1. 网站分析
本篇文章使用 requests 库抓取糗事百科网的段子。读者可以点击 此处 访问糗事百科段子页面。页面如下图所示:

在页面的下方是带有数字链接的导航条,可以切换到不同的页面,每一页会显示 25 个段子。所以要实现抓取多页段子的爬虫,不仅要分析当前页面的 HTML 代码,还要可以抓取多页的 HTML 代码。
现在切换到其他页面,看一下 URL 的规律。第 1、2、3 页对应的 URL 如下:
https://www.qiushibaike.com/text/page/1/
https://www.qiushibaike.com/text/page/2/
https://www.qiushibaike.com/text/page/3/
从 URL 的规律可以看出,页面索引是通过 URL 最后的数字指定的。第 1 页,数字就是 1,第 12 页,数字就是 12 ,很容易根据这个规律得到任意页面的 URL。现在的主要任务是分析每一个页面的 HTML 代码,读者可以按 F12 在开发者工具中跟踪相关部分的 HTML 代码,如下图所示:
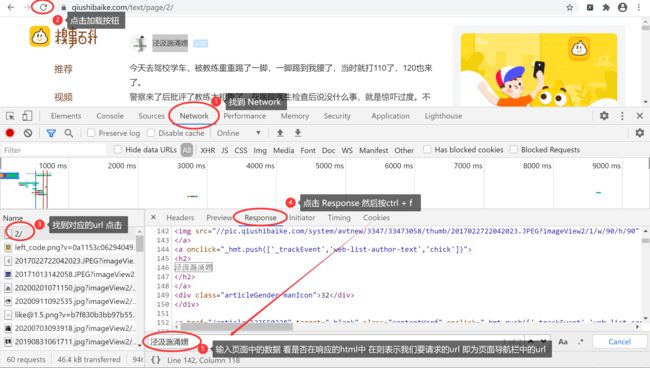

本文主要是使用 正则表达式 进行数据解析,如果不懂 正则表达式 的读者 可以看博主此篇文章:Python爬虫数据抽取(三):正则表达式 可以在 Pycharm 中进行 正则表达式 的验证。

糗事百科的 HTML 代码相对比较规范,特定 HTML 的位置也比较好找。例如,要想定位鉴别性别的 HTML 代码,可以定位到下面的 HTML 代码。
<div class="articleGender manIcon">34div>
通过 manIcon 可以识别发这条段子的用户是男性,女性是 womenIcon。
2. 示例代码
根据前面的描述和实现方式,编写一个用于抓取 13 页糗事百科段子的爬虫,并将抓取结果保存在名为 jokes.txt 的文件中。示例代码如下:
"""
@author:AmoXiang
@file:3.抓取糗事百科网的段子.py
@time:2020/09/11
"""
import requests
import re
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.83 Safari/537.36'
}
joke_list = []
def verify_sex(class_name):
if class_name == "womenIcon":
return '女'
else:
return '男'
def get_joke(url):
res = requests.get(url=url, headers=headers)
text = res.text
print(text)
id_list = re.findall(r'(.*?)
', text, re.S)
level_list = re.findall(r'(\d+)
', text)
sex_list = re.findall(r'\d+
', text)
content_list = re.findall(r'.*?
(.*?)'
, text
, re
.S
)
laugh_list
= re
.findall
(r
'(\d+)', text, re.S)
comment_list = re.findall(r'(\d+) 评论', text)
for id, level, sex, content, laugh, comment in zip(id_list, level_list, sex_list, content_list, laugh_list,
comment_list):
id = id.strip()
sex = verify_sex(sex)
content = content.strip().replace('
', '')
info = {
'id': id,
'level': level,
'sex': sex,
'content': content,
'laugh': laugh,
'comment': comment
}
joke_list.append(info)
if __name__ == '__main__':
url_list = ["https://www.qiushibaike.com/text/page/{}/".format(i) for i in range(1, 14)]
for url in url_list:
get_joke(url)
for joke in joke_list:
f = open("./jokes.txt", 'a', encoding="utf8")
try:
f.write(joke['id'] + "\n")
f.write(joke['level'] + "\n")
f.write(joke['sex'] + "\n")
f.write(joke['content'] + "\n")
f.write(joke['laugh'] + "\n")
f.write(joke['comment'] + "\n\n")
except Exception:
pass
finally:
f.close()
运行程序,会看到当前目录多了一个 jokes.txt 文件,内容如下图所示:

以上内容仅为技术学习交流使用,请勿采集数据进行商用,否则后果自负,与博主无关,如有侵权,联系博主删除,编写不易,手留余香~。