Spark SQL——开窗函数
开窗函数和聚合函数一样,都是对行的集合组进行聚合计算。
开窗用于为行定义一个窗口(这里的窗口是指运算将要操作的行的集合),它对一组值进行操作,不需要使用group by子句对数据进行分组,能够在同一行中同时返回基础行的列和聚合列。
开窗函数调用格式为:函数名(列) OVER(选项)
第一类:聚合开窗函数 --> 排列函数(列)OVER(选项),这里的选项可以是PARTITION BY 子句,但不可以是ORDER BY子句
第二类:排列开窗函数 --> 排序函数(列)OVER(选项),这里的选项可以是ORDER BY子句,也可以是OVER(PARTITION BY子句 ORDER BY子句),但是不可以是PARTITION BY子句。
代码示例:
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setAppName("score").setMaster("local[*]")
val sparkSession = SparkSession.builder().config(sparkConf).getOrCreate()
import sparkSession.implicits._
val scoreDF = sparkSession.sparkContext.makeRDD(Array(Score("a1", 1, 80),
Score("a2", 1, 78),
Score("a3", 1, 95),
Score("a4", 2, 74),
Score("a5", 2, 92),
Score("a6", 3, 99),
Score("a7", 3, 99),
Score("a8", 3, 45),
Score("a9", 3, 55),
Score("a10", 3, 78))).toDF("name", "class
", "score")
scoreDF.createOrReplaceTempView("score")
scoreDF.show()
}
1、聚合开窗函数
OVER关键字表示把聚合函数当成聚合开窗函数而不是聚合函数,SQL标准允许将所有聚合函数用作聚合开窗函数。
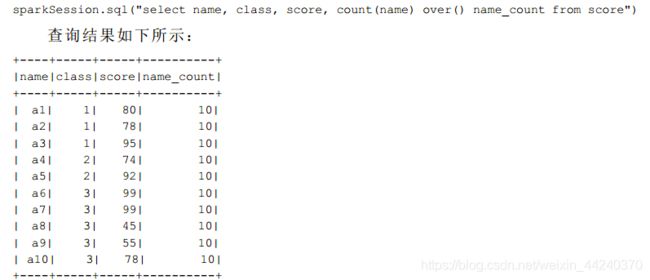
上面例子中开窗函数COUNT(*) OVER()对于查询结果的每一行都返回所有符合条件的行的条数。OVER关键字后的括号中还经常添加选项用以改变进行聚合运算的窗口范围。如果OVER关键字后的括号中的选项为空,则开窗函数会对结果集中的所有行进行聚合运算。
开窗函数的OVER关键字后括号中的可以使用PARTITION BY子句来定义行的分区来供进行聚合计算。与GROUP BY子句不同,PARTITION BY子句创建的分区是独立于结果集的,创建的分区只是供进行聚合计算的,而且不同的开窗函数所创建的分袂也不互相影响。
下面的SQL语句用于显示按照班级分组后每组的人数:
sparkSession.sql("select name, class, score, count(name) over(partition by class)
name_count from score").show()
查询结果如下所示:

OVER(PARTITION BY class)表示对结果集按照class进行分区,并且计算当前行所属的组的聚合计算结果。在同一个select语句中可以同时使用多个开窗函数,而且这些开窗函数并不会相互干扰。
比如下面SQL语句用于显示每一个人员的信息、所属城市的人员数和同龄人的人数。
sparkSession.sql("select name, class, score, count(name) over(partition by class)
name_count1 from score").show()
sparkSession.sql("select name, class, score, count(name) over(partition by score)
name_count2 from score").show()
2、排序开窗函数
对于排序开窗函数来讲,支持的开窗函数分别为ROW_NUMBER(行号)、RANK(排名)、DENSE_RANK(密集排名)和NTILE(分组排名)
sparkSession.sql("select name, class, score, row_number() over(order by score) rank from
score").show()
sparkSession.sql("select name, class, score, rank() over(order by score) rank from
score").show()
sparkSession.sql("select name, class, score, dense_rank() over(order by score) rank from
score").show()
sparkSession.sql("select name, class, score, ntile(6) over(order by score) rank from
score").show()
查询的结果分别为:
//第一个语句
+----+-----+-----+----+
|name|class|score|rank|
+----+-----+-----+----+
| a8| 3| 45| 1|
| a9| 3| 55| 2|
| a4| 2| 74| 3|
| a2| 1| 78| 4|
| a10| 3| 78| 5|
| a1| 1| 80| 6|
| a5| 2| 92| 7|
| a3| 1| 95| 8|
| a6| 3| 99| 9|
| a7| 3| 99| 10|
+----+-----+-----+----+
//第二个语句
+----+-----+-----+----+
|name|class|score|rank|
+----+-----+-----+----+
| a8| 3| 45| 1|
| a9| 3| 55| 2|
| a4| 2| 74| 3|
| a2| 1| 78| 4|
| a10| 3| 78| 4|
| a1| 1| 80| 6|
| a5| 2| 92| 7|
| a3| 1| 95| 8|
| a6| 3| 99| 9|
| a7| 3| 99| 9|
+----+-----+-----+----+
//第三个语句
+----+-----+-----+----+
|name|class|score|rank|
+----+-----+-----+----+
| a8| 3| 45| 1|
| a9| 3| 55| 2|
| a4| 2| 74| 3|
| a2| 1| 78| 4|
| a10| 3| 78| 4|
| a1| 1| 80| 5|
| a5| 2| 92| 6|
| a3| 1| 95| 7|
| a6| 3| 99| 8|
| a7| 3| 99| 8|
+----+-----+-----+----+
//第四个语句
+----+-----+-----+----+
|name|class|score|rank|
+----+-----+-----+----+
| a8| 3| 45| 1|
| a9| 3| 55| 1|
| a4| 2| 74| 2|
| a2| 1| 78| 2|
| a10| 3| 78| 3|
| a1| 1| 80| 3|
| a5| 2| 92| 4|
| a3| 1| 95| 4|
| a6| 3| 99| 5|
| a7| 3| 99| 6|
+----+-----+-----+----+
对于row_number() over(order by score) as rownum来说,这个排序开窗函数是按照score升序方式来排序,并得出排序结果的序号。
对于rank() over(order by score) as rank来说,这个排序形容函数是按FSalary升序方式来排序并得出排序结果的排名号,这个函数求出来的排名结果可以并列,并列排名之后的排名将是并列的排名加上并列数(简单说每个人只有一种排名,然后出现两个并列第一名的情况,这时候排在两个第一名后面的人将是第三名,就是没有了第二名但是有两个第一名。)
对于dense_rank() over(order by score) as dense_rank来说,这个排序函数是按照score升序的方式来排序并得出排序结果的排名号,这个函数与rank()函数不同在于并列排名之后的排名只是并列排名加1
对于 ntile(6) over(order by score)as ntile 来说,这个排序函数是按 FSalary 升序的方式来排序,然后 6 等分成 6 个组,并显示所在组的序号。
排序函数和聚合开窗函数类似,支持在OVER子句中使用PARTITION BY语句,例如:
sparkSession.sql("select name, class, score, row_number() over(partition by class order
by score) rank from score").show()
sparkSession.sql("select name, class, score, rank() over(partition by class order by score)
rank from score").show()
sparkSession.sql("select name, class, score, dense_rank() over(partition by class order
by score) rank from score").show()
sparkSession.sql("select name, class, score, ntile(6) over(partition by class order by score)
rank from score").show()
需要注意一点,在排序开窗函数中使用PARTITION BY子句需要放置在ORDER BY子句之前。