(一)Android数据结构学习之链表
需要看本系列其他文章的请转到:
- (一)Android数据结构学习之链表
- (二)Android数据结构学习之数组
- (三)Android数据结构学习之队列
- (四)Android数据结构学习之栈
前言
我们都知道Android是基于java的,Java中实现了很多数据结构,像我们最常使用的数组、List都是数据结构,当我们使用的时候可能会觉得这些东西真是方便,但是并不知道其中原理,很多好的公司招人会要求不但懂得Android的相关知识,还要懂得数据结构和算法的知识,所以我们就不能只停留在只会使用的层次上。
数据结构的分类
这里我们借用百度百科的一张图看一下数据结构的常用分类:
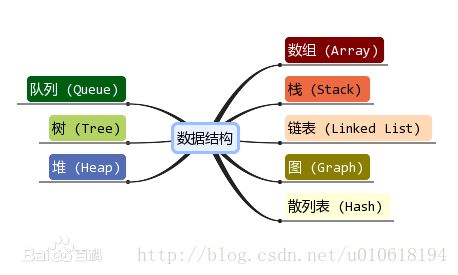
除了Graph以外都是见过的,像数组、链表、队列都是大量使用于我们的日常开发中的。今天我们就链表入手开始学习数据结构
链表
概念:链表由一系列结点(链表中每一个元素称为结点)组成,每个结点包括两个部分:一个是存储数据元素的数据域,另一个是存储下一个(上一个)结点地址的指针域。
图:

上图是双链表,代表着节点中有2个指针,一个指向前一个元素,另外一个指向后一个元素。链表其实可以分类为单链表和双链表,双链表比单链表多了一个指向前一个元素的指针而已,相信很好理解
优点:
1. 插入和删除只需修改指针,不需要移动其他元素,效率高,为O(1);
2. 不要求连续空间,空间利用率高;
缺点:
1. 查找元素的效率低,比如要查找位置为99的元素,需要从第1个开始查找到99,效率非常低
注:O为时间复杂度的表示,有兴趣了解的可以转到:https://zh.wikipedia.org/wiki/%E5%A4%A7O%E7%AC%A6%E5%8F%B7
不明白的也没有关系,不影响理解。
以上就是关于链表的概念,相信大家可以很好的理解。知道了链表的优缺点,在我们日常开发中需要对数据进行频繁插入和删除的就可以使用链表。
链表在java中的实现
链表在java中的实现类为LinkedList,这个类的代码不多,也很好理解,我们来一起看一下到底是怎么实现的。
首先java使用一个静态内部类来代表链表的节点:
private static class Node {
E item;// 数据
Node next;// 前一个节点
Node prev;// 后一个节点
Node(Node prev, E element, Node next) {
this.item = element;
this.next = next;
this.prev = prev;
}
} 非常简单粗暴,很好理解。像我们日常使用最常用的方法肯定是:add,remove,get,set。让我们一个一个看:
public boolean add(E e) {
linkLast(e);
return true;
}首先是add方法,里面调用了linkLast方法,方法名的意思是连接最后一个,一起来看:
void linkLast(E e) {
final Node l = last;
final Node newNode = new Node<>(l, e, null);
last = newNode;
if (l == null)
first = newNode;
else
l.next = newNode;
size++;
modCount++;
} last记录的是链表中最后一个元素,当列表为空时last为null,这段代码简单,首先new一个节点,头指针指向当前链表节点中的最后一个,尾指针是指向null。然后,如果last为空就说明链表还是空的,那么这个新增的节点就是头节点。
再来看remove方法,remove方法有3个重载,remove()删除的是第一个节点,remove(int index)删除的是指定位置节点,remove(Object o)删除的是节点数据为o的节点,其实只需要知道remove(Object o)就行,其余2个重载的方法都使用的是相同的方法。
public E remove(int index) {
checkElementIndex(index);// 检查index是否为0或是否越界
return unlink(node(index));
}
private void checkElementIndex(int index) {
if (!isElementIndex(index))
throw new IndexOutOfBoundsException(outOfBoundsMsg(index));
}上述代码中最关键的就是unlink(node(index)),node方法会根据index查找到对应节点,unlink方法则是删除指定节点
Node node(int index) {
// assert isElementIndex(index);
if (index < (size >> 1)) {
Node x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
Node x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
} 这里的size >> 1其实就是size/2,这段代码很巧妙的已链表大小的一半来查询,是为了增加查询的效率。如果index小于size/2,则从链表的第一个节点开始遍历到index然后返回节点;如果index大于size/2,则从链表最后一个节点开始倒叙遍历到index然后返回节点。其实这里就很明显的体现出了链表的缺点了,因为必须要从链表的第一个节点开始查询,且要遍历index次才能找到对应节点。
node方法找到了对应index的节点,然后unlink则负责断开该节点。
E unlink(Node x) {
// assert x != null;
final E element = x.item;
final Node next = x.next;
final Node prev = x.prev;
if (prev == null) {
first = next;
} else {
prev.next = next;
x.prev = null;
}
if (next == null) {
last = prev;
} else {
next.prev = prev;
x.next = null;
}
x.item = null;
size--;
modCount++;
return element;
} 首先判断该节点是不是头节点,如果是,记录下一个节点作为头节点;如果不是,则让前一个节点的尾指针指向后一个节点。然后再判断是不是尾节点,如果是,记录前一个节点为尾节点;如果不是,让后一个节点的头指针指向前一个节点。这段代码很好理解,完全可以不用看解析。
然后在来看remove(Object o)
public boolean remove(Object o) {
if (o == null) {
for (Node x = first; x != null; x = x.next) {
if (x.item == null) {
unlink(x);
return true;
}
}
} else {
for (Node x = first; x != null; x = x.next) {
if (o.equals(x.item)) {
unlink(x);
return true;
}
}
}
return false;
} 很简单粗暴,遍历链表,查看是否有节点数据为o,有,则调用unlink方法删除。这里要注意的一点是,链表的节点数据是允许为null的。
再来看一下get方法
public E get(int index) {
checkElementIndex(index);
return node(index).item;
}还是熟悉的味道和配方,关键的node方法,找到对应节点并返回数据。
public E set(int index, E element) {
checkElementIndex(index);
Node x = node(index);
E oldVal = x.item;
x.item = element;
return oldVal;
} set方法同样使用的是node方法,不再详述了
总结
这篇文章主要讲的是对于数据结构的基本认识和链表的了解,可能对于我们实际开发并不会有很大的实质性帮助,但是这只是数据结构和算法知识的一小部分,我相信当我们对数据结构和算法有一个比较全面的了解和理解的时候,对于我们的实质编码肯定是会有帮助的,加油吧!