实在智能RPA学院|高性能特征工程Pipeline设计要点
当前深度学习技术已经在搜索、广告、推荐等点击率预估及类似场景中得到了广泛和有效的运用,取得了一些突破性的进展。其中一部分进展得益于在隐藏层之外显示构造特征组合,从而弥补神经网络的局部低效表达能力。从这个角度看,特征交叉等传统的特征工程技术仍将在一定时间内继续存在。另一方面,在工业场景中,作为基线的LR/FTRL模型或者GBDT模型,也是考察深度神经网络效果的必要对照实验组,甚至是初次场景建模的首选打底方案。
本文主要介绍配合这类方法的关键技术设计要点:高性能特征工程的Pipeline设计。这也是实在智能在实施AI赋能过程中算法积淀的产物之一,已在多个大规模数据应用场景得到效果和性能等多方面的验证。
一、设计范围
数据类型:结构化数据(Tabular Data)
场景类型:大规模样本、高维稀疏特征、实时特征
非结构化数据不是本文的设计范围,下面只做简单描述。
1.非结构化数据类型
(1)文本、图像、语音数据等
(2) 特点:具有空间或时间相关性
2.一般采用深度学习端到端建模
(1)不同框架提供不同的一致性端到端解决方案
(2) Pytorch/Fastai(离线)— Caffe2(在线)
(3) Keras(离线) — TFX(在线)
3.拥有特定数据预处理工具
(1) TorchText、PyText
(2) TorchImage
(3) TorchAudio
4.特定情况可转换为结构化数据
(1) 文本数据:BOW (高维稀疏:Set Categorical)
二、设计目标
1.一致性
(1)线上排序与离线训练使用同一数据处理Pipeline(必须完全一致)
2.复杂性
(1)十亿级特征维度、支持近实时特征
(2)支持所有的属性转换操作、特征转换操作
3.高性能
(1) 经验条件举例:单机48cores,单次排序请求包含300个物料、十亿级别特征
(2)经验性能举例:平均延迟:30ms;QPS:300次请求/s (每秒约十万次打分)
(3)可以做得更好(例如,指令集优化)
4.扩展性
(1)在线排序
*支持不同服务架构(传统单点、微服务、容器)
*弹性扩展到超大规模并发请求
(2)离线训练
*支持不同数据流框架(批处理、分布式、流式)
* 弹性扩展到超大规模样本数量
三、数据模型
所有系统中只存在三种数据状态类型:
1.属性数据
(1)业务数据的原始形式
(2)是对业务数据的高度抽象(结构化数据的前提下)
2.特征数据
(1)特征工程的数据闭包
3.编码数据
(1)机器学习模型使用的数据形式

四、属性数据及其转换
1.属性数据类型(冒号前是属性名)
(1)Categorical:例如Sex: Male(程序表示:string/int)
(2)Set-Categorical:例如Interests: {sport: 3, ent: 6}(程序表示:[
(3)Real Valued:例如Fail Times: 3(程序表示:float)
(4)Unix Timestamp:例如Occur time: 1546333884(程序表示:float)
2.属性转换
(1)Input:属性数据 =》Output:特征数据
(2)One Output Op
*Sex: Male => Sex_Male: 1.0
* Fail Times: 3 => (Direct Transform) Fail Times: 3.0
(3)Multiple Output Op
*Interests: {sport: 3, ent: 6} => {Interests_Sport: 0.33, Interest_Ent: 0.67}
*Occur time: 1546333884 =>
Weekday: 1.0
Afternoon: 1.0
Festival: 1.0
Tuesday: 1.0
First day of month: 1.0
五、特征数据及其转换
1.特征数据类型(冒号前是特征名)
(1)Discrete Feature Data
*特征值只有0/1两种值
*Sex_Male: 1.0
*Weekday:1.0
(2)Continuous Feature Data
*特征值是连续数值
*Fail Times:3
*Interest_Sport:0.33
2.特征转换
(1)Unary Transform Op
*Cont =》Disc,e.g., Bucketize
*Disc =》Cont,e.g., Lookup Historical Statistics
(2)Binary Transform Op
*Disc^Disc => Disc,e.g., Feature Cross
*Cont^Cont => Cont,e.g., Similarity Feature
(3)有向有环图
*解耦为串行结构的嵌套
*见下节
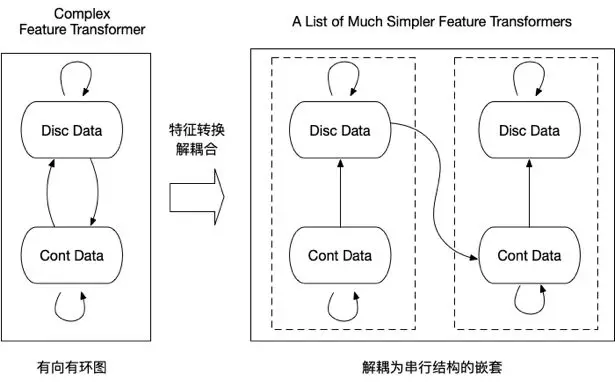
六、特征转换的解耦设计
1.有向有环图 =》串行结构的嵌套
2.优点
(1)简化了工程实现:复杂结构 =》简单结构的串行
(2)虚框之间的转换可以在外部系统中进行(例如,实时特征的构造)
七、编码数据及其转换
编码数据类型(冒号前是特征编码,冒号后是特征值)
1. Hash Encoding
(1)高维稀疏特征 (LR/FTRL模型)
(2)工业界一般使用Murmur Hash
(3)32 bits encode roughly 4 billion features
2. Sequence Encoding
(1)低维连续特征(GBDT模型)
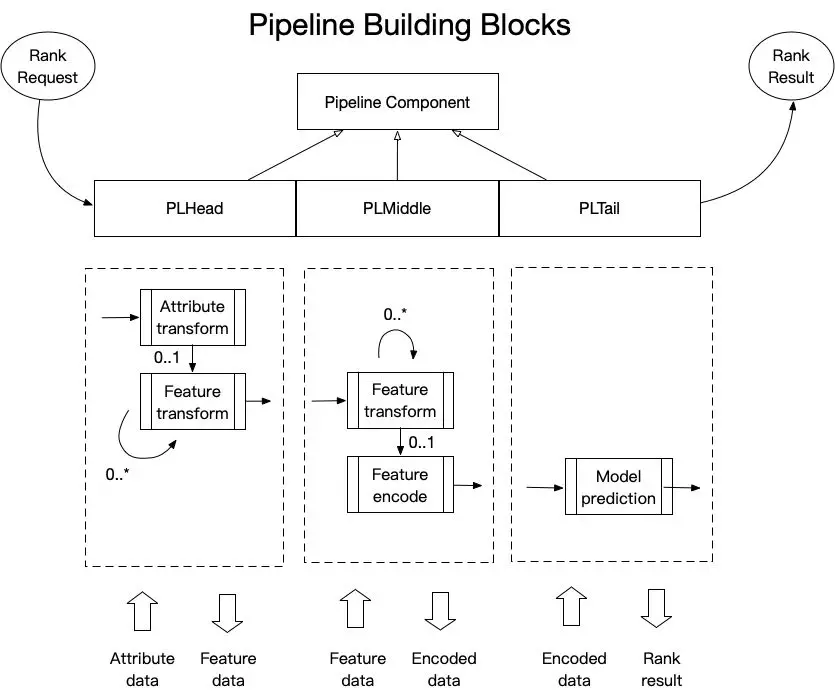
八、特征工程Pipeline设计
将整个Pipeline拆分为三个粒度适中的部分,兼顾了工程实施的灵活性和便捷性。
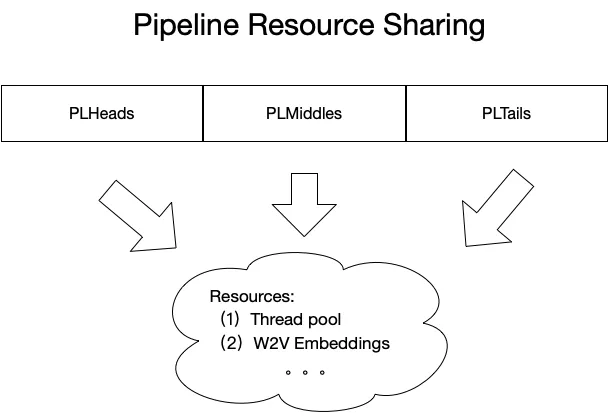
九、特征工程Pipeline的资源共享
基于动态规划的理念,自底向上实现资源的最大化重复利用。
十、线上线下计算的强一致性保证
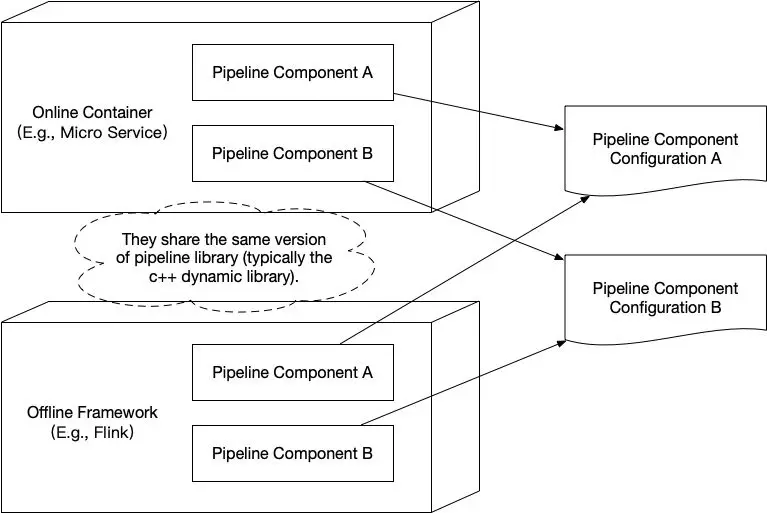
十一、排序任务的数据组织结构
1.User and Context处理只计算一次
2.多线程实施位置:ads
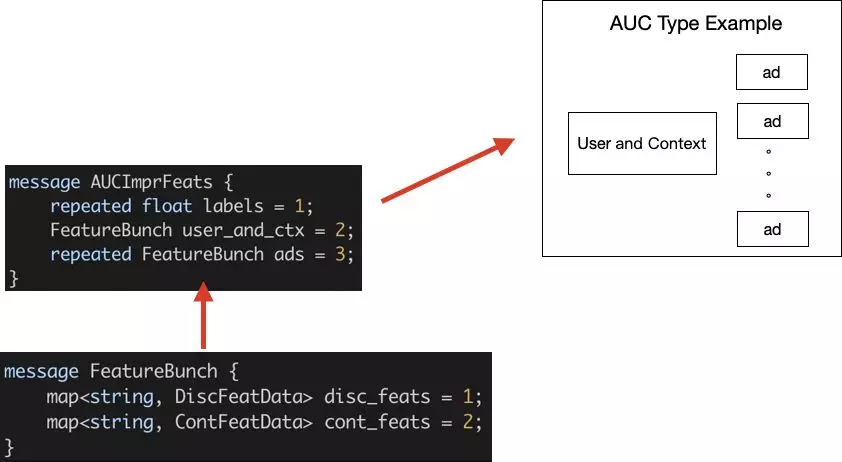
十二、系统模块间的交互协议
1.系统模块的交互场景
(1)离线:e.g., Flink内调用C++ DSL
(2)在线:e.g., 微服务内调用C++ DSL
2.程序设计语言的交互协议
(1) Swig(Java/Python => C++)
3. 数据的交换协议
(1) Protobuf格式
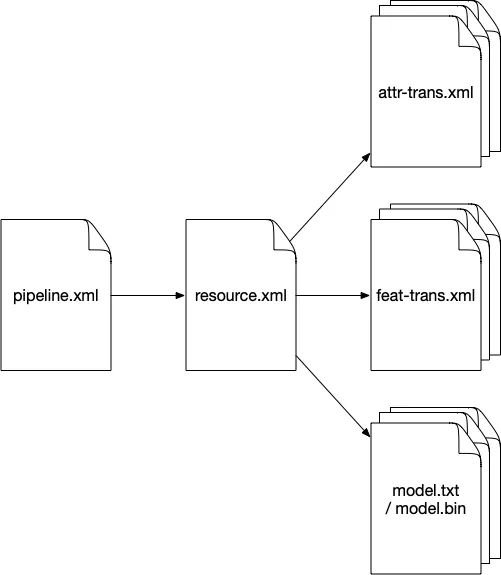
十三、特征工程及Pipeline的可配置性
不同粒度的特征工程部件:属性转换、特征转换、模型、资源管理、Pipeline等都做到可配置的程度,添加新特征或新算子非常方便。