python requests接收chunked编码问题
很久以前写爬虫用C++和libcurl来实现,体会了libcurl的复杂和强大,后来学会了python,才发现用python+urllib/urllib2写爬虫比C++来得容易,再后来发现了python的requests库,这个更简洁简单,只要懂HTTP和HTTPS就可以写某米抢购器、火车票刷票工具、医院挂号刷号工具、驾校约车软件……,太强大了,著名的HTTP工具httpie就是基于requests实现的。
最近就用python的requests写个了爬虫,导出某汽车4s店的订单excel文件,我们都知道网页下载文件大多数是chunked编码,而requests库在解析chunked编码时就报错了:
requests.exceptions.ChunkedEncodingError: ('Connection broken: IncompleteRead(4360 bytes read)', IncompleteRead(4360 bytes read))
详细错误信息如下:
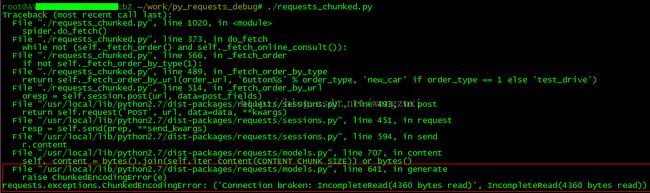
其中requests_chunked.py的第514行只是调用requests.session.post:
![]()
从Traceback信息可以看出是/usr/local/lib/python2.7/dist-packages/requests/models.py的第641行抛异常了,遇到这种情况我肯定是看看这一行代码之前都干了啥为啥抛异常,果断打开之:
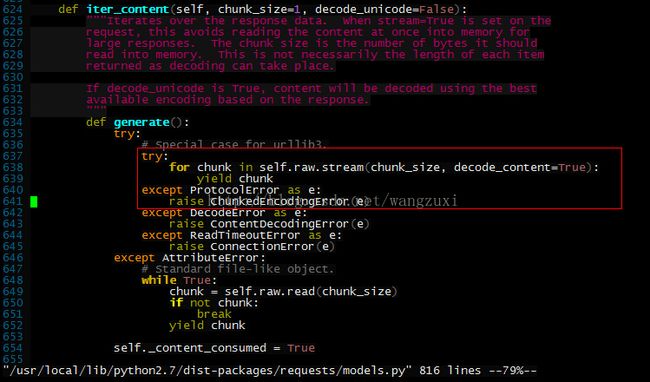
这一块应该是循环接收chunk数据,异常到这里就中止了,要追查抛异常的源是哪里只能把try...except...注掉:
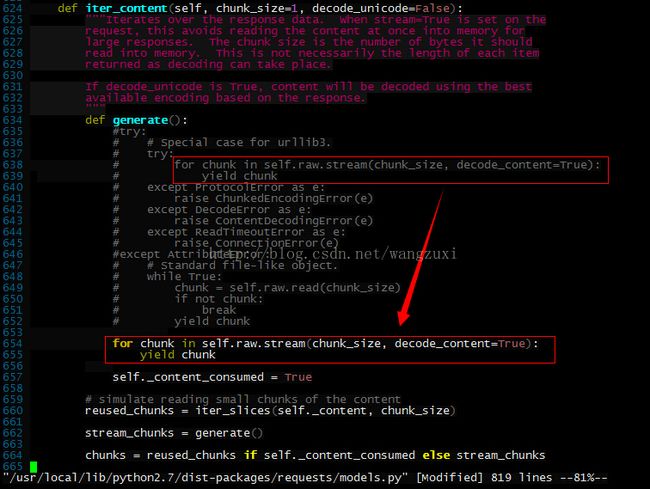
这回出错信息比较细了:
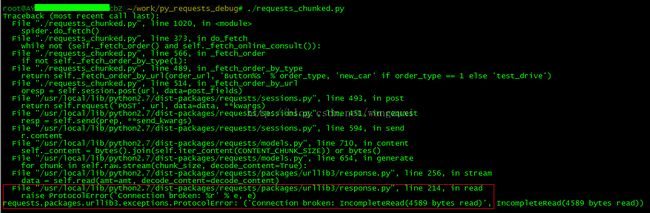
同样追踪/usr/local/lib/python2.7/dist-packages/requests/packages/urllib3/response.py第214行:
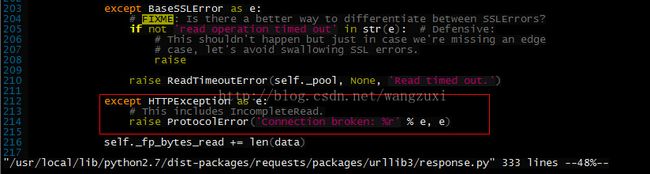
同样也是把这个except分支注掉,让上一层异常信息暴露出来:
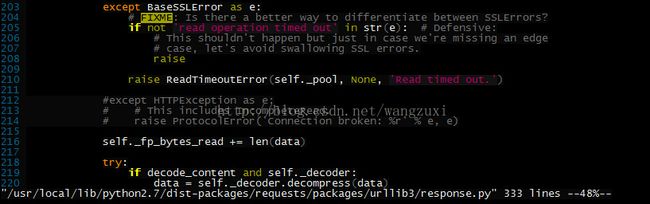
这回的出错信息为:

vim /usr/lib/python2.7/httplib.py +586

从Traceback可以看出是第586行抛的异常,而这里try分支只有第581行一行代码: chunk_left = int(line, 16),这句代码的意思是将十六进制字符串line转换成整型,这时先想到的是line值到底是什么,用pdb调试器跟一下就知道了:

可以看出接收第一个chunked正常,第二次时line为空,导致int转换时出异常,元凶终于找到了,那为什么line为空呢,line是self.fp.readline返回的,应该是tcp连接被关闭了,用tcpdump抓包下来看的确是收到了fin包,在windows下用浏览器正常访问,用Fiddler看看具体的HTTP包交互过程,导致问题的这个chunked包文件内容是完整的,但最后没有结束chunked,包太大就不截图了,自己写个php验证了一下:
';
ob_flush();
flush();
?>HTTP/1.1 200 OK
Date: Thu, 23 Oct 2014 00:58:43 GMT
Server: Apache/2.4.9 (Win32) OpenSSL/1.0.1g PHP/5.5.11
X-Powered-By: PHP/5.5.11
Keep-Alive: timeout=5, max=100
Connection: Keep-Alive
Transfer-Encoding: chunked
Content-Type: text/html
1b
xxxxxxxxxxxxxxxxxxxxxxx
0
导致问题的chunked包大概是这样:
HTTP/1.1 200 OK
Date: Thu, 23 Oct 2014 00:41:31 GMT
Server: Apache/2.4.9 (Win32) OpenSSL/1.0.1g PHP/5.5.11
X-Powered-By: PHP/5.5.11
Keep-Alive: timeout=5, max=100
Connection: Keep-Alive
Transfer-Encoding: chunked
Content-Type: text/html
1b
xxxxxxxxxxxxxxxxxxxxxxx
解决方案:
方案1、修改httplib.py第581行为:
chunk_left = int(line, 16) if line else 0
方案2、自己的程序忽略这个异常;(我自己最开始也是这么干的,但接收特别大的chunked包时有时时间太长,对端还没发完数据就把tcp连接断掉了,导致数据不完整,最后放弃了这个方案);
方案3、参考http://stackoverflow.com/questions/14442222/how-to-handle-incompleteread-in-python,这个我没试过,不知道咋样;
方案4、用pycurl来代替requests,但必须将HTTP协议版本设置为1.0,否则与方案2无差别,因为Transfer-Encoding:chunked , Connection:keep-alive 都是HTTP 1.1的新特性,如果将自己的HTTP协议版本设置为1.0,那么服务端将不会再返回chunked,而是以TCP分段的方式直接返回整个文件内容,最后重组成一个完整的HTTP包。
def __pypost(self, url, data):
sio = StringIO.StringIO()
c = pycurl.Curl()
c.setopt(pycurl.URL, url)
c.setopt(pycurl.REFERER, url)
c.setopt(pycurl.HTTPHEADER, ['Connection: close', 'Cache-Control: max-age=0', 'Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8', 'Content-Type: application/x-www-form-urlencoded', 'User-Agent: Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/36.0.1985.143 Safari/537.36', 'Content-Type: application/x-www-form-urlencoded', 'Accept-Language: zh-CN,zh;q=0.8'])
c.setopt(pycurl.HTTP_VERSION, pycurl.CURL_HTTP_VERSION_1_0)
c.setopt(pycurl.COOKIE, self.__login_cookie)
c.setopt(pycurl.POST, 1)
c.setopt(pycurl.POSTFIELDS, urllib.urlencode(data, True))
c.setopt(pycurl.CONNECTTIMEOUT, 300)
c.setopt(pycurl.TIMEOUT, 300)
c.setopt(pycurl.WRITEFUNCTION, sio.write)
try:
c.perform()
except Exception, ex:
# print 'error', ex
pass
c.close()
resp = sio.getvalue()
sio.close()
return resp 另外,对于HTTP 1.0来讲,如果一次HTTP的响应内容很多,而且又无法提前预知内容的多少,那么就不使用content-length,输出完成后,直接关闭连接即可,一定程度上来讲,content-length对于HTTP 1.0来讲,是可有可无的;通过wireshark抓包来看也是没有Transfer-Encoding:chunked和Content-Length头部的:
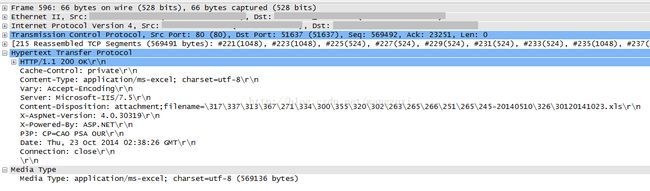
遇到IIS这种web服务器也只能这么对付了。
如果对chunked编码比较熟悉的话直接抓包就能知道原因了,本文只是讲了自己的debug思路,在写程序遇到问题时第一步可能是google之,但有些问题是google不出来的,那就只能深入的研究了,希望本文对你有帮助。
参考:
http://www.tuicool.com/articles/RfAfqa
http://stackoverflow.com/questions/14442222/how-to-handle-incompleteread-in-python