > $@; \
cat $@
rm -f $@.$$$$
2. 然后从缺省目标或者命令行指定的目标开始,根据依赖关系图选择适当的规则执行,执行Makefile中的规则和执行C代码不一样,并不是从前到后按顺序执行,也不是所有规则都要执行一遍,例如make缺省目标时不会更新clean目标,因为从上图可以看出,它跟缺省目标没有任何依赖关系。
.d文件都不存在时候make
zhangyi@xxx:~/work/idyll_project/ctest/mftest$ make
Makefile:8: main.d: No such file or directory
Makefile:8: stack.d: No such file or directory
Makefile:8: maze.d: No such file or directory
set -e; rm -f maze.d; \
cc -MM maze.c > maze.d.$$; \
sed 's,\(maze\)\.o[ :]*,\1.o maze.d : ,g' < maze.d.$$ > maze.d; \
rm -f maze.d.$$
cat maze.d
maze.o maze.d : maze.c maze.h main.h
set -e; rm -f stack.d; \
cc -MM stack.c > stack.d.$$; \
sed 's,\(stack\)\.o[ :]*,\1.o stack.d : ,g' < stack.d.$$ > stack.d; \
rm -f stack.d.$$
cat stack.d
stack.o stack.d : stack.c stack.h main.h
set -e; rm -f main.d; \
cc -MM main.c > main.d.$$; \
sed 's,\(main\)\.o[ :]*,\1.o main.d : ,g' < main.d.$$ > main.d; \
rm -f main.d.$$
cat main.d
main.o main.d : main.c main.h stack.h
#不管是Makefile本身还是被它包含的文件,只要有一个文件在make过程中被更新了,make就会重新读取整个Makefile以及被它包含的所有文件,现在main.d、stack.d和maze.d都生成了,就可以正常包含进来了
cc -c -o main.o main.c
cc -c -o stack.o stack.c
maze
gcc -c maze.c
gcc main.o stack.o maze.o -o main
如果maze.c删除或加入一个头文件:从缺省目标开始
all->main->1.main.o 2.stack.o 3.maze.o
按顺序寻找各个.o
all: main
main: main.o stack.o maze.o
gcc $^ -o $@
clean:
-rm main *.o
.PHONY: clean
sources = main.c stack.c maze.c
main.o main.d: main.c main.h stack.h maze.h
maze.o maze.d: maze.c maze.h main.h
stack.o stack.d: stack.c stack.h main.h
maze.o: maze.c maze.h main.h
@echo "maze"
gcc -c maze.c
%.d: %.c
set -e; rm -f $@; \
$(CC) -MM $(CPPFLAGS) $< > $@.$$$$; \
sed 's,\($*\)\.o[ :]*,\1.o $@ : ,g' < $@.$$$$ > $@; \
cat $@
rm -f $@.$$$$
maze.c改变了,所以maze.o maze.d 需要重新生成。
make的执行过程如下:
1. 依次读取变量“MAKEFILES”定义的makefile文件列表
2. 读取工作目录下的makefile文件(缺省的是根据命名的查找顺序“GNUmakefile”,“makefile”,“Makefile”,首先找到那个就读取那个)
3. 依次读取工作目录makefile文件中使用指示符“include”包含的文件
4. 查找重建所有已读取的makefile文件的规则(如果存在一个目标是当前读取的某一个makefile文件,则执行此规则重建此makefile文件,完成以后从第一步开始重新执行)
5. 初始化变量值并展开那些需要立即展开的变量和函数并根据预设条件确定执行分支
6. 根据“终极目标”以及其他目标的依赖关系建立依赖关系链表
7. 执行除“终极目标”以外的所有的目标的规则(规则中如果依赖文件中任一个文件的时间戳比目标文件新,则使用规则所定义的命令重建目标文件)
8. 执行“终极目标”所在的规则
zhangyi@xxx:~/work/idyll_project/ctest/mftest$ make
set -e; rm -f maze.d; \
cc -MM maze.c > maze.d.$$; \
sed 's,\(maze\)\.o[ :]*,\1.o maze.d : ,g' < maze.d.$$ > maze.d; \
rm -f maze.d.$$
cat maze.d
maze.o maze.d : maze.c
cc -c -o main.o main.c
cc -c -o stack.o stack.c
maze
gcc -c maze.c
gcc main.o stack.o maze.o -o main
采用以下规则生成maze.d
%.d: %.c
set -e; rm -f $@; \
$(CC) -MM $(CPPFLAGS) $< > $@.$$$$; \
sed 's,\($*\)\.o[ :]*,\1.o $@ : ,g' < $@.$$$$ > $@; \
cat $@
rm -f $@.$$$$
显式规则优先级 > 隐藏规则 所以采用以下规则生成maze.o
maze.o: maze.c maze.h main.h
@echo "maze"
gcc -c maze.c
5. 常用的make命令行选项
-n选项只打印要执行的命令,而不会真的执行命令,这个选项有助于我们检查Makefile写得是否正确,由于Makefile不是顺序执行的,用这个选项可以先看看命令的执行顺序,确认无误了再真正执行命令。
-C选项可以切换到另一个目录执行那个目录下的Makefile,比如先退到上一级目录再执行我们的Makefile(假设我们的源代码都放在testmake目录下):
$ cd ..
$ make -C testmake
make: Entering directory `/home/akaedu/testmake'
cc -c -o main.o main.c
cc -c -o stack.o stack.c
cc -c -o maze.o maze.c
gcc main.o stack.o maze.o -o main
make: Leaving directory `/home/akaedu/testmake'
一些规模较大的项目会把不同的模块或子系统的源代码放在不同的子目录中,然后在每个子目录下都写一个该目录的Makefile,然后在一个总的Makefile中用make -C命令执行每个子目录下的Makefile。例如Linux内核源代码根目录下有Makefile,子目录fs、net等也有各自的Makefile,二级子目录fs/ramfs、net/ipv4等也有各自的Makefile。
在make命令行也可以用=或:=定义变量,如果这次编译我想加调试选项-g,但我不想每次编译都加-g选项,可以在命令行定义CFLAGS变量,而不必修改Makefile编译完了再改回来:
$ make CFLAGS=-g
cc -g -c -o main.o main.c
cc -g -c -o stack.o stack.c
cc -g -c -o maze.o maze.c
gcc main.o stack.o maze.o -o main
如果在Makefile中也定义了CFLAGS变量,则命令行的值覆盖Makefile中的值。