11 03Spring之资源访问
文章目录
- 1 读取不同资源
- 2 ResourceLoader接口
- 3 注入Resource
- 4 路径通配符
如果要想进行磁盘文件的读取操作,首先想到的一定是java.io包中提供的一系列类,还可以继续深入想到:InputStream、OutputStream、Scanner、PrintStream、BufferedReader等核心的处理操作类。但是现在有如下几个问题:
(1)这几个类的互相操作难度太高,很多人实际上对于IO的领悟并不是很彻底;
(2)IO支持的读取有限且复杂:
|————读取jar包里面的文件呢?
|————读取不同资源文件的时候操作不统一,例如:读取文件、网络读取;
所以在整个Spring设计过程之中充分考虑到了IO操作的种种操作问题,那么提供了一套新的资源访问处理的操作支持,而整个操作的关键就在于一个接口上:org.springframework.core.io.Resource,而这个接口就表示所有的可用资源读取,在此接口里面定义有如下的几个常用方法:
(1)取得资源的数据长度:public long contentLength() throws IOException
(2)判断资源是否存在:public boolean exists()
(3)取得资源对应的文件类型:public File getFile() throws IOException
(4)取得资源的完整网络路径:public URL getURL() throws IOException
(5)判断资源是否打开:public boolean isOpen()
(6)最后一次修改日期:public long lastModified() throws IOException
(7)创建一个操作资源:public Resource createRelative(String relativePath) throws IOException
Resource本身只属于一个子接口,它有一个对应的父接口:org.springframework.core.io.InputStreamSource,在这个接口里面也定义有一些资源访问的操作方法:
(1)取得资源的输入流:public InputStream getInputStream() throws IOException
Resource本身是一个接口,那么如果要想使用这个操作接口,需要找到它的子类:ByteArrayResource(内存读取)、ClassPathResource(CLASSPATH读取)、FileSystemResource(文件读取。)
1 读取不同资源
下面首先按照传统的开发实现一些基本资源读取。
1、读取内存资源:org.springframework.core.io.ByteArrayResource
(1)构造方法:public ByteArrayResource(byte[] byteArray)
范例:实现内存读取
package org.lks.resource.demo;
import java.util.Scanner;
import org.springframework.core.io.ByteArrayResource;
import org.springframework.core.io.Resource;
public class ByteArrayResourceDemo {
public static void main(String[] args) throws Exception{
//此处的内存处理流与ByteArrayInputStream使用形式类似
Resource resource = new ByteArrayResource("hhy big fool".getBytes());
//单单就可以取得更多的资源信息来讲,这一点比InputStream更强
System.out.println(resource.contentLength());
//如果给出的是InputStream,那么可以简化读取
//getInputStream是通过InputStreamSource父接口继承而来的方法
Scanner scan = new Scanner(resource.getInputStream());
scan.useDelimiter("\n");
while(scan.hasNext()){
System.out.println(scan.next());
}
scan.close();
}
}
2、文件读取:org.springframework.core.io.FileSystemResource
(1)构造方法:public FileSystemResource(File file)
(2)构造方法:public FileSystemResource(String path)
范例:进行文件读取
package org.lks.resource.demo;
import java.io.File;
import java.util.Scanner;
import org.springframework.core.io.FileSystemResource;
import org.springframework.core.io.Resource;
public class ByteArrayResourceDemo {
public static void main(String[] args) throws Exception{
Resource resource = new FileSystemResource("D:" + File.separator + "text.xml");
//单单就可以取得更多的资源信息来讲,这一点比InputStream更强
System.out.println(resource.contentLength());
//如果给出的是InputStream,那么可以简化读取
//getInputStream是通过InputStreamSource父接口继承而来的方法
Scanner scan = new Scanner(resource.getInputStream());
scan.useDelimiter("\n");
while(scan.hasNext()){
System.out.println(scan.next());
}
scan.close();
}
}
3、CLASSPATH读取:org.springframework.core.io.ClassPathResource
(1)构造方法:public ClassPathResource(String path)
只要是保存在了CLASSPATH环境属性下的路径信息都可以通过此类读取进来。
范例:读取applicationContext.xml文件
package org.lks.resource.demo;
import java.util.Scanner;
import org.springframework.core.io.ClassPathResource;
import org.springframework.core.io.Resource;
public class ClassPathResourceDemo {
public static void main(String[] args) throws Exception{
Resource resource = new ClassPathResource("applicationContext.xml");
//单单就可以取得更多的资源信息来讲,这一点比InputStream更强
System.out.println(resource.contentLength());
//如果给出的是InputStream,那么可以简化读取
//getInputStream是通过InputStreamSource父接口继承而来的方法
Scanner scan = new Scanner(resource.getInputStream());
scan.useDelimiter("\n");
while(scan.hasNext()){
System.out.println(scan.next());
}
scan.close();
}
}
如果要进行文件的读取必须要提供有完整的路径,也就是说默认情况下要想读取一个指定的资源,那么必须要想办法拼凑出路径(还需要取得一堆的系统属性)。
2 ResourceLoader接口
ResourceLoader(org.springframework.core.io.ResourceLoader)接口的主要作用是进行Resource接口对象实例化使用的,这个接口的定义如下:
(1)读取指定的资源信息:public Resource getResource(String location)
(2)取得类加载器:public ClassLoader getClassLoader()
ResourceLoader是一个接口,于是要使用这个接口必须知道它对应的子类:org.springframework.core.io.DefaultResourceLoader,利用这个子类就可以实现ResourceLoader类接口的实例化,但是现在整个的资源操作的问题并不在于Resource或者是ResourceLoader接口以及其一堆子类,而关键性的问题在于这个定位的字符串。
(1)文件读取资源:file:路径;
(2)CLASSPATH读取:classpath:路径;
(3)网络读取:http://路径。
范例:进行文件读取
package org.lks.resource.demo;
import java.io.File;
import java.util.Scanner;
import org.springframework.core.io.DefaultResourceLoader;
import org.springframework.core.io.Resource;
import org.springframework.core.io.ResourceLoader;
public class ResourceLoaderDemo {
public static void main(String[] args) throws Exception{
ResourceLoader loader = new DefaultResourceLoader();
Resource resource = loader.getResource("file:D:" + File.separator + "text.xml");
//单单就可以取得更多的资源信息来讲,这一点比InputStream更强
System.out.println(resource.contentLength());
//如果给出的是InputStream,那么可以简化读取
//getInputStream是通过InputStreamSource父接口继承而来的方法
Scanner scan = new Scanner(resource.getInputStream());
scan.useDelimiter("\n");
while(scan.hasNext()){
System.out.println(scan.next());
}
scan.close();
}
}
只是写了一个字符串,而后就可以进行读取了。
范例:读取CLASSPATH的路径
Resource resource = loader.getResource("classpath:applicationContext.xml");
范例:读取网络资源
Resource resource = loader.getResource("https://www.runoob.com/java/java-file.html");
所有读取的操作过程之中,可以清楚的感受到都是利用了字符串来进行的资源定位,也就是说在整个Spring里面核心的设计思想就是:利用合理的字符串格式来进行更加复杂的操作。
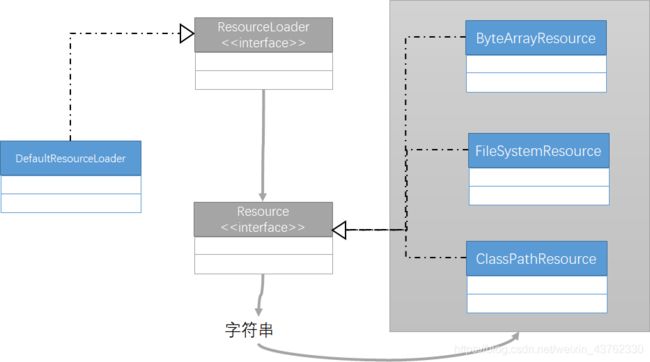
3 注入Resource
在以上的操作之中可以发现,虽然Resource的子类可以利用字符串格式进行了隐藏,但是此时的代码之中发现ResourceLoader跟我的开发没有任何的关系。如果真的开发只关心Resource一个接口就足够了。
为了解决Resource与ResourceLoader的操作关系的耦合问题,那么在Spring设计的时候考虑到了数据的自动转型问题,也就是说利用注入的操作模式,就可以让ResourceLoader消失了。
范例:编写一个资源处理类
package org.lks.resource.vo;
import org.springframework.core.io.Resource;
public class ResourceUtils {
private Resource resource;
public void setResource(Resource resource) {
this.resource = resource;
}
public Resource getResource() {
return resource;
}
}
要想实现资源数据的注入操作,就必须要编写applicationContext.xml文件,在这个文件里面定义所需要的资源。
范例:在applicationContext.xml文件里面定义资源信息
<bean id="myResource" class="org.lks.resource.vo.ResourceUtils">
<property name="resource" value="file:D:/text.xml"/>
bean>
<bean id="myResource" class="org.lks.resource.vo.ResourceUtils">
<property name="resource" value="classpath:META-INF/notice.txt"/>
bean>
<bean id="myResource" class="org.lks.resource.vo.ResourceUtils">
<property name="resource" value="https://www.baidu.com/robots.txt"/>
bean>
范例:测试代码
package org.lks.test;
import java.util.Scanner;
import org.lks.resource.vo.ResourceUtils;
import org.springframework.context.ApplicationContext;
import org.springframework.context.support.ClassPathXmlApplicationContext;
public class TestResource {
public static void main(String[] args) throws Exception{
ApplicationContext ctx = new ClassPathXmlApplicationContext("applicationContext.xml");
ResourceUtils resourceUtils = ctx.getBean("myResource", ResourceUtils.class);
Scanner scan = new Scanner(resourceUtils.getResource().getInputStream());
scan.useDelimiter("\n");
while(scan.hasNext()){
System.out.println(scan.next());
}
scan.close();
}
}
利用了配置文件的方式进行处理的时候,那么用户关心的只是Resource一个接口的使用,而ResourceLoader接口的作用被Spring封装起来了。
而且最为方便的是,在Spring里面允许用户设置资源数组。
范例:修改程序类
package org.lks.resource.vo;
import java.util.List;
import org.springframework.core.io.Resource;
public class ResourceUtils {
private List<Resource> resource;
public void setResource(List<Resource> resource) {
this.resource = resource;
}
public List<Resource> getResource() {
return resource;
}
}
<bean id="myResource" class="org.lks.resource.vo.ResourceUtils">
<property name="resource">
<list value-type="org.springframework.core.io.Resource">
<value>File:D:/text.xmlvalue>
<value>classpath:applicationContext.xmlvalue>
<value>https://www.baidu.com/robots.txtvalue>
list>
property>
bean>
package org.lks.test;
import java.util.Iterator;
import java.util.Scanner;
import org.lks.resource.vo.ResourceUtils;
import org.springframework.context.ApplicationContext;
import org.springframework.context.support.ClassPathXmlApplicationContext;
import org.springframework.core.io.Resource;
public class TestResource {
public static void main(String[] args) throws Exception{
ApplicationContext ctx = new ClassPathXmlApplicationContext("applicationContext.xml");
ResourceUtils resourceUtils = ctx.getBean("myResource", ResourceUtils.class);
Iterator<Resource> iter = resourceUtils.getResource().iterator();
Scanner scan = null;
while(iter.hasNext()){
scan = new Scanner(iter.next().getInputStream());
scan.useDelimiter("\n");
while(scan.hasNext()){
System.out.println(scan.next());
}
scan.close();
System.out.println("*************************************************");
}
}
}
利用Spring读取外部文件资源的时候它的设计要比直接使用IO包操作更加容易。
4 路径通配符
以上的操作都有一个共同的问题,那么就是必须设置好完整的路径,但是很多时候无法一一设置完整路径。例如:现在在不同的目录下都会存在有applicationContext-xxx.xml命名的结构,如果要想将其完整的全部读取进来,那么就必须考虑到陆劲歌的通过通配符使用,在Spring之中继续发扬了ANT工具的特征,而在这个工具下提供有几种符号:
(1)?:匹配任意的一位字符,例如:applicationContext-?.xml表示可以访问applicationContext-1.xml、applicationContext-2.xml;
(2)*:匹配零个、一个或多个任意字符,例如:applicationContext-*.xml,则表示可以访问applicationContext-xxx.xml、applicationContext-12345.xml;
(3)**:表示匹配任意的目录,可以是零个、一个或多个。
但是一旦要进行多个路径的匹配,那么返回的内容也一定是多个,此时就只能够利用ResourceLoader的子接口完成读取:org.springframework.core.io.support.ResourcePatternResolver。可以使用的一个子类PathMatchingResourcePatternResolver
范例:读取资源文件
package org.lks.test;
import org.springframework.core.io.Resource;
import org.springframework.core.io.support.PathMatchingResourcePatternResolver;
import org.springframework.core.io.support.ResourcePatternResolver;
public class TestResourceResolver {
public static void main(String[] args) throws Exception{
ResourcePatternResolver loader = new PathMatchingResourcePatternResolver();
Resource[] resources = loader.getResources("classpath:org/msg/**/applicationContext-?.xml");
for(int i = 0; i < resources.length; i++){
System.out.println(resources[i].getFilename() + resources[i].contentLength());
System.out.println("*************************************************");
}
}
}
在Spring里面目录的访问不再成为限制。