地图匹配小结
如果您是要做交通轨迹方面的研究,那么地图匹配你一定会遇到,因为要进行后续研究,在数据预处理阶段,必须要做的工作之一就是地图匹配,现在地图匹配算法已经很成熟了,并且已存在开源的代码可用了,那么本文主要就是把从数据,到算法到程序这整个环节走通,做一个总结。
开源地图-OpenStreetMap

OpenStreetMap(OSM)是一款由网络大众共同打造的免费开源、可编辑的地图服务。它是利用公众集体的力量和无偿的贡献来改善地图相关的地理数据。作为一个开源地图,虽然国内数据还不是很完善,但是不管怎样能从上面直接下载地图数据呀,真是极大的方面的我们的生活可科学研究。如果没有他,还真是寸步难行。
下面首先介绍介绍一下如何下载openstreemap的数据,然后介绍一下它的数据格式。
下载数据
在openstreet官网点击导出,然后选择都市摘录,对于中国,里面有北京,上海,广州,成都,重庆等大城市可供下载。我们选择下载北京的数据。

有四中类型的数据,然后数据格式有SHAPEFILE,GEOJSON,OSM PBF,OSM XML等,需要什么样的数据以及什么格式的数据,点击下载即可。
下载之后,如果想要查看数据,这里介绍一个工具QGIS,我下载的数据为beijing_china.osm2pgsql-geojson,里面有三个layer的数据,分别为:
- beijing_china_osm_line.geojson
- beijing_china_osm_point.geojson
- beijing_china_osm_polygon.geojson
如果,我们想要查看每个层数据可视化是怎样的,就可以用QGIS
beijing_china_osm_line.geojson :

beijing_china_osm_line.geojson :
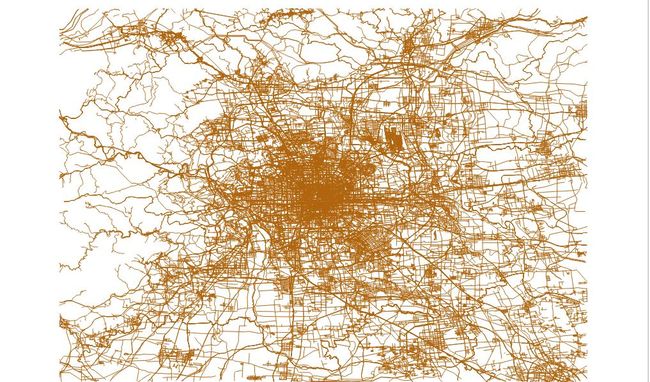
beijing_china_osm_polygon.geojson:
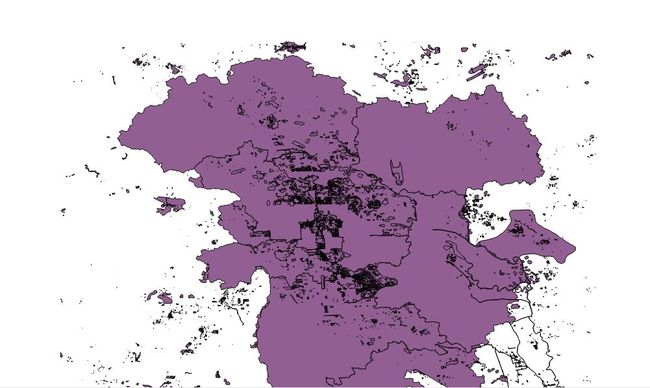
这样能可视化,是不是很方便,对于数据的介绍可以参考这篇博客: OpenStreetMap初探(二)——osm的数据结构
地图匹配算法
关于地图匹配算法介绍的不错的博客有:
地图匹配实践
基于隐马尔可夫的地图匹配算法
上面两篇博客很不错,尤其是第二篇,有兴趣可看看!
地图匹配就是,把车辆的行驶轨迹和电子地图数据库中的道路网进行比较,在地图上找出与行驶轨迹最相近的路线,并将实际定位数据映射到直观的数字地图上。

常用方法:
1、基于几何的方法
点到点,点到线,线到线
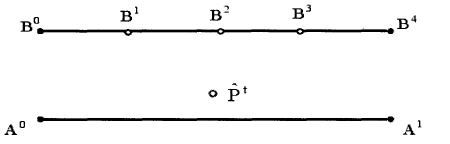
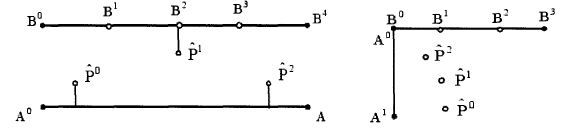
2、基于概率统计得方法
按照统计理论,假设定位系统的方差、协方差矩阵模型为:
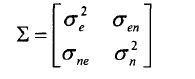
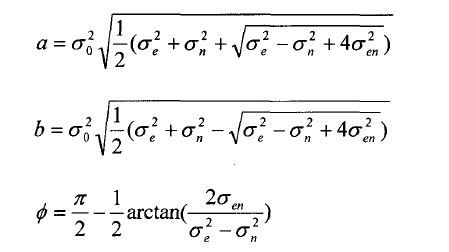
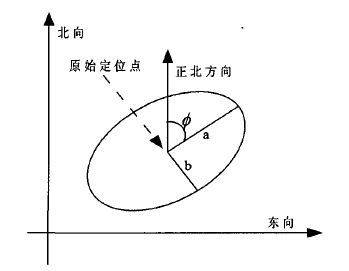
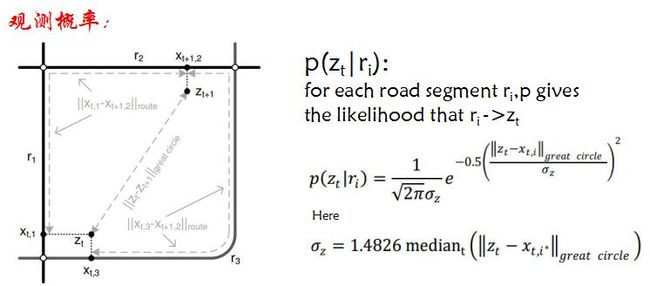
但是上面的方法都有局限,尤其当当GPS点间隔很大时,很不准确,现在比较好的算法就是采用隐马尔科夫模型。
首先回顾下隐马尔可夫模型









地图匹配算法实现及效果
很幸运,现在已经有开源的地图匹配实现了,GITHUB上一搜会出现一大推,这里我介绍一个比较好的,graphhopper-mapmatching,这是一个用java写的地图匹配项目,是作为graphhopper的子项目。
graphhopper-mapmatching早前版本0.6以前吧,用的是几何方法,现在最新的,已经用的是马尔克夫模型了;graphhopper是算是一个地图引擎,里面包含读入OSM数据,构建路网图,并实现了Dijstra算法,A*算法等,可进行最短最快路径导航,这两个项目都非常不错,很有研究价值,具体代码组织和逻辑,有兴趣的可以自己看看!
这里我只列举一下匹配的效果图:
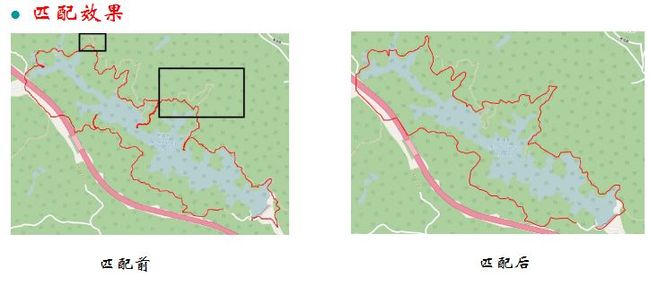
这里比较繁琐的就是轨迹的各种格式,比如plt,csv,gpx,特定场合需要需要特定格式数据,因此,我写了个想换转换的代码,需要的可以直接用:
1、csv文件转换为gpx:
def csv2gpx(infilepath, outfilepath):
data = pd.read_csv(infilepath)
outstring = '\n'
outstring += ' \
'xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" ' \
'xsi:schemaLocation="http://www.topografix.com/GPX/1/1 http://www.topografix.com/GPX/1/1/gpx.xsd">'
outstring += '\n\n'
for i in range(len(data)):
item = ''" lat="' +str(data.lat.values[i])+'">'
outstring = outstring+item+"\n"
outstring += '\n\n '
fw = open(outfilepath, 'w')
fw.write(outstring)
fw.close()
# ------------------------------------------Test----------------------------------
def forfolders():
infilepath = "放csv文件夹"
outfilepath = "存gpx文件夹"
files = os.listdir(infilepath)
for file in files:
csv2gpx(infilepath+"\\"+file, outfilepath+"\\"+file.split('.')[0]+".gpx")
forfolders()2、gpx转换为csv:
import pandas as pd
from xml.dom.minidom import parse
import xml.dom.minidom
import os
# 使用minidom解析器打开 XML 文档
def gpx2csv(infile,outfile):
domtree = xml.dom.minidom.parse(infile)
collection = domtree.documentElement
edgeids=collection.getElementsByTagName("edgeid")
edgeidarray=[]
for i in edgeids:
eid=float(i.childNodes[0].data)
edgeidarray.append(int(eid))
latarray=[]
lonarray=[]
pionts=collection.getElementsByTagName("trkpt")
for piont in pionts:
lat=piont.getAttribute('lat')
latarray.append(lat)
lon=piont.getAttribute('lon')
lonarray.append(lon)
data=pd.DataFrame({'lon':lonarray,'lat':latarray,'edgeid':edgeidarray})
data[['lon','lat','edgeid']].to_csv(outfile,index=False)
def foreachfile(filespath):
files=os.listdir(filespath)
for file in files:
infilepath=filespath+"\\"+file
outfilepath="放csv文件的文件路径"
gpx2csv(infilepath,outfilepath)
foreachfile("存gpx文件的文件夹")3、PLT转换为CSV:
import pandas as pd
def plt2csv(filename):
filepath=“PLT文件路径”
fr = open(filepath)
array = fr.readlines() # 以文件中的每行为一个元素,形成一个list列表
index = 1
data=[]
for line in array:
if index > 6:
line = line.strip() # 去掉一行后的回车符号
linelist = line.split(',') # 将一行根据分割符,划分成多个元素的列表
linelist[5]=linelist[5]+' '+linelist[6]
linelist.pop()
data.append(linelist)
index += 1
data = pd.DataFrame(data, columns=['lat', 'lon', 'datatype', 'altitude', 'date1', 'datetime'])
outfilepath = “输出路径”
data[['lon', 'lat', 'altitude', 'datetime']].to_csv(outfilepath, index=False) #将自己感兴趣的列输出总结
感谢大神的博客,以及开源社区github上的开源代码提供的帮助!