Hadoop基础知识笔记
该文为个人学习笔记,仅供参考。
更多内容关注本人Halo1博客
Hadoop概述
概述
Hadoop是一个由Apache基金会所开发的分布式系统基础架构。
用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行高速运算和存储。
Apache Hadoop 原本来源于 Google 一款名为MapReduce的编程模型包。
GFS -> HDFS
MapReduce -> MapReduce
BigTable -> HBase
Hadoop主要组成
-
Hadoop Common:为其他Hadoop模块提供基础设施。
-
Hadoop HDFS:一个高可靠、高吞吐量的分布式文件系统。
- 分布式
- 安全性
- 副本数据
-
Hadoop MapReduce:一个分布式的离线并行计算框架。
-
分布式
-
思想
-
分而治之
大数据集分为小的数据集
每个数据集,进行逻辑业务处理(map)
合并统计数据结果(reduce)
-
-
-
Hadoop YARN:一个新的MapReduce框架,任务调度与资源管理。
分布式资源管理框架
- 管理整个集群的资源(内存、CPU核数)
- 分配调度集群的资源
HDFS 分布式文件系统
HDFS架构
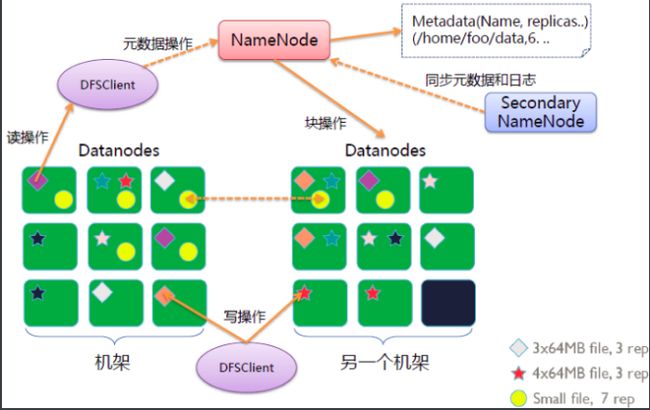
NameNode 用于保存元数据,处理客户端请求 管理节点
管理文件系统的命名空间。维护着文件系统树及整棵树内所有的文件和目录。这些信息以命名空间镜像文件和编辑日志文件的形式永久保存在本地磁盘上。
Client 发起请求
代表用户通过namenode和datanode交互来访问整个文件系统。提供文件系统接口。
DataNode 保存具体数据
文件系统的工作节点。他们根据需要存储并检索数据块(受客户端或namenode调度)。
SecondaryNode 用于同步元数据,
HDFS没有namenode将无法运行。所以secondarynode作为第二名称节点,用来监控HDFS状态的辅助后台程序,每隔一段时间获取HDFS元数据的快照。
Hadoop读写流程
HDFS写操作
-
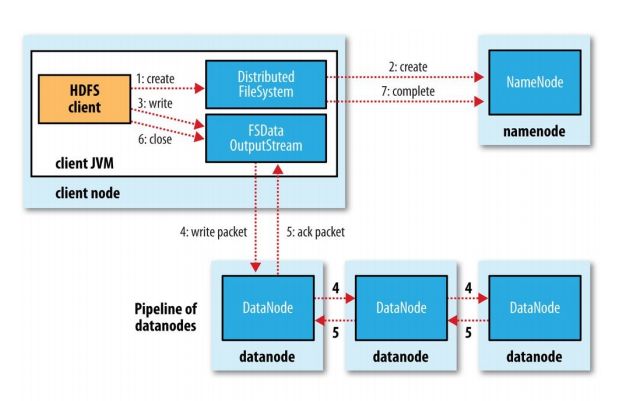
客户端向Namenode发起写操作请求,Namenode检查文件是否存在并检查权限,如果存在,则返回exist,不能上传,不可覆盖,如果不存在,那么Namenode会创建一个临时文件用于存储。
-
Namenode放置副本并遵循就近原则,即如果客户端在该集群且有Datanode节点,那么优先在该节点放置第一块副本,再将另外两块副本放置到另外两台Datanode(文件副本数通常为3,可根据需求及集群性能自定义),并根据距离排序,将Datanode列表返回给客户端。
如果为多集群,假定3个集群,则每个集群中一台Datanode节点保存一份副本
-
客户端根据Namenode返回的Datanode列表连接第一个节点,且第一个节点与其余两个节点根据顺序保持串联连接关系,这种并联连接关系被成为Pipeline(管道)连接。
-
客户端将文件切分成block(block默认128MB)
在写入过程中,block又被切分成package(默认为64KB),以流式向DataNode写入block文件。
-
Datanode各节点每传输完一个block后,会返回验证信息
每次验证是在写完一个block后,并非在传输package完成时
-
完成文件写入,关闭输出流。
-
发送完成信号给Namenode
在传输过程中,其中一个Datanode挂掉了,Namenode会在整个流程结束,收集并验证Datanode的信息,发现此文件的副本数没有达到要求,则将挂掉的datanode移出Pipeline,然后再寻找另一个可用Datanode节点保存副本
HDFS读操作
-
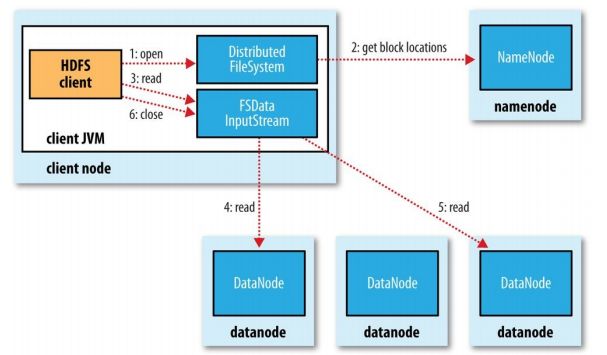
客户端发起向Namenode读请求并获取元数据信息。
-
客户端根据Namenode返回的信息,就近选择Datanode节点并与各个节点建立输入流。
-
Datanode向输入流中写数据。
-
客户端下载完成block后验证,保证块数据的完整性。
就近原则:本地,最近的距离;同机架,次之的距离;other(数据中心),最远的距离;
HDFS启动流程
心跳机制
namenode从集群中的每个datanode接收心跳信号和快状态报告(Blockreport)。
-
接收心跳信号
默认每3秒一次,表示改datanode节点工作正常
心跳返回结果带有namenode给该datanode的命令,如复制删除等等。
超过10分钟namenode没有收到某个datanode的心跳,则认为该节点不可用。
-
块状态报告
datanode启动后,向namenode注册,周期性(1小时)的向namenode报告块信息。
- 数据损坏处理
block创建时会产生checksum,当datanode读取block的时候,它会重新计算得到checksum,如果与初始checksum不同,则说明该block已经损坏,Client读取其他datanode上的block。那么弄得标记该块已损坏,复制block以达到预期的副本数量。
- Namenode元数据合并同步
NameNode的元数据操作先往edits文件中写,
当edits文件达到一定的阈值(3600秒或一定的事务数量)的时候,会开启合并的流程。
合并流程:
1.当开始合并的时候,SecondaryNameNode会把edits和fsimage拷贝到所在服务器所在内存中,合并生成名为fsimage.ckpt的文件。
2.将fsimage.ckpt文件拷贝到NameNode上,删除原有的fsimage,并将fsimage.ckpt重命名为fsimage。
3.当SecondaryNameNode将edits和fsimage拷贝走之后, NameNode会立刻生成一个edits.new文件,用于记录新来的元数据,当合并完成之后,原有的edits文件才会被删除,并将edits.new文件重命名为edits文件。
- 在达到一定阈值 开启下一轮合并,只拷贝edits文件。
启动流程
- 启动HDFS相关进程,进入安全模式(只读不写)
- 加载元数据,namenode等待datanode注册
- datanode周期性的向namenode发送心跳
- 离开安全模式
Yarn集群资源管理系统
Yarn架构
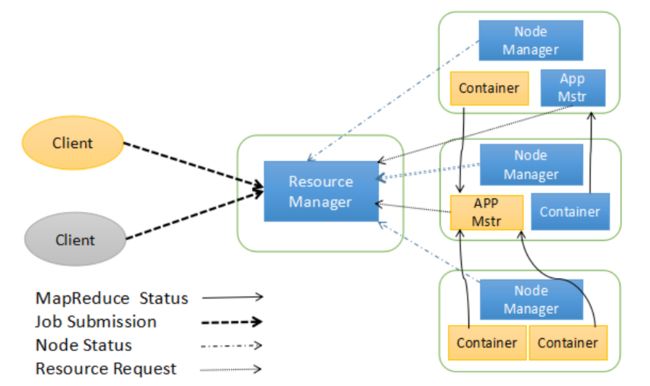
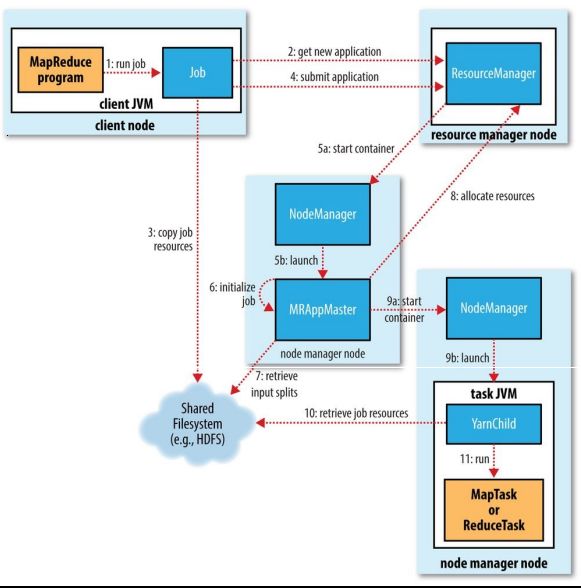
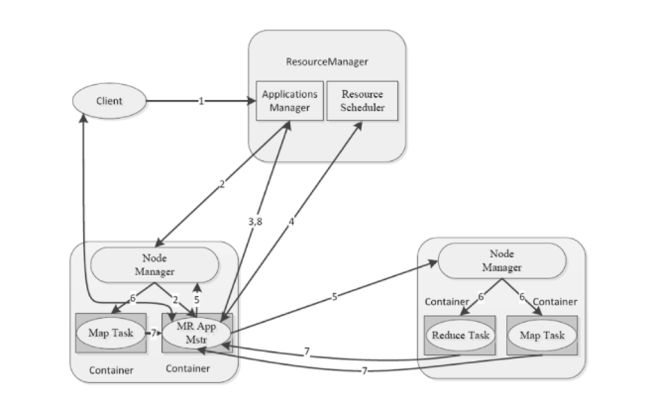
ResourceManger 任务的调度和资源的管理(CPU、内存)管理集群上资源使用的资源管理器。
Container 对环境的抽象,封装了CPU,内存,环境变量等等多维的资源。运行在集群中所有节点上且能够启动和监控的容器。
NodeManger 单个节点的资源管理,节点管理器
application master 为任务程序申请资源,任务的监控和容错
Yarn运行机制
MapReduce编程模型
概述
MapReduce应用广泛的原因之一就是其易用性,提供了一个高度抽象画二变得非常简单的编程模型,他是总结大量应用的共同特点的基础上抽象出来的分布式计算框架,在其编程模型中,任务可以被分解成相互独立的子问题。任务过程分为两个处理阶段:map阶段和reduce阶段。每阶段都以键-值对作为输入和输出,其数据类型可自定义,需要编写map和reduce函数。
MapReduce作业(job)是客户端需要执行的一个工作单元:它包括输入数据、MapReduce程序和配置信息。Hadoop将作业分成若干个任务(task)来执行,其中包括两类任务:map任务和reduce任务。
MapReduce编程模型给出分布式编程方法的5个步骤:
- 迭代,遍历输入数据,将其解析成key/value对;
- 将输入key/value对映射map成另外一些key/value对;
- 根据key对中间结果进行分组(grouping);
- 以组为单位对数据进行归约;
- 迭代,将最终产生的key/value对保存到输出文件中。
过程及作用
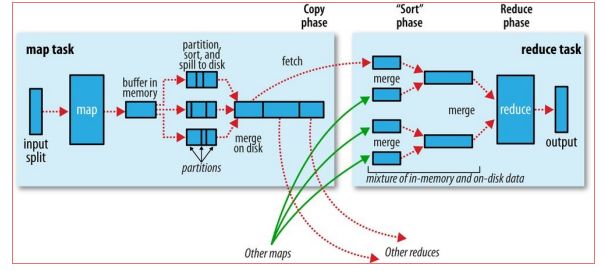
执行顺序:InputFormat - OutputFormat - Map - Shuffle - Reduce
InputFormat
OutputFormat
Map
Reduce
Shuffle
Map Shuffle Phase
-
进入环形缓冲区(默认100MB)
默认情况下,当达到环形缓冲区内存的80%,将会将缓冲区中的数据spill到本地磁盘中(溢出到MapTask所运行的NodeManager机器的本地磁盘中)
-
溢写 并不是立即将缓冲区中的数据溢写到本地磁盘,而是需要经历一些操作
- 分区paritioner
分区决定Map Task输出的数据进入哪个Reduce,且分区数量等同于Reduce数量。
默认情况下,key采用HashParitioner
-
自定义Paritioner用途
解决数据倾斜:另一种需要我们自己定义一个Partitioner的情况是各个Reduce task处理的键值对数量极不平衡。对于某些数据集,由于很多不同的key的hash值都一样,导致这些键值对都被分给同一个Reducer处理,而其他的Reducer处理的键值对很少,从而拖延整个任务的进度。当然,编写自己的Partitioner必须要保证具有相同key值的键值对分发到同一个Reducer。
-
对于map输出的每一个键值对,系统都会给定一个partition,partition值默认通过计算key的hash值后对Reduce task的数量取模获得。如果一个键值对的partition值为1,意味着这个键值对会交给第一个Reducer处理。
//HashPartitioner int getParitition(key, value, numreducetask) { return ( key.hashCode&Integer.maxValue)%numreducetask; } -
排序sorter
会对每个分区中的数据进行排序,默认情况下依据key进行排序。
-
spill溢写
将分区排序后的数据写到本地磁盘的一个文件中,重复上述操作,产生多个小文件。
-
-
当溢写结束后
[可选]combiner:Map端的reduce,在分区前
[可选]compress:减少数据量,减少网络IO处理,但压缩消耗CPU性能,也需要时间。
Reduce Shuffle Phase
Reduce端的shuffle主要包括三个阶段,copy,sort(merge),reduce
- Copy
- 排序(merge)
- 分组group
Map-side tuning properties
| Property name | Type | Default value | Description |
|---|---|---|---|
| mapreduce.task.io.sort.mb | int | 100 | The size, in megabytes, of the memory buffer to use while sorting map output. |
| mapreduce.map.sort.spill.percent | float | 0.80 | The threshold usage proportion for both the map output memory buffer and the record boundaries index to start the process of spilling to disk. |
| mapreduce.task.io.sort.facto | int | 10 | The maximum number of streams to merge at once when sorting files. This property is also used in the reduce. It’s fairly common to increase this to 100. |
| mapreduce.map.combine.minspills | int | 3 | The minimum number of spill files needed for the combiner to run (if a combiner is specified). |
| mapreduce.map.output.compress | boolean | false | Whether to compress map outputs. |
| mapreduce.map.output.compress.codec | Class name | org.apache.hadoop.io.compress.DefaultCodec | The compression codec to use for map outputs. |
| mapreduce.shuffle.max.threads | int | 0 | The number of worker threads per node manager for serving the map outputs to reducers. This is a clusterwide setting and cannot be by individual jobs. 0 means use the Netty default of twice the number of available processors. |
Reduce-side tuning properties
| Property name | Type | Default value | Description |
|---|---|---|---|
| mapreduce.reduce.shuffle.parallelcopies | int | 5 | The number of threads used to copy map outputs to the reducer. |
| mapreduce.reduce.shuffle.maxfetchfailures | int | 10 | The number of times a reducer tries to fetch a map output before reporting the error. |
| mapreduce.task.io.sort.factor | int | 10 | The maximum number of streams to merge at once when sorting files. This property is also used in the map. |
| mapreduce.reduce.shuffle.input.buffer.percent | float | 0.70 | The proportion of total heap size to be allocated to the map outputs buffer during the copy phase of the shuffle. |
| mapreduce.reduce.shuffle.merge.percent | float | 0.66 | The threshold usage proportion for the map outputs buffer (defined by mapred.job.shuffle.input.buffer.percent)for starting the process of merging the outputs and spilling to disk. |
| mapreduce.reduce.merge.inmem.threshol | int | 1000 | The threshold number of map outputs for starting the process of merging the outputs and spilling to disk. A value of 0 or less means there is no threshold, and the spill behavior is governed solely by mapreduce.reduce.shuffle.merge.percent. |
| mapreduce.reduce.input.buffer.percent | float | 0.0 | The proportion of total heap size to be used for retaining map outputs in memory during the reduce. For the reduce phase to begin, the size of map outputs in memory must be no more than this size. By default, all map outputs are merged to disk before the reduce begins, to give the reducers as much memory as possible. However, if your reducers require less memory,this value may be increased to minimize the number of trips to disk |
附录
集群架构设计示例:
| master | slave1 | slave2 | slave3 | |
|---|---|---|---|---|
| HDFS | datanode | datanode | datanode | |
| namenode 9820 | secondaryNamenode | |||
| namenode web 9870 | secondaryNamenode web 9868 | |||
| Yarn | nodemanager | nodemanager | nodemanager | |
| resourcemanager | resourcemanager | |||
| resourcemanager web 8088 | ||||
| 历史服务 | HistroryServer 10020 | |||
| HistroryServer web 19888 |
服务端口
2.x、3.x版本端口差别
摘自网络
| 分类 | 应用 | Haddop 2.x port | Haddop 3 port |
|---|---|---|---|
| NNPorts | Namenode | 8020 | 9820 |
| NNPorts | NN HTTP UI | 50070 | 9870 |
| NNPorts | NN HTTPS UI | 50470 | 9871 |
| SNN ports | SNN HTTP | 50091 | 9869 |
| SNN ports | SNN HTTP UI | 50090 | 9868 |
| DN ports | DN IPC | 50020 | 9867 |
| DN ports | DN | 50010 | 9866 |
| DN ports | DN HTTP UI | 50075 | 9864 |
| DN ports | Namenode | 50475 | 9865 |
| 组件 | 节点 | 默认端口 | 配置 | 用途说明 |
|---|---|---|---|---|
| HDFS | DataNode | 50010 | dfs.datanode.address | datanode服务端口,用于数据传输 |
| HDFS | DataNode | 50075 | dfs.datanode.http.address | http服务的端口 |
| HDFS | DataNode | 50475 | dfs.datanode.https.address | https服务的端口 |
| HDFS | DataNode | 50020 | dfs.datanode.ipc.address | ipc服务的端口 |
| HDFS | NameNode | 50070 | dfs.namenode.http-address | http服务的端口 |
| HDFS | NameNode | 50470 | dfs.namenode.https-address | https服务的端口 |
| HDFS | NameNode | 8020 | fs.defaultFS | 接收Client连接的RPC端口,用于获取文件系统metadata信息。 |
| HDFS | journalnode | 8485 | dfs.journalnode.rpc-address | RPC服务 |
| HDFS | journalnode | 8480 | dfs.journalnode.http-address | HTTP服务 |
| HDFS | ZKFC | 8019 | dfs.ha.zkfc.port | ZooKeeper FailoverController,用于NN HA |
| YARN | ResourceManager | 8032 | yarn.resourcemanager.address | RM的applications manager(ASM)端口 |
| YARN | ResourceManager | 8030 | yarn.resourcemanager.scheduler.address | scheduler组件的IPC端口 |
| YARN | ResourceManager | 8031 | yarn.resourcemanager.resource-tracker.address | IPC |
| YARN | ResourceManager | 8033 | yarn.resourcemanager.admin.address | IPC |
| YARN | ResourceManager | 8088 | yarn.resourcemanager.webapp.address | http服务端口 |
| YARN | NodeManager | 8040 | yarn.nodemanager.localizer.address | localizer IPC |
| YARN | NodeManager | 8042 | yarn.nodemanager.webapp.address | http服务端口 |
| YARN | NodeManager | 8041 | yarn.nodemanager.address | NM中container manager的端口 |
| YARN | JobHistory Server | 10020 | mapreduce.jobhistory.address | IPC |
| YARN | JobHistory Server | 19888 | mapreduce.jobhistory.webapp.address | http服务端口 |
| HBase | Master | 60000 | hbase.master.port | IPC |
| HBase | Master | 60010 | hbase.master.info.port | http服务端口 |
| HBase | RegionServer | 60020 | hbase.regionserver.port | IPC |
| HBase | RegionServer | 60030 | hbase.regionserver.info.port | http服务端口 |
| HBase | HQuorumPeer | 2181 | hbase.zookeeper.property.clientPort | HBase-managed ZK mode,使用独立的ZooKeeper集群则不会启用该端口。 |
| HBase | HQuorumPeer | 2888 | hbase.zookeeper.peerport | HBase-managed ZK mode,使用独立的ZooKeeper集群则不会启用该端口。 |
| HBase | HQuorumPeer | 3888 | hbase.zookeeper.leaderport | HBase-managed ZK mode,使用独立的ZooKeeper集群则不会启用该端口。 |
| Hive | Metastore | 9083 | /etc/default/hive-metastore中export PORT=来更新默认端口 | |
| Hive | HiveServer | 10000 | /etc/hive/conf/hive-env.sh中export HIVE_SERVER2_THRIFT_PORT=来更新默认端口 | |
| ZooKeeper | Server | 2181 | /etc/zookeeper/conf/zoo.cfg中clientPort= | 对客户端提供服务的端口 |
| ZooKeeper | Server | 2888 | /etc/zookeeper/conf/zoo.cfg中server.x=[hostname]:nnnnn[:nnnnn],标蓝部分 | follower用来连接到leader,只在leader上监听该端口。 |
| ZooKeeper | Server | 3888 | /etc/zookeeper/conf/zoo.cfg中server.x=[hostname]:nnnnn[:nnnnn],标蓝部分 | 用于leader选举的。只在electionAlg是1,2或3(默认)时需要。 |
Halo:基于Java的开源博客,感谢halo提供如此强大的博客系统。 ↩︎