json解析和字符串解析_高效创建和解析定界字符串
json解析和字符串解析
描述 (Description)
Converting a delimited string into a dataset or transforming it into useful data can be an extremely useful tool when working with complex inputs or user-provided data. There are many methods available to accomplish this task; here we will discuss many of them, comparing performance, accuracy, and availability!
在处理复杂的输入或用户提供的数据时,将定界的字符串转换为数据集或将其转换为有用的数据可能是非常有用的工具。 有许多方法可以完成此任务。 在这里,我们将讨论其中的许多内容,并比较性能,准确性和可用性!
介绍 (Introduction)
While we try to ensure that the queries we write are set-based, and run as efficiently as possible, there are many scenarios when delimited strings can be a more efficient way to manage parameters or lists. Sometimes alternatives, such as temp tables, table-valued parameters, or other set-based approaches simply aren’t available. Regardless of reasons, there is a frequent need to convert a delimited string to and from a tabular structure.
尽管我们尝试确保编写的查询是基于集合的并尽可能高效地运行,但在许多情况下,分隔字符串可以是一种更有效的方法来管理参数或列表。 有时,临时表,表值参数或其他基于集合的方法等替代方法根本不可用。 无论出于何种原因,都经常需要将定界字符串与表格结构之间进行转换。
Our goal is to examine many different approaches towards this problem. We’ll dive into each method, discuss how and why they work, and then compare and contrast performance for both small and large volumes of data. The results should aid you when trying to work through problems involving delimited data.
我们的目标是研究解决此问题的许多不同方法。 我们将深入探讨每种方法,讨论它们的工作方式和原因,然后比较和对比小型和大型数据的性能。 当您尝试解决包含分隔数据的问题时,结果应为您提供帮助。
As a convention, this article will use comma separated values in all demos, but commas can be replaced with any other delimiter or set of delimiting characters. This convention allows for consistency and is the most common way in which list data is spliced. We will create functions that will be used to manage the creation, or concatenation of data into delimited strings. This allows for portability and reuse of code when any of these methods are implemented in your database environments.
按照惯例,本文将在所有演示中使用逗号分隔的值,但是可以用任何其他定界符或定界字符集替换逗号。 该约定允许一致性,并且是拼接列表数据的最常用方法。 我们将创建一些函数,这些函数将用于管理数据的创建或将数据串联成定界字符串。 当在数据库环境中实现这些方法中的任何一种时,都可以实现代码的可移植性和代码重用。
创建定界数据 (Creating Delimited Data)
The simpler use case for delimited strings is the need to create them. As a method of data output, either to a file or an application, there can be benefits in crunching data into a list prior to sending it along its way. For starters, we can take a variable number of columns or rows and turn them into a variable of known size or shape. This is a convenience for any stored procedure that can have a highly variable set of outputs. It can be even more useful when outputting data to a file for use in a data feed or log.
带分隔符的字符串的更简单的用例是需要创建它们。 作为将数据输出到文件或应用程序的一种方法,将数据压缩到列表中然后再按顺序发送可能会有好处。 首先,我们可以采用可变数量的列或行,并将它们转换为已知大小或形状的变量。 这对于可以具有高度可变的输出集的任何存储过程都是很方便的。 将数据输出到文件以供数据订阅源或日志使用时,它甚至会更加有用。
There are a variety of ways to generate delimited strings from data within tables. We’ll start with the scariest option available: The Iterative Approach. This is where we cue the Halloween sound effects and spooky music.
有多种方法可以从表中的数据生成定界字符串。 我们将从可用的最可怕的选项开始:“迭代方法”。 在这里,我们可以提示万圣节的音效和怪异的音乐。
迭代法 (The Iterative Approach)
In terms of simplicity, iterating through a table row-by-row is very easy to script, easy to understand, and simple to modify. For anyone not too familiar with SQL query performance, it’s an easy trap to fall into for a variety of reasons:
就简单性而言,逐行遍历表非常容易编写脚本,易于理解且易于修改。 对于不太熟悉SQL查询性能的任何人来说,由于多种原因,这都是一个容易陷入的陷阱:
SQL Server is optimized for set-based queries. Iterative approaches require repetitive table access, which can be extremely slow and expensive.
SQL Server针对基于集合的查询进行了优化。 迭代方法需要重复的表访问,这可能非常缓慢且昂贵。
Iterative approaches are very fast for small row sets, leading us to the common mistake of accepting small-scale development data sets as indicative of large-scale production performance.
对于小行集,迭代方法非常快,这导致我们常犯一个错误,即接受小规模开发数据集作为大规模生产性能的指标。
Debugging and gauging performance can be difficult when a loop is repeating many, many times. Ie: in what iteration was it when something misbehaved, created bad data, or broke?
当循环重复很多次时,调试和测量性能可能会很困难。 即:什么时候行为不当,创建不良数据或损坏了?
The performance of a single iteration may be better than a set-based approach, but after some quantity of iterations, the sum of query costs will exceed that of getting everything in a single query.
单个迭代的性能可能比基于集合的方法更好,但是经过一定数量的迭代后,查询成本的总和将超过在单个查询中获取所有内容的总和。
Consider the following example of a cursor-based approach that builds a list of sales order ID numbers from a fairly selective query:
考虑以下基于游标的方法示例,该方法通过相当有选择性的查询构建销售订单ID号的列表:
DECLARE @Sales_Order_ID INT;
DECLARE @Sales_Order_Id_List VARCHAR(MAX) = '';
DECLARE Sales_Order_Cursor CURSOR FOR
SELECT
SalesOrderID
FROM Sales.SalesOrderHeader
WHERE Status = 5
AND OrderDate BETWEEN '1/1/2014' AND '2/1/2014'
AND TotalDue > 140000;
OPEN Sales_Order_Cursor;
FETCH NEXT FROM Sales_Order_Cursor INTO @Sales_Order_ID;
WHILE @@FETCH_STATUS = 0
BEGIN
SELECT @Sales_Order_Id_List = @Sales_Order_Id_List + CAST(@Sales_Order_ID AS VARCHAR(MAX)) + ',';
FETCH NEXT FROM Sales_Order_Cursor INTO @Sales_Order_ID;
END
SELECT @Sales_Order_Id_List = LEFT(@Sales_Order_Id_List, LEN(@Sales_Order_Id_List) - 1);
CLOSE Sales_Order_Cursor;
DEALLOCATE Sales_Order_Cursor;
SELECT @Sales_Order_Id_List AS Sales_Order_Id_List;
The above TSQL will declare a cursor that will be used to iterate through all sales order headers with a specific status, order date range, and total amount due. The cursor is then open and iterated through using a WHILE loop. At the end, we remove the trailing comma from our string-building and clean up the cursor object. The results are displayed as follows:
上面的TSQL将声明一个游标,该游标将用于遍历具有特定状态,订单日期范围和到期总额的所有销售订单标题。 然后打开游标,并使用WHILE循环对其进行迭代。 最后,我们从字符串构造中删除结尾的逗号,并清理游标对象。 结果显示如下:
We can see that the comma-separated list was generated correctly, and our ten IDs were returned as we wanted. Execution only took a few seconds, but that in of itself should be a warning sign: Why did a result set of ten rows against a not-terribly-large table take more than a few milliseconds? Let’s take a look at the STATISTICS IO metrics, as well as the execution plan for this script:
我们可以看到以逗号分隔的列表是正确生成的,并且我们根据需要返回了十个ID。 执行只花了几秒钟,但它本身应该是一个警告信号:为什么对一个不算大的表的十行结果集要花几毫秒以上的时间? 让我们看一下STATISTICS IO指标以及此脚本的执行计划:

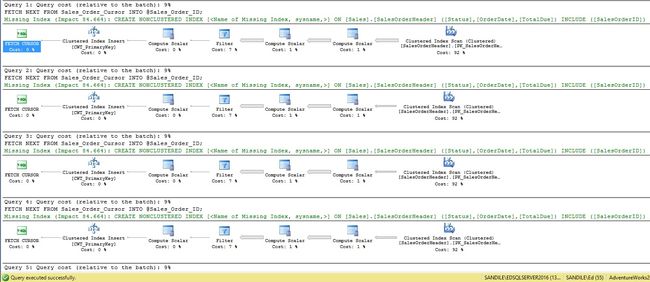
The execution plan is cut off, but you can be assured that there are six more similar plans below the ones pictured here. These metrics are misleading as each loop doesn’t seem too bad, right? Just 9% of the subtree cost or a few hundred reads doesn’t seem too wild, but add up all of these costs and it becomes clear that this won’t scale. What if we had thousands of rows to iterate through? For 5,000 rows, we would be looking at about 147,995,000 reads! Not to mention a very, very long execution plan that is certain to make Management Studio crawl as it renders five thousand execution plans.
执行计划已被切断,但是您可以放心,在此处所示的计划下方还有六个类似的计划。 这些指标会产生误导,因为每个循环看起来都还不错,对吧? 仅仅9%的子树成本或几百次读取看起来并不算太疯狂,但是将所有这些成本加起来,很明显,这不会扩展。 如果我们要遍历数千行怎么办? 对于5,000行,我们将查看大约147,995,000次读取! 更不用说一个非常非常长的执行计划,它肯定会使Management Studio爬行,因为它呈现了五千个执行计划。
Alternatively, we could cache all of the data in a temp table first, and then pull it row-by-row. This would result in significantly fewer reads on the underlying sales data, outperforming cursors by a mile, but would still involve iterating through the temp table over and over. For the scenario of 5,000 rows, we’d still have an inefficient slog through a smaller data set, rather than crawling through lots of data. Regardless of method, it’s still navigating quicksand either way, with varying amounts of quicksand.
另外,我们可以先将所有数据缓存在临时表中,然后逐行提取。 这将导致对基础销售数据的读取显着减少,性能比游标高出一英里,但是仍然需要反复遍历临时表。 对于5,000行的情况,我们仍然会通过较小的数据集进行低效率的搜索,而不是通过大量数据进行爬网。 无论采用哪种方法,它都仍会以不同的流沙量浏览流沙。
We can quickly illustrate this change as follows:
我们可以快速说明这种变化,如下所示:
DECLARE @Sales_Order_Id_List VARCHAR(MAX) = '';
DECLARE @Row_Count SMALLINT;
DECLARE @Current_Row_ID SMALLINT = 1;
CREATE TABLE #SalesOrderIDs
(Row_ID SMALLINT NOT NULL IDENTITY(1,1) CONSTRAINT PK_SalesOrderIDs_Temp PRIMARY KEY CLUSTERED, SalesOrderID INT NOT NULL);
INSERT INTO #SalesOrderIDs
(SalesOrderID)
SELECT
SalesOrderID
FROM Sales.SalesOrderHeader
WHERE Status = 5
AND OrderDate BETWEEN '1/1/2014' AND '2/1/2014'
AND TotalDue > 140000;
SELECT @Row_Count = @@ROWCOUNT;
WHILE @Current_Row_ID <= @Row_Count
BEGIN
SELECT @Sales_Order_Id_List = @Sales_Order_Id_List + CAST(SalesOrderID AS VARCHAR(MAX)) + ','
FROM #SalesOrderIDs
WHERE Row_ID = @Current_Row_ID;
SELECT @Current_Row_ID = @Current_Row_ID + 1;
END
SELECT @Sales_Order_Id_List = LEFT(@Sales_Order_Id_List, LEN(@Sales_Order_Id_List) - 1);
SELECT @Sales_Order_Id_List AS Sales_Order_Id_List;
DROP TABLE #SalesOrderIDs;
The resulting performance is better in that we only touch SalesOrderHeader once, but then hammer the temp table over and over. STATISTICS IO reveals the following:
这样产生的性能更好,因为我们只需触摸一次SalesOrderHeader ,然后反复敲击临时表。 统计IO显示了以下内容:

This is a bit better than before, but still ugly. The execution plan also looks better, but still far too many operations to be efficient:
这比以前要好一些,但仍然很丑。 执行计划看起来也更好,但是仍然有太多操作无法有效执行:
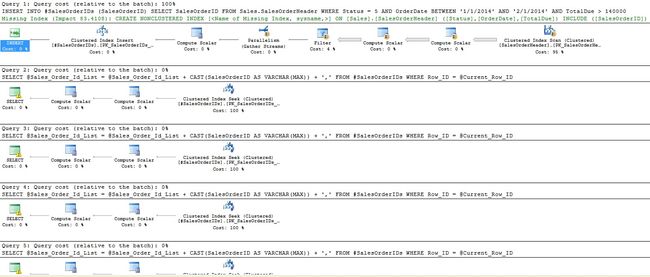
An iteration is universally a bad approach here, and one that will not scale well past the first few iterations. If you are building a delimited list, it is worth taking the time to avoid iteration and consider any other method to build a string. Nearly anything is more efficient than this and certainly less scary!
在这里,通常来说,迭代是一种不好的方法,并且在最初的几次迭代后,这种方法无法很好地扩展。 如果要构建定界列表,则值得花时间避免迭代并考虑使用任何其他方法来构建字符串。 几乎任何事情都比这更有效,当然也没有那么可怕!
XML字符串构建 (XML String-Building)
We can make some slick use of XML in order to build a string on-the-fly from the data retrieved in any query. While XML tends to be a CPU-intensive operation, this method allows us to gather the needed data for our delimited list without the need to loop through it over and over. One query, one execution plan, one set of reads. This is much easier to manage than what has been presented above. The syntax is a bit unusual, but will be explained below:
我们可以巧妙地使用XML,以便根据任何查询中检索到的数据即时构建字符串。 尽管XML往往是占用大量CPU的操作,但这种方法使我们能够为分隔列表收集所需的数据,而无需一遍又一遍地遍历它。 一个查询,一个执行计划,一组读取。 这比上面介绍的要容易得多。 语法有点不寻常,但下面将对其进行说明:
DECLARE @Sales_Order_Id_List VARCHAR(MAX) = '';
SELECT @Sales_Order_Id_List = STUFF((SELECT ',' + CAST(SalesOrderID AS VARCHAR(MAX))
FROM Sales.SalesOrderHeader
WHERE Status = 5
AND OrderDate BETWEEN '1/1/2014' AND '2/1/2014'
AND TotalDue > 140000
FOR XML PATH(''), TYPE).value('.', 'VARCHAR(MAX)'), 1, 1, '');
SELECT @Sales_Order_Id_List AS Sales_Order_Id_List;
In this script, we start with the list of SalesOrderID values as provided by the SELECT statement embedded in the middle of the query. From there, we add the FOR XML PATH(‘’) clause to the end of the query, just like this:
在此脚本中,我们从嵌入在查询中间的SELECT语句提供的SalesOrderID值列表开始。 从那里,我们将FOR XML PATH('')子句添加到查询的末尾,如下所示:
DECLARE @Sales_Order_Id_List VARCHAR(MAX) = '';
SELECT @Sales_Order_Id_List = (SELECT ',' + CAST(SalesOrderID AS VARCHAR(MAX))
FROM Sales.SalesOrderHeader
WHERE Status = 5
AND OrderDate BETWEEN '1/1/2014' AND '2/1/2014'
AND TotalDue > 140000
FOR XML PATH(''));
SELECT @Sales_Order_Id_List AS Sales_Order_Id_List;
The result of this query is almost there—we get a comma-separated list, but one with two flaws:
该查询的结果几乎存在,我们得到了一个用逗号分隔的列表,但其中有两个缺陷:
The obvious problem is the extra comma at the start of the string. The less obvious problem is that the data type of the output is indeterminate and based upon the various components of the SELECT statement. To resolve the data type, we add the TYPE option to the XML statement. STUFF is used to surreptitiously omit the comma. The leading comma can also be removed using RIGHT, as follows:
明显的问题是字符串开头的多余逗号。 不太明显的问题是输出的数据类型不确定,并且基于SELECT语句的各个组成部分。 为了解析数据类型,我们将TYPE选项添加到XML语句中。 STUFF用于秘密地省略逗号。 也可以使用RIGHT删除前导逗号,如下所示:
DECLARE @Sales_Order_Id_List VARCHAR(MAX) = '';
SELECT @Sales_Order_Id_List = (SELECT ',' + CAST(SalesOrderID AS VARCHAR(MAX))
FROM Sales.SalesOrderHeader
WHERE Status = 5
AND OrderDate BETWEEN '1/1/2014' AND '2/1/2014'
AND TotalDue > 140000
FOR XML PATH(''), TYPE).value('.', 'VARCHAR(MAX)');
SELECT @Sales_Order_Id_List = RIGHT(@Sales_Order_Id_List, LEN(@Sales_Order_Id_List) - 1);
SELECT @Sales_Order_Id_List AS Sales_Order_Id_List;
This is a bit easier to digest at least. So how does this XML-infused syntax perform? We benefit greatly from doing everything in a single TSQL statement, and the resulting STATISTICS IO data and execution plan are as follows:
至少这要容易一点。 那么,这种注入XML的语法如何执行? 通过在单个TSQL语句中完成所有操作,我们将受益匪浅,并且生成的STATISTICS IO数据和执行计划如下:


Well, that execution plan is a bit hard to read! Much of it revolves around the need to generate XML and then parse it, resulting in the desired comma-delimited list. While not terribly pretty, we are also done without the need to loop through an ID list or step through a cursor. Our reads are as low as they will get without adding any indexes to SalesOrderHeader to cover this query.
好吧,这个执行计划有点难以理解! 它大部分围绕生成XML然后解析它的需求,从而产生了所需的逗号分隔列表。 虽然不是很漂亮,但我们也不需要循环遍历ID列表或单步游标。 在不向SalesOrderHeader添加任何索引来覆盖此查询的情况下,读取的数据将尽可能少。
XML is a slick way to quickly generate a delimited list. It’s efficient on IO, but will typically result in high subtree costs and high CPU utilization. This is an improvement over iteration, but we can do better than this.
XML是一种快速生成分隔列表的巧妙方法。 它在IO上非常有效,但通常会导致较高的子树成本和较高的CPU使用率。 这是对迭代的一种改进,但是我们可以做得更好。
基于集合的字符串构建 (Set-Based String Building)
There exists a better option for building strings (regardless of how they are delimited or structured) that provides the best of both worlds: Low CPU consumption and low disk IO. A string can be built in a single operation by taking a string and building it out of columns, variables, and any static text you need to add. The syntax looks like this:
有一个更好的方法来构建字符串(无论它们如何定界或构造),这可以同时兼顾两个方面:低CPU消耗和低磁盘IO。 可以通过将一个字符串从列,变量和您需要添加的任何静态文本中构建出来,从而在单个操作中构建一个字符串。 语法如下所示:
DECLARE @Sales_Order_Id_List VARCHAR(MAX) = '';
SELECT @Sales_Order_Id_List = @Sales_Order_Id_List + CAST(SalesOrderID AS VARCHAR(MAX)) + ','
FROM Sales.SalesOrderHeader
WHERE Status = 5
AND OrderDate BETWEEN '1/1/2014' AND '2/1/2014'
AND TotalDue > 140000
SELECT @Sales_Order_Id_List = LEFT(@Sales_Order_Id_List, LEN(@Sales_Order_Id_List) - 1);
SELECT @Sales_Order_Id_List;
The start of this process is to start with a string and set it equal to some starting value. An empty string is used here, but anything could be inserted at the start of the string as a header, title, or starting point. We then SELECT the string equal to itself plus our tabular data plus any other string data we wish to add to it. The results are the same as our previous queries:
此过程的开始是从字符串开始,并将其设置为等于某个起始值。 这里使用一个空字符串,但是可以在字符串的开头插入任何内容作为标题,标题或起点。 然后,我们选择等于其自身的字符串,再加上我们的表格数据以及我们希望添加到其中的任何其他字符串数据。 结果与之前的查询相同:
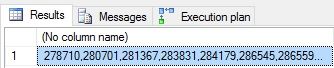
The SELECT statement is identical to what we would run if we were not building a string at all, except that we assign everything back to the list string declared above. Using this syntax, we can retrieve data by reading the table only as much as is needed to satisfy our query, and then build the string at the low cost of a COMPUTE SCALAR operator, which is typically SQL Server performing basic operations. In other words, no disk IO costs associated with it, and very minimal query cost/CPU/memory overhead.
SELECT语句与根本不构建字符串时执行的语句相同,只是将所有内容分配回上述声明的列表字符串。 使用这种语法,我们可以通过仅读取满足查询所需的表来检索数据,然后以COMPUTE SCALAR运算符的低成本构建字符串,该运算符通常是SQL Server执行基本操作。 换句话说,没有任何磁盘IO成本与之相关,并且查询成本/ CPU /内存开销非常小。
As we can see, the execution plan and STATISTICS IO both are simpler and come out as an all-around win in terms of performance:
如我们所见,执行计划和STATISTICS IO都更简单,并且在性能方面取得了全面的胜利:


The resulting execution plan is almost as simple as if we did not have any string building involved, and there is no need for worktables or other temporary objects to manage our operations.
生成的执行计划几乎就像我们没有涉及任何字符串构建一样简单,并且不需要工作表或其他临时对象来管理我们的操作。
This string-building syntax is fun to play with and remarkably simple and performant. Whenever you need to build a string from any sort of tabular data, consider this approach. The same technique can be used for building backup statements, assembling index or other maintenance scripts, or building dynamic SQL scripts for future execution. It’s versatile and efficient, and therefore being familiar with it will benefit any database professional.
这种构建字符串的语法很有趣,并且非常简单和高效。 每当您需要从任何类型的表格数据构建字符串时,请考虑使用此方法。 可以使用相同的技术来构建备份语句,组装索引或其他维护脚本,或构建动态SQL脚本以供将来执行。 它具有通用性和高效性,因此对其熟悉将使任何数据库专业人员受益。
解析定界数据 (Parsing Delimited Data)
The flip-side of what we demonstrated above is parsing and analyzing a delimited string. There exist many methods for pulling apart a comma-separated list, each of which has benefits and disadvantages to them. We’ll now look at a variety of methods and compare speed, resource consumption, and effectiveness.
我们上面演示的另一面是解析和分析定界字符串。 存在许多用于拆分以逗号分隔的列表的方法,每种方法都有其优点和缺点。 现在,我们将研究各种方法,并比较速度,资源消耗和有效性。
To help illustrate performance, we’ll use a larger comma-delimited string in our demonstrations. This will exaggerate and emphasize the benefits or pitfalls of the performance that we glean from execution plans, IO stats, duration, and query cost. The methods above had some fairly obvious results, but what we experiment with below may be less obvious, and require larger lists to validate. The following query (very similar to above, but more inclusive) will be used to generate a comma-delimited list for us to parse:
为了帮助说明性能,我们将在演示中使用较大的逗号分隔的字符串。 这将夸大并强调我们从执行计划,IO状态,持续时间和查询成本中收集的性能收益或陷阱。 上面的方法有一些相当明显的结果,但是我们下面的实验可能不太明显,需要更大的列表才能进行验证。 以下查询(与上面的查询非常相似,但包含更多内容)将用于生成逗号分隔的列表,供我们解析:
DECLARE @Sales_Order_Id_List VARCHAR(MAX) = '';
SELECT @Sales_Order_Id_List = @Sales_Order_Id_List + CAST(SalesOrderID AS VARCHAR(MAX)) + ','
FROM Sales.SalesOrderHeader
WHERE Status = 5
AND OrderDate BETWEEN '1/1/2014' AND '2/1/2014'
AND TotalDue > 50000
SELECT @Sales_Order_Id_List = LEFT(@Sales_Order_Id_List, LEN(@Sales_Order_Id_List) - 1);
SELECT @Sales_Order_Id_List;
This will yield 693 IDs in a list, which should provide a decent indicator of performance on a larger result set.
这将在列表中产生693个ID,这应该在较大的结果集上提供不错的性能指标。
迭代法 (The Iterative Method)
Once again, iteration is a method we can employ to take apart a delimited string. Our work above should already leave us skeptical as to its performance, but look around the SQL Server blogs and professional sites and you will see iteration used very often. It is easy to iterate through a string a deconstruct it, but we once again will need to evaluate
再一次,迭代是我们可以用来分割定界字符串的一种方法。 上面的工作应该已经使我们对其性能有所怀疑,但是看看SQL Server博客和专业站点,您会发现迭代使用非常频繁。 在字符串中进行迭代以对其进行解构很容易,但是我们将再次需要评估
CREATE TABLE #Sales_Order_Id_Results
(Sales_Order_Id INT NOT NULL);
DECLARE @Sales_Order_Id_Current INT;
WHILE @Sales_Order_Id_List LIKE '%,%'
BEGIN
SELECT @Sales_Order_Id_Current = LEFT(@Sales_Order_Id_List, CHARINDEX(',', @Sales_Order_Id_List) - 1);
SELECT @Sales_Order_Id_List = RIGHT(@Sales_Order_Id_List, LEN(@Sales_Order_Id_List) - CHARINDEX(',', @Sales_Order_Id_List));
INSERT INTO #Sales_Order_Id_Results
(Sales_Order_Id)
SELECT @Sales_Order_Id_Current
END
INSERT INTO #Sales_Order_Id_Results
(Sales_Order_Id)
SELECT @Sales_Order_Id_List
SELECT * FROM #Sales_Order_Id_Results;
DROP TABLE #Sales_Order_Id_Results;
This query takes the string and pulls out each ID from the left, one at a time, and then inserting it into the temp table we created at the top. The final insert grabs the last remaining ID that was left out of the loop. It takes quite a long time to run as it needs to loop 693 times in order to retrieve each value and add it to the temporary table. Our performance metrics show the repetitive nature of our work here:
该查询获取字符串,并从左侧一次提取每个ID,然后将其插入我们在顶部创建的临时表中。 最后的插入将获取循环之外剩余的最后一个ID。 运行需要很长时间,因为它需要循环693次才能检索每个值并将其添加到临时表中。 我们的绩效指标在这里显示了我们工作的重复性质:

This shows the first 5 of 693 iterations. Each loop may only require a single read in order to insert a new value to the temp table, but repeating that hundreds of times is time consuming. The execution plan is similarly repetitive:
这显示了693次迭代中的前5次。 每个循环可能只需要读取一次即可向临时表中插入新值,但是重复数百次非常耗时。 执行计划同样是重复的:

0% per loop is misleading as it’s only 1/693th of the total execution plan. Subtree costs, memory usage, CPU, cached plan size, etc…all are tiny, but when multiplied by 693, they become a bit more substantial:
每个环路0%是误导,因为它是唯一六百九十三分之一总执行计划的日 。 子树成本,内存使用率,CPU,缓存的计划大小等……都很小,但是乘以693,它们就会变得更加庞大:
693 Logical Reads
6.672 Query cost
6KB Data Written
10s Runtime (clean cache)
1s Runtime (subsequent executions)
693逻辑读取
6.672查询费用
写入6KB数据
10s运行时(干净的缓存)
1s运行时(后续执行)
An iterative approach has a linear runtime, that is for each ID we add to our list, the overall runtime and performance increases by whatever the costs are for a single iteration. This makes the results predictable, but inefficient.
迭代方法具有线性运行时间,即对于我们添加到列表中的每个ID,无论单个迭代花费多少成本,总体运行时间和性能都会增加。 这使结果可预测,但效率低下。
XML格式 (XML)
We can make use of XML again in order to convert a delimited string into XML and then output the parsed XML into our temp table. The benefits and drawbacks of using XML as described earlier all apply here. XML is relatively fast and convenient but makes for a messy execution plan and a bit more memory and CPU consumption along the way (as parsing XML isn’t free).
我们可以再次使用XML,以便将定界的字符串转换为XML,然后将解析的XML输出到我们的临时表中。 如前所述,使用XML的优缺点都适用于此。 XML相对较快且方便,但会导致执行计划混乱,并增加了更多的内存和CPU消耗(因为解析XML不是免费的)。
The basic method here is to convert the comma-separated list into XML, replacing commas with delimiting XML tags. Next, we parse the XML for each of the values delimited by those tags. From this point, the results go into our temp table and we are done. The TSQL to accomplish this is as follows:
此处的基本方法是将以逗号分隔的列表转换为XML,并用定界的XML标记替换逗号。 接下来,我们解析由这些标记分隔的每个值的XML。 至此,结果进入了我们的临时表,我们就完成了。 TSQL完成此操作的方法如下:
DECLARE @Sales_Order_idlist VARCHAR(MAX) = '';
SELECT @Sales_Order_idlist = @Sales_Order_idlist + CAST(SalesOrderID AS VARCHAR(MAX)) + ','
FROM Sales.SalesOrderHeader
WHERE Status = 5
AND OrderDate BETWEEN '1/1/2014' AND '2/1/2014'
AND TotalDue > 50000
SELECT @Sales_Order_idlist = LEFT(@Sales_Order_idlist, LEN(@Sales_Order_idlist) - 1);
CREATE TABLE #Sales_Order_Id_Results
(Sales_Order_Id INT NOT NULL);
DECLARE @Sales_Order_idlist_XML XML = CONVERT(XML, '' + REPLACE(@Sales_Order_idlist, ',', ' ') + ' ');
INSERT INTO #Sales_Order_Id_Results
(Sales_Order_Id)
SELECT
Id.value('.', 'INT') AS Sales_Order_Id
FROM @Sales_Order_idlist_XML.nodes('/Id') Sales_Order_idlist_XML(Id);
SELECT * FROM #Sales_Order_Id_Results;
DROP TABLE #Sales_Order_Id_Results;
The results of this query are the same as the iterative method, and will be identical to those of any demos we do here:
该查询的结果与迭代方法相同,并且将与我们在此处进行的任何演示的结果相同:
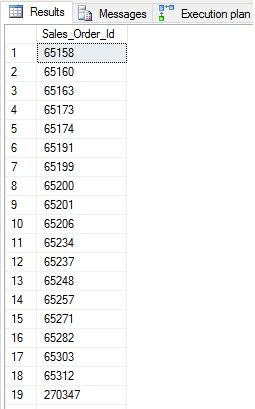
No surprises here, we get a list of 693 IDs that had been stored in the CSV we created earlier.
毫不奇怪,我们会得到一个693个ID的列表,这些ID已存储在我们先前创建的CSV中。
The performance metrics are as follows:
性能指标如下:


IO is about the same as earlier. Instead of paying that cost one-at-a-time, we do it all at once in order to load everything into the temporary table. The execution plan is more complex, but there is only one of them, which is quite nice!
IO与之前差不多。 为了一次将所有内容加载到临时表中,我们一次执行了所有操作,而不是一次支付这笔费用。 执行计划比较复杂,但是只有一个,这非常不错!
696 Logical Reads
136.831 Query cost
6KB Data Written
1s Runtime (clean cache)
100ms Runtime (subsequent executions)
696逻辑读取
136.831查询费用
写入6KB数据
1s运行时(干净的缓存)
100ms运行时间(后续执行)
This is a big improvement. Let’s continue and review other methods of string-splitting.
这是一个很大的改进。 让我们继续并回顾其他字符串拆分方法。
STRING_SPLIT (STRING_SPLIT)
Included in SQL Server 2016 is a long-requested function that will do all the work for you, and it’s called SPLIT_STRING(). The syntax is as simple as it gets, and will get us the desired results quickly:
SQL Server 2016中包括一个要求很长时间的功能,它将为您完成所有工作,它称为SPLIT_STRING() 。 语法非常简单,可以快速为我们提供所需的结果:
CREATE TABLE #Sales_Order_Id_Results
(Sales_Order_Id INT NOT NULL);
INSERT INTO #Sales_Order_Id_Results
(Sales_Order_Id)
SELECT * FROM STRING_SPLIT(@Sales_Order_idlist, ',');
SELECT * FROM #Sales_Order_Id_Results;
DROP TABLE #Sales_Order_Id_Results;
This is certainly the easiest way to split up a delimited list. How does performance look?
当然,这是拆分定界列表的最简单方法。 效果如何?


1396 Logical Reads
0.0233 Query cost
6KB Data Written
0.8s Runtime (clean cache)
90ms Runtime (subsequent executions)
1396逻辑读
0.0233查询成本
写入6KB数据
0.8s运行时(清理缓存)
90ms运行时(后续执行)
Microsoft’s built-in function provides a solution that is convenient and appears to perform well. It isn’t faster than XML, but it clearly was written in a way that provides an easy-to-optimize execution plan. Logical reads are higher, as well. While we cannot look under the covers and see exactly how Microsoft implemented this function, we at least have the convenience of a function to split strings that are shipped with SQL Server. Note that the separator passed into this function must be of size 1. In other words, you cannot use STRING_SPLIT with a multi-character delimiter, such as ‘”,”’.
Microsoft的内置功能提供了一种方便且看起来表现良好的解决方案。 它的速度并不比XML快,但是显然是以一种易于优化的执行计划的方式编写的。 逻辑读取也更高。 虽然我们不能完全了解Microsoft到底是如何实现此功能的,但是至少我们可以方便地使用该功能来拆分SQL Server附带的字符串。 请注意,传递给此函数的分隔符的大小必须为1。换句话说,您不能将STRING_SPLIT与多字符定界符(例如“”,“”)一起使用。
We can easily take any of our string-splitting algorithms and encapsulate them in a function, for convenience. This allows us to compare performance side-by-side for all of our techniques and compare performance. This also allows us to compare our solutions to STRING_SPLIT. I’ll include these metrics later in this article.
为了方便起见,我们可以轻松地采用任何字符串拆分算法并将其封装在一个函数中。 这使我们可以比较所有技术的性能并比较性能。 这也使我们可以将解决方案与STRING_SPLIT进行比较。 我将在本文后面介绍这些指标。
OPENJSON (OPENJSON)
Here is another new alternative that is available to us in SQL Server 2016. Our abuse of JSON parsing is similar to our use of XML parsing to get the desired results earlier. The syntax is a bit simpler, though there are requirements on how we delimit the text in that we must put each string in quotes prior to delimiting them. The entire set must be in square brackets.
这是SQL Server 2016中提供给我们的另一个新选择。我们对JSON解析的滥用与我们对XML解析的使用相似,以便更早地获得所需的结果。 语法稍微简单一些,尽管对如何定界文本有一些要求,因为在定界之前,必须将每个字符串都放在引号中。 整套必须放在方括号中。
SELECT @Sales_Order_idlist = '["' + REPLACE(@Sales_Order_idlist, ',', '","') + '"]';
CREATE TABLE #Sales_Order_Id_Results
(Sales_Order_Id INT NOT NULL);
INSERT INTO #Sales_Order_Id_Results
(Sales_Order_Id)
SELECT value FROM OPENJSON(@Sales_Order_idlist)
SELECT * FROM #Sales_Order_Id_Results;
DROP TABLE #Sales_Order_Id_Results;
Our first SELECT formats our string to conform to the expected syntax that OPENJSON expects. From there, our use of this operator is similar to how we used STRING_SPLIT to parse our delimited list. Since the output table contains 3 columns (key, value, and type), we do need to specify the value column name when pulling data from the output.
我们的第一个SELECT格式将字符串格式化为符合OPENJSON期望的语法。 从那里开始,我们对这个运算符的使用类似于我们使用STRING_SPLIT解析定界列表的方式。 由于输出表包含3列( key , value和type ),因此在从输出中提取数据时,我们确实需要指定value列名。
How does performance look for this unusual approach?
性能如何寻找这种不寻常的方法?


2088 Logical Reads
0.0233 Query cost
6KB Data Written
1s Runtime (clean cache)
40ms Runtime (subsequent executions)
2088逻辑读取
0.0233查询成本
写入6KB数据
1s运行时(干净的缓存)
40ms运行时间(后续执行)
This method of list-parsing took more reads than our last few methods, but the query cost is the same as if it were any other SQL Server function, and the runtime on all subsequent runs was the fastest yet (as low as 22ms, and as high as 50ms). It will be interesting to see how this scales from small lists to larger lists, and if it is a sneaky way to parse lists, or if there are hidden downsides that we will discover later on.
这种列表解析方法比最后几种方法读取的内容更多,但是查询成本与其他任何SQL Server函数相同,并且所有后续运行的运行时间是最快的(低至22ms,并且高达50ms)。 有趣的是,它会如何从小列表扩展到大列表,以及这是解析列表的偷偷摸摸的方式,还是我们稍后会发现隐藏的缺点。
递归CTE (Recursive CTE)
Recursion can be used to do a pseudo-set-based parse of a delimited list. We are limited by SQL Server’s recursion limit of 32,767, though I do sincerely hope that we don’t need to parse any lists longer than that!
递归可用于对定界列表进行基于伪集的解析。 我们受到SQL Server的32767递归限制的限制,尽管我真诚地希望我们不需要解析任何更长的列表!
In order to build our recursive solution, we begin by creating an anchor SELECT statement that pulls the location of the first delimiter in the TSQL, as well as a placeholder for the starting position. To make this TSQL a bit more reusable, I’ve included a @Delimiter variable, instead of hard-coding a comma.
为了构建递归解决方案,我们首先创建一个锚定SELECT语句,该语句提取TSQL中第一个定界符的位置以及起始位置的占位符。 为了使此TSQL更具可重用性,我添加了@Delimiter变量,而不是对逗号进行硬编码。
The second portion of the CTE returns the starting position of the next element in the list and the end of that element. An additional WHERE clause removes edge cases that would result in infinite recursion, namely the first and last elements in the list, which we only want/need to process a single time.
CTE的第二部分返回列表中下一个元素的起始位置和该元素的结尾。 附加的WHERE子句删除了会导致无限递归的边缘情况,即列表中的第一个元素和最后一个元素,我们只希望/需要处理一次。
The following TSQL illustrates this implementation:
以下TSQL说明了此实现:
CREATE TABLE #Sales_Order_Id_Results
(Sales_Order_Id INT NOT NULL);
IF @Sales_Order_idlist LIKE '%' + @Delimiter + '%'
BEGIN
WITH CTE_CSV_SPLIT AS (
SELECT
CAST(1 AS INT) AS Data_Element_Start_Position,
CAST(CHARINDEX(@Delimiter, @Sales_Order_idlist) - 1 AS INT) AS Data_Element_End_Position
UNION ALL
SELECT
CAST(CTE_CSV_SPLIT.Data_Element_End_Position AS INT) + LEN(@Delimiter),
CASE WHEN CAST(CHARINDEX(@Delimiter, @Sales_Order_idlist, CTE_CSV_SPLIT.Data_Element_End_Position + LEN(@Delimiter) + 1) AS INT) <> 0
THEN CAST(CHARINDEX(@Delimiter, @Sales_Order_idlist, CTE_CSV_SPLIT.Data_Element_End_Position + LEN(@Delimiter) + 1) AS INT)
ELSE CAST(LEN(@Sales_Order_idlist) AS INT)
END AS Data_Element_End_Position
FROM CTE_CSV_SPLIT
WHERE (CTE_CSV_SPLIT.Data_Element_Start_Position > 0 AND CTE_CSV_SPLIT.Data_Element_End_Position > 0 AND CTE_CSV_SPLIT.Data_Element_End_Position < LEN(@Sales_Order_idlist)))
INSERT INTO #Sales_Order_Id_Results
(Sales_Order_Id)
SELECT
REPLACE(SUBSTRING(@Sales_Order_idlist, Data_Element_Start_Position, Data_Element_End_Position - Data_Element_Start_Position + LEN(@Delimiter)), @Delimiter, '') AS Column_Data
FROM CTE_CSV_SPLIT
OPTION (MAXRECURSION 32767);
END
ELSE
BEGIN
INSERT INTO #Sales_Order_Id_Results
(Sales_Order_Id)
SELECT @Sales_Order_idlist AS Column_Data;
END
SELECT * FROM #Sales_Order_Id_Results;
DROP TABLE #Sales_Order_Id_Results;
This is definitely a more complex query, which leads us to ask if recursion is an efficient way to parse a delimited list. The following are the metrics for this approach for our current example list:
这绝对是一个更复杂的查询,这使我们问到递归是否是解析定界列表的有效方法。 以下是我们当前示例列表中此方法的指标:

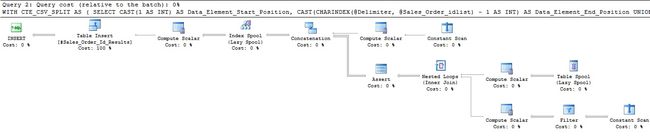
4853 Logical Reads
0.01002 Query cost
6KB Data Written
800ms Runtime (clean cache)
30ms Runtime (subsequent executions)
4853逻辑读取
0.01002查询费用
写入6KB数据
800ms运行时(清理缓存)
30ms运行时间(后续执行)
These are interesting metrics. More reads are necessary to support the worktable required by the recursive CTE, but all other metrics look to be an improvement. In addition to having a surprisingly low query cost, the runtime was very fast when compared to our previous parsing methods. I’d guess the execution plan is low-cost as there are only a small number of ways to optimize it when compared to other queries. Regardless of this academic guess, we have (so far) a winner for the most performant option.
这些是有趣的指标。 为了支持递归CTE所需的工作表,需要进行更多读取,但是所有其他度量指标似乎都是一种改进。 除了具有惊人的低查询成本外,与我们以前的解析方法相比,运行时非常快。 我猜执行计划是低成本的,因为与其他查询相比,只有很少的方法可以对其进行优化。 不管这种学术猜测如何,我们(到目前为止)都是性能最高的选择的获胜者。
At the end of this study, we’ll provide performance metrics for each method of string parsing for a variety of data sizes, which will help determine if some methods are superior for shorter or longer delimited lists, different data types, or more complex delimiters.
在研究结束时,我们将为各种数据大小的每种字符串解析方法提供性能指标,这将有助于确定某些方法对于较短或较长的定界列表,不同的数据类型还是更复杂的定界符是否优越。
理货单 (Tally Table)
In a somewhat similar fashion to the recursive CTE, we can mimic a set-based list-parsing algorithm by joining against a tally table. The begin this exercise in TSQL insanity, let’s create a tally table containing an ordered set of numbers. To make an easy comparison, we’ll make the number of rows equal to the maximum recursion allowed by a recursive CTE:
以某种类似于递归CTE的方式,我们可以通过加入一个计数表来模仿基于集合的列表解析算法。 从TSQL精神错乱开始本练习,让我们创建一个包含有序数字集的理货表。 为了进行简单的比较,我们将使行数等于递归CTE允许的最大递归:
CREATE TABLE dbo.Tally
( Tally_Number INT);
GO
SET STATISTICS IO OFF;
SET STATISTICS TIME OFF;
GO
DECLARE @count INT = 1;
WHILE @count <= 32767
BEGIN
INSERT INTO dbo.Tally
(Tally_Number)
SELECT @count;
SELECT @count = @count + 1;
END
GO
SET STATISTICS IO ON;
SET STATISTICS TIME ON;
This populates 32767 rows into Tally, which will serve as the pseudo-anchor for our next CTE solution:
这会将32767行填充到Tally中 ,这将用作我们下一个CTE解决方案的伪锚点:
CREATE TABLE #Sales_Order_Id_Results
(Sales_Order_Id INT NOT NULL);
SELECT @Sales_Order_idlist = LEFT(@Sales_Order_idlist, LEN(@Sales_Order_idlist) - 1);
DECLARE @List_Length INT = DATALENGTH(@Sales_Order_idlist);
WITH CTE_TALLY AS (
SELECT TOP (@List_Length) ROW_NUMBER() OVER (ORDER BY (SELECT 1)) AS Tally_Number FROM dbo.Tally),
CTE_STARTING_POINT AS (
SELECT 1 AS Tally_Start
UNION ALL
SELECT
Tally.Tally_Number + 1 AS Tally_Start
FROM dbo.Tally
WHERE SUBSTRING(@Sales_Order_idlist, Tally.Tally_Number, LEN(@Delimiter)) = @Delimiter),
CTE_ENDING_POINT AS (
SELECT
CTE_STARTING_POINT.Tally_Start,
CHARINDEX(@Delimiter, @Sales_Order_idlist, CTE_STARTING_POINT.Tally_Start) - CTE_STARTING_POINT.Tally_Start AS Element_Length,
CASE WHEN CHARINDEX(@Delimiter, @Sales_Order_idlist, CTE_STARTING_POINT.Tally_Start) IS NULL THEN 0
ELSE CHARINDEX(@Delimiter, @Sales_Order_idlist, CTE_STARTING_POINT.Tally_Start)
END - ISNULL(CTE_STARTING_POINT.Tally_Start, 0) AS Tally_End
FROM CTE_STARTING_POINT)
INSERT INTO #Sales_Order_Id_Results
(Sales_Order_Id)
SELECT
CASE WHEN Element_Length > 0
THEN SUBSTRING(@Sales_Order_idlist, CTE_ENDING_POINT.Tally_Start, CTE_ENDING_POINT.Element_Length)
ELSE SUBSTRING(@Sales_Order_idlist, CTE_ENDING_POINT.Tally_Start, @List_Length - CTE_ENDING_POINT.Tally_Start + 1)
END AS Sales_Order_Id
FROM CTE_ENDING_POINT;
SELECT * FROM #Sales_Order_Id_Results;
DROP TABLE #Sales_Order_Id_Results;
This set of CTEs performs the following actions:
这套CTE执行以下操作:
Builds a CTE with numbers from the tally table, counting only up to the total data length of our list.
使用理货表中的数字构建CTE,仅计算列表中的总数据长度。
Build a CTE set of starting points that indicate where each list element starts.
建立一组CTE起点,以指示每个列表元素的起点。
Build a CTE set of ending points that indicate where each list element ends and the length of each.
建立一组CTE端点,以指示每个列表元素的结尾以及每个元素的长度。
Perform arithmetic on those numbers to determine the contents of each list element.
对这些数字执行算术运算,以确定每个列表元素的内容。
The CASE statement near the end handles the single edge case for the last element in the list, which would otherwise return a negative number for the end position. Since we know the length of the overall list, there’s no need for this calculation anyway.
末尾的CASE语句处理列表中最后一个元素的单边情况,否则将为结束位置返回负数。 由于我们知道整个列表的长度,因此无论如何都不需要进行此计算。
Here are the performance metrics for this awkward approach to delimited list-splitting:
这是此笨拙的分隔列表拆分方法的性能指标:


The bulk of reads on this operation comes from the scan on Tally. The execution plan is surprisingly simple for TSQL that appears even more complex than the recursive CTE. How do the remaining metrics stack up?
对该操作的大量读取来自Tally上的扫描。 对于TSQL,执行计划非常简单,看起来比递归CTE还要复杂。 其余指标如何堆叠?
58 Logical Reads
0.13915 Query cost
6KB Data Written
1s Runtime (clean cache)
40ms Runtime (subsequent executions)
58逻辑读
0.13915查询费用
写入6KB数据
1s运行时(干净的缓存)
40ms运行时间(后续执行)
While the query cost is evaluated as higher, all other metrics look quite good. The runtime is not better than recursion in this case but is very close to being as fast. The bulk of speed of this operation comes from the fact that everything can be evaluated in-memory. The only logical reads necessary are to the tally table, after which SQL Server can crunch the remaining arithmetic quickly and efficiently as any computer is able to.
虽然查询成本被评估为较高,但所有其他指标看起来都不错。 在这种情况下,运行时并不比递归好,但是非常快。 此操作的主要速度来自于所有内容都可以在内存中进行评估的事实。 唯一必要的逻辑读取是对理货单进行记录,此后,SQL Server可以像任何计算机一样快速,高效地处理剩余的算术运算。
性能比较 (Performance Comparison)
In an effort to provide more in-depth performance analysis, I’ve rerun the tests from above on a variety of list lengths and combinations of data types. The following are the tests performed:
为了提供更深入的性能分析,我从上面对各种列表长度和数据类型组合重新运行了测试。 以下是执行的测试:
List of 10 elements, single-character delimiter. List is VARCHAR(100).
10个元素的列表,单字符定界符。 列表为VARCHAR(100)。
List of 10 elements, single-character delimiter. List is VARCHAR(MAX).
10个元素的列表,单字符定界符。 列表为VARCHAR(MAX)。
List of 500 elements, single-character delimiter. List is VARCHAR(5000).
500个元素的列表,单字符定界符。 列表为VARCHAR(5000)。
List of 500 elements, single-character delimiter. List is VARCHAR(MAX).
500个元素的列表,单字符定界符。 列表为VARCHAR(MAX)。
List of 10000 elements, single-character delimiter. List is VARCHAR(MAX).
10000个元素的列表,单字符定界符。 列表为VARCHAR(MAX)。
List of 10 elements, 3-character delimiter. List is VARCHAR(100).
10个元素的列表,3个字符的分隔符。 列表为VARCHAR(100)。
List of 10 elements, 3-character delimiter. List is VARCHAR(MAX).
10个元素的列表,3个字符的分隔符。 列表为VARCHAR(MAX)。
List of 500 elements, 3-character delimiter. List is VARCHAR(5000).
500个元素的列表,3个字符的分隔符。 列表为VARCHAR(5000)。
List of 500 elements, 3-character delimiter. List is VARCHAR(MAX).
500个元素的列表,3个字符的分隔符。 列表为VARCHAR(MAX)。
List of 10000 elements, 3-character delimiter. List is VARCHAR(MAX).
10000个元素的列表,3个字符的分隔符。 列表为VARCHAR(MAX)。
The results are attached in an Excel document, including reads, query cost, and average runtime (no cache clear). Note that execution plans were turned off when testing duration, in order to prevent their display from interfering with timing. Duration is calculated as an average of 10 trials after the first (ensuring the cache is no longer empty). Lastly, the temporary table was omitted for all methods where it wasn’t needed, to prevent IO noise writing to it. The only one that requires it is the iteration, as it’s necessary to write to the temp table on each iteration in order to save results.
结果附在Excel文档中 ,包括读取,查询成本和平均运行时间(不清除缓存)。 请注意,在测试持续时间时,将关闭执行计划,以防止其显示干扰时间。 计算的持续时间是第一次执行后平均进行10次尝试(确保缓存不再为空)。 最后,为了避免IO噪音写入临时表,所有不需要它的方法都被省略。 唯一需要它的是迭代,因为有必要在每次迭代中写入temp表以保存结果。
The numbers reveal that the use of XML, JSON, and STRING_SPLIT consistently outperform other methods. Oftentimes, the metrics for STRING_SPLIT are almost identical to the JSON approach, including the query cost. While the innards of STRING_SPLIT are not exposed to the end user, this leads me to believe that some string-parsing method such as this was used as the basis for building SQL Server’s newest string function. The execution plan is nearly identical as well.
数字显示,使用XML,JSON和STRING_SPLIT始终优于其他方法。 通常,STRING_SPLIT的指标与JSON方法几乎相同,包括查询成本。 尽管STRING_SPLIT的内幕没有暴露给最终用户,但是这使我相信,诸如此类的某些字符串解析方法被用作构建SQL Server最新字符串函数的基础。 执行计划也几乎相同。
There are times where CTEs perform well but under a variety of conditions, such as when a VARCHAR(MAX) is used, or when the delimiter becomes larger than 1 character, performance falls behind other methods. As noted earlier, if you would like to use a delimiter longer than 1 character, STRING_SPLIT will not be of help. As such, trials with 3-character delimiters were not run for this function.
有时CTE的性能很好,但是在多种条件下(例如,使用VARCHAR(MAX)或分隔符大于1个字符时),其性能会落后于其他方法。 如前所述,如果您要使用超过1个字符的分隔符,则STRING_SPLIT将无济于事。 因此,没有对此功能使用3个字符分隔符的试验。
Duration is ultimately the true test for me here, and I weighted it heavily in my judgment. If I can parse a list in 10ms versus 100ms, then a few extra reads or bits of CPU/memory use is of little concern to me. It is worth noting that there is some significance to methods that require no disk IO. CTE methods require worktables, which reside in TempDB and equate to disk IO when needed. XML, JSON, and STRING_SPLIT occur in memory and therefore require no interaction with TempDB.
在这里,持续时间最终是对我的真正考验,我在自己的判断中对其进行了加权。 如果我可以在10ms到100ms的时间内解析一个列表,那么我不需要担心一些额外的读取或CPU /内存使用量。 值得注意的是,不需要磁盘IO的方法有一些意义。 CTE方法需要工作表,这些工作表位于TempDB中,并且在需要时等同于磁盘IO。 XML,JSON和STRING_SPLIT出现在内存中,因此不需要与TempDB进行交互。
As expected, the iterative method of string parsing is the ugliest, requiring IO to build a table, and plenty of time to crawl through the string. This latency is most pronounced when a longer list is parsed.
不出所料,字符串解析的迭代方法是最丑陋的,需要IO来构建表,并且需要大量时间来爬网字符串。 当解析较长的列表时,此延迟最明显。
结论 (Conclusion)
There are many ways to build and parse delimited lists. While some are more or less creative than others, there are some definitive winners when it comes to performance. STRING_SPLIT performs quite well—kudos to Microsoft for adding this useful function and tuning it adequately. JSON and XML parsing, though, also perform adequately—sometimes better than STRING_SPLIT. Since the query cost & CPU consumption of XML are consistently less than the other 2 methods mentioned here, I’d recommend either JSON or STRING_SPLIT over the others. If a delimiter longer than 1 character is required, then STRING_SPLIT is eliminated as longer delimiters are not allowed for the separator parameter. The built-in nature of STRING_SPLIT is handy but leaves absolutely no room for customization.
有很多方法可以构建和解析定界列表。 尽管有些人比其他人或多或少具有创造力,但在表现方面还是有一些绝对的赢家。 STRING_SPLIT的性能非常好-对于Microsoft添加此有用的功能并进行适当调优表示感谢。 但是,JSON和XML解析也可以正常执行-有时比STRING_SPLIT更好。 由于XML的查询成本和CPU消耗始终少于这里提到的其他两种方法,因此我建议使用JSON或STRING_SPLIT而不是其他方法。 如果需要一个大于1个字符的定界符,则将STRING_SPLIT删除,因为分隔符参数不允许使用更长的定界符。 STRING_SPLIT的内置特性很方便,但绝对没有自定义空间。
There are other ways to parse lists that are not presented here. If you have one and believe it can outperform everything here, let me know and I’ll run it through a variety of tests to see where it falls.
还有其他解析列表的方法,此处未介绍。 如果您有一个,并且相信它可以胜过这里的一切,请告诉我,我将通过各种测试来测试它的出处。
参考资料和进一步阅读 (References and Further Reading)
Many of these methods I’ve been playing with for years, while others are brand new in SQL Server 2016. Some have been explored in other blogs or Microsoft documentation, and for any that have seen attention elsewhere, I’ve made it a point to get creative and find newer, simpler, or more performant ways to manage them. Here are some references for the built-in functions used:
我使用了许多年的方法,而其他方法是SQL Server 2016中的全新方法。一些方法已在其他博客或Microsoft文档中进行了探讨,对于在其他地方引起关注的任何方法,我都说得很对。获得创造力并找到更新,更简单或更高性能的方式来管理它们。 以下是所用内置函数的一些参考:
Documentation on OPENJSON:
OPENJSON上的文档:
- OPENJSON (Transact-SQL) OPENJSON(Transact-SQL)
Information on XML, both for parsing and list building:
有关XML的信息,用于解析和列表构建:
- xml (Transact-SQL) xml(Transact-SQL)
- nodes() Method (xml Data Type) nodes()方法(xml数据类型)
Documentation on the new STRING_SPLIT function:
有关新的STRING_SPLIT函数的文档:
- STRING_SPLIT (Transact-SQL) STRING_SPLIT(Transact-SQL)
Also, my book, Dynamic SQL: Applications, Performance, and Security has a chapter that delves into list-building and provides significantly more detail and script options than was presented here:
另外,我的书《动态SQL:应用程序,性能和安全性》有一章专门研究列表构建,并且比此处介绍的内容提供了更多的详细信息和脚本选项:
- Dynamic SQL: Applications, Performance, and Security 动态SQL:应用程序,性能和安全性
翻译自: https://www.sqlshack.com/efficient-creation-parsing-delimited-strings/
json解析和字符串解析