STAMP:Short-TermAttention/MemoryPriorityModelfor Session-basedRecommendation
基于会话的推荐的短期注意/记忆优先级模型
摘要
然而,现有的方法都没有明确考虑到用户当前操作对其下一步行动的影响。
在本研究中,我们认为长期记忆模型可能不足以对长会话进行建模,而长会话通常包含由意外点击引起的用户兴趣漂移。提出了一种新的短期注意/记忆优先级模型,该模型能够从会话上下文的长期记忆中获取用户的一般兴趣,同时考虑到用户当前的兴趣来自于最后一次点击的短期记忆。在2015年RecSys挑战赛和2016年CIKM杯的三个基准数据集上,对所提出的注意机制的有效性和有效性进行了广泛的评估。数值结果表明,该模型在所有试验中均取得了较好的性能。
introduction
基于已有文献,几乎所有基于rnnr的SRS模型都只考虑将会话建模为一个项目序列,而没有明确考虑到用户兴趣随[6]时间的漂移,这在实践中可能存在问题。例如,如果用户刚刚单击了某个特定的数码相机链接并将其记录在会话中,那么用户的下一步操作很可能是响应当前操作。(1)如果当前的操作是在做出购买决定之前浏览产品描述,那么用户很可能在下一步访问另一个数码相机品牌目录。(2)如果当前的操作是将相机添加到购物车中,那么用户的浏览兴趣可能会被更改为其他外设,如存储卡。在这种情况下,向该用户推荐另一台数码相机不是一个好主意,尽管这个会话的最初意图是购买一台数码相机(如前面的操作所反映的)。
在典型的SRS任务中,会话由一系列命名项组成,用户的兴趣隐藏在这些隐式的反馈中(例如,单击)。为了进一步提高RNN模型的预测精度,必须同时具备学习这种隐式反馈的长期利益和短期利益的能力。正如Jannach等人[7]所指出的,用户的短期兴趣和长期兴趣对于推荐都是非常重要的,但是传统的RNN架构并没有同时区分和利用这两类兴趣[11]。
在本研究中,我们考虑通过在SRS模型中引入一个近期的动作优先机制,即短时注意/记忆优先(STAMP)模型来解决这个问题,该模型可以同时考虑用户的一般兴趣和当前兴趣。在STAMP中,用户的兴趣通常由一个外部内存捕获,该内存由会话前缀中的所有历史单击(包括最后一次单击)构建而成,这就是术语“内存”的含义所在。术语“last-click”表示会话前缀的最后一个操作(项),SRS的目标是预测与此“last-click”相关的“next click”。在本研究中,我们使用了嵌入last-click来表示用户当前的兴趣,并在此基础上构建了提出的注意机制。由于last-click是外部内存的一个组成部分,所以可以看作是用户兴趣的短期内存。同样,建立在最后一次点击之上的用户注意力可以被看作是短期的注意力。据我们所知,这是第一次在构建基于会话的推荐的神经注意模型时同时考虑长/短期记忆。本研究的主要贡献如下:
- 我们引入了一个短期注意力/记忆优先级模型:(a)一个包含跨会话项的统一嵌入空间;(b)一个用于基于会话的推荐系统中下一次点击预测的新神经注意力模型。
- 针对STAMP模型的实现,提出了一种新的注意机制,该机制根据会话上下文计算注意权重,并根据用户当前的兴趣进行增强。输出的注意向量被解读为用户时间兴趣的合成表示,并且比其他基于神经注意的解决方案更敏感于用户兴趣随时间的漂移。因此,它能够同时捕捉用户的长期兴趣(响应最初的目的)和短期注意(当前的兴趣)。通过对比研究,验证了该注意机制的有效性和有效性。
- 本模型分别在两个现实世界数据集上进行了评估,分别是来自RecSys 2015的Yoochoose数据集和来自CIKM Cup 2016的Diginetica数据集。实验结果表明,该方法达到了目前的水平,所提出的注意机制发挥了重要作用。
method
每一个session 由 S = [s1,s2, . . .,sN ] 表示,St = {s1,s2, . . .,st }表示一个截断的序列。
V = {v1,v2, . . .,v |V |} 是所有的item,item词典,X ={x1,x2, . . .,x|V |} 是item的embedding。
yˆ = {yˆ1,yˆ2, … .,yˆ|V |} 表示输出的score 向量,yˆi 对应于item vi 的分数,topk用来预测。
为便于标注,我们将三个向量的三线性乘积定义为:
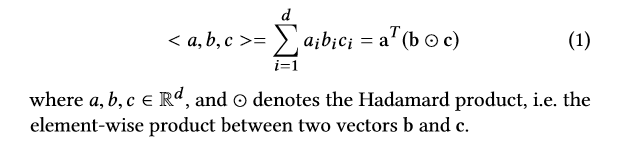
短期记忆优先模型
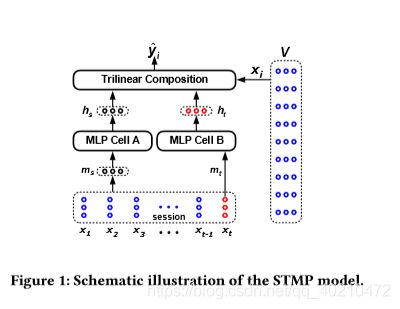
STAMP 模型展示为图1.
从图1可以看出,STMP模型以两个embeddings (ms和mt)作为输入,其中ms表示用户对当前会话的总体兴趣,定义为会话external记忆的平均值:
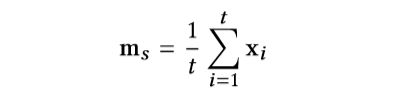
其中,**external memory 一词是指嵌入当前会话St的以前的项序列。?**符号mt表示该会话中用户当前的兴趣,在本研究中,使用lastclick xt表示用户当前的兴趣:mt =xt。由于xt是从会话的external memory中提取的,所以我们将其称为用户兴趣的短期内存。然后利用两个MLP网络对一般兴趣ms和当前兴趣mt进行处理,实现特征提取。图1中所示的MLP单元的网络结构彼此相同,只是它们具有独立的参数设置。使用一个简单的没有隐藏层的MLP进行特征抽象,对ms的操作定义为:

where hs ∈ Rd denotes the output state, Ws ∈ Rd×d is
a weighting matrix, and bs ∈ Rd is the bias vector. f (·) is a non-linear activation function (we use tanh in this
study).
与 mt 相关的 状态向量ht计算与hs相似。
对于每一个候选item,计算score的方程为
![]() 让
让
让zˆ ∈ R|V | 表示 三个向量的点积,每一个zi 表示了非归一化的余弦相似度,表示用户兴趣之间与当前会话前缀st和候选项xi之间的。
然后经过一个softmax函数,
![]()
使用交叉熵函数计算loss,
y表示由groundtruth激活的one-hot向量。
The STAMP Model
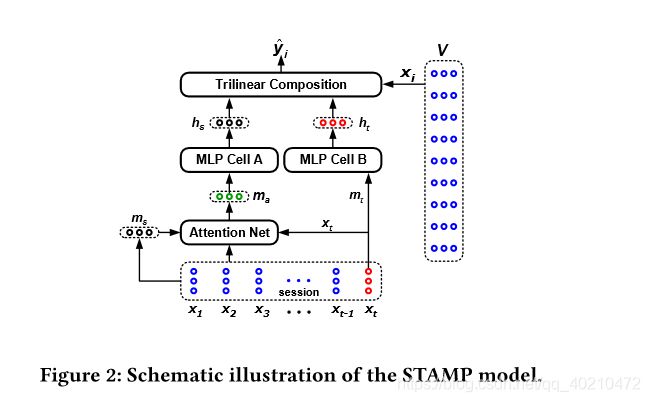
注意力网络
1)一个简单的前馈神经网络(FNN)负责生成注意重量为每个项目在当前会话st,和(2)注重复合函数负责计算在注ma基于用户的兴趣的注意力。用于注意力计算的FNN定义为:

注意,式7中明确考虑了短时记忆,这与相关著作有明显不同,这就是为什么提出的注意模型被称为短时注意优先模型。
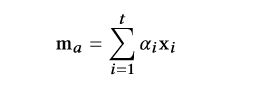
再将ms加到这个上下文向量 ma中。
the short -Term memory only model
评估的有效性本研究的基本理念,也就是说,将优先分配给用户的短期关注/记忆行为决策根据会话(序列的动作),在本节中,我们提出一个短期记忆(STMO)模型,使预测的再次单击st+1只基于当前会话前缀的last-click st。
与STMP模型类似,在STMO模型中使用一个没有隐藏层的简单MLP进行特征抽象。MLP将last-click st作为输入,输出一个向量ht∈Rd,与STMP中的“MLP CELL B”一样(见图1),定义为:
 当给定一个候选item,score 被计算为 ht和xi的点积,
当给定一个候选item,score 被计算为 ht和xi的点积,

实验
-
数据 Recsy’15 挑战 网址:[1] http://2015.recsyschallenge.com/challege.html包含电商平台六个月的点击流
-
Diginetica dataset coming from the CIKM Cup 2016 http://cikm2016.cs.iupui.edu/cikm-cup 只使用了交互数据
-
过滤掉长度小于1 的session,出现次数小于5的item
-
Yoochoose的测试集由与训练集相关的后续几天的会话组成,我们过滤掉训练集中没有出现的点击(条目)。对于Diginetica,唯一的区别是我们使用后续一周的会话进行测试。在预处理阶段之后,Yoochoose dataset中还有7,966,257个会话,共37,483个条目,共点击31,637,239次;Diginetica dataset中还有202,633个会话,共43,097个条目,点击982,961次。
-
与[相同,我们使用序列分割预处理,对于输入会话S = {s1,s2,…,sn},我们生成序列和相应的标签([s1], s2), ([s1, s2], s3)…([s1, s2,…,sn - 1], sn)对两个数据集进行训练和测试,证明是有效的。
-
由于Yoochoose训练集比较大,根据[17]的实验,对最近一部分的训练比对整个部分的训练效果更好,所以我们使用了最近部分1/64和1/4的训练序列。这三个数据集的统计数据如表1所示。
-

-
评测指标
-
P@20 P @ K表示测试用例中在排名列表的前K位拥有正确推荐项目的比例。其中N表示SRS系统G中测试数据的个数,nhit表示在前K个排名列表中拥有所需项目的案例的个数,当t出现在G的排名列表的前K个位置时,就发生了hit。
-
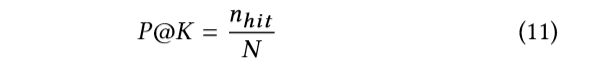
-
MRR @20: 所需项的倒数秩的平均值t.如果秩大于20,则倒数秩为零。
-

-
MRR是一个标准化的范围分数[0,1],其值的增加反映了大多数“点击率”在推荐列表的排名中会出现更高的排名,这表明相应的推荐系统性能更好。