【学习】评价指标理解
目录
ROC曲线
AUC
KS曲线
P-R曲线
准确率(precision)
召回率(recall)
F1系列
ROC曲线
ROC的全称是Receiver Operating Characteristic Curve,中文名字叫“受试者工作特征曲线”,顾名思义,其主要的分析方法就是画这条特征曲线。ROC曲线的横轴是FPR(假阳性率、误诊率)、纵轴是TPR(真阳性率、灵敏度)。
这条曲线代表的是在不同的阈值下,FPR和TPR的一个变化曲线,通常,我们希望FPR尽可能的小,而TPR尽可能的大,所以曲线越靠近左上角,模型的效果越好。
def acu_curve(y,prob):
"""
param y:真实值
param prob:预测值
"""
fpr,tpr,threshold = roc_curve(y,prob) ###计算真正率和假正率
roc_auc = auc(fpr,tpr) ###计算auc的值
plt.figure()
lw = 2
plt.figure(figsize=(10,10))
plt.plot(fpr, tpr, color='darkorange',
lw=lw, label='ROC curve (area = %0.3f)' % roc_auc) ###假正率为横坐标,真正率为纵坐标做曲线
plt.plot([0, 1], [0, 1], color='navy', lw=lw, linestyle='--')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('Receiver operating characteristic example')
plt.legend(loc="lower right")
plt.show()
AUC
AUC(Area Under Curve)被定义为ROC曲线下的面积,取值范围一般在0.5和1之间。使用AUC值作为评价标准是因为很多时候ROC曲线并不能清晰的说明哪个分类器的效果更好,而作为一个数值,对应AUC更大的分类器效果更好。
KS曲线
KS(Kolmogorov-Smirnov)曲线(洛伦兹曲线)的纵轴是表示TPR和FPR的值,就是这两个值可以同时在一个纵轴上体现,横轴就是阈值,表示模型能够将正、负客户区分开的程度越大。两条曲线之间相距最远的地方对应的阈值,就是最能划分模型的阈值,即KS=max(TPR-FPR),KS值越大,模型的区分度越好。
说明K-S曲线的做法:
-
把模型对样本的输出概率(predict_proba)从大到小排序,计算对应不同阈值时,大于等于阈值的样本数占总样本的百分比percentage
-
计算阈值取每个概率时对应的TPR和FPR值,分别画(percentage, TPR)和(percentage, FPR)的曲线
-
K-S曲线上的KS值,即max(TPR−FPR),即两条曲线间的最大间隔距离。
from sklearn.metrics import roc_curve
import matplotlib.pyplot as plt
def KS_cal(y,y_hat_proba):
"""
param y:真实值
param y_hat_proba:预测分数
"""
# 计算ks值
fpr, tpr, _ = roc_curve(y, y_hat_proba)
diff = np.subtract(tpr, fpr)
ks = diff.max()
return ks
def plot_ks(y,y_hat_proba):
# 画ks曲线
fpr, tpr, thresholds = roc_curve(y, y_hat_proba)
diff = np.subtract(tpr, fpr)
ks = diff.max()
y_len = len(y)
# 计算比例,这样计算比较快
# 也可以自己划分样本的比例,自己计算fpr,tpr
y_hat_proba_sort = sorted(y_hat_proba, reverse=True)
cnt_list = []
cnt = 0
for t in thresholds:
for p in y_hat_proba_sort[cnt:]:
if p >= t:
cnt += 1
else:
cnt_list.append(cnt)
break
percentage = [c/float(y_len) for c in cnt_list]
if min(thresholds)<=min(y_hat_proba_sort):
percentage.append(1)
# 以下为画图部分
best_thresholds = thresholds[np.argmax(diff)]
best_percentage = percentage[np.argmax(diff)]
best_fpr = fpr[np.argmax(diff)]
lw = 2
plt.figure(figsize=(8, 8))
plt.plot(percentage, tpr, color='darkorange',
lw=lw, label='True Positive Rate')
plt.plot(percentage, fpr, color='darkblue',
lw=lw, label='False Positive Rate')
plt.plot(percentage, diff, color='darkgreen',
lw=lw, label='diff')
plt.plot([best_percentage, best_percentage], [best_fpr, best_fpr+ks],
color='navy', lw=lw, linestyle='--',label = 'ks = %.2f, thresholds = %.2f'%(ks,best_thresholds))
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('percentage')
plt.title('Kolmogorov-Smirnov')
plt.legend(loc="lower right")
plt.show()
P-R曲线
在PR曲线中,以Recall(貌似翻译为召回率或者查全率)为x轴,Precision为y轴。
# 画P-R曲线
def pr_curve(y_true, y_scores):
plt.title('Precision/Recall Curve')# give plot a title
plt.xlabel('Recall')# make axis labels
plt.ylabel('Precision')
precision, recall, thresholds = precision_recall_curve(y_true, y_scores)
plt.plot(precision, recall)
plt.show()
准确率(precision)
precision 体现了模型对负样本的区分能力,precision越高,说明模型对负样本的区分能力越强。

召回率(recall)
recall 体现了分类模型HH对正样本的识别能力,recall 越高,说明模型对正样本的识别能力越强,
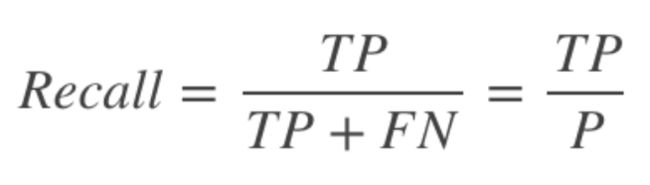
F1系列
-
f1-score 是precision和recall两者的综合。

-
macro-f1会考虑每个类别,得到的值属于宏观的值。

-
micro-f1会考虑不同类别的样本量。
