架构
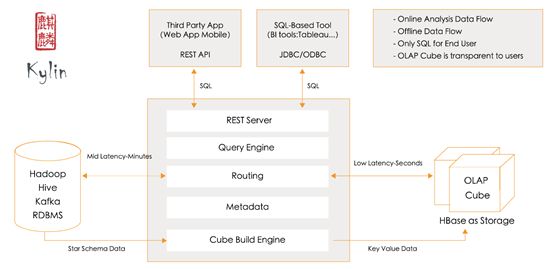
官网很直接,上来就给出了kylin的架构,也很清晰。可以把kylin看成3个部分。
- cube管理查询
- cube构建引擎
- cube存储引擎
其中,构建引擎和存储引擎可以自由扩展,默认是mapreduce和hbase
术语
OLTP
在线事务处理是传统的关系型数据库的主要应用,主要是基本的、日常的事务处理,例如银行交易。OLAP是数据仓库系统的主要应用,支持复杂的分析操作,侧重决策支持,并且提供直观易懂的查询结果。
OLAP
数据在线分析处理引擎。通过对数据的各个维度,实时之间构建出cube来分析数据的价值。kylin就是一款针对OLAP的系统。
OLAP和OLTP的区别可以理解为,OLAP是主观的需求产物,OLTP是客观的需求产物。
cube
cube和传统的关系数据库和二维表不一样,可以有很多个维度,比如需要获取维度a,b,c之间任意组合的数据结果,这在sql中表达可能是group by a; group a,b; group b,看似简单,实则计算量很大。在数据分析中,cube非常重要,下面章节会针对kylin中的cube进行详细描述。
MXD
MDX语句(MultiDimensionalExpressions)是一种语言,支持多维对象与数据的定义和操作。它可以表达在线分析出来数据卡上的选择、计算和一些元数据定义等操作,并赋予用户表现查询结果的能力。
如同SQL查询一样,每个MDX 查询都要求有数据请求(SELECT子句)、起始点(FROM子句)和筛选(WHERE子句)。这些关键字以及其它关键字提供了各种工具,用来从多维数据集析取数据特定部分。MDX还提供了可靠的函数集,用来对所检索的数据进行操作,同时还具有用户定义函数扩展 MDX的能力。
语法:
最基本的语法:select 轴1,轴2,…… from 立方体模型名 where 切片
可以看到,非常类似于SQL的语法:Select 列1,列2…… from 表1,表2…… where 条件子句。
首先,需要理解轴的概念:
轴:相当于SQL里的列,想象轴,需要有点立体概念,或者,我们把问题简化,对于平面表的展示,只会存在两个轴,也就是列轴和行轴。现有的大多数OLAP展示,也只体现这两个轴,我们公司的产品也不例外。说具体一点,轴对应于一个集合。
集合:由元组形成,
元组:可包括多个维度中的成员,也可包括来自同一个维度的多个成员。
成员:维度中一次或多次数据出现的项。
再看看立方体模型:这个很好理解,也就是主题分析时形成的模型方案了,MDX只支持单一模型。
最后看一下 切片:这和SQL中的筛选一样。不过,因为OLAP的数据是立体的,多维的,要变成平面,就需要切啊,切啊,把一些不需要展示的维度设定固定值(也就是切一下)。注意:当不指定任何切片时,一般的实现是将未出现的维度的默认成员值做为切片值。
事实表 & 维度 & 度量
事实表
每个数据仓库都包含一个或者多个事实数据表。事实数据表可能包含业务销售数据,如销售商品所产生的数据,与软件中实际表概念一样。
维度
说明数据,维度是指可指定不同值的对象的描述性属性或特征。例如,地理位置的维度可以包括“纬度”、“经度”或“城市名称”。“城市名称”维度的值可以为“旧金山”、“柏林”或“新加坡”。可以用于从不同角度来分析数据,例如常见的时间,地点维度
度量
事实表和维度交叉汇聚的点,度量和维度构成OLAP的主要概念,这里面对于在事实表或者一个多维立方体里面存放的数值型的、连续的字段,就是度量。这符合上面的意思,有标准,一个度量字段肯定是统一单位,例如元、户数。如果一个度量字段,其中的度量值可能是欧元又有可能是美元,那这个度量可没法汇总。在统一计量单位下,对不同维度的描述。
维度 & 度量
维度是指审视数据的角度,它通常是数据记录的一个属性,例如时间、地点等。度量是基于数据所计算出来的考量值;它通常是一个数值,如总销售额、不同的用户数等。分析人员往往要结合若干个维度来审查度量值,以便在其中找到变化规律。在一个SQL查询中,Group By的属性通常就是维度,而所计算的值则是度量
例子1:
有item A,time t, location l。那么item A位于事实表,time t和location l位于维度表。假如对time t按天做group by, 对 item A做sum()。那么得到的数据就是度量。
维度表 & 事实表
事实表(Fact Table)是指存储有事实记录的表,如系统日志、销售记录等;事实表的记录在不断地动态增长,所以它的体积通常远大于其他表。
维度表(Dimension Table)或维表,有时也称查找表(Lookup Table),是与事实表相对应的一种表,注意OLAP的lookup table主要是指数据的基础维度以及一些衍生维度;它保存了维度的属性值,可以跟事实表做关联;相当于将事实表上经常重复出现的属性抽取、规范出来用一张表进行管理。常见的维度表有:日期表(存储与日期对应的周、月、季度等的属性)、地点表(包含国家、省/州、城市等属性)等。使用维度表有诸多好处,具体如下。
·缩小了事实表的大小。
·便于维度的管理和维护,增加、删除和修改维度的属性,不必对事实表的大量记录进行改动。
·维度表可以为多个事实表重用,以减少重复工作。
多维分析模型
数据仓库常用的建模思路通常有基于维度的建模和实体建模。实体建模就是按照数据库3范式,规规矩矩的设计好每一张表,在进行多维分析的时候做大量的表关系得到数据。维度建模则是尽可能的抽象出业务过程,细化业务粒度,然后将该业务过程中相关的数据字段看成一个个维度,将业务的核心数据看成是事实,从而简化表结构,提高数据获取效率。
星型模型
星型架构是一种非正规化的结构,多维数据集的每一个维度都直接与事实表相连接,不存在渐变维度,所以数据有一定的冗余,如在地域维度表中,存在国家 A 省 B 的城市 C 以及国家 A 省 B 的城市 D 两条记录,那么国家 A 和省 B 的信息分别存储了两次,即存在冗余。
雪花模型
雪花模型是对星型模型的扩展。它对星型模型的维表进一步层次化,原有的各维表可能被扩展为小的事实表,形成一些局部的 " 层次 " 区域,这些被分解的表都连接到主维度表而不是事实表。如图 2,将地域维表又分解为国家,省份,城市等维表。其实就是把一张事实表拆成多张小维度表,并通过key关键。它的优点是 : 通过最大限度地减少数据存储量以及联合较小的维表来改善查询性能。雪花型结构去除了数据冗余。
区别
星型模型因为数据的冗余所以很多统计查询不需要做外部的连接,因此一般情况下效率比雪花型模型要高。星型结构不用考虑很多正规化的因素,设计与实现都比较简单。雪花型模型由于去除了冗余,有些统计就需要通过表的联接才能产生,所以效率不一定有星型模型高。正规化也是一种比较复杂的过程,相应的数据库结构设计、数据的 ETL、以及后期的维护都要复杂一些。因此在冗余可以接受的前提下,实际运用中星型模型使用更多,也更有效率。目前kylin只支持星型模型,或者通过ETL工具建星型模型转换成一张宽表再进行多维分析。。
cube
介绍
cube的设计是olap系统的核心,这会影响到查询分析的覆盖程度和性能。如果cube设计的维度太多,那么会导致构建速度很慢,存储空间浪费,查询性能低的现象。所以在满足需求的条件下,对cube不断的优化。
针对N维的数据分析而言,一共可以衍生出2n中聚合结果,如图所示,4个维度的排列组合。用数学的公式来说就是 C40+ C41 + C42 + C43 + C44。一个星型模型的维度数量最好控制在15以内,由于cube构建数量和维度是指数关系,所以维度太高会导致cube构建时间很长,并且,数据量的增大也会导致查询速度下降。如果真的有这么多的维度需要分析,那么可以拆成多个星型模型。
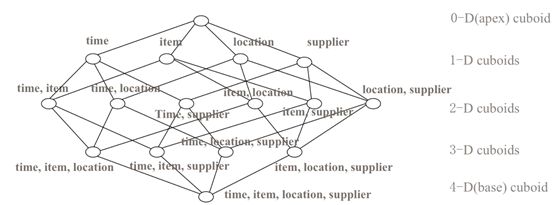
kylin维度组合模式
概述
cube的维度很容易爆炸,因为是指数增长的,所以降维是cube设计中的核心,下面是kylin支持的几种cube组合模式。
Normal
正常模式。也就是N个维度构建成2N个cube。
例子:假设有三个维度A,B,C每个维度都为Normal模式,那么构建的cube如图2,cube的总数为C30+C31+C32+C33。

图2
Mandatory
维度强制模式。当某个维度设置为Mandatory模式,那么该维度会出现在所有cube的构建中,比如时间维度,可以强绑定到cube的构建中。这种构建模式可以很大程度降低最后生成的cube数量,但是会导致分析失去一定的灵活性。
例子:假设有三个维度A,B,C 其中维度A为Mandatory模式,那么构建的cube如图3,最终生成的cube数为C20+C21+C22
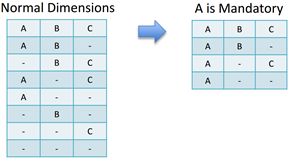
图3
Hierarchy
依赖模式。维度间通过依赖关系来决定构建cube的组合关系,只有父维度存在,子维度才会有效。常见的有国家,省份,城市这类字段。在做分析的时候,一般场景为:
group by 国家;
group by 国家,省份;
group by 国家,省份,城市;
例子:假设有维度A,B,C 其中B依赖于A,C依赖于B,那么构建的cube如图4。

图4
Derived
衍生模式。衍生模式的使用场景为,一个或多个维度可以由另一个维度生成。这是什么意思呢,假设在事实表中有外键列A, lookup表中B,C列,其中B为主键,列A和列B是映射关系,那么在查询事实表中的列A同时,kylin会自动的查询到lookup表中的B列。从维度数量的角度来看,Normal模式下有ABC,AB,AC,BC,A,B,C这几种组合情况,而在Derived模式下,cube的构建组合只有AC,A,C。
那么当请求的sql为`select count(*) from lookup group by B`的时候,由于没有对B列做预处理,所以kylin先查询A列的count,然后再实时计算出对应的B列的count 。
如图5,ID列为已知的某个维度列,A,C,B为ID列的衍生列,那么最终cube构建组合只有ID列。

图5
Joint
联合模式。在很多分析场景中,有些维度单独分析是没有意义的,要么同时出现,要么不出现。
例如维度A,B,C 当维度B和A是Joint关系,那么在构建cube的时候,kylin只会组合出ABC,AB,C三种。
Aggregation Group
聚合组
Max Dimension Combination最大的维度组合数量。
例如维度A,B,C 那么Max Dimension Combination设置为2时,kylin只会构建AB,AC,BC,A,B,C这几种组合,ABC这种组合会被省略。
参考
《Apache Kylin权威指南》
// 官网对术语的介绍
http://kylin.apache.org/docs23/gettingstarted/terminology.html
事实表和维度表详细介绍
http://www.lxway.com/46065956.htm
// 事实表和维度表定义 案例分析
https://blog.csdn.net/y3177530/article/details/51121652
// 星型模式&雪花模式
https://blog.csdn.net/nisjlvhudy/article/details/7889422
// cube设计模式
http://kylin.apache.org/docs/howto/howto_optimize_cubes.html