数据结构入门系列——排序
本章仅考虑递增排序
基本概念
1.在排序过程中,若整个表都是放在内存中处理,排序时不涉及数据的内、外存交换,则称之为内排序。
若排序过程中要进行数据的内、外存交换,则称之为外排序。
2.根据内排序算法是否基于关键字的比较,将内排序算法分为基于比较的排序算法和不基于比较的排序算法(基数排序)。
3.基于比较的排序算法性能:

方法分类

内排序:(内存里完成)【重点掌握】
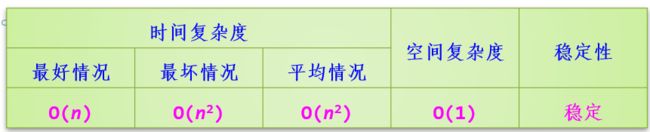
1)插入排序:直接插入(算法排序过程,时间复杂度,空间O(1)复杂度,稳定的排序)
二分直接插入排序(.....)
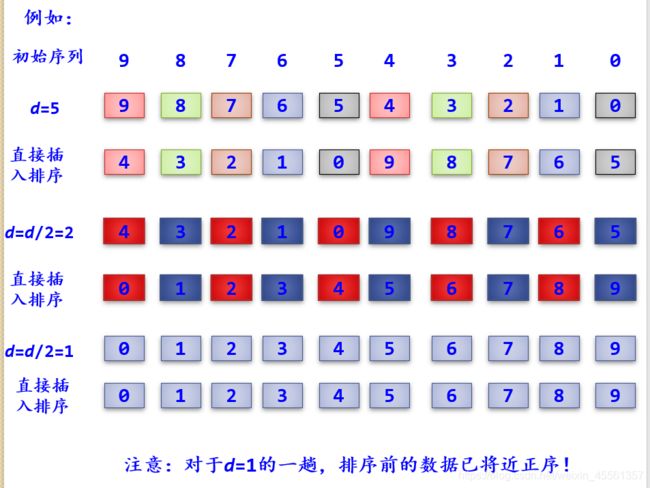
希尔排序(掌握排序的过程,希尔值(d = n / 2.....d = 1),时间空间O(1)复杂度
不稳定的排序)
2)交换排序:冒泡(重点掌握算法,排序过程,时间空间O(1)复杂度,稳定排序)
快速排序(采用递归是形式,对数据按某一基准分组,排序过程,递归展开的
过程,时间空复杂度,不稳定的排序,O(1))
3)选择排序:简单选择排序:(算法排序过程,时间复杂度,空间O(1)复杂度,不稳定的排序)
堆排序:(堆(二叉完全树)的建立,),堆的筛选从下标为 n / 2 结点开始删选,
筛选到根结点(编号是1)结束。时间复杂O(nlog2n),空间复杂度是
O(1),不稳定排序。
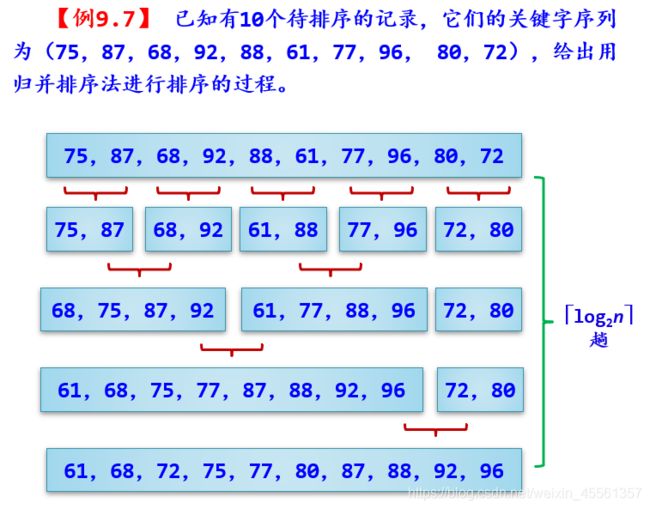
4)归并排序:2路归并排序:排序过程,时间复杂度,空间复杂度O(n),是稳定排序。
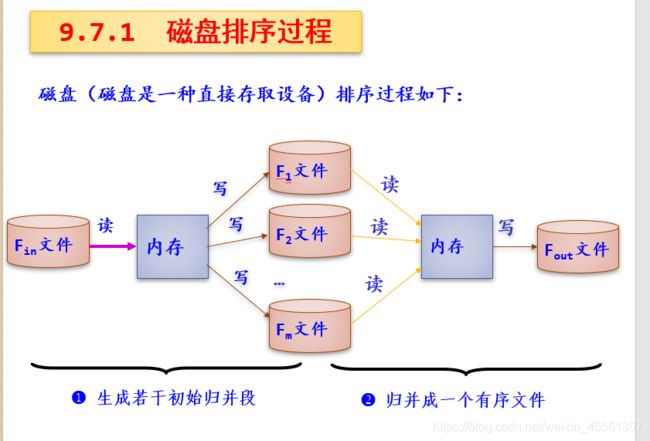
外排序:(外存数据---- > 内存排序---- > 外存;多次交换数据和排序,然后就采用归并
方式排序一个数据量很大的文件)。
在社会生活中,是否存在大量数据的外排序?其实很少存在?
参考动态查找。
详细介绍
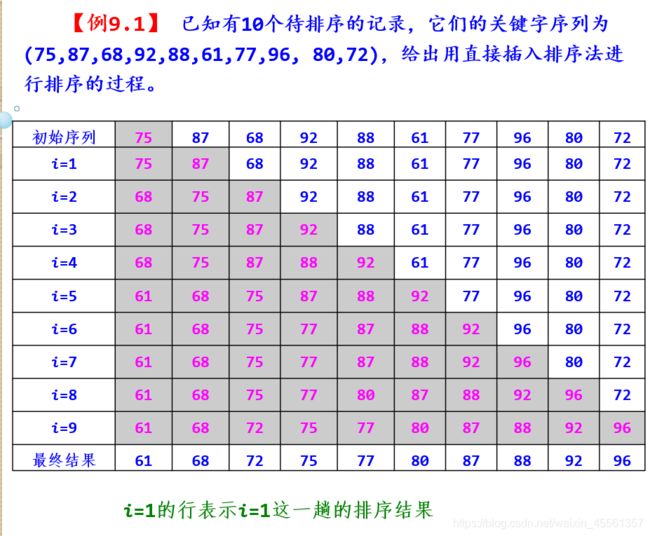
直接插入排序

折半插入排序
void BinInsertSort(SqType R[],int n)
{
int i,j,low,high,mid; SqType tmp;
for (i=1;i<n;i++)
{
if (R[i-1].key>R[i].key)
{
tmp=R[i]; //将R[i]保存到tmp中
low=0;high=i-1;
while (low<=high) //在R[low..high]中折半查找
{
mid=(low+high)/2; //取中间位置
if (tmp.key<R[mid].key)
high=mid-1; //插入点在左半区
else
low=mid+1; //插入点在右半区
}
for (j=i-1;j>=high+1;j--) //元素后移
R[j+1]=R[j];
R[high+1]=tmp; //插入原来的R[i]
}
}
}

希尔排序

void ShellSort(SqType R[],int n)
{
int i,j,d;
SqType tmp;
d=n/2; //增量置初值
while (d>0)
{
for (i=d;i<n;i++)
{
tmp=R[i]; //对所有相隔d位置的记录组采用直接插入排序
j=i-d;
while (j>=0 && tmp.key<R[j].key)
{
R[j+d]=R[j];
j=j-d;
}
R[j+d]=tmp;
}
d=d/2; //减小增量
}
}
冒泡排序

void BubbleSort(SqType R[],int n)
{
int i,j,exchange;
SqType tmp;
for (i=0;i<n-1;i++)
{
exchange=0; //本趟排序前置exchange为0
for (j=n-1;j>i;j--) //比较,找出最小关键字的记录
if (R[j].key<R[j-1].key)
{
tmp=R[j]; //R[j]与R[j-1]进行交换,
R[j]=R[j-1]; //将最小关键字记录前移
R[j-1]=tmp;
exchange=1; //本趟排序发生交换置exchange为1
}
if (exchange==0) //本趟未发生交换时结束算法
return;
}
}
快速排序


void QuickSort(SqType R[],int s,int t)
//对R[s..t]的记录进行递增快速排序
{
int i=s,j=t; SqType tmp;
if (s<t) //区间内至少存在一个记录的情况
{
tmp=R[s]; //用区间的第1个记录作为基准
while (i!=j) //从区间两端交替向中间扫描,直至i=j为止
{
while (j>i && R[j].key>=tmp.key)
j--; //从右向左扫描,找第1个小于tmp.key的R[j]
R[i]=R[j]; //将R[j]前移到R[i]的位置
while (i<j && R[i].key<=tmp.key)
i++; //从左向右扫描,找第1个大于tmp.key的R[i]
R[j]=R[i]; //将R[i]后移到R[j]的位置
}
R[i]=tmp;
QuickSort(R,s,i-1); //对左区间递归排序
QuickSort(R,i+1,t); //对右区间递归排序
}
}
堆排序

过程


//调整堆
void Sift(SqType R[],int low,int high)
//对R[low..high]进行堆筛选
{
int i=low,j=2*i; //R[j]是R[i]的左孩子
SqType tmp=R[i];
while (j<=high)
{
if (j<high && R[j].key<R[j+1].key)
j++; //若右孩子较大,把j指向右孩子
if (tmp.key<R[j].key)
{
R[i]=R[j]; //将R[j]调整到双亲结点位置上
i=j; //修改i和j值,以便继续向下筛选
j=2*i;
}
else break; //已是大根堆,筛选结束
}
R[i]=tmp; //被筛选结点的值放入最终位置
}
//排序
void HeapSort(SqType R[],int n)
//对R[1..n]进行递增堆排序
{
int i;
SqType tmp;
for (i=n/2;i>=1;i--) //循环建立初始堆
Sift(R,i,n);
for (i=n;i>=2;i--) //进行n-1次循环,完成堆排序
{
tmp=R[1]; //将R[1]和R[i]交换
R[1]=R[i]; R[i]=tmp;
Sift(R,1,i-1); //筛选
}
}
归并排序

void Merge(SqType R[],int low,int mid,int high)
//将R[low..mid]和R[mid+1..high]两个相邻的有序表归并为有序表R[low..high]
{
SqType *R1;
int i=low,j=mid+1,k=0; //k是R1的下标
R1=(SqType *)malloc((high-low+1)*sizeof(SqType));
//动态分配空间R1
while (i<=mid && j<=high) //均未扫描完时循环
if (R[i].key<=R[j].key) //将第1子表中的记录放入R1中
{
R1[k]=R[i];
i++;k++;
}
else //将第2子表中的记录放入R1中
{
R1[k]=R[j];
j++;k++;
}
while (i<=mid) //将第1子表余下部分复制到R1
{
R1[k]=R[i];
i++;k++;
}
while (j<=high) //将第2子表余下部分复制到R1
{
R1[k]=R[j];
j++;k++;
}
for (k=0,i=low;i<=high;k++,i++)
R[i]=R1[k]; //将R1复制回R中
free(R1); //释放R1所占内存空间
}
void MergePass(SqType R[],int length,int n)
//一趟二路归并排序
{
int i;
for (i=0;i+2*length-1<n;i=i+2*length)
Merge(R,i,i+length-1,i+2*length-1);
//归并length长的两相邻子表
if (i+length-1<n) //余下两个子表,后者长度小于length
Merge(R,i,i+length-1,n-1);
}
void MergeSort(SqType R[],int n) //二路归并算法
{
int length;
for (length=1;length<n;length=2*length)
MergePass(R,length,n);
}
基数排序




typedef struct rnode
{
char key[MAXD]; //存放关键字
ElemType data; //存放其他数据
struct rnode *next;
} RadixNode; //单链表结点类型
void RadixSort1(RadixNode *&h,int d,int r)
//最高位优先基数排序算法
//实现基数排序:h为待排序数列单链表指针,r为基数,d为关键字位数
{
RadixNode *head[MAXR]; //建立链队队头数组
RadixNode *tail[MAXR]; //建立链队队尾数组
RadixNode *p,*tc;
int i,j,k;
for (i=d-1;i>=0;i--) //从高位到低位循环
{
for (j=0;j<r;j++) //初始化各链队首、尾指针
head[j]=tail[j]=NULL;
p=h;
while (p!=NULL) //分配:对于原链表中每个结点循环
{
k=p->key[i]-'0'; //找第k个链队
if (head[k]==NULL) //第k个链队空,队头队尾均指向p结点
head[k]=tail[k]=p;
else
{
tail[k]->next=p; //第k个链队非空时,p结点入队
tail[k]=p;
}
p=p->next; //取下一个待排序的元素
}
h=NULL; //重新用h来收集所有结点
for (j=0;j<r;j++) //收集:对于每一个链队循环
if (head[j]!=NULL) //若第j个链队是第一个非空链队
{
if (h==NULL)
{
h=head[j];
tc=tail[j];
}
else //若第j个链队是其他非空链队
{
tc->next=head[j];
tc=tail[j];
}
}
tc->next=NULL; //尾结点的next域置NULL
}
}
外排序