Tensorflow2.0学习笔记-Day1
Tensorflow2.0学习笔记-Day1
1.深度学习主要解决的是分类和回归问题
分类问题:输出的是概率分布,例如[0.2,0.7,0.1],概率最大的为类别
回归问题:预测值,会输出一个真实的数值
目标函数(损失函数):目标是通过调参让目标函数变小,来优化模型
目标函数通常用:

one-hot编码:把正整数化成一个1多个0的向量
2.导入后面需要的包
import matplotlib as mpl
import matplotlib.pyplot as plt
%matplotlib inline#让图可以输出在屏幕上
import numpy as np
import sklearn
import pandas as pd
import os
import sys
import time
import tensorflow as tf
from tensorflow import keras
检验这些包的版本:
print(tf.__version__)
print(sys.version_info)
for module in mpl, np, pd, sklearn, tf, keras:
print(module.__name__, module.__version__)
输出结果:
2.0.0
sys.version_info(major=3, minor=7, micro=4, releaselevel='final', serial=0)
matplotlib 3.1.1
numpy 1.16.5
pandas 0.25.1
sklearn 0.21.3
tensorflow 2.0.0
tensorflow_core.keras 2.2.4-tf
注:keras/datasets里面的文件不要删,删了之后引用keras会报错
3.加载数据集
加载数据集原本是一个很轻松,很正常的事情,然后我就踩坑了…
正常下载是这样的:
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/imdb.npz
17465344/17464789 [==============================] - 7s 0us/step
然后不知道是网络问题还是什么下载过程中报错,然后再下就不能下了
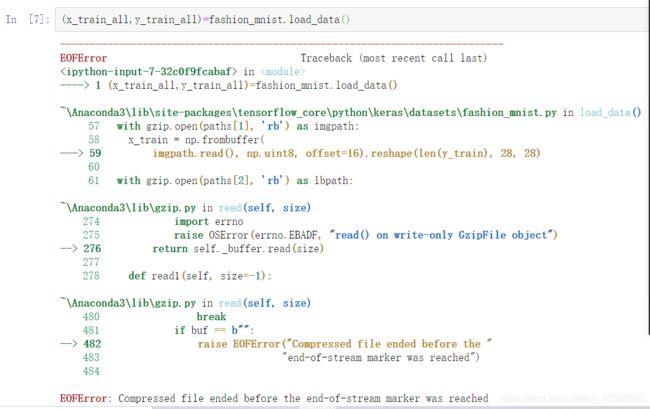
为了解决这个问题呢,网上的办法是找到下载到半截的数据集删掉,再重新下,然后我不知道Jupyter下载的数据集默认存在了哪,网上只有更改jupyter默认下载路径的办法,然后我还不适用
我的jupyter_notebook_config.py文件中没有下面这行:
#c.NotebookApp.notebook_dir = ''
这个方法放弃了,最终没有在这下载数据集,而是到网上自行下载了数据集,存到自己新建的文件夹中
然后从网上找到了一个加载.gz格式的load_data()函数,解决了问题
import os
import gzip
# 定义加载数据的函数,data_folder为保存gz数据的文件夹,该文件夹下有4个文件
# 'train-labels-idx1-ubyte.gz', 'train-images-idx3-ubyte.gz',
# 't10k-labels-idx1-ubyte.gz', 't10k-images-idx3-ubyte.gz'
def load_data(data_folder):
files = ['train-labels-idx1-ubyte.gz', 'train-images-idx3-ubyte.gz', 't10k-labels-idx1-ubyte.gz', 't10k-images-idx3-ubyte.gz']
paths = []
for fname in files:
paths.append(os.path.join(data_folder,fname))
with gzip.open(paths[0],'rb') as lbpath:
y_train = np.frombuffer(lbpath.read(),np.uint8,offset=8)
with gzip.open(paths[1],'rb') as imgpath:
x_train = np.frombuffer(imgpath.read(), np.uint8, offset=16).reshape(len(y_train), 28, 28)
with gzip.open(paths[2], 'rb') as lbpath:
y_test = np.frombuffer(lbpath.read(), np.uint8, offset=8)
with gzip.open(paths[3], 'rb') as imgpath:
x_test = np.frombuffer(imgpath.read(), np.uint8, offset=16).reshape(len(y_test), 28, 28)
return (x_train, y_train), (x_test, y_test)
然后分出训练集,测试集,验证集
(x_train_all, y_train_all), (x_test, y_test)= load_data('C:/Users/mnist')
此时的这个路径还有个小坑,开始我用的\,然后报错:
SyntaxError: (unicode error) ‘unicodeescape’ codec can’t decode bytes in position 2-3
解决方案找到了3个:
路径前加r,双反斜杠分隔,正斜杠分隔(我采用的这种)
解决问题后,取前5000张作为验证集,后55000张作为训练集
x_valid, x_train = x_train_all[:5000], x_train_all[5000:]
y_valid, y_train = y_train_all[:5000], y_train_all[5000:]
print(x_valid.shape, y_valid.shape)
print(x_train.shape, y_train.shape)
print(x_test.shape, y_test.shape)
(5000, 28, 28) (5000,)
(55000, 28, 28) (55000,)
(10000, 28, 28) (10000,)
以上就是昨天学习的全过程, 排坑并不是那么顺利。
今天继续往后进展!