phoenix修改表中字段的数据类型
使用phoenix修改表中的字段数据类型
本文部分转自 https://blog.csdn.net/yuanhaiwn/article/details/82141923
软件环境:
hbase version 2.1.0-cdh6.1.0
phoneix version phoenix-5.0.0-HBase-2.0
Phoenix的表是映射hbase的表,hbase存储的数据都是字节数组, 因此, 限制数据类型的只能是Phoenix自己, 所以, 我们就可以通过修改Phoenix元数据的方式修改表中字段的数据类型.
Phoenix中有5张系统表,存储表相关的信息

其中表的元数据信息存储在SYSTEM.CATALOG表中
desc查看SYSTEM.CATALOG表的结构


1.创建一张表
CREATE TABLE IF NOT EXISTS mytest (
name VARCHAR(40) NOT NULL PRIMARY KEY,
id VARCHAR(20),
score VARCHAR(16),
level VARCHAR(20),
addr VARCHAR(40));

2.插入数据
upsert into mytest values(‘tom’,‘001’,‘89.5’,‘A’,‘China’);
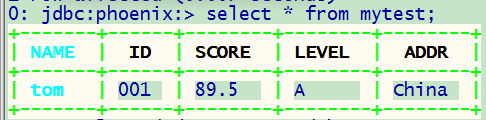
写入成功,但是,我现在需要将score改为float类型的数据类型
3.查看元数据信息
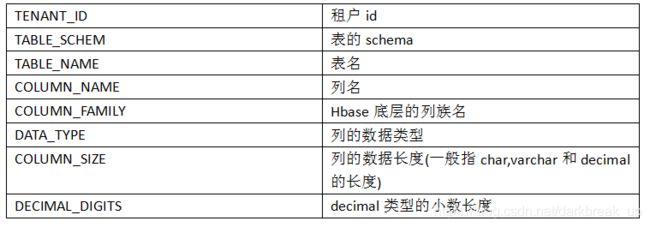
select TENANT_ID,TABLE_SCHEM,TABLE_NAME,COLUMN_NAME,COLUMN_FAMILY,DATA_TYPE,COLUMN_SIZE,DECIMAL_DIGITS from SYSTEM.CATALOG where TABLE_NAME=‘MYTEST’;

各个字段的含义:
4. 修改元数据

4.1 修改字段长度
upsert into SYSTEM.CATALOG (TENANT_ID,TABLE_SCHEM,TABLE_NAME,COLUMN_NAME,COLUMN_FAMILY,COLUMN_SIZE) values(’’,’’,‘MYTEST’,‘SCORE’,‘0’,6);

可以看出修改COLUMN_SIZE可以修改SCORE的字段长度
4.2 修改字段数据类型
upsert into SYSTEM.CATALOG (TENANT_ID,TABLE_SCHEM,TABLE_NAME,COLUMN_NAME,COLUMN_FAMILY,DATA_TYPE) values(’’,’’,‘MYTEST’,‘SCORE’,‘0’,6);

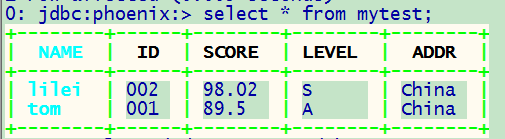
可以看到SCORE的数据类型改为了FLOAT
- 验证
upsert into mytest values(‘lilei’,‘002’,‘98.02’,‘S’,‘China’);
- 数据类型和数据名称对应关系

- 补充
在参考文章中看到作者强调改完字段数据长度之后,需要重启hbase才能生效,但是本次测试中,修改完之后字段之后,可以直接写入新的类型的数据不会出错
此外,对于也可以通过upsert into的方式修改SYSTEM.CATALOG表中的可以修改小数点长度DECIMAL_DIGITS等等.