深度学习(5)——多线程输入数据处理框架
目录
摘要:
1. 队列与多线程
2. 输入文件队列
3.组合训练数据
4.输入数据处理框架
4.1 一个完整的tensorflow处理输入数据
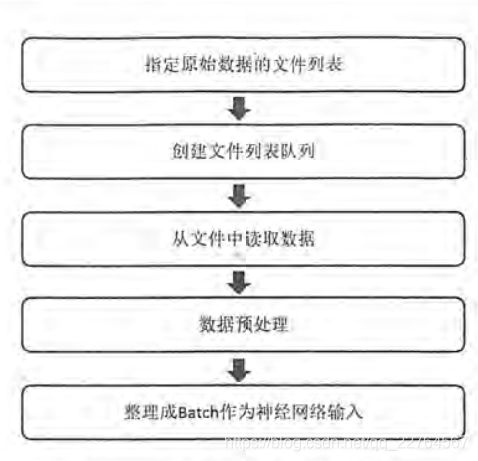
摘要:
图像处理中出现的亮度、对比度等对图像的影响很大,对图像进行预处理可以使得神经网络模型尽可能小的被无关因素影响,但复杂的预处理过程可能导致训练效率下降。为了减小预处理对训练速度的影响,就需要用到多线程处理输入数据。
1. 队列与多线程
修改队列状态的操作:Enqueue、EnqueueMany和Dequeue
tensorflow提供了两种队列,除了FIFOQueue,还有RandomShuffleQueue,后者会将队列的元素打乱,每次出队列得到的是从当前队列所有元素种随机一个
# -*- coding: utf-8 -*-
import tensorflow as tf
#创建一个先进先出队列,指定队列中最多可以保存两个元素,并指定类型
q=tf.FIFOQueue(2,"int32")
init=q.enqueue_many(([0,10],))
#使用dequeue将队列的第一个元素出队列,这个元素保存在变量x中
x=q.dequeue()
y=x+1
#重回队列
q_inc=q.enqueue([y])
with tf.Session() as sess:
init.run()
for _ in range(5):
v,_=sess.run([x,q_inc])
print(v)tensorflow中用来完成多线程协同功能的tf.Coordinator(Coordinator有协调者的意思)和tf.QueueRunner。
tf.Coordinator主要用于协同多个线程一起停止,并提供了should_stop\request_stop\join三个函数。
import tensorflow as tf
import numpy as np
import threading
import time
def MyLoop(coord,worker_id):
while not coord.should_stop():
if np.random.rand()<0.1:
print("stoping from id:%d\n"%worker_id)
else:
print("working on id:%d\n"%worker_id)
time.sleep(1)
coord=tf.train.Coordinator()
threads=[threading.Thread(target=MyLoop,args=(coord,i,)) for i in range(5)]
for t in threads:t.start()
coord.join(threads)tf.QueueRunner主要用来启动多个线程来操作同一个队列
import tensorflow as tf
#定义队列及其操作。
queue = tf.FIFOQueue(100,"float")
enqueue_op = queue.enqueue([tf.random_normal([1])])
qr = tf.train.QueueRunner(queue, [enqueue_op] * 5)
tf.train.add_queue_runner(qr)
#定义出队操作
out_tensor = queue.dequeue()
#启动线程
with tf.Session() as sess:
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(sess=sess, coord=coord)
for _ in range(3): print (sess.run(out_tensor)[0])
coord.request_stop()
coord.join(threads)2. 输入文件队列
note:Tensorflow提供了一种统一的格式来存储数据,TFRecord
#获取文件列表
files=tf.train.match_filenames_once("/path/to/data.tfrecords-*")
#通过tf.train.string_input_producer函数创建输入队列
filename_queue=tf.train.string_input_producer(files,shuffle=False)
reader = tf.TFRecordReader()
_, serialized_example = reader.read(filename_queue)
features = tf.parse_single_example(
serialized_example,
features={
'i': tf.FixedLenFeature([], tf.int64),
'j': tf.FixedLenFeature([], tf.int64),
})
with tf.Session() as sess:
sess.run([tf.global_variables_initializer(), tf.local_variables_initializer()])
print (sess.run(files))
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(sess=sess, coord=coord)
for i in range(6):
print (sess.run([features['i'], features['j']]))
coord.request_stop()
coord.join(threads)3.组合训练数据
# 组合训练数据
example, label = features['i'], features['j']
batch_size = 2
capacity = 1000 + 3 * batch_size
#使用tf.train.batch来组合样例,batch给出样例个数,capacity给出队列的最大容量
example_batch, label_batch = tf.train.batch([example, label], batch_size=batch_size, capacity=capacity)
with tf.Session() as sess:
tf.global_variables_initializer().run()
tf.local_variables_initializer().run()
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(sess=sess, coord=coord)
for i in range(3):
cur_example_batch, cur_label_batch = sess.run([example_batch, label_batch])
print cur_example_batch, cur_label_batch
coord.request_stop()
coord.join(threads)
4.输入数据处理框架
4.1 一个完整的tensorflow处理输入数据
# -*- coding: utf-8 -*-
"""
# 输入数据,使用生成的训练和测试数据。
"""
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
import numpy as np
# 定义函数转化变量类型。
def _int64_feature(value):
return tf.train.Feature(int64_list=tf.train.Int64List(value=[value]))
def _bytes_feature(value):
return tf.train.Feature(bytes_list=tf.train.BytesList(value=[value]))
# 将数据转化为tf.train.Example格式。
def _make_example(pixels, label, image):
image_raw = image.tostring()
example = tf.train.Example(features=tf.train.Features(feature={
'pixels': _int64_feature(pixels),
'label': _int64_feature(np.argmax(label)),
'image_raw': _bytes_feature(image_raw)
}))
return example
# 读取mnist训练数据。
mnist = input_data.read_data_sets("../../datasets/MNIST_data",dtype=tf.uint8, one_hot=True)
images = mnist.train.images
labels = mnist.train.labels
pixels = images.shape[1]
num_examples = mnist.train.num_examples
# 输出包含训练数据的TFRecord文件。
with tf.python_io.TFRecordWriter("output.tfrecords") as writer:
for index in range(num_examples):
example = _make_example(pixels, labels[index], images[index])
writer.write(example.SerializeToString())
print("TFRecord训练文件已保存。")
# 读取mnist测试数据。
images_test = mnist.test.images
labels_test = mnist.test.labels
pixels_test = images_test.shape[1]
num_examples_test = mnist.test.num_examples
# 输出包含测试数据的TFRecord文件。
with tf.python_io.TFRecordWriter("output_test.tfrecords") as writer:
for index in range(num_examples_test):
example = _make_example(
pixels_test, labels_test[index], images_test[index])
writer.write(example.SerializeToString())
print("TFRecord测试文件已保存。")
train_files = tf.train.match_filenames_once("output.tfrecords")
test_files = tf.train.match_filenames_once("output_test.tfrecords")
"""
# 定义解析一个TFRecord的方法。
"""
def parser(record):
features = tf.parse_single_example(
record,
features={
'image_raw':tf.FixedLenFeature([],tf.string),
'pixels':tf.FixedLenFeature([],tf.int64),
'label':tf.FixedLenFeature([],tf.int64)
})
decoded_images = tf.decode_raw(features['image_raw'],tf.uint8)
retyped_images = tf.cast(decoded_images, tf.float32)
images = tf.reshape(retyped_images, [784])
labels = tf.cast(features['label'],tf.int32)
#pixels = tf.cast(features['pixels'],tf.int32)
return images, labels
"""
# 定义训练数据集
"""
image_size = 299 # 定义神经网络输入层图片的大小。
batch_size = 100 # 定义组合数据batch的大小。
shuffle_buffer = 10000 # 定义随机打乱数据时buffer的大小。
# 定义读取训练数据的数据集。
dataset = tf.data.TFRecordDataset(train_files)
dataset = dataset.map(parser)
# 对数据进行shuffle和batching操作。这里省略了对图像做随机调整的预处理步骤。
dataset = dataset.shuffle(shuffle_buffer).batch(batch_size)
# 重复NUM_EPOCHS个epoch。
NUM_EPOCHS = 10
dataset = dataset.repeat(NUM_EPOCHS)
# 定义数据集迭代器。
iterator = dataset.make_initializable_iterator()
image_batch, label_batch = iterator.get_next()
"""
# 定义神经网络的结构以及优化过程。
"""
def inference(input_tensor, weights1, biases1, weights2, biases2):
layer1 = tf.nn.relu(tf.matmul(input_tensor, weights1) + biases1)
return tf.matmul(layer1, weights2) + biases2
INPUT_NODE = 784
OUTPUT_NODE = 10
LAYER1_NODE = 500
REGULARAZTION_RATE = 0.0001
TRAINING_STEPS = 5000
weights1 = tf.Variable(tf.truncated_normal([INPUT_NODE, LAYER1_NODE], stddev=0.1))
biases1 = tf.Variable(tf.constant(0.1, shape=[LAYER1_NODE]))
weights2 = tf.Variable(tf.truncated_normal([LAYER1_NODE, OUTPUT_NODE], stddev=0.1))
biases2 = tf.Variable(tf.constant(0.1, shape=[OUTPUT_NODE]))
y = inference(image_batch, weights1, biases1, weights2, biases2)
# 计算交叉熵及其平均值
cross_entropy = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=y, labels=label_batch)
cross_entropy_mean = tf.reduce_mean(cross_entropy)
# 损失函数的计算
regularizer = tf.contrib.layers.l2_regularizer(REGULARAZTION_RATE)
regularaztion = regularizer(weights1) + regularizer(weights2)
loss = cross_entropy_mean + regularaztion
# 优化损失函数
train_step = tf.train.GradientDescentOptimizer(0.01).minimize(loss)
"""
# 定义测试用的Dataset。
"""
test_dataset = tf.data.TFRecordDataset(test_files)
test_dataset = test_dataset.map(parser)
test_dataset = test_dataset.batch(batch_size)
# 定义测试数据上的迭代器。
test_iterator = test_dataset.make_initializable_iterator()
test_image_batch, test_label_batch = test_iterator.get_next()
# 定义测试数据上的预测结果。
test_logit = inference(test_image_batch, weights1, biases1, weights2, biases2)
predictions = tf.argmax(test_logit, axis=-1, output_type=tf.int32)
# 声明会话并运行神经网络的优化过程。
with tf.Session() as sess:
# 初始化变量。
sess.run((tf.global_variables_initializer(),
tf.local_variables_initializer()))
# 初始化训练数据的迭代器。
sess.run(iterator.initializer)
# 循环进行训练,直到数据集完成输入、抛出OutOfRangeError错误。
while True:
try:
sess.run(train_step)
except tf.errors.OutOfRangeError:
break
test_results = []
test_labels = []
# 初始化测试数据的迭代器。
sess.run(test_iterator.initializer)
# 获取预测结果。
while True:
try:
pred, label = sess.run([predictions, test_label_batch])
test_results.extend(pred)
test_labels.extend(label)
except tf.errors.OutOfRangeError:
break
# 计算准确率
correct = [float(y == y_) for (y, y_) in zip (test_results, test_labels)]
accuracy = sum(correct) / len(correct)
print("Test accuracy is:", accuracy)