TensorRT INT8量化原理以及如何编写校准器类进行校准
在上一篇博客中介绍了从Pytorch模型到ONNX中间格式文件再到TensorRT推理引擎的整个过程,其中在进行INT8格式的转换时,需要额外的工作来做,这篇博客就针对INT8转换的具体过程及如何准备校准集、编写校准器进行详细介绍。
同时,使用TensorRT进行INT8量化的过程也分享到了GitHub,欢迎大家参考。
目录
1、INT8量化过程
2、编写校准器,并进行INT8量化
1、INT8量化过程
众所周知,一个训练好的深度学习模型,其数据包含了权重(weights)和偏移(biases)两部分,在其进行前向推理(forward)时,中间会根据权重和偏移产生激活值(activation)。
关于INT8的量化原理,这篇回答非常详尽,我这里就简单说结论了:
- TensorRT在进行INT8量化时,对权重直接使用了最大值量化,对偏移直接忽略,对前向计算中的激活值的量化是重点;
- 对激活值进行INT8量化采用饱和量化:因为激活值通常分布不均匀,直接使用非饱和量化会使得量化后的值都挤在一个很小的范围从而浪费了INT8范围内的其他空间,也就是说没有充分利用INT8(-128~+127)的值域;而进行饱和量化后,使得映射后的-128~+127范围内分布相对均匀,这相当于去掉了一些不重要的因素,保留了主要成分。
 图1. 直接忽略bias
图1. 直接忽略bias
图1告诉我们,直接忽略bias就完事了,这是官方给出的实验结论。
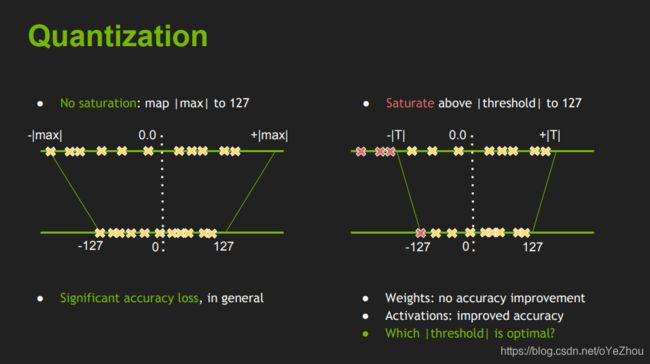 图1. 非饱和量化(左图)和饱和量化(右图)
图1. 非饱和量化(左图)和饱和量化(右图)
图2告诉我们权重没必要使用饱和映射,因为没啥提高,而激活值使用饱和映射能调高性能,这好理解,因为权重通常分别较为均匀直接最大值非饱和映射和费劲力气找阈值再进行饱和映射,其量化后的分布很可能是极其相似的,而激活值分布不均,寻找一个合适的阈值进行饱和映射就显得比较重要了;并展示了直接使用最大值量化到INT8和选择一个合适的阈值后饱和地量化到INT的区别,可以看出:右图的关键在于选择一个合适的阈值T,来对原来的分布进行一个截取,将-T~+T之间的值映射到-128~+127,而>T和<-T的值则忽略掉。
如何寻找这个阈值T就成了INT量化的关键。
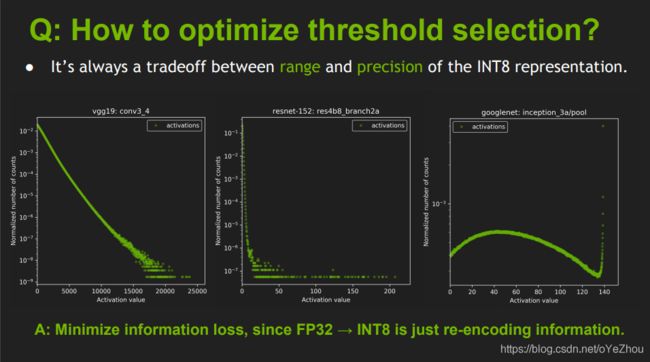 图3. 各模型激活值分布
图3. 各模型激活值分布
图3可以看出,不同模型的激活值分布差异很大,这就需要进行动态的量化,也即针对每一个模型,寻找一个对它来说最合适的T。
于是,NVIDIA就选择了KL散度也即相对熵来对量化前后的激活值分布进行评价,来找出使得量化后INT8分布相对于原来的FP32分布信息损失最小的那个阈值。如图4所示:
 图4. 相对熵:KL散度
图4. 相对熵:KL散度
于是,整个的量化过程就给了出来,如图5所示:
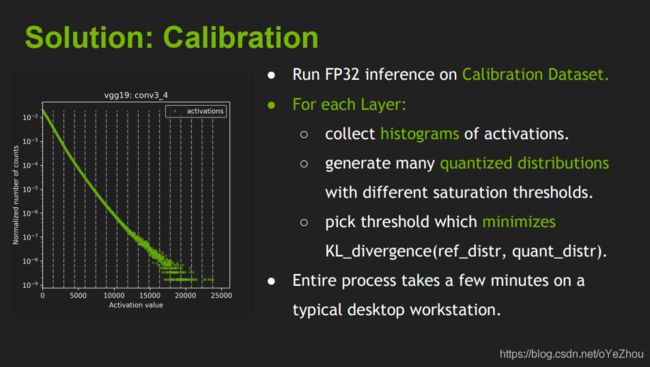 图5. INT8量化校准过程
图5. INT8量化校准过程
意思就是:
- 先在一个校准数据集上跑一遍原FP32的模型;
- 然后,对每一层都收集激活值的直方图,并生成在不同阈值下的饱和量化分布;
- 最后,找出使得KL散度最小的那个阈值T,即为所求。
这个过程同时也告诉了我们,要做INT8量化,需要准备哪些东西——原来的未量化的模型(废话,没有原模型拿什么量化!)、一个校准数据集、进行量化过程的校准器。如图6所示:
 图6. TensorRT的INT8工作流程
图6. TensorRT的INT8工作流程
图6可以看出,校准过程我们是不用参与的,全部都由TensorRT内部完成,但是,我们需要告诉校准器如何获取一个batch的数据,也就是说,我们需要重写校准器类中的一些方法。下面,我们就开始介绍如何继承原校准器类并重写其中的部分方法,来获取我们自己的数据集来校准我们自己的模型。
2、编写校准器,并进行INT8量化
我们需要继承父类——trt.IInt8EntropyCalibrator2,并重写他的一些方法:get_batch_size, get_batch, read_calibration_cache, write_calibration_cache。
这些方法分别是:获取batch大小、获取一个batch的数据、将校准集写入缓存、从缓存读出校准集。前两个是必须的,不然校准器不知道用什么数据来校准,后两个方法可以忽略,但当你需要多次尝试时,后两个方法将很有用,它们会大大减少数据读取的时间!
下面给出我写的一个读取我自己的数据集的校准器示例,完整工程可参考GitHub:
import tensorrt as trt
import pycuda.driver as cuda
import pycuda.autoinit
import os
import numpy as np
from PIL import Image
import torchvision.transforms as transforms
class CenterNetEntropyCalibrator(trt.IInt8EntropyCalibrator2):
def __init__(self, args, files_path='/home/user/Downloads/datasets/train_val_files/val.txt'):
trt.IInt8EntropyCalibrator2.__init__(self)
self.cache_file = 'CenterNet.cache'
self.batch_size = args.batch_siz
self.Channel = args.channel
self.Height = args.height
self.Width = args.width
self.transform = transforms.Compose([
transforms.Resize([self.Height, self.Width]), # [h,w]
transforms.ToTensor(),
])
self._txt_file = open(files_path, 'r')
self._lines = self._txt_file.readlines()
np.random.shuffle(self._lines)
self.imgs = [os.path.join('/home/user/Downloads/datasets/train_val_files/images',
line.rstrip() + '.jpg') for line in self._lines]
self.batch_idx = 0
self.max_batch_idx = len(self.imgs)//self.batch_size
self.data_size = trt.volume([self.batch_size, self.Channel,self.Height, self.Width]) * trt.float32.itemsize
self.device_input = cuda.mem_alloc(self.data_size)
def next_batch(self):
if self.batch_idx < self.max_batch_idx:
batch_files = self.imgs[self.batch_idx * self.batch_size:\
(self.batch_idx + 1) * self.batch_size]
batch_imgs = np.zeros((self.batch_size, self.Channel, self.Height, self.Width),
dtype=np.float32)
for i, f in enumerate(batch_files):
img = Image.open(f)
img = self.transform(img).numpy()
assert (img.nbytes == self.data_size/self.batch_size), 'not valid img!'+f
batch_imgs[i] = img
self.batch_idx += 1
print("batch:[{}/{}]".format(self.batch_idx, self.max_batch_idx))
return np.ascontiguousarray(batch_imgs)
else:
return np.array([])
def get_batch_size(self):
return self.batch_size
def get_batch(self, names, p_str=None):
try:
batch_imgs = self.next_batch()
if batch_imgs.size == 0 or batch_imgs.size != self.batch_size*self.Channel*self.Height*self.Width:
return None
cuda.memcpy_htod(self.device_input, batch_imgs.astype(np.float32))
return [int(self.device_input)]
except:
return None
def read_calibration_cache(self):
# If there is a cache, use it instead of calibrating again. Otherwise, implicitly return None.
if os.path.exists(self.cache_file):
with open(self.cache_file, "rb") as f:
return f.read()
def write_calibration_cache(self, cache):
with open(self.cache_file, "wb") as f:
f.write(cache)上述代码中,你需要改动的并不多,只需要根据你的数据集存放路径及格式,读取一个batch即可。需要注意的是,读取的一个batch数据,数据类型是np.ndarray,shape为[batch_size, C, H, W],也即[batch大小, 通道, 高, 宽]。
OK,现在编写好了校准器,那么如何进行INT量化呢?这一步,上一篇博客已经介绍过了,这里就不多说了,仅给出示例代码,直接看也很清晰,解释可以看上篇博客:
def ONNX2TRT(args, calib=None):
''' convert onnx to tensorrt engine, use mode of ['fp32', 'fp16', 'int8']
:return: trt engine
'''
assert args.mode.lower() in ['fp32', 'fp16', 'int8'], "mode should be in ['fp32', 'fp16', 'int8']"
G_LOGGER = trt.Logger(trt.Logger.WARNING)
with trt.Builder(G_LOGGER) as builder, builder.create_network() as network, \
trt.OnnxParser(network, G_LOGGER) as parser:
builder.max_batch_size = args.batch_size
builder.max_workspace_size = 1 << 30
if args.mode.lower() == 'int8':
assert (builder.platform_has_fast_int8 == True), "not support int8"
builder.int8_mode = True
builder.int8_calibrator = calib
elif args.mode.lower() == 'fp16':
assert (builder.platform_has_fast_fp16 == True), "not support fp16"
builder.fp16_mode = True
print('Loading ONNX file from path {}...'.format(args.onnx_file_path))
with open(args.onnx_file_path, 'rb') as model:
print('Beginning ONNX file parsing')
parser.parse(model.read())
print('Completed parsing of ONNX file')
print('Building an engine from file {}; this may take a while...'.format(args.onnx_file_path))
engine = builder.build_cuda_engine(network)
print("Created engine success! ")
# 保存计划文件
print('Saving TRT engine file to path {}...'.format(args.engine_file_path))
with open(args.engine_file_path, "wb") as f:
f.write(engine.serialize())
print('Engine file has already saved to {}!'.format(args.engine_file_path))
return engine
参考:
NVIDIA TensorRT量化介绍PPT——8-bit Inference with TensorRT:
http://on-demand.gputechconf.com/gtc/2017/presentation/s7310-8-bit-inference-with-tensorrt.pdf
知乎上@章小龙的Int8量化-介绍:
https://zhuanlan.zhihu.com/p/58182172
我整理的INT8量化GitHub工程:
https://github.com/qq995431104/Pytorch2TensorRT.git