java8学习总结——Collectors类源代码分析
概述
在JDK8中,对Collectos类的定义:一个Collector接口的实现,并提供很多有用的方法。事实也是如此,通过Collectors提供的方法,我们可以完成大多数日常的集合运算操作。因此,Collectors类的所有方法返回都是Collector的实例。其实,Collectors使Collector更具体化。因为,Collector只是约束了一种操作运算的规范(提供容器,计算,归集,finisher得出最终结果),而Collectors则提供了各种各样的,具有具体功能的Collector。比如:toList(),、toMap、toSet()、joining()等等Collector,这些Collector都是有具体的功能的。
joining():将字符串元素拼接起来;
toSet():将操作的元素以Set集合形式输出;
toMap() :将操作元素以Map形式输出;
所以说,Collectors使Collector更加的具体化,简洁实用。
第一组:toSet、toMap、toCollectioin、toList、toConcurrentMap
这组Collector都是输出集合对象,它们的实现方式也大同小异,但是需要对Collector的实现方式很熟悉才可以很轻松看懂下面的源代码。
源代码:
public static >
Collector toCollection(Supplier collectionFactory) {
return new CollectorImpl<>(collectionFactory, Collection::add,
(r1, r2) -> { r1.addAll(r2); return r1; },
CH_ID);
}
public static
Collector> toList() {
return new CollectorImpl<>((Supplier>) ArrayList::new, List::add,
(left, right) -> { left.addAll(right); return left; },
CH_ID);
}
public static
Collector> toSet() {
return new CollectorImpl<>((Supplier>) HashSet::new, Set::add,
(left, right) -> { left.addAll(right); return left; },
CH_UNORDERED_ID);
}
从上面的代码中可以看出,toSet、toList、toCollection的实现方式都是通过创建ConllectorImpl来获得具体的Collector,创建的方式也很简单。首先创建一个集合容器;其次将元素放入集合容器中,最后进行归集操作conbiner,将多个结果集合合并为一个结果集合输出。由于输出类型与输入类型一致,也就没有finisher方法了。
只有map集合稍微复杂些。虽然toMap和toConcurrentMap也是通过创建CollectorImpl对象来实现的,但是由于Map集合的特殊性,所以在实现上有些微的差别。
源代码:
public static >
Collector toMap(Function keyMapper,
Function valueMapper,
BinaryOperator mergeFunction,
Supplier mapSupplier) {
BiConsumer accumulator
= (map, element) -> map.merge(keyMapper.apply(element),
valueMapper.apply(element), mergeFunction);
return new CollectorImpl<>(mapSupplier, accumulator, mapMerger(mergeFunction), CH_ID);
}
public static >
Collector toConcurrentMap(Function keyMapper,
Function valueMapper,
BinaryOperator mergeFunction,
Supplier mapSupplier) {
BiConsumer accumulator
= (map, element) -> map.merge(keyMapper.apply(element),
valueMapper.apply(element), mergeFunction);
return new CollectorImpl<>(mapSupplier, accumulator, mapMerger(mergeFunction), CH_CONCURRENT_ID);
} 从传入的参数上来看,toMap不仅有suppier方法,同时还有keyMapper和valueMapper两个Function,还有mergeFunctionh。前两个方法是用来分别获得存入map对象的key和value的。其传入参数是待操作的元素(element),而两个函数分别根据element获得key和value值。mergeFunction是用来将key和value值融入map集合中的。看一下map集合的merge方法的实现,或许可以更清晰一些。
源代码:
default V merge(K key, V value,
BiFunction remappingFunction) {
Objects.requireNonNull(remappingFunction);
Objects.requireNonNull(value);
V oldValue = get(key);
V newValue = (oldValue == null) ? value :
remappingFunction.apply(oldValue, value);
if(newValue == null) {
remove(key);
} else {
put(key, newValue);
}
return newValue;
}第二组:groupingBy,partioningBy
源代码:
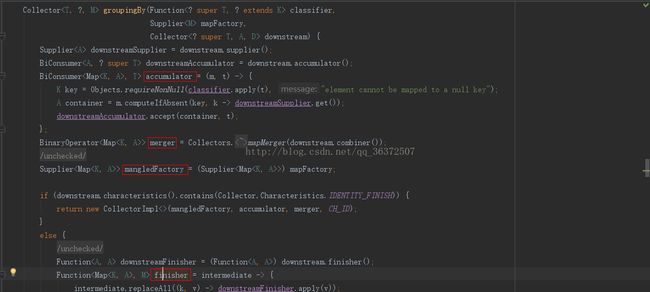
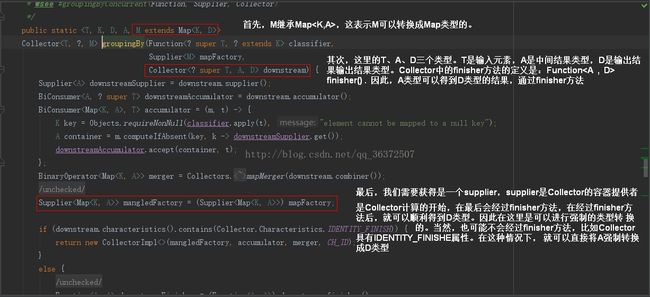
Collectors创建Collector,将其具体化为某种行为。创建Collector需要五个参数,上面红框标注的分别是前四个参数supplier、accumulate、combiner、finisher。
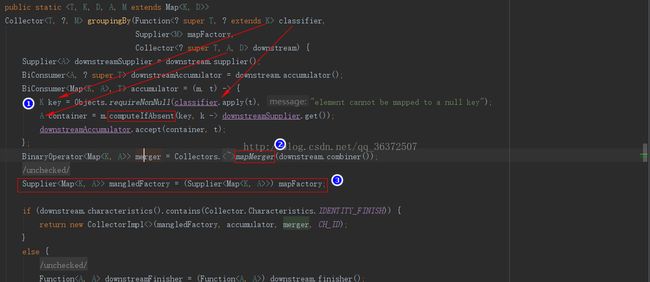
classifer函数接收的是T类型返回的是K类型。K类型正好就是分组函数中的key的类型,然后根据key去获取容器,这里应用了computeIfAbsent方法。调用computeIfAbsent方法的是一个map对象,即m。computeIfAbsent的计算方式是:如果存在则返回,不存在则创建。也就是说,这个方法会为每一个唯一的key创建一个容器,并且将这个容器放入m的map中,这也就达到了根据key进行分组的目的。m的结构示意如下:
Map
接下在再第二步时,通过mapMerge方法获得merger,即combiner。mapMerge方法的源代码如下:
private static >
BinaryOperator mapMerger(BinaryOperator mergeFunction) {
return (m1, m2) -> {
for (Map.Entry e : m2.entrySet())
m1.merge(e.getKey(), e.getValue(), mergeFunction);
return m1;
};
} 注: 这里只是解释这个mapMerger的运算过程,实际上在这里是不会执行这些运算的,这里只是将这一系列的运算方式封装成了merger,即Colletor中的combiner。
第三步没有太多的可说的,就是一个强制类型转换获得mangleFactory,即Collector中的supplier。这里解释一下为什么可以进行强制类型转换。
在理解完上面的groupingBy的源代码之后,再来看partitioningBy就简单很多了。
源代码:

第一步是创建了一个partition对象,这个对象包含两个属性forTrue和forFalse,在这里也分别创建了两个集合分别对应两个属性,这也符合partitionBy的本意,即将集合切分成true和false两个结果集合,根据给定的条件。
第二步也是创建了一个partition对象,分别应用downstream的combiner方法将true的结果集合和false的结果集合分别合并。然后就得到了两个结果集合。
第一个红框内,通过传入的predicate,如果predicate返回结果为true,则向downstreamaccumulate传入forTrue集合,认知则传入forFalse集合,以达到分组的目的。最后finisher方法的获取也是通过partition对象来完成的,方式很简单,就不一一赘述。partition的源代码如下:
private static final class Partition
extends AbstractMap
implements Map {
final T forTrue; //保存true类型的集合
final T forFalse; //保存false类型的集合
Partition(T forTrue, T forFalse) {
this.forTrue = forTrue;
this.forFalse = forFalse;
}
@Override
public Set> entrySet() {
return new AbstractSet>() {
@Override
public Iterator> iterator() {
Map.Entry falseEntry = new SimpleImmutableEntry<>(false, forFalse);
Map.Entry trueEntry = new SimpleImmutableEntry<>(true, forTrue);
return Arrays.asList(falseEntry, trueEntry).iterator();
}
@Override
public int size() {
return 2;
}
};
}
}
第三组:mapping,reducing
这两个方法辅助的性质更强一些。mapping方法可以转换Collector的接收元素类型。比如:Collector
这是mapping方法的特点,所以mapping方法的参数是两个:第一个参数是类型转换方法Function
源代码:
public static
Collector mapping(Function mapper,
Collector downstream) {
BiConsumer downstreamAccumulator = downstream.accumulator();
return new CollectorImpl<>(downstream.supplier(),
(r, t) -> downstreamAccumulator.accept(r, mapper.apply(t)),
downstream.combiner(), downstream.finisher(),
downstream.characteristics());
} 至于reducing方法,这个方法是将BinaryOperator操作转换成Collector接口实例,然后应用到Collector接收的每个元素上。
源代码:
public static Collector
reducing(T identity, BinaryOperator op) {
return new CollectorImpl<>(
boxSupplier(identity),
(a, t) -> { a[0] = op.apply(a[0], t); },
(a, b) -> { a[0] = op.apply(a[0], b[0]); return a; },
a -> a[0],
CH_NOID);
}