病毒木马查杀实战第018篇:病毒特征码查杀之基本原理
前言
在本系列的导论中,我曾经在“病毒查杀方法”中简单讲解过特征码查杀这种方式。而我也在对于实际病毒的专杀工具编写中,使用过CRC32算法来对目标程序进行指纹匹配,从而进行病毒判定。一般来说,类似于MD5以及CRC32这样的算法,在病毒大规模爆发时是可以提高查杀效率的,但是传统的更为常用的方法是采用以静态分析文件的结构为主并结合动态分析的方法,通过反汇编来寻找病毒的内容代码段、入口点代码段等等信息。尽管病毒特征码的定义非常简单,但是特征码的具体提取方法,却鲜有资料可供参考。那么我在这里就简单讨论一下关于病毒特征码的知识。
特征码选取的基本要求
说到特征码,也许我们接触最多的是在使用查壳工具PEiD时,对目标程序进行判定时所采用的特征匹配代码。PEiD的特征码保存在程序目录的userdb.txt中,举个例子来说,我们拿之前研究过的cf.exe“敲竹杠”病毒样本来看。首先将病毒样本拖入PEiD:
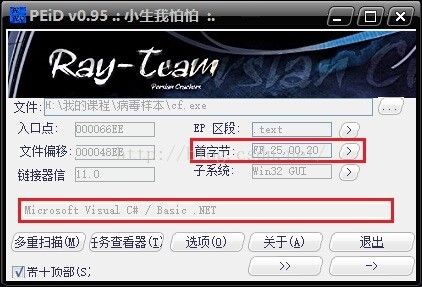
图1
可见,程序是由“MicrosoftVisual C# / Basic .NET”编译的,那么为什么PEiD能够识别出这款软件是怎么编译的呢?我们可以先查看一下程序入口的首字节:
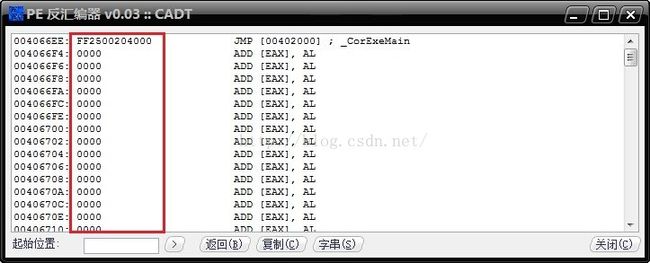
图2
可见程序的入口地址代码为“FF 25 0020 40 00”然后是一大串的“00”。然后我们打开userdb.txt,查找一下“Microsoft Visual C# / Basic .NET”字符串来看一下,可以找到以下结果:
[MicrosoftVisual C# / Basic .NET]
signature= FF 25 00 20 ?? ?? 00 00 00 00 0000 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 0000 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
ep_only= true
在signature后面,是“FF 25 0020 ?? ??”(其中的??表示任意字符),也就是说,只要目标程序的入口代码部分能够匹配“FF 25 00 20 ?? ??”,就认为程序是由“Microsoft Visual C# / Basic .NET”编译的。而通过对比图2,我们的cf.exe程序的入口代码可以匹配这段特征码,于是也就检测出了cf.exe的编译方式。PEiD通过对这种“共性”的匹配,就能够识别出各种各样的壳以及编译方式了。
病毒程序的特征码与上述我们讲的有相同的地方也有不同的地方。相同点在于我们同样需要在病毒的二进制代码中提取一部分作为病毒特征。但是我们的病毒程序是不能够采用上述这种方式,即从程序入口进行提取的,因为这样一来病毒程序和普通的程序的检测结果就没有区别了。因此计算机病毒的特征码需要能够把病毒程序与一般的程序区分开来,即能够唯一标识一个或者一类多态病毒,要能够成为计算机病毒程序的“指纹”。如果只是随意从病毒内选取一段二进制代码串作为该病毒的特征码,很可能会在正常的程序中也匹配到该特征码,从而出现误报的情况。所以在我看来,选取恰当的特征代码串绝对是一个很具技巧性的工作,这需要经验的积累以及对目标病毒的深刻理解。当然对于不同的杀毒软件厂商而言,都会有自己的一套提取特征码的方式,可能是自动获取,也可能是手动分析。
一般来说,病毒特征码需要满足以下几个要求:
1、不能从数据区提取,因为数据区的内容很容易改变,一旦病毒程序变更版本,改变了数据内容,特征码就会失效。而其它的区块则相对来说保险一些。
2、在保持特征码的唯一性的前提下,应当尽量使得特征码短小精悍,从而减少检测过程中的时间与空间的复杂度,提高检测效率。
3、经过详细的逆向分析之后选取出来的特征码,才足以将该病毒与其它病毒或正常程序相区别。
4、病毒程序的特征码一定不能匹配到普通程序,比如选取病毒入口点的二进制代码,就必然出现误报的情况。
5、特征码的长度应当控制在64个字节以内。
特征码选取的基本方法
病毒的特征码可能是病毒的感染标记,也可能是若干计算机指令组成的一段计算机程序。一般使用以下几种方法来提取病毒的特征码
1、计算校验和
这种方法的特点是简单快速,也是我们之前的专杀工具所采用的方式。但是采用这种方法,一种特征码只能匹配一个病毒,即便病毒的变动很小,也需要重新提取特征码,这造成的后果是会使得特征码库过于庞大,一般用于临时提取特征码。所以这种计算校验和的方式不是我们讨论的重点。
2、提取特征字符串
病毒文件中总会存在一些可供识别的字符串,很多时候,这些字符串是某个病毒所特有的,因此这种方式适用于所有病毒的特征码的提取。采用这种方式甚至还能识别某一大类病毒,但是缺点是需要耗费比较多的扫描时间。以我们之前讨论过的“熊猫烧香”病毒为例,经过我们之前的逆向分析可以知道,病毒最开始会使用“xboy”以及“whboy”这两个字符串来进行解密的操作。比如我们尝试一下,在病毒程序的二进制代码中搜索“whboy”:
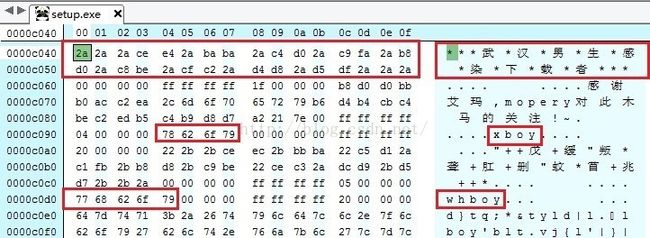
图3
相信一般的程序中不会出现“whboy”以及“xboy”这两段字符,因此就可以考虑将这两个字符串或者其中的一个字符串作为“熊猫烧香”病毒的特征码。这样只要对目标程序中的可打印字符串进行检索,如果发现了“whboy”就可以认为目标程序是“熊猫烧香”病毒程序。这样即便是病毒出现了变种,只要它依旧包含有“whboy”,我们就依然能够实现查杀的工作。或者我们也可以考虑使用更长的字符串,比如上图中开始的那32个字节,即“***武*汉*男*生*感*染*下*载*者***”,将其十六进制代码提取出来作为特征码,也是可以的。那么我就将这段字符串作为“熊猫烧香”的特征码。然后可以使用PEiD查看一下该段代码所在的区段:
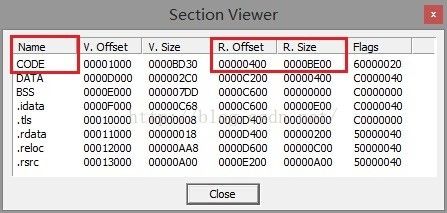
图4
可见,文件偏移0x0c040位于CODE,即代码区段中,那么其实在进行匹配的时候,我们只要检索目标程序的这个区段就可以了。或者为了方便起见,我们在检测目标程序时,只检测位于文件偏移0x0c040处的字符,如果能够匹配病毒特征码,就认为目标程序是病毒。
3、提取特征反汇编代码
病毒的反汇编代码往往都会有一些比较有特色的地方,那么我们就可以将这些反汇编代码的十六进制数值提取出来作为特征码,以唯一的标识该病毒。比如我们之前分析过的U盘病毒,它的反汇编代码有这么几句:
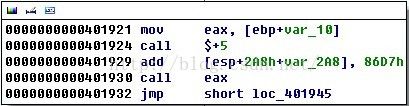
图5
这里第二行的反汇编代码为“call $+5”,其实这种写法并不多见。但事实上这不过是IDA Pro解析方式上的问题,在OD中,这段代码会被解析为“call 00401929”:

图6
那么我们就不妨将这段十六进制代码提取出来作为我们的特征码。同样选取32个字节,并且加上文件的偏移:

图7
此处的文件偏移为0x1921,查看区段表:
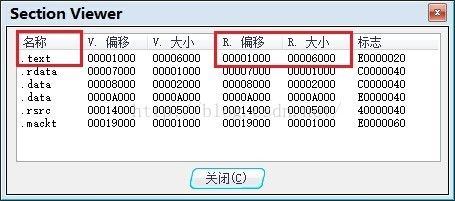
图8
可见它位于.text区段,也就是代码段中。
当然,从反汇编代码中进行特征码的提取,方法是有很多的,可能每个人都有自己的方法,我也不敢说我所提取出来的特征码就一定满足唯一性等特征,我这里所举的都是最简单的例子。但是选取以下这段代码明显是不合适的:
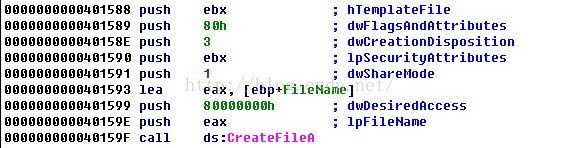
图9
因为CreateFile这个函数实在是过于普遍,因此如果选取这段代码作为特征码,那么误报的可能性是非常高的,这需要大家特别注意。当然在实际的工作中,对于同一个病毒而言,为了保险起见,特征码可能会选择多处,既有字符串,又有反汇编代码,从而保证检测的准确性。
4、两段检验和形式
这种方式包含两段病毒文件特殊位置的数据,该数据能够代表该病毒的特性。我们将这两段数据的校验和计算出来。那么在检测扫描目标程序时,先计算目标文件在该位置处的校验和的值,通过判断是否符合相应的特征码来判定目标程序是否为病毒程序。这种方法的准确率高,耗时也比较少。很多时候能够利用一个特征码检测出同一类的病毒。
特征码检测的不足
病毒特征码只是一种检测的方式,只能够防患于未然。如果说计算机已经中了病毒,那么就算我们拥有该病毒的特征码,至多只能将病毒从计算机中删除,而无法修复该病毒对计算机造成的危害。另外,现在有些软件能够实现对病毒特征码的定位,也就是能够将病毒程序分为几个部分,然后使用杀毒软件对这些部分进行查杀,哪部分报毒,就说明特征码在哪部分中,然后再不断地进行细分,再用杀软进行检测,最终确定特征码的具体位置。而找到特征码后,就可以修改特征码,从而实现针对于某一款或某几款杀毒软件的免杀。
云查杀技术简介
既然这次讲到了病毒的特征码,那么在最后不得不简单讲一下云查杀的一些知识。因为传统的杀毒软件,需要用户不断地升级病毒库,将病毒特征码保存在本地的计算机中,这样才能够让本地的杀毒软件能够识别各种各样的新式病毒。这种方式的缺点是占用本地计算机资源过大,而且也有一定的滞后性,为了解决这个问题,云查杀技术也就应运而生了。
云查杀是依赖于云计算的技术,云技术是分布式计算的一种,其最基本的概念,是通过计算机网络将庞大的计算处理程序自动分拆成无数个较小的子程序,之后再交由多部服务器所组成的庞大系统经过搜寻、计算分析之后将处理结果回传给用户。通过这项技术,网络服务提供者可以在数秒之内,达成处理数以千万计甚至亿万计的信息,从而达到和“超级计算机”同样强大效能的网络服务。
所谓云查杀,就是把安全引擎和病毒木马特征库放在服务器端,解放用户的个人计算机,从而获取更加优秀的查杀效果、更快的安全响应时间、更小的资源占用以及更快的查杀速度,并且无需升级病毒木马特征库。
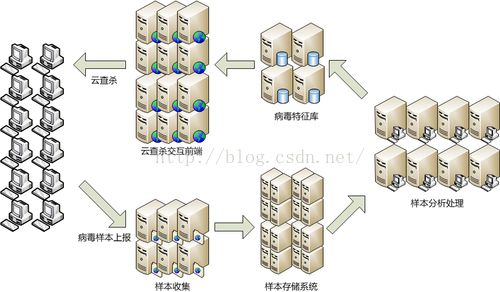
图10
云查杀是对付病毒木马泛滥的一种先进而有效的方法。判断一个文件是不是病毒,计算的工作不在用户计算机中完成,而是在一个安全公司的“云端”,即服务端来做,“云端”可以配置上千台服务器,以进行快速的大规模计算,这是对付病毒非常有效的方法。
云查杀也有其弊端,最主要的就是要求用户必须连接互联网,否则无法完成病毒的查杀任务。另外用户隐私的泄露问题也是云查杀技术必须要解决的问题。
小结
这次我简单讲解了一下关于病毒特征码的知识,希望大家能够依照上述方法,或者自己总结方法,试着查找一下病毒程序中符合条件的特征码。相信大家找到的特征码能够更加有效地对病毒进行识别。