RocketMQ学习教程:03.消息投递模式【云图智联】
消息中间件( Message Oriented Middleware,简称MOM)在企业开发中变得越来越重要。本文介绍消息中间件中的四种消息投递模型,主要是介绍模型的核心特性,以及不同模型之前的区别。这四种模型分别是:
-
PTP模型
-
Pub/Sub模型
-
Partition模型
-
Transfer模型(笔者自己起的名字)
其中PTP模型和Pub/Sub模型在JMS(Java Message Service)规范中有定义,消息中间件ActiveMQ就实现了JMS规范。JMS规范旨在于为消息中间件厂商提供了一个规范,使得Java应用可以更加容易的访问不同的消息中间件产品,类似于我们可以通过JDBC规范定义的相关接口不同厂商的数据库(Mysql/Oracle/SqlServer等)产品。然而一些消息中间件,并没有实现JMS规范,而是自己设计出了一套模型,例如Kafka和RocketMQ就采用了Partition模型。此外业界还有一些其他的消息投递模型,例如Transfer模型,这是笔者自己起的名字。
PTP模型
Point-to-Point,点对点通信模型。PTP是基于队列(Queue)的,一个队列可以有多个生产者,和多个消费者。消息服务器按照收到消息的先后顺序,将消息放到队列中。队列中的每一条消息,只能由一个消费者进行消费,消费之后就会从队列中移除。
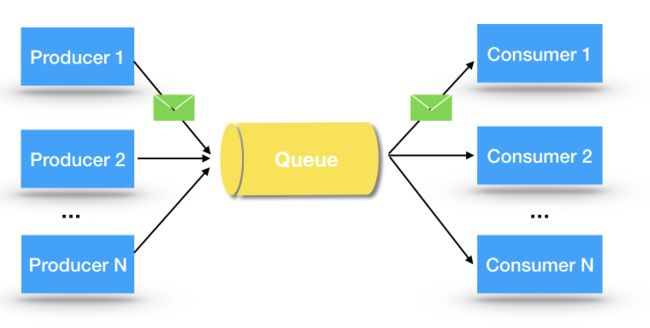
需要注意的是,尽管这里使用Queue的概念,但并不是先进入队列消息,一定会被先消费。在存在多个下游Consumer情况下,一些消息中间件,例如ActiveMQ,为了提升消费能力,会将队列中的消息分发到不同Consumer并行进行处理。这意味着消息发送的时候可能是有序的,但是在消费的时候,就变成无序了。
为了保证消费的有序,一些MQ提供了"专有消费者”或者"排他消费者”的概念,在这种情况下,队列中的消息仅允许一个消费者进行消费,如果存在多个消费者,那么从中选择一个。但是,这意味着在消息在处理中没有了并行性。如果消息量很多的情况下,将会产生消息积压。
为了解决"专有消费者”的性能问题,一些消息中间件采用分区的概念来解决性能问题,我们将在后文进行介绍。
Pub/Sub模型
publish-and- subscribe, 即发布订阅模型。在Pub/Sub模型中,生产者将消息发布到一个主题(Topic)中,订阅了该Topic的所有下游消费者,都可以接收到这条消息。如下图:
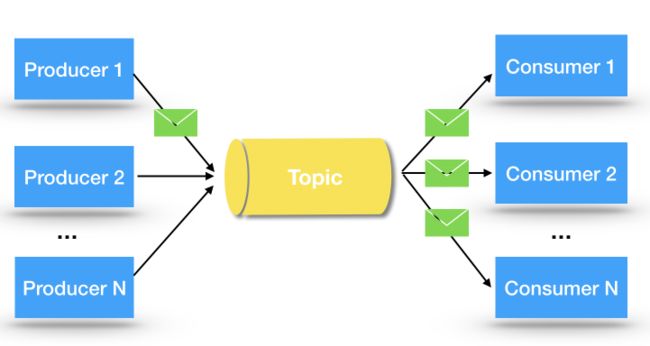
通常情况下,一个条消息只要被消费一次就行了,那么什么情况下需要所有的消费者都对这条消息进行消费呢?最典型的情况就是需要在内存中对数据进行缓存,并需要实时进行更新。
例如,笔者做过一个违禁词系统,对用户输入的评论内容进行违禁词汇检测。这个违禁词系统,部署了在N台服务器上,为了提升检测性能,每台机器都会讲违禁词系统的词库全量加载内存中,之后检测时,对于用户的评论内容进行分词,判断分词后的内容有没有出现在违禁词词汇中。因为词库中不可能包含所有的敏感词,所以还要支持动态的添加敏感词。这个时候,Pub/Sub模型就发挥作用了,每个机器上都启动一个consumer,当生产者发送一个敏感词到Topic中,所有的消费者都会接受到这些消息,更新敏感词库。
Partition模型
为了解决在PTP模型下,有序消息需要通过"专有消费者”消费带来的性能问题,一些消息中间件,如rocketmq,kafka采用了Partition模型,即分区模型,如下所示:

生产者发送消息到某个Topic中时,最终选择其中一个Partition进行发送。你可以将Parition模型中的分区,理解为PTP模型的队列,不同的是,PTP模型中的队列存储的是所有的消息,而每个Partition只会存储部分数据。
对于消息者,此时多了一个消费者组的概念,Paritition会在同一个消费者组下的消费者中进行分配,每个消费者只会消费分配给自己的Paritition。例如上图中,consumer 1分配到了parititon1,consumer 2分配到了parititon2和parititon3,consumer N分配到了paritition 4。
通过这种方式,Paritition模式巧妙的将PTP模型和Pub/Sub模型结合在了一起。
对于PTP模型,一条消息只会由一个消费者进行消费,而Partition模型中每个分区最终也只会有一个消费者进行消费。对于通过"专有消费者"来保证全局消费有序的场景,在Partition模型中,只需保证创建的Topic只有一个Partition即可,这个Paritition最终也只会分配其中一个消费者。
另外,在绝大部分场景下,我们没有必要保证全局有序,例如一个订单产生了3条消息,分别是订单创建,订单付款,订单完成。消费时,要按照这个顺序消费才能有意义。但是订单之间是可以并行消费的,例如将订单1产生的3条消息发送到Partiton 1,将订单2产生的3条消息发送到Partition 2,如此便达到了不同订单之间的并行消费。
对于Pub/Sub模型,一条消息所有的下游消费者都可以进行消费。在Paritition模型中,只需要为每个消费者设置成不同的消费者组即可。
然而,过多的消费者组,会给消息中间件运维带来麻烦。所以一些消息中间件,结合了Partition模型和Pub/Sub模型。例例如RocketMQ,支持为消费者组设置消费模式,如果是集群模式,就按照上述描述进行消费,如果是广播模式,就按照Pub/Sub模型进行消费。
当然,Partition模型也不全是优点,其最大的限制在于Partition数量是固定的(虽然可以调整),针对同一个消费者组,一个Partition最多只可以分配给其中一个消费者。当消费者的数量大于Partition数量时,这些多出来的消费者将无法消费到消息。一些消息中间件对此进行了优化,即在对单个消费者内,同时启动多个线程,来消费这个Partition中的数据,当然前提是要求消息不是有序的,对于有序的消息,只能使用一个线程按顺序消费这个Partition中的数据。
Transfer模型
Paritition模型中的消费者组概念很有用,同一个Topic下的消息可以由多个不同业务方进行消费,只要使用不同的消费者组即可,不同消费者组消费到的位置单独记录,互不影响。 但是,Paritition模型还是限制了消费者数量不能多于分区数。
因此,又有了另外一种消费模型,笔者称之为Transfer模型,如下图所示:
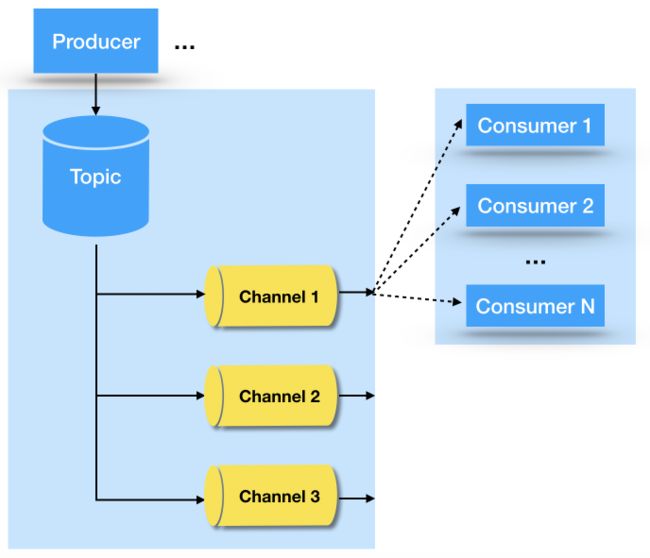
生产者还是将消息发送到Topic中,针对一个Topic,可以创建多个通道,笔者称之为channel。与分区不同的是,发送到Topic中的每条消息,都会转发到每个channel,因此每个channel都有这个Topic的全量数据。当然,没有必要把真的把消息体完整的拷贝一份到channel中,可以只记录一下消息元数据,表示有一条放到这个channel中了。
消费者在消费消息时,必须指定从哪个channel消费。多个消费者消费同一个channel时,每条消息只会有一个消费者消费达到,这一点与PTP模型类似。事实上,我们可以认为,消费了同一个channel的消费者,就自动组成了一个消费者组。但是,与Partition模型不同的是,这里没有分区的概念,因此消费者的数量可以是任意的。事实上,GO语言编写的NSQ消息中间件,采用的就是这种模型。
当然,这种模型与PTP一样,也不能保证被消息有序,除非通过类似于”专用消费者”的概念。
免费学习视频欢迎关注云图智联:https://e.yuntuzhilian.com/