mongoDB的读书笔记(04)_【Replica】(04)_Rollback、回头看看Write Concern的絮叨
mongoDB中的Rollback
mongoDB没有transaction
Rollback是什么意思?在关系数据库中都有这个意识,也就是不commit那么就可以rollback。rollback代表一个还原,即不把真实的操作写入数据库,保持不变。。。等等。
首先需要声明一下,mongoDB的单独一个instance的操作中是没有transaction控制的,写入,那么就写进去了,update,那么就update进去了,删除,那么就删除咯。没有先做再commit的这个过程。所以对于复杂的transaction控制的事件,比如一个交易平台的转账,就要借助two phrase commit或者更强的方式来进行了,这种模式也够讨论一阵的,后面再说,先把Replica搞完。所以,所以,mongoDB中的Rollback指的其实是Replica中的Rollback。
Replica中的Rollback是什么
试想一个场景:
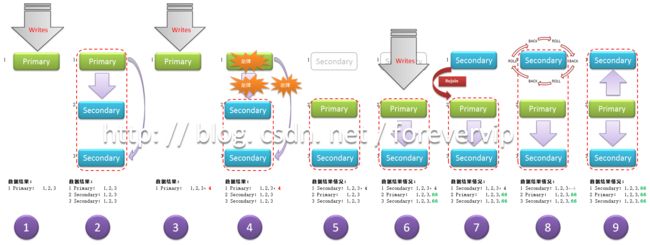
有一个三节点的Replica,id分别为1,2,3,关系为Primary,Secondary,Secondary
① Primary接收Writes过来的数据
此时Primary接收过来的数据是1,2,3
② 两个Secondaries从Primary的oplog中读取命令,进行操作
同时,两个Secondaries把自己的数据也同步为1,2,3
③ Primary又接收了新的数据
此时Primary接收的最新数据是1,2,3,4
④ Primary突然间Step Down了
注意,这个时候,Primary最新更新的数据4还没有同步到其他两个Secondaries中去
⑤ Replica关闭所有的写操作,选举
由于Primary挂掉,集群短时间关闭写操作开始竞选,竞选出最新的Primary和Secondary
⑥ 新的Writes继续
新的Writes过来,由新的Primary主导并且同步到Secondary中去,此时挂掉的原Primary还没有恢复
新写入的数据是66,所以Primary和Secondary的最新数据都是1,2,3,66
⑦ 原Step Down的Primary恢复申请加入Replica
原来挂掉的Primary节点恢复完毕,申请加入集群,此时因为已经有Primary,所以此节点只能以Secondary加入
⑧ Rollback发生
新加入的这个原Primary节点发现自己的数据和现在Primary不一致,需要同步到(也就是rollback到)同一时点的数据为止,所以,节点id为1的这个节点就必须开始回滚数据到1,2,3为止
⑨ 数据更新追回
rollback到合适节点后,id为1的这个节点继续开始同步id为2的Primary的最新数据,最终使得自身数据变成1,2,3,66
※我们可以通过设置来指定新加入节点从哪里来进行数据更新初期化,可以指定同步目标的类型(如Secondary)或者属性(如Hidden)。后面还会解说。
那么结论是
至此,上面的9个过程展示了一次rollback的过程。也就是说rollback的keypoint在于,一个Primary写入操作后,没有及时同步到Secondary中,产生了数据不一致后,Primary挂掉,剩余节点选举后恢复正常后,源Primary继续要加入集群时自己所做的强一致性的一个动作,即为mongoDB的Replica的Rollback。
Rollback掉的数据在哪里
上面说到的被Rollback掉的那一条内容为4个数据怎么办?
mongoDB会自动在dbpath下面建立一个rollback文件夹,然后生成一个型为下面酱的bson文件
. . .bson
尖括号中是每个字段代表的含义。Rollback的数据会被生生成这么一个文件进行数据的备份。
Rollback掉的数据怎么写回去
这个又够写一章的了,估计后面有机会写到Reference的时候再说。大概说起来就是调用mongoDB的mongorestore命令利用文件写回到Primary中去,当然,这个是要人工操作的。
如何避免这种Rollback
嗯,这个可够写的了。继续继续。
要知道的前提概念:Write Concern
首先要知道一个概念,Write Concern,写关心。
字面上可以大概明白是啥意思,就是很关心写,关心写?嗯,关心写的结果。
一个客户端通过某种Driver连接到了末能够DB,进行了一个Write的操作,那么操作完毕后结果可以是OK,也可以是NG,所以Write Concern其实就是一个对于这个OK还是NG的是否获取获取到什么程序的一个level的总称。
还要知道的前提概念:Journal
日志。对于数据库系统来说,比如oracle,有着很强大的日志功能,在断电,宕机或者分布的时候日志可以起到很好的保护作用,使得数据不受损坏,很健壮地去维护or去恢复操作。mongoDB亦是如此。mongoDB也有自己的日志,叫做journal。mongoDB的journal是保证数据库强一致性的一个方式。在写入mongoDB之前先写入Journal当中,如果出现了数据库crash的话,那么restart数据库后,会先从Journal中读取相关内容进行更新。然后Journal的文件会被删除。一般情况下目录下不会留太多Journal的文件,除非读取速度是按照bytes的龟速进行读取。而,mongoDB在做一个写操作的时候还不是很easy的就写入journal然后写入disk,还有很复杂的一些列操作,这里简要说说。来一个写操作,首先会写到一个叫做private view的东东去,这个东东是第一个接收到写这个操作的,然后会把相应的内容转移到Journal中,然后再写到一个叫做shared view的东东去,这个shared view的东东是唯一一个能够直接和mongoDB的disk data files通话的机构。所有处理都会先写入private view 然后最终写入data files,这样保证crash的时候的强一致性。也就是说,mongoDB在写入disk之前有写入内存(private view 和 shared view)的过程,所以mongoDB还有一个特性,就是虽然不提供transaction,但是可以在数据最终commit到磁盘前对数据进行读取的操作。参考下面的mongoDB的原文(粗体标识出):
Read Isolation
MongoDB allows clients to read documents inserted or modified before it commits these modifications to disk, regardless of write concern level or journaling configuration. As a result, applications may observe two classes of behaviors:
•For systems with multiple concurrent readers and writers, MongoDB will allow clients to read the results of a write operation before the write operation returns.
•If the mongod terminates before the journal commits, even if a write returns successfully, queries may have read data that will not exist after the mongod restarts.
继续要知道的Write Concern level
OK,要知道的话就来个彻底,再继续说一下Write Concern的几个level
Unacknowledged
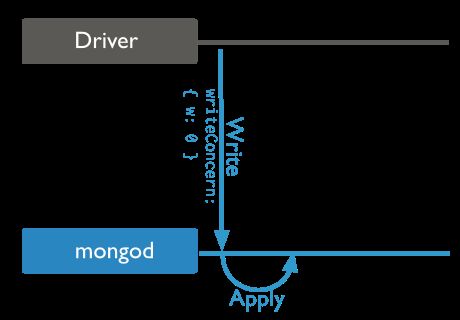
看图其实可以看出来,一个Driver发出的写操作mongoDB是否做了答复是否OK或者NG并不在意。这就是所谓的Unacknowledged,在以前版本的mongoDB中,这个是Default的设置。但是呢,这个东东已经不是主流了,在2012年11月后的mongoDB的版本中,Default的设置是下面这种。
Acknowledged
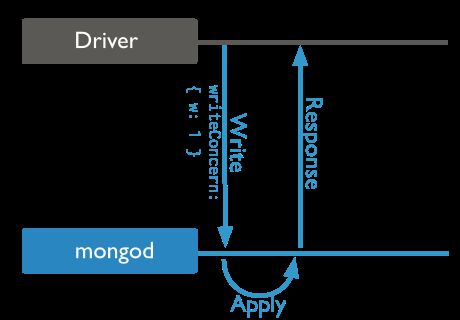
看图很简单咯,就是mongoDB会给Driver一个反馈了,Driver会得知是OK还是NG了。从mongoDB2.6开始,所有的增删改都已经默认增加了这个Response的反馈。这个反馈其实是调用了mongoDB的一条shell命令:getLastError 。所以,现在我们使用的新版mongoDB在执行写操作的时候,都会有一个WriteResult返回回来告诉我们操作是否OK。那么,有时候操作可能会稍长,那么客户端就会等操作这个完结msg才进行下一步操作。这就保证了操作会完成,要么正常,要么异常,客户端可以得知并加以控制。
另外,这种反馈并不是指数据已经正常写入磁盘的反馈,按照mongoDB的说法,这个操作是写入了一个in-memory view的正常反馈,也就是写入了内存,上面我们说过有private view 和 shared view,所以想必是写入了这两个的一个,在线文档中没有明确写出是哪个,我猜想应该是后者,shared view,直接和disk files打交道的这个吧。鉴于不是最终写入磁盘的正确反馈,mongoDB特别的写了下面这个声明,不保证准确写入file disk哦。(略肯爹。。。)
Acknowledged write concern does not confirm that the write operation has persisted to the disk system.
Journaled
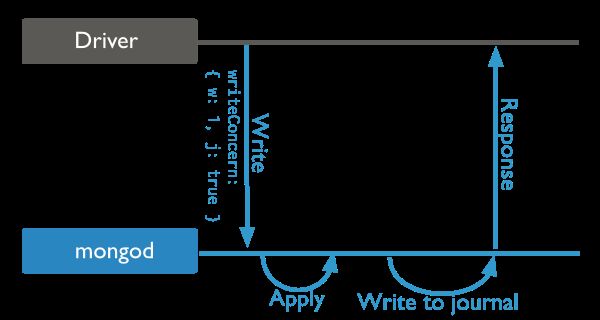
好吧,大名鼎鼎的Journal来了。看图,也相对简哈。当一个写操作写入到journal中才返回response,保证这个操作已经写入了Journal,即使数据库宕机了,重启了,操作已经持久化到Journal中了,所以操作不会丢失,安全恢复。当然,前提是你需要设定Journal有效才可以。
其实这才是真正正题,防止rollback的方法:Replica Acknowledged

前面写了那么那么多,其实看完后再看这张图,茅塞顿开吧。
是的,我们的Replica产生rollback的原因就是Primary的“写”OK了,但是并没有传播到Secondary上去,而Primary一旦Step Down,就出现了灰色数据在原Primary重新加入集群中时需要自行rollback。那么如果采用了这种Replica Acknowledged的方式,当我们的写操作传达到我们提前设定好的足够数目的Secondaries后,再进行结果的return,Driver端拿到返回结果可以得知是否Secondaries已经更新OK了。比如我们有一个Primary,有两个Secondary,那么我们设置每一个写操作必须要起码得到一个Secondary的返回信息才可以的话,那每一个写操作就都可以保证这个操作已经传播到相应个数的Secondary上面去。当然,如果出现网络问题出现阻塞等待的话,我们可以提前设置timeout来防止长时间等待。
最后,rollback的限制
rollback的数据量有300MB的限制哦。太大了mongoDB处理不了。。。
つづく・・・