python中一次替换字符串中的多个字符
知识传送门:正则表达式
先直接上解决方案:
比如下面给出的字符串a,有字母、'(单引号)、\n(换行符)、数字、:(冒号)、,(逗号),目标是只保留字符串中的数字和字母,且看我如何操作。
import re
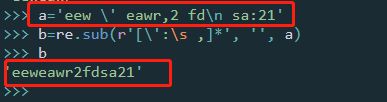
a='eew \' eawr,2 fd\n sa:21'
b=re.sub(r'[\':\s ,]*', '', a) # 前面是正则表达式,匹配多种字符(串)
print(b)具体运行展示一下:
解释一下这个正则表达式的意思:r'[\':\s ,]*'
1:添加r,说明该字符串中全为普通字符(可参考:以r或u开头的字符串,按评论里IwillbecomeAIgod同学的说法是用于防转义),常用于正则表达式
2:[]内是一个字符集,字符集内的字符任何一个被匹配,都算匹配成功,比如r'a[bcd]e',可以匹配到'abe'、'ace'、'ade'。
3:*代表匹配前一个字符0次或无限次。
4:\s代表的是空白字符,比如空格、换行符、制表符等等。
于是r'[\':\s ,]*'组合起来就是匹配字符串中所有的的'(单引号)、\n(换行符)、:(冒号)、,(逗号)
最后re.sub(a, b, string)表示将string中a所匹配到的所有字符通通替换成b,我们这个例子就是将匹配到的'(单引号)、\n(换行符)、:(冒号)、,(逗号)通通替换成''(nothing)。
关于正则表达式,另外我是受了这篇文章的启发(在此感谢):启发就是re.sub可以传给他正则表达式。
在此之前,先试了一下用正则表达式来匹配多个字符串,然后用replace方法行不通,但这个思路也是很正确的,最终还是帮我解决了问题。先看replace:
看看在replace中用上面提到的思路是什么结果:

看到了吗,我的正则表达式可没写错,是replace不行,就是说replace不接受我的正则表达式。
最后让我们来欣赏一首诗吧:
我看到了我的爱恋,
我飞到她的身边
我捧出给她的礼物
那是一小块凝固的时间
时间上有美丽的条文
摸起来像浅海的泥一样柔软
她把时间涂满全身
然后拉起我飞向存在的边缘
这是灵态的飞行
我们眼中的星星像幽灵
星星眼中的我们也像幽灵
——语出《三体》