在Python中实现对称矩阵
这一篇文章较早被作者写出,最早是在2016年7月24日。因为最近要用到对称矩阵,因此翻译过来以备后续回顾。
在计算机科学中,对称矩阵可用于存储对象之间的距离或表示为无向图的邻接矩阵。与经典矩阵相比,使用对称矩阵的主要优势在于较小的内存需求。在这篇文章中,描述了这种矩阵的Python实现。
介绍
在对称矩阵中,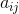 是等同于
是等同于 ![]() 的。由于这个特性,一个
的。由于这个特性,一个 ![]() 的对称矩阵需要存储的也仅仅是
的对称矩阵需要存储的也仅仅是 ![]() 个元素 而不是一般矩阵中的
个元素 而不是一般矩阵中的 ![]() 个元素。此类矩阵的示例如下所示:
个元素。此类矩阵的示例如下所示:

矩阵对角线可以看作是一面镜子。此镜像上方的每个元素都会反射到该镜像下方的元素。因此,不需要存储对角线上方的元素。如前所述,对称矩阵可用于表示距离或邻接矩阵。在本文的以下部分中,将逐步解释对称矩阵的Python实现及其用法。
创建矩阵
在本节及后续各节中,我将首先展示特定用法,然后再展示实现。以下源代码显示了如何创建一个4 × 4 对称矩阵:
>>> from symmetric_matrix import SymmetricMatrix as SM
>>> sm = SM(4)为了使此代码可运行,必须实现 SymmetricMatrix 类。目前,仅需编写一种特殊的方法,特别是该__init__()方法仅需一个称为的参数size。此参数指定行数。由于对称矩阵是正方形,因此无需传递列数。__init__()首先检查提供的内容size是否有效。如果不是,ValueError则会引发异常。否则,size存储矩阵中的一个,并初始化矩阵的数据存储(在这种情况下为列表)。以下代码显示了实现:
class SymmetricMatrix:
def __init__(self, size):
if size <= 0:
raise ValueError('size has to be positive')
self._size = size
self._data = [0 for i in range((size + 1) * size // 2)]值得注意的是 _data 用于存储矩阵的存储空间。它小于 ![]() 。为了解释元素数量的计算,假设我们有一个
。为了解释元素数量的计算,假设我们有一个 ![]() 的对称矩阵。为了节省空间,仅需要保存对角线以下和其上的元素。因此,对于第一行,只需要存储一个元素,对于第二行,则要保存两个元素,依此类推。因此,对于第 N 行,有 N 个元素需要保存。如果我们汇总所有行中需要保存的所有元素,则会得到以下结果:
的对称矩阵。为了节省空间,仅需要保存对角线以下和其上的元素。因此,对于第一行,只需要存储一个元素,对于第二行,则要保存两个元素,依此类推。因此,对于第 N 行,有 N 个元素需要保存。如果我们汇总所有行中需要保存的所有元素,则会得到以下结果:
![]()
获取矩阵大小
有可能使用一种标准的Python方法来获得矩阵大小(即len()函数),将是很好的。因此,为了获得矩阵大小,我们希望可以使用以下代码:
>>> print(len(sm))
4要启动先前的代码,必须实现另一种魔术方法。此方法是,__len__()并且它唯一的责任是返回_size属性:
def __len__(self):
return self._size访问矩阵
到现在为止,我们已经能够创建一个对称矩阵,并将所有元素初始化为零并获取其大小。但是,这在现实生活中不是很有用。我们还需要写入和读取矩阵。由于我们希望矩阵的使用尽可能舒适和自然,因此[]在访问矩阵时将使用下标运算符:
>>> sm[1, 1] = 1
>>> print('sm[1, 1] is', sm[1, 1])
sm[1, 1] is 1写入
首先,让我们专注于写入矩阵。在Python中,sm[1, 1]执行对的赋值时,解释器将调用__setitem__()magic方法。为了实现预期的行为,必须在中实现此方法SymmetricMatrix。由于仅存储对角线下方和对角线上的元素,并且整个矩阵保存在一维数据存储中,因此需要计算对该存储的正确索引。现在,假设该_get_index()方法返回此索引。稍后,将显示此方法的实现。现在,有了索引后,我们可以使用__setitem__()基础存储提供的方法,可以简单地将其称为self._data[index] = value:
def __setitem__(self, position, value):
index = self._get_index(position)
self._data[index] = value读取
为了从矩阵中获得一个元素,我们将以类似的方式进行。因此,__getitem__()必须实现另一种魔术方法,特别是该方法。与前面的情况类似,要从矩阵中获取所需的元素,必须将位置转换为基础存储的适当索引。该服务是通过_get_index()本节最后一部分专门介绍的方法来完成的。当我们拥有正确的索引时,将返回基础存储中此位置上的元素:
def __getitem__(self, position):
index = self._get_index(position)
return self._data[index]计算指标
现在,该展示如何_get_index()实现了。传递的位置是一对表格(row, column)。此方法的源代码可以分为两个步骤,必须按提供的顺序执行:
- 将对角线上方的位置转换为对角线下方的适当位置,然后
- 计算到基础存储的正确索引。

如果给定位置(row, column)处于对角线上方,则将row与交换column,因为对角线上方的每个元素的(column, row)位置都恰好在对角线上。为了阐明第二部分,特别是使用存储器的索引的计算,将使用上图和下表:
| Row | Size of All Previous Rows | Matrix Position | Calculated Index |
|---|---|---|---|
| 1 | 0 | (0,column) | 0+column |
| 2 | 0+1 | (1,column) | 0+1+column |
| 3 | 0+1+2 | (2,column) | 0+1+2+column |
| … | … | … | … |
| row+1 | 0+1+2+3+⋯+row | (row,column) | 0+1+2+3+⋯+row+column |
请注意,对于第一行,该对的列部分(row, column)足以用作基础存储的索引。对于第二行,该对的前一行和列部分中的元素数量(row, column)足够。对于第二行,计算得出的索引为 ![]() ,因为上一行仅包含一个元素。对于第三行,情况有些复杂,因为必须对所有先前行中的元素进行求和。因此,该
,因为上一行仅包含一个元素。对于第三行,情况有些复杂,因为必须对所有先前行中的元素进行求和。因此,该(2, column)位置的索引是 ![]() 。因此,对于该
。因此,对于该(row, column)位置,正确的索引是 ![]() 。由于有限的算术级数,该表达式可以简化如下:
。由于有限的算术级数,该表达式可以简化如下:
![]()
最后,下面的源代码显示了计算到基础存储中的索引的实现:
def _get_index(self, position):
row, column = position
if column > row:
row, column = column, row
index = (0 + row) * (row + 1) // 2 + column
return index使用自己的存储类型
现在,我们有了对称矩阵的有效实现。由于使用这种类型的矩阵的主要动机是内存效率,因此可能出现的问题是,是否可以进行更高效的内存实现。这使我们考虑使用的list是否是用于存储的最佳数据结构。如果您熟悉的Python实现list,则可能知道其中list不包含您要插入其中的元素。实际上,它包含指向这些元素的指针。因此,list对于例如array.array直接存储元素的存储要求要更高。当然,还有其他数据结构比的存储效率更高list。因此,问题是应该使用哪一个。假设我们选择array.array了list在对称矩阵实现过程中。以后,此矩阵需要在多个进程之间共享。当然,由于array.array它不应该由不同的进程共享,因此它将不起作用。
因此,选择基础数据结构时更好的解决方案是留出空间供用户根据自己的需求选择存储类型。如果没有特殊要求,则list可以用作默认存储类型。否则,用户将在矩阵创建期间传递其存储类型,如以下示例所示:
>>> def create_storage(size):
... return multiprocessing.Array(ctypes.c_int64, size)
...
>>> sm = SM(3, create_storage)
>>> sm[1, 2] = 5上面的代码create_storage()返回一个数组,其中包含64b个整数,可以由不同的进程共享。
为了实现这种改进,该__init__()方法仅需要很小的改变。首先,添加一个参数,即create_storage默认值设置为None。如果未传递该参数的参数,list则将用作存储类型。否则,需要一个采用一个参数(特别是存储空间的大小)并返回创建的存储空间的函数:
def __init__(self, size, create_storage=None):
if size <= 0:
raise ValueError('size has to be positive')
if create_storage is None:
create_storage = lambda n: [0 for i in range(n)]
self._size = size
self._data = create_storage((size + 1) * size // 2)基准测试
为了比较引入的对称矩阵和通过numpy模块创建的矩阵,我编写了一个基准脚本,该脚本使用4000 × 4000矩阵以显示实现的对称矩阵和numpy矩阵的内存要求和平均访问时间。创建对称矩阵时,array.array()将其用作基础存储。创建numpy矩阵,numpy.zeros()称为。两个矩阵中的元素都是64b整数。
内存使用情况
首先,比较内存使用情况。模块中的asizeof.asizeof()函数pympler计算所创建矩阵的大小。该实验的结果可以在下表中看到。
| Matrix Type | Memory Usage |
|---|---|
Symmetric Matrix (via array) |
61.05 MB |
numpy Matrix |
122.07 MB |
我们可以看到对称矩阵可以节省大约50%的存储空间。
访问时间
接下来,针对两种矩阵类型,计算用于写入整个矩阵的访问时间。进行五次该计算,然后计算平均结果。实验在Intel四核i7-4700HQ(6M高速缓存,2.40 GHz)处理器上运行。从下表中可以看出,已实现的对称矩阵的平均访问时间比矩阵的平均访问时间差得多numpy:
| Matrix Type | Access Time |
|---|---|
Symmetric Matrix (via array) |
11.26 sec |
numpy Matrix |
2.00 sec |
该cProfile模块可以揭示对称矩阵访问时间较慢的原因。在使用cProfile模块运行脚本之前,仅存在相关部分。因此,比较内存需求的第一部分和使用该numpy代码的所有部分均未包含在配置文件中。
$ python -m cProfile -s cumtime benchmark.py
...
Ordered by: cumulative time
ncalls tottime percall cumtime percall filename:lineno(function)
130/1 0.005 0.000 74.098 74.098 {built-in method exec}
1 0.000 0.000 74.098 74.098 benchmark.py:8()
1 0.002 0.002 74.028 74.028 benchmark.py:91(main)
1 25.421 25.421 74.026 74.026 benchmark.py:56(benchmark_access_time)
80000000 24.473 0.000 48.290 0.000 symmetric_matrix.py:22(__setitem__)
80000000 23.817 0.000 23.817 0.000 symmetric_matrix.py:30(_get_index)
1 0.000 0.000 0.315 0.315 symmetric_matrix.py:9(__init__)
1 0.315 0.315 0.315 0.315 benchmark.py:21(create_array)
... 为了理解上面的输出,只有三列对我们很重要,即ncalls,cumtime和filename:lineno(function)。第一个名为ncalls,表示从中filename:lineno(function)调用该函数的次数。该cumtime列通知我们有关在所有调用期间此功能和所有子功能所花费的累积时间。从输出中可以看出,时间主要花费在__setitem__()和中_get_index()。开销是由于Python的内部工作和对基础存储的计算索引所致。因此,这种对称矩阵实现方式适用于内存使用量比处理器功率大的问题。
源代码
GitHub上 SymmetricMatrix提供了已实现类的完整源代码,以及单元测试和基准脚本。所有代码都是使用Python 3.4编写,测试和分析的。