正则表达式 学习
前言
20161112
晃了几天,寻找下阶段项目;
这感觉就像有力气找不到地方使,
三个项目
’分析一段文字作曲‘
’爬取facebook做情感趋势变化曲线‘
’爬取微博头像 进行相似头像查询‘
最后决定,先研究研究爬虫
爬虫多处使用正则表达式,这不是第一次遇到正则了,再次遇到便好好研究一番;
20161116.选定api分析爬虫数据已经一个多星期了感觉,进展很慢;
原因总结:
1 知识面很窄,这次需要用到的html/php/javascript等相关网页网站服务端的知识点,我基本上一无所知,导致xpath和css解析html对象的时候一直null
2 一旦遇到bug卡壳的情况,总感觉不把这个问题解决不太好,死磕到底的代价效率太低。有时候感觉莫名其妙就是达不到预期效果,调试这些小问题浪费很多时间,不过时间充足的话我觉得去好好研究是值得的,时不时的就发现另一个方面的知识,加深对其深层的理解。这次的xpath和css还有正则,饶了一大圈,还是正则靠谱,xpath和css在某些情况会出现选取失败的情况,具体原因还没有找到。
20161117 正则表达式才是正确的选择,css/xpath在JS返回数据的网页都无效(具体原因不明);
webmagic自带regex也无发解析正确的正则表达式,这作者难道没有发现这个问题。
使用java8库自带的正则表达式才能成功,这又是一大圈
**
苦尽甘来,我实现了!
WebMagic框架抓取 + 正则表达式解析 (webmagic自带解析方式都失效)
NBA球员 DwyaneWade
的所有微博!

**
以下内容来自各大论坛博客,已给出链接,只做为我个人总结
正文
正则表达式刚刚入门
参考链接:正则表达式 - 语法
参考链接: 正则表达式练习题集(附答案)
参考链接:在线测试正则表达式
参考链接:别在迷恋正则表达式解析html了,好吗?
参考链接:非常强大的正则表达式,解析HTML
参考链接:实用正则表达式匹配和替换
参考链接:正则表达式30分钟入门教程
正则表达式测试工具有
正则工具RegexBuddy百度下载
正则表达式测试器
正则表达式 转 java String
参考链接:在线工具
JAVA正则表达式的用法(循环匹配)
http://blog.csdn.net/xrt95050/article/details/7165938
http://blog.csdn.net/shamoyuu/article/details/40048281多行匹配处理
JFC 折线图,直接借用了这为仁兄的 GUI代码显示抓取的数据
java实现各种数据统计图(柱形图,饼图,折线图)
谢了
表达式一
^\d+$
解释:

所以,去掉^和$后剩下
\d+d 匹配一个数字字符。等价于 [0-9]
\D 匹配一个非数字字符。等价于 [^0-9]
+ 匹配前面的子表达式一次或多次。例如,’zo+’ 能匹配 “zo” 以及 “zoo”,但不能匹配 “z”。+ 等价于 {1,}。
所以 ,^\d+$ 是匹配一个或多个,且以数字开头,且以数字结尾的串,即非负的整数
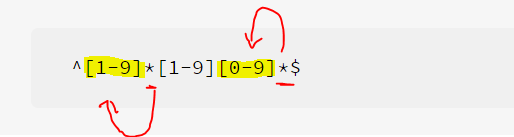
表达式二
^[1-9]*[1-9][0-9]*$解释:
^和$同上,
* 匹配前面的子表达式零次或多次。例如,zo* 能匹配 “z” 以及 “zoo”。* 等价于{0,}。
[xyz] 字符集合。匹配所包含的任意一个字符。例如, ‘[abc]’ 可以匹配 “plain” 中的 ‘a’。
[^xyz] 负值字符集合。匹配未包含的任意字符。例如, ‘[^abc]’ 可以匹配 “plain” 中的’p’、’l’、’i’、’n’。
[a-z] 字符范围。匹配指定范围内的任意字符。例如,’[a-z]’ 可以匹配 ‘a’ 到 ‘z’ 范围内的任意小写字母字符。
[^a-z] 负值字符范围。匹配任何不在指定范围内的任意字符。例如,’[^a-z]’ 可以匹配任何不在 ‘a’ 到 ‘z’ 范围内的任意字符。
即 匹配正整数
注意的是:这个表达式里面 * 符号,每次只能最靠近的左边的一个子表达式起作用,
表达式三
^(-\d+|(0+))$( ) 标记一个子表达式的开始和结束位置。子表达式可以获取供以后使用。要匹配这些字符,请使用 \( 和 \)。
非正整数
笔记
\(?0\d{2}[) -]?\d{8}中的[) -]?
左中括号 右括号 空格 减号 右中括号 问号
的意思是匹配)或-或空格中的一个或零个
2[0-4]\d|25[0-5]|[01]?\d\d?匹配 000-255的数字
(\\t\b)+匹配
\t\t\t\t\t\t \t\t \t\t\t \t
中的
\t\t\t\t\t\t和\t\t和\t\t\t和\t
因为\b匹配单词的开始或结束是字母,的开始和结束,这里不\b没有作用
使用或 | 的时候,在()里面使用能匹配,在[ ]里面就会多匹配多余的东西。
(?<=(\Wclass=\\"WB_text\WW_f14\\"\Wnode-type=\\"feed_list_content\\"\W[(>\\\w)|(.{10}\\"\w+\\">\\n)])).*?(?=<(\\\/div>\\n))
基础就这样
边学便用 暂记
摘抄:
1、长度为8-10的用户密码(以字母开头、数字、下划线)
^[a-zA-Z]\w{7,10} 2、验证输入只能是汉字:[\u4e00−\u9fa5]0,
3、电子邮箱验证:^\w+([-+.]\w+)@\w+([-.]\w+).\w+([-.]\w+)*$
4、URL地址验证:^http://([\w-]+.)+[\w-]+(/[\w-./?%&=]*)?$
5、电话号码的验证:请参考:http://blog.csdn.net/kiritor/article/details/8733469
6、简单的身份证号验证:\d{15}|\d{18}$
end