【PaddlePaddle】使用Tiny-Yolo做“垃圾图像”目标识别
PaddlePaddle-使用Tiny-Yolo实现“垃圾图像”目标识别
代码环境:
在AI Studio平台基于
Python 2.7
PaddlePaddle 1.5.0
在本地基于
windows 10 1803
Python 3.7
PaddlePaddle 1.5.1
cuda 8.0
cudnn 7.5.1
写在前面
前段时间,在参加2019年的人工智能创意赛,在初赛的时候,我们团队是利用残差神经网络ResNet-50做了一个垃圾图像分类的项目,之后会把初赛的项目也写入blog里。进入复赛时,老师给我们的建议是:“残差做不了目标识别,换个模型”。
本文主要是讲讲数据的获取、预处理以及Paddle-Reader的构造,最后分享一下在本地实现实时预测的方法。训练的过程就不在本文阐述了,下一篇文章会分享一下我们使用基于mobilenet-v1的SSD来实现垃圾图像的识别。
目录
- PaddlePaddle-使用Tiny-Yolo实现“垃圾图像”目标识别
-
- 数据集来源与制作
- 图像预处理
- 生成图像列表及Paddle-Reader构造
- 本地部署预测
数据集来源与制作
在初赛的时候,我们的数据集来自斯坦福大学Gary Thung,Mindy Yang的学年论文《Classification of Trash for Recyclability Status》,数据集中原本有6类可回收垃圾,“glass”,“cardboard”,“plastic”,“paper”,“trash”,“metal”,共2527张垃圾图像。
- 594 paper
- 501 glass
- 137 trash
- 410 metal
- 482 plastic
- 403 cardboard

经过筛选,我们删除了“cardboard”,“trash”两类图片,原因分别是:“cardboard”类图像占总图片的面积过大,我们担心会影响该类垃圾的识别;“trash”类图像数量过少,仅有137张,数量相较于其他类过少,我们担心该类垃圾会成为模型中的“奇异值”。
斯坦福论文垃圾图像数据集
同时,我们项目组补充了252张多目标图片加入训练数据集。
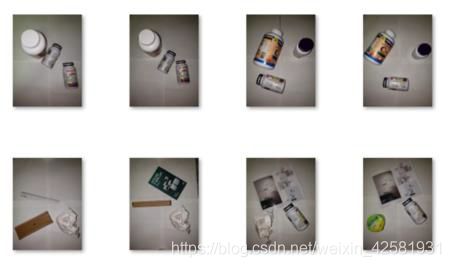
然后,使用LabelImg对每张垃圾图像进行目标标识和标注,制作符合 Pascal VOC 标准的数据集 。LabelImg的使用方法,我在此简单介绍一下。
LabelImg 是一个可视化的图像标定工具。Faster R-CNN,YOLO,SSD等目标检测网络所需要的数据集,均需要借此工具标定图像中的目标。生成的 XML 文件是遵循 PASCAL VOC 的格式的。
图像预处理
在图片预处理工作上,我们全部使用第三方库Pillow,做图形图像处理。
train 和 test 在图像预处理 (图像增强) 的部分使用的操作不相同:
在训练的过程中,尽可能希望模型能够看到更多更丰富更多样化的输入数据,所以经常会使用类似于
- 随机调整图像明度、色彩、对比度、饱和度
- 随机翻转
- 随机切块
"image_distort_strategy": {
"expand_prob": 0.5,
"expand_max_ratio": 4,
"hue_prob": 0.5,
"hue_delta": 18,
"contrast_prob": 0.5,
"contrast_delta": 0.5,
"saturation_prob": 0.5,
"saturation_delta": 0.5,
"brightness_prob": 0.5,
"brightness_delta": 0.125
}
def random_brightness(img):
prob = np.random.uniform(0, 1)
if prob < 0.5:
brightness_delta = 0.125
delta = np.random.uniform(-brightness_delta, brightness_delta) + 1
img = ImageEnhance.Brightness(img).enhance(delta)
return img
def random_contrast(img):
prob = np.random.uniform(0, 1)
if prob < 0.5:
contrast_delta = 0.5
delta = np.random.uniform(-contrast_delta, contrast_delta) + 1
img = ImageEnhance.Contrast(img).enhance(delta)
return img
def random_saturation(img):
prob = np.random.uniform(0, 1)
if prob < 0.5:
saturation_delta = 0.5
delta = np.random.uniform(-saturation_delta, saturation_delta) + 1
img = ImageEnhance.Color(img).enhance(delta)
return img
def random_hue(img):
prob = np.random.uniform(0, 1)
if prob < 0.5:
hue_delta = 18
delta = np.random.uniform(-hue_delta, hue_delta)
img_hsv = np.array(img.convert('HSV'))
img_hsv[:, :, 0] = img_hsv[:, :, 0] + delta
img = Image.fromarray(img_hsv, mode='HSV').convert('RGB')
return img
生成图像列表及Paddle-Reader构造
生成图像列表
for images in all_images:
trainval = []
test = []
if data_num % 10 == 0:
# 每10张图像取一个做测试集
name = images.split('.')[0]
annotation = os.path.join(annotation_path, name + '.xml')
# 如果该图像的标注文件不存在,就不添加到图像列表中
if not os.path.exists(annotation):
continue
test.append(os.path.join(images_path, images))
test.append(annotation)
# 添加到总的测试数据中
test_list.append(test)
else:
# 其他的的图像做训练数据集
name = images.split('.')[0]
annotation = os.path.join(annotation_path, name + '.xml')
# 如果该图像的标注文件不存在,就不添加到图像列表中
if not os.path.exists(annotation):
continue
trainval.append(os.path.join(images_path, images))
trainval.append(annotation)
# 添加到总的训练数据中
trainval_list.append(trainval)
data_num += 1
生成图像列表train.txt

构造同步读取reader
def custom_reader(file_list, data_dir, input_size, mode):
def reader():
np.random.shuffle(file_list)
for line in file_list:
if mode == 'train' or mode == 'eval':
###################### 以下可能是需要自定义修改的部分 ############################
image_path, label_path = line.split()
image_path = os.path.join(data_dir, image_path)
label_path = os.path.join(data_dir, label_path)
img = Image.open(image_path)
if img.mode != 'RGB':
img = img.convert('RGB')
im_width, im_height = img.size
# layout: label | xmin | ymin | xmax | ymax | difficult
bbox_labels = []
root = xml.etree.ElementTree.parse(label_path).getroot()
for object in root.findall('object'):
bbox_sample = []
# start from 1
bbox_sample.append(float(train_parameters['label_dict'][object.find('name').text]))
bbox = object.find('bndbox')
difficult = float(object.find('difficult').text)
bbox_sample.append(float(bbox.find('xmin').text) / im_width)
bbox_sample.append(float(bbox.find('ymin').text) / im_height)
bbox_sample.append(float(bbox.find('xmax').text) / im_width)
bbox_sample.append(float(bbox.find('ymax').text) / im_height)
bbox_sample.append(difficult)
bbox_labels.append(bbox_sample)
###################### 可能需要自定义修改部分结束 ############################
if len(bbox_labels) == 0: continue
img, sample_labels = preprocess(img, bbox_labels, input_size, mode)
# sample_labels = np.array(sample_labels)
if len(sample_labels) == 0: continue
boxes = sample_labels[:, 1:5]
lbls = sample_labels[:, 0].astype('int32')
difficults = sample_labels[:, -1].astype('int32')
max_box_num = train_parameters['max_box_num']
cope_size = max_box_num if len(boxes) >= max_box_num else len(boxes)
ret_boxes = np.zeros((max_box_num, 4), dtype=np.float32)
ret_lbls = np.zeros((max_box_num), dtype=np.int32)
ret_difficults= np.zeros((max_box_num), dtype=np.int32)
ret_boxes[0: cope_size] = boxes[0: cope_size]
ret_lbls[0: cope_size] = lbls[0: cope_size]
ret_difficults[0: cope_size] = difficults[0: cope_size]
yield img, img.shape[1:], ret_boxes, ret_lbls, ret_difficults
elif mode == 'test':
img_path = os.path.join(line)
yield Image.open(img_path)
return reader
本地部署预测
最后讲讲模型训练好以后,我们如何实现在本地进行实时的预测
我们需要准备Pycharm、iVCam(可以调用iPhone摄像头)
import argparse
import codecs
import numpy as np
import sys
import time
import paddle.fluid as fluid
import cv2
from PIL import Image
from PIL import ImageDraw,ImageFont
train_parameters = {
"data_dir": "",
"file_list": "train.txt",
"class_dim": -1,
"label_dict": {
},
"image_count": -1,
"continue_train": False,
"pretrained": False,
"pretrained_model_dir": "./pretrained-model",
"save_model_dir": "./yolo-model",
"model_prefix": "yolo-v3",
"use_tiny": True,
"max_box_num": 1,
"num_epochs": 120,
"train_batch_size": 5,
"use_gpu": True,
"yolo_cfg": {
"input_size": [3, 608, 608],
"anchors": [10, 13, 16, 30, 33, 23, 30, 61, 62, 45, 59, 119, 116, 90, 156, 198, 373, 326],
"anchor_mask": [[6, 7, 8], [3, 4, 5], [0, 1, 2]]
},
"yolo_tiny_cfg": {
"input_size": [3, 256, 256],
"anchors": [145, 190, 49, 54, 187, 115, 90, 119, 222, 240, 87, 68],
"anchor_mask": [[3, 4, 5], [0, 1, 2]]
},
"ignore_thresh": 0.7,
"mean_rgb": [127.5, 127.5, 127.5],
"mode": "train",
"multi_data_reader_count": 4,
"apply_distort": True,
"valid_thresh": 0.01,
"nms_thresh": 0.45,
"image_distort_strategy": {
"expand_prob": 0.5,
"expand_max_ratio": 4,
"hue_prob": 0.5,
"hue_delta": 18,
"contrast_prob": 0.5,
"contrast_delta": 0.5,
"saturation_prob": 0.5,
"saturation_delta": 0.5,
"brightness_prob": 0.5,
"brightness_delta": 0.125
},
"rsm_strategy": {
"learning_rate": 0.001,
"lr_epochs": [20, 40, 60, 80, 100],
"lr_decay": [1, 0.5, 0.25, 0.1, 0.05, 0.01],
},
"momentum_strategy": {
"learning_rate": 0.1,
"decay_steps": 2 ** 7,
"decay_rate": 0.8
},
"early_stop": {
"sample_frequency": 50,
"successive_limit": 3,
"min_loss": 2.5,
"min_curr_map": 0.84
}
}
ues_tiny = train_parameters['use_tiny']
yolo_config = train_parameters['yolo_tiny_cfg'] if ues_tiny else train_parameters['yolo_cfg']
target_size = yolo_config['input_size']
anchors = yolo_config['anchors']
anchor_mask = yolo_config['anchor_mask']
nms_threshold = 0.4
valid_thresh = 0.4
confs_threshold = 0.5
label_dict = {
}
with codecs.open('label_list.txt') as f:
for line in f:
parts = line.strip().split()
label_dict[str(float(parts[0]))] = parts[1]
print(label_dict)
class_dim = len(label_dict)
use_gpu = True
place = fluid.CUDAPlace(0) if use_gpu else fluid.CPUPlace()
exe = fluid.Executor(place)
path = "freeze_model" #预测模型位置
[inference_program, feed_target_names, fetch_targets] = fluid.io.load_inference_model(dirname=path,
executor=exe)
'''
由于我们使用OpenCV获取摄像头图像,但使用PIL读取,这里需要做两次格式的转换
'''
def cv2_to_PIL(image):
# image=cv2.imread('lena.png')
image=Image.fromarray(cv2.cvtColor(image,cv2.COLOR_BGR2RGB))
# image.show()
return image
def PIL_to_cv2(image):
# image=Image.open('lena.png')
image=cv2.cvtColor(np.asarray(image),cv2.COLOR_RGB2BGR)
# cv2.imshow('lena',image)
# cv2.waitKey()
return image
def get_yolo_anchors_classes(class_num, anchors, anchor_mask):
yolo_anchors = []
yolo_classes = []
for mask_pair in anchor_mask:
mask_anchors = []
for mask in mask_pair:
mask_anchors.append(anchors[2 * mask])
mask_anchors.append(anchors[2 * mask + 1])
yolo_anchors.append(mask_anchors)
yolo_classes.append(class_num)
return yolo_anchors, yolo_classes
def draw_bbox_image(img, boxes, labels):
color = "red"
draw = ImageDraw.Draw(img)
for box, label in zip(boxes, labels):
if label_dict[str(label)]=="glass":
color = "blue"
elif label_dict[str(label)]=="plastic":
color = "yellow"
elif label_dict[str(label)] == "metal":
color = "red"
else:
color = "green"
xmin, ymin, xmax, ymax = box[0], box[1], box[2], box[3]
draw.rectangle((xmin, ymin, xmax, ymax), None, color)
ft = ImageFont.truetype('Arial.ttf', 22)
draw.text((xmin, ymin), "{0}".format(label_dict[str(label)]),font = ft, fill = color)
return img
def clip_bbox(bbox):
xmin = max(min(bbox[0], 1.), 0.)
ymin = max(min(bbox[1], 1.), 0.)
xmax = max(min(bbox[2], 1.), 0.)
ymax = max(min(bbox[3], 1.), 0.)
return xmin, ymin, xmax, ymax
def resize_img(img, target_size):
img = img.resize(target_size[1:], Image.ANTIALIAS)
return img
mean = np.array([0.485, 0.456, 0.406]).reshape((3, 1, 1))
std = np.array([0.229, 0.224, 0.225]).reshape((3, 1, 1))
# 正则化一张图片
def normalize_image(image):
image = (image - mean) / std
return image
#image = np.array(image).astype('float32').transpose((2, 0, 1)) / 255
def read_image(img_path):
origin = img_path.copy()
img = resize_img(origin, target_size)
resized_img = img.copy()
if img.mode != 'RGB':
img = img.convert('RGB')
#img = np.array(img).astype('float32').transpose((2, 0, 1)) # HWC to CHW
img = np.array(img).astype('float32').transpose((2, 0, 1))
#img = normalize_image(img)
img -= 127.5
img *= 0.007843
img = img[np.newaxis, :]
return origin, img, resized_img
def sigmoid(x):
"""Perform sigmoid to input numpy array"""
return 1.0 / (1.0 + np.exp(-1.0 * x))
def box_xywh_to_xyxy(box):
shape = box.shape
assert shape[-1] == 4, "Box shape[-1] should be 4."
box = box.reshape((-1, 4))
box[:, 0], box[:, 2] = box[:, 0] - box[:, 2] / 2, box[:, 0] + box[:, 2] / 2
box[:, 1], box[:, 3] = box[:, 1] - box[:, 3] / 2, box[:, 1] + box[:, 3] / 2
box = box.reshape(shape)
return box
def box_iou_xyxy(box1, box2):
assert box1.shape[-1] == 4, "Box1 shape[-1] should be 4."
assert box2.shape[-1] == 4, "Box2 shape[-1] should be 4."
b1_x1, b1_y1, b1_x2, b1_y2 = box1[:, 0], box1[:, 1], box1[:, 2], box1[:, 3]
b2_x1, b2_y1, b2_x2, b2_y2 = box2[:, 0], box2[:, 1], box2[:, 2], box2[:, 3]
inter_x1 = np.maximum(b1_x1, b2_x1)
inter_x2 = np.minimum(b1_x2, b2_x2)
inter_y1 = np.maximum(b1_y1, b2_y1)
inter_y2 = np.minimum(b1_y2, b2_y2)
inter_w = inter_x2 - inter_x1
inter_h = inter_y2 - inter_y1
inter_w[inter_w < 0] = 0
inter_h[inter_h < 0] = 0
inter_area = inter_w * inter_h
b1_area = (b1_x2 - b1_x1) * (b1_y2 - b1_y1)
b2_area = (b2_x2 - b2_x1) * (b2_y2 - b2_y1)
return inter_area / (b1_area + b2_area - inter_area)
def rescale_box_in_input_image(boxes, im_shape, input_size):
"""Scale (x1, x2, y1, y2) box of yolo output to input image"""
h, w = im_shape
fx = w / input_size
fy = h / input_size
boxes[:, 0] *= fx
boxes[:, 1] *= fy
boxes[:, 2] *= fx
boxes[:, 3] *= fy
boxes[boxes < 0] = 0
boxes[:, 2][boxes[:, 2] > (w - 1)] = w - 1
boxes[:, 3][boxes[:, 3] > (h - 1)] = h - 1
return boxes
def get_yolo_detection(preds, anchors, class_num, img_height, img_width):
"""Get yolo box, confidence score, class label from Darknet53 output"""
preds_n = np.array(preds)
n, c, h, w = preds_n.shape
print(preds_n.shape, anchors)
anchor_num = len(anchors) // 2
preds_n = preds_n.reshape([n, anchor_num, class_num + 5, h, w]).transpose((0, 1, 3, 4, 2))
preds_n[:, :, :, :, :2] = sigmoid(preds_n[:, :, :, :, :2])
preds_n[:, :, :, :, 4:] = sigmoid(preds_n[:, :, :, :, 4:])
pred_boxes = preds_n[:, :, :, :, :4]
pred_confs = preds_n[:, :, :, :, 4]
pred_scores = preds_n[:, :, :, :, 5:] * np.expand_dims(pred_confs, axis=4)
grid_x = np.tile(np.arange(w).reshape((1, w)), (h, 1))
grid_y = np.tile(np.arange(h).reshape((h, 1)), (1, w))
anchors = [(anchors[i], anchors[i + 1]) for i in range(0, len(anchors), 2)]
anchors_s = np.array([(an_w, an_h) for an_w, an_h in anchors])
anchor_w = anchors_s[:, 0:1].reshape((1, anchor_num, 1, 1))
anchor_h = anchors_s[:, 1:2].reshape((1, anchor_num, 1, 1))
pred_boxes[:, :, :, :, 0] += grid_x
pred_boxes[:, :, :, :, 1] += grid_y
pred_boxes[:, :, :, :, 2] = np.exp(pred_boxes[:, :, :, :, 2]) * anchor_w
pred_boxes[:, :, :, :, 3] = np.exp(pred_boxes[:, :, :, :, 3]) * anchor_h
pred_boxes[:, :, :, :, 0] = pred_boxes[:, :, :, :, 0] * img_width / w
pred_boxes[:, :, :, :, 1] = pred_boxes[:, :, :, :, 1] * img_height / h
pred_boxes[:, :, :, :, 2] = pred_boxes[:, :, :, :, 2]
pred_boxes[:, :, :, :, 3] = pred_boxes[:, :, :, :, 3]
#pred_boxes = box_xywh_to_xyxy(pred_boxes)
pred_boxes = np.tile(np.expand_dims(pred_boxes, axis=4), (1, 1, 1, 1, class_num, 1))
pred_labels = np.zeros_like(pred_scores) + np.arange(class_num)
return pred_boxes.reshape((n, -1, 4)), pred_scores.reshape((n, -1)), pred_labels.reshape((n, -1)
def get_all_yolo_pred(outputs, yolo_anchors, yolo_classes, input_shape):
all_pred_boxes = []
all_pred_scores = []
all_pred_labels = []
for output, anchors, classes in zip(outputs, yolo_anchors, yolo_classes):
pred_boxes, pred_scores, pred_labels = get_yolo_detection(output, anchors, classes, input_shape[0],
input_shape[1])
all_pred_boxes.append(pred_boxes)
all_pred_labels.append(pred_labels)
all_pred_scores.append(pred_scores)
pred_boxes = np.concatenate(all_pred_boxes, axis=1)
pred_scores = np.concatenate(all_pred_scores, axis=1)
pred_labels = np.concatenate(all_pred_labels, axis=1)
return pred_boxes, pred_scores, pred_labels
def calc_nms_box(pred_boxes, pred_scores, pred_labels, valid_thresh=0.4, nms_thresh=0.45, nms_topk=400):
output_boxes = np.empty((0, 4))
output_scores = np.empty(0)
output_labels = np.empty(0)
for boxes, labels, scores in zip(pred_boxes, pred_labels, pred_scores):
valid_mask = scores > valid_thresh
boxes = boxes[valid_mask]
scores = scores[valid_mask]
labels = labels[valid_mask]
score_sort_index = np.argsort(scores)[::-1]
boxes = boxes[score_sort_index][:nms_topk]
scores = scores[score_sort_index][:nms_topk]
labels = labels[score_sort_index][:nms_topk]
for c in np.unique(labels):
c_mask = labels == c
c_boxes = boxes[c_mask]
c_scores = scores[c_mask]
detect_boxes = []
detect_scores = []
detect_labels = []
while c_boxes.shape[0]:
detect_boxes.append(c_boxes[0])
detect_scores.append(c_scores[0])
detect_labels.append(c)
if c_boxes.shape[0] == 1:
break
iou = box_iou_xyxy(detect_boxes[-1].reshape((1, 4)), c_boxes[1:])
c_boxes = c_boxes[1:][iou < nms_thresh]
c_scores = c_scores[1:][iou < nms_thresh]
output_boxes = np.append(output_boxes, detect_boxes, axis=0)
output_scores = np.append(output_scores, detect_scores)
output_labels = np.append(output_labels, detect_labels)
return output_boxes, output_scores, output_labels
def box_xywh_to_xyxy(box):
shape = box.shape
assert shape[-1] == 4, "Box shape[-1] should be 4."
box = box.reshape((-1, 4))
box[:, 0], box[:, 2] = box[:, 0] - box[:, 2] / 2, box[:, 0] + box[:, 2] / 2
box[:, 1], box[:, 3] = box[:, 1] - box[:, 3] / 2, box[:, 1] + box[:, 3] / 2
box = box.reshape(shape)
return box
'''
实时预测
'''
#使用OpenCV读取摄像头
cap = cv2.VideoCapture(0)
while cv2.waitKey(1) < 0:
hasimg, img = cap.read()
if not hasimg:
cv2.waitKey()
break
imgpil = cv2_to_PIL(img)
origin,tensor_img,resized_img = read_image(imgpil)
t1 = time.time()
batch_outputs = exe.run(inference_program,
feed={
feed_target_names[0]: tensor_img},
fetch_list=fetch_targets)
period = time.time() - t1
print("predict result:{0} cost time:{1}".format(batch_outputs, "%2.2f sec" % period))
input_w, input_h = origin.size[0], origin.size[1]
yolo_anchors, yolo_classes = get_yolo_anchors_classes(class_dim, anchors, anchor_mask)
pred_boxes, pred_scores, pred_labels = get_all_yolo_pred(batch_outputs, yolo_anchors, yolo_classes,
(target_size[1], target_size[2]))
boxes, scores, labels = calc_nms_box(pred_boxes, pred_scores, pred_labels, valid_thresh, nms_threshold)
boxes = rescale_box_in_input_image(boxes, [input_h, input_w], target_size[1])
draw = draw_bbox_image(origin, boxes, labels)
drawcv2 = PIL_to_cv2(draw)
cv2.imshow('ImageShow', img)
cv2.imshow('ImageInfer', drawcv2)
实时预测的效果如图
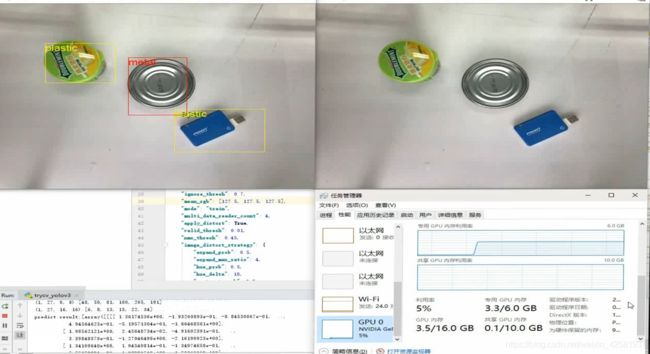
以上
有不懂的朋友可以评论询问噢