python3爬虫学习笔记之Ajax数据爬取(七)
有了以上章节的学习,相信一般静态网页的爬取已经是轻而易举的事情了,但是,在实际爬虫中,经常会遇到动态网页,在我们用requests抓取页面时,得到的结果和在浏览器中看到的不一样。
Ajax数据爬取
Ajax即一种异步加载数据的方式,原始的页面不会包含数据,原始页面加载完毕后,会向服务器请求接口获取数据,然后数据被处理再显示在页面上。现在的趋势是,原始HTML不包含任何数据,数据都是通过Ajax统一加载然后呈现,这样即前后端分离!!!
那么我们爬取Ajax数据的原理就是我们使用Requests来模拟Ajax请求!Ajax三步:发送请求,解析内容,渲染页面
Ajax是由JS来实现的,实际上就是执行了下面的代码:
var xmlhttp;
if (window.XMLHttpRequest) {
// code for IE7+, Firefox, Chrome, Opera, Safari
xmlhttp=new XMLHttpRequest();
} else {// code for IE6, IE5
xmlhttp=new ActiveXObject("Microsoft.XMLHTTP");
} # 新建XMLHttpRequest对象
xmlhttp.onreadystatechange=function() {
if (xmlhttp.readyState==4 && xmlhttp.status==200) {
document.getElementById("myDiv").innerHTML=xmlhttp.responseText;
}
} # 调用了onreadystatechange属性设置了监听
xmlhttp.open("POST","/ajax/",true);
xmlhttp.send(); # 最后使用了open() 和 send() 方法向服务器发送了请求
由于设置了监听,所以服务器返回响应的时候,onreadystatechange设置的监听方法也会被调用,我们只需要在这个方法里面解析响应内容就可以了。我们可以使用xmlhttp 的 responseText 属性来获取响应的内容。
实例引入
以崔庆才微博主页(该笔记为崔庆才python3爬虫实战笔记)为例:https://m.weibo.cn/u/2830678474,一直下滑,可以发现下滑几个微博之后,就没有了,转而出现一个加载动画,然后继续出现新的微博内容,这个过程就是Ajax加载的过程。
1. 查看请求
开发者模式中Elements选项卡里面是网页的源代码,右侧是节点的样式
Network选项卡里面是页面加载过程中浏览器和服务器之间发送request和response的记录,如果我们想搜取Ajax记录,我们可以在filter里面选取XHR,得到的结果就全都是Ajax请求了。
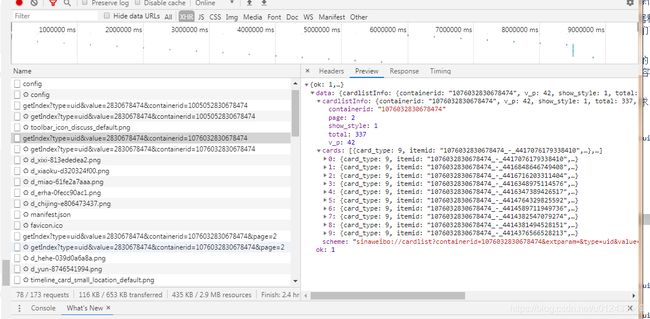
点开任意一个请求条目,我们都可以清楚的看到Request URL、Request Headers、Response Headers、Response Body等内容,基于这些内容我们就可以模拟出来Ajax请求了。
下拉页面,我们可以看到在不断发出Ajax请求(以getIndex开头,type为uid),我们随便点开一个:
可以看到是get请求,请求的链接为:https://m.weibo.cn/api/container/getIndex?type=uid&value=2830678474&containerid=1076032830678474&page=2
2. 过滤请求
接下来,再利用Chrome开发者工具的筛选功能筛选出所有的Ajax请求,点击XHR,此时下方显示的所有请求便是Ajax请求了。
3. 分析请求
然后我们观察其他的请求,我们可以发现,按前面可知,请求中有Type,value,containerid,page四个参数,前三个参数都没有变化,只有第四个控制分页的有变化。
4. 分析响应
分析请求的响应内容,内容是json格式的,我们可以看到最关键的内容就是cardlistinfo和cards,前者里面有个total属性,是微博的总数量,可以根据这个数字来估算分页数;后者是一个列表,代表每一篇博文,每个博文里面有个mblog,里面是微博内容的信息,比如attritudes_count(点赞数)、text(微博正文)等。
这样我们请求一个接口,就可以得到10条微博,而且请求时只需要改变page参数即可。

5. 抓取内容
抓取前10页微博。
代码见weibo_text.py
# weibo_text.py
# -*- coding: utf-8 -*-
"""
Created on Mon Sep 16 14:26:28 2019
@author: Administrator
"""
from urllib.parse import urlencode
import requests
import json
base_url = 'https://m.weibo.cn/container/getIndex?'
headers = {
'Host':'m.weibo.cn',
'Refere':'https://m.weibo.cn/u/2830678474',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:57.0) Gecko/20100101 Firefox/57.0',
'X-Requested-With':'XMLHttpRequest',
}
def get_page(page):
params = {
'type':'uid',
'value':'2830678474',
'containerid':'1076032830678474',
'page':page
}
url = base_url+urlencode(params)
try:
response = requests.get(url,headers=headers)
if response.status_code==200:
return response.json()
except requests.ConnectionError as e:
print('error ',e.args)
from bs4 import BeautifulSoup
from pyquery import PyQuery as pq
def parse_page(json):
if json:
items = json.get('data').get('cards')
for item in items:
item = item.get('mblog')
#print(item)
weibo={}
weibo['id']=item.get('id')
print(item.get('id'))
weibo['attitudes']=item.get('attitudes_count')
print(item.get('attitudes_count'))
weibo['comments']=item.get('comments_count')
print(item.get('comments_count'))
weibo['reposts']=item.get('reporsts_count')
print(item.get('reporsts_count'))
#print(soup.prettify())
soup = BeautifulSoup(item.get('text'),'lxml')
print(soup.prettify())
print(pq(item.get('text')).text())
#print(soup.p.string)
if __name__=='__main__':
for page in range(1,11):
json_text = get_page(page)
results = parse_page(json_text)
如果对你有用,点个赞 手动笑脸(*_*)