Java使用Bean上加注解完成csv文件导出
引言:
- csv输出的标题和字段是分开的,标题和字段初始化顺序稍有不慎就会出现张冠李戴…
- 以往拼写csv数据格式,逻辑重复,代码量大,写起来很麻烦,核心逻辑不突出,改起来也很麻烦.
- csv字段显示值:前端可能需要1,0这种状态码,而csv文件需要详细的显示值(比如男女).
这个时候可能就需要写两个构造方法或加参数来区分. - 同一个Bean或者VO在不同的场景需要的字段可能不是完全相同的,比如对于工人这个Bean,前台展示关于身份证这种敏感的字段可能不展示,后台就需要展示,如何满足这种需求.
使用到的技术
- SpringEL+自定义注解+反射+缓存
package com.learn.csvdownload.core;
import java.lang.annotation.*;
@Target(ElementType.FIELD)
@Retention(RetentionPolicy.RUNTIME)
@Documented
public @interface CsvColumn {
/**
* 该列数据的标题名
*
* @return String
*/
String title();
/**
* 排序规则,按照asc排序。如果不初始化该字段,将按照field定义的先后顺序,
* 对field定义的先后顺序强依赖是不健壮的,如果对顺序苛求的场景,应初始化该字段。
*
* @return int
*/
int weight() default 0;
/**
* 通过的SpringEL表达,处理自定义显示值的需求,
*
* @return String
*/
String springEL() default "";
/**
* 分组:同一个VO不同需求场景,在CSV文件中需要展示的字段可能存在不同,通过此字段区分
* 定义该字段后,想要对应方法生成的CSV中包含被注解的字段,必须在调用CSVUtil方法时加入该参数。
* 只有显式声明group的方法才【会】加入被注解字段
*
* @return String
*/
String doGroup() default "";
/**
* 分组:同一个VO不同需求场景,在CSV文件中需要展示的字段可能存在不同,通过此字段区分
* 定义该字段后,想要对应方法生成的CSV中剔除被注解的字段
* 只有显式声明group的方法才【不会】加入被注解字段
*
* @return String
*/
String unDoGroup() default "";
}注解基本解决了以上说的问题.每个注解都有特定的意义,注释很详细.....下面看下具体实现
Model
package com.learn.csvdownload.entity;
import com.learn.csvdownload.core.CsvColumn;
import lombok.Data;
import java.util.Date;
@Data
public class Worker {
@CsvColumn(title = "姓名")
private String name;
@CsvColumn(title = "年龄", weight = 2)
private Integer age;
@CsvColumn(title = "性别", weight = 4, springEL = "sex==0?'女':'男'")
private Integer sex;
//这里的时间util更换成自己的
@CsvColumn(title = "生日", weight = 3, springEL = "T(com.learn.csvdownload.util.DateUtil).getYMDMms(birthDay)")
private Date birthDay;
@CsvColumn(title = "身份证号", weight = 3, unDoGroup = "myGroup")
private String IdCard;
}
Controller
package com.learn.csvdownload.controller;
import com.learn.csvdownload.core.CsvUtil;
import com.learn.csvdownload.entity.Worker;
import org.springframework.core.io.Resource;
import org.springframework.http.ResponseEntity;
import org.springframework.stereotype.Controller;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.ResponseBody;
import java.util.ArrayList;
import java.util.Date;
import java.util.List;
/**
* Created by suyouliang .
*/
@Controller
@RequestMapping("/api/test/v1")
public class DemoController {
@GetMapping("/download-csv-normal")
public ResponseEntity downloadCsvNormal() {
List workers = initData();
return CsvUtil.sendDataStream(workers, "have_id_card", Worker.class);
}
@GetMapping("/download-csv-group")
public ResponseEntity downLoadCsvGroup() {
List workers = initData();
return CsvUtil.sendDataStream(workers, "no_id_card", "myGroup", Worker.class);
}
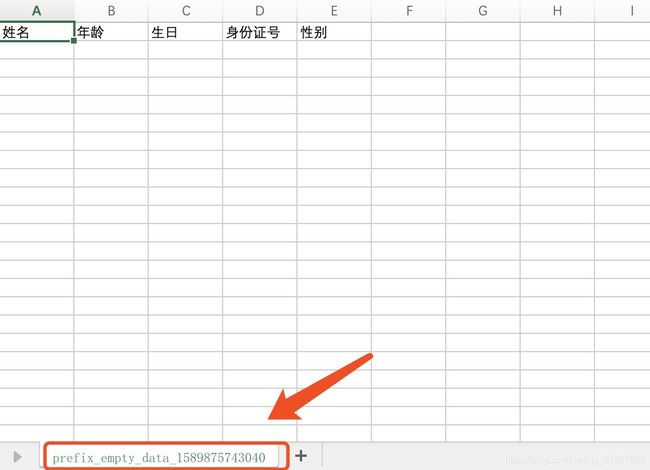
@GetMapping("/download-empty")
@ResponseBody
public ResponseEntity downLoadEmpty() {
return CsvUtil.sendDataStream(null, "empty_data", "no_id_card", Worker.class);
}
private List initData() {
List dataList = new ArrayList<>();
for (int i = 0; i < 10; i++) {
Worker worker = new Worker();
//这里测试出现与CSV逻辑符号","冲突时是否能正常显示
worker.setName("张,\r\n" + i);
worker.setAge(10 + i);
worker.setSex(i % 2 == 0 ? 0 : 1);
worker.setBirthDay(new Date(System.currentTimeMillis() - 1000 * 60 * 60 * 24 * 10 * i));
//这里测试出现与CSV逻辑符号"\r\n"冲突时是否能正常显示
worker.setIdCard("345454198" + i + "xxxxxxx");
dataList.add(worker);
}
return dataList;
}
} 将需要输出的List传入即可.三个方法:
- 不指定分组,查看正常数据是否能够输出

- 指定分组,查看分组逻辑是否能够正常执行

- 空list,测试数据查询为空时是否能够正常输出
具体实现:
package com.learn.csvdownload.core;
import com.google.common.cache.Cache;
import com.google.common.cache.CacheBuilder;
import lombok.extern.slf4j.Slf4j;
import org.apache.commons.lang3.StringUtils;
import org.springframework.core.io.InputStreamResource;
import org.springframework.core.io.Resource;
import org.springframework.expression.Expression;
import org.springframework.expression.ExpressionParser;
import org.springframework.expression.spel.standard.SpelExpressionParser;
import org.springframework.http.HttpHeaders;
import org.springframework.http.MediaType;
import org.springframework.http.ResponseEntity;
import org.springframework.util.CollectionUtils;
import java.io.ByteArrayInputStream;
import java.lang.reflect.Field;
import java.nio.charset.StandardCharsets;
import java.util.*;
import java.util.stream.Collectors;
/**
* User: suyouliang
* Date: 2019/1/4
* Time: 4:39 PM
* Description: 使用SpringEL+自定义注解CsvColumn实现的Csv内容初始化通用工具
* 功能点:
* 1.当数据为空时,默认输出头信息
* 2.处理因为单元格内容包含特殊字符导致的CSV显示格式异常的问题
* 3.基于缓存提高CSV文件格式及头信息获取性能
* 4.基于SpringEl实现自定义输出格式
* 5.基于ResponseEntity屏蔽底层Servlet Api
* 6.
*
* 使用:
* 在需要导出的DTO或PO的field加上@CsvColumn,该field就会写入csv
* 本类为了方便,引入了lang3包的StringUtils和Guava的Cache 如果项目本身没有相关依赖或者对于外部依赖有严格的控制
* 请自行重构。其中Cache是基于concurrentHashMap实现(并发安全)
* 重构时需注意缓存初始化时的并发安全问题,可使用ConcurrentHashMap也可以使用锁...
*/
@Slf4j
public class CsvUtil {
/**
* CSV文件列分隔符
*/
private static final String CSV_COLUMN_SEPARATOR = ",";
/**
* CSV文件数据出现和分隔符相同时的替换字符(也可以转译)
*/
private static final String CSV_COLUMN_SEPARATOR_REPLACE = ".";
/**
* CSV文件换行符
*/
private static final String CSV_RN = "\r\n";
/**
* CSV文件名前缀(按照需求自行重构)
*/
private static final String FILE_PREFIX = "prefix_";
/**
* 被@CsvColumn注解的字段缓存(如果存在大量(上百个)的csv下载,可以考虑缓存增加失效时间)
* key:Class+group
* value:Map
* key:filedName value:CsvColumn
*/
private static final Cache> annotationMapCache = CacheBuilder.newBuilder().build();
/**
* csv文件标题行数据缓存
* key:Map对象的hashCode Hex
* value:Csv行数据
*/
private static final Cache csvHeadLineCache = CacheBuilder.newBuilder().build();
public static ResponseEntity sendDataStream(List dataList, String fileName, Class dataClass) {
return sendDataStream(dataList, fileName, null, dataClass);
}
public static ResponseEntity sendDataStream(List dataList, String fileName, String group, Class dataClass) {
final Map filedAnnotationMap = getFiledAnnotationMap(dataClass, group);
StringBuilder builder = new StringBuilder();
//1..拼接头信息
builder.append(getCsvHeaderLine(filedAnnotationMap));
builder.append(CSV_RN);
//2.拼接数据列
if (!CollectionUtils.isEmpty(dataList)) {
dataList.forEach(obj -> builder.append(getCsvOneLine(filedAnnotationMap, obj, dataClass)));
}
//3.将数据写入response流中
return writeData(builder.toString(), fileName);
}
/**
* 先从缓存中获取,如果获取不到,初始化数据并放入本地缓存
* 缓存过程线程安全
*
* @param dataClass 数据对应class
* @param group 分组编码
* @return getIfPresent排序后的Map
*/
private static Map getFiledAnnotationMap(Class dataClass, String group) {
return Optional.ofNullable(annotationMapCache.getIfPresent(getAnnotationMapKey(dataClass, group)))
.orElseGet(() -> initFiledAnnotationMap(dataClass, group));
}
private static Map initFiledAnnotationMap(Class dataClass, String group) {
Map columnMap = new LinkedHashMap<>();
//1.查找带有@CsvColumn注解的field,并装入CsvColumnMap
Arrays.asList(dataClass.getDeclaredFields()).forEach(field -> {
CsvColumn annotation = field.getDeclaredAnnotation(CsvColumn.class);
if (annotation != null) {
field.setAccessible(true);
//剔除分组过滤的字段
if ((StringUtils.isNotEmpty(group) && StringUtils.isNotEmpty(annotation.doGroup()) && !annotation.doGroup().equals(group)) ||
(StringUtils.isNotEmpty(annotation.unDoGroup()) && annotation.unDoGroup().equals(group))) {
return;
}
columnMap.put(field.getName(), annotation);
}
});
//2.根据FileCsvColumn的weight属性对CsvColumnMap进行排序.
final Map filedAnnotationMap = sortByValue(columnMap);
//3.加入缓存
annotationMapCache.put(getAnnotationMapKey(dataClass, group), filedAnnotationMap);
return filedAnnotationMap;
}
/**
* 拼接CVS表格一行数据
*
* @param filedAnnotationMap
* @return
*/
private static String getCsvOneLine(Map filedAnnotationMap, T lineDate, Class dataClass) {
StringBuilder lineStrBuilder = new StringBuilder();
//1循环data,一个obj代表一行
filedAnnotationMap.forEach((key, value) -> {
//2循环filedAnnotationMap,一个Entity代表一列的数据
try {
Field field = dataClass.getDeclaredField(key);
field.setAccessible(true);
String dataColumn = Optional.ofNullable(field.get(lineDate)).orElse("").toString();
//3解析SpringEL表达式,处理自定义的输出格式需求
if (StringUtils.isNotEmpty(value.springEL())) {
dataColumn = getSpringELValue(value.springEL(), lineDate);
}
//4转译处理(放在el解析后,防止el解析逻辑出现幺蛾子(EL转译后出现CSV逻辑符号))
lineStrBuilder.append(symbolTranslation(dataColumn));
lineStrBuilder.append(CSV_COLUMN_SEPARATOR);
} catch (NoSuchFieldException | IllegalAccessException e) {
log.error("CsvUtil根据反射操作属性异常,异常信息{0}", e);
}
});
return lineStrBuilder.append(CSV_RN).toString();
}
/**
* 获取
*
* @param filedAnnotationMap
* @return String
*/
private static String getCsvHeaderLine(Map filedAnnotationMap) {
return StringUtils.join(Optional.ofNullable(csvHeadLineCache.getIfPresent(Integer.toHexString(filedAnnotationMap.hashCode())))
.orElseGet(() -> initCsvHeaderLine(filedAnnotationMap)), CSV_COLUMN_SEPARATOR);
}
/**
* 获取annotationMapCache的key
*
* @param dataClass
* @param group
* @return
*/
private static String getAnnotationMapKey(Class dataClass, String group) {
return dataClass.getName().concat(Optional.ofNullable(group).orElse(""));
}
private static String initCsvHeaderLine(Map filedAnnotationMap) {
final String csvHeaderLineStr = StringUtils.join(filedAnnotationMap.values().stream()
.map(CsvColumn::title).collect(Collectors.toList()), CSV_COLUMN_SEPARATOR);
csvHeadLineCache.put(Integer.toHexString(filedAnnotationMap.hashCode()), csvHeaderLineStr);
return csvHeaderLineStr;
}
/**
* 根据csv的内容 使用HttpServletResponse 发送
*
* @param data csv内容
* @return
*/
private static ResponseEntity writeData(String data, String fileName) {
//此行为了标示文件解析的格式,不加在Excel上会乱码,wps好像没事
data = "\ufeff".concat(data);
return ResponseEntity.ok()
.contentType(MediaType.parseMediaType("application/csv"))
.header(HttpHeaders.CONTENT_DISPOSITION, "attachment; filename=".concat(getRealCsvFileName(fileName) + ".csv"))
.body(new InputStreamResource(new ByteArrayInputStream(data.getBytes(StandardCharsets.UTF_8))));
}
private static String getSpringELValue(String springEL, Object sourceObj) {
ExpressionParser parser = new SpelExpressionParser();
Expression exp = parser.parseExpression(springEL);
return exp.getValue(sourceObj) + "";
}
/**
* 根据FileColumn中的weight属性为Map map排序
*
* @param map 需要排序的map
* @return 排序后的CsvColumn Map
*/
private static Map sortByValue(Map map) {
Map result = new LinkedHashMap<>();
map.entrySet().stream()
.sorted(Comparator.comparing(entry -> entry.getValue().weight()))
.forEach(e -> result.put(e.getKey(), e.getValue()));
return result;
}
private static String getRealCsvFileName(String fileName) {
fileName = StringUtils.isEmpty(fileName) ? "default" : fileName.trim();
return CsvUtil.FILE_PREFIX
.concat(fileName.replaceAll(" ", "-").concat("_"))
.concat(System.currentTimeMillis() + "");
}
/**
* 特殊符号转译,防止内容中包含CSV的逻辑符号
* 针对英文的",",与CSV的列标示冲突,统一更换为中文的","
* 针对"\r\n",与CSV的行标示冲突,统一更换为""
* 也可以自己定制
*
* @param dataColumn 单元格内容
* @return 转译后的单元格内容
*/
private static String symbolTranslation(String dataColumn) {
return dataColumn.replaceAll(CSV_RN, "").replaceAll(CSV_COLUMN_SEPARATOR, ",");
}
}
其他相关类型:
package com.learn.csvdownload.util;
import java.text.SimpleDateFormat;
import java.util.Date;
/**
* User: suyouliang
* Date: 4/2/19
* Time: 8:43 PM
* Description:
*/
public class DateUtil {
/**
* 时间转换格式yyyy年MM月dd日 HH:mm:ss
*
* @param date
* @return
*/
public static String getYMDMms(Date date) {
SimpleDateFormat formatter = new SimpleDateFormat("yyyy年MM月dd日 HH:mm:ss");
return formatter.format(date);
}
}项目目录:

自己项目使用时,只需要引入core包下的两个文件就可以了(相关依赖代码中有解释)
代码gitHub地址:代码