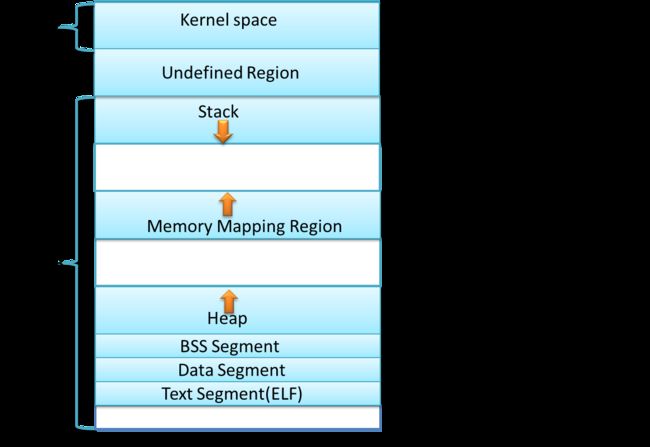
linux进程内存布局
在多任务操作系统中的每一个进程都运行在一个属于它自己的内存沙盘中。这个沙盘就是虚拟地址空间(virtual address space),在32位模式下它总是一个4GB的内存地址块。这些虚拟地址通过页表(page table)映射到物理内存,页表由操作系统维护并被处理器引用。每一个进程拥有一套属于它自己的页表,但是还有一个隐情。只要虚拟地址被使能,那么它就会作用于这台机器上运行的所有软件,包括内核本身。因此一部分虚拟地址必须保留给内核使用:
这并不意味着内核使用了那么多的物理内存,仅表示它可支配这么大的地址空间,可根据内核需要,将其映射到物理内存。内核空间在页表中拥有较高的特权级(ring 2或以下),因此只要用户态的程序试图访问这些页,就会导致一个页错误(page fault)。在Linux中,内核空间是持续存在的,并且在所有进程中都映射到同样的物理内存。内核代码和数据总是可寻址的,随时准备处理中断和系统调用。与此相反,用户模式地址空间的映射随进程切换的发生而不断变化:
色区域表示映射到物理内存的虚拟地址,而白色区域表示未映射的部分。在上面的例子中,Firefox使用了相当多的虚拟地址空间,因为它是传说中的吃内存大户。地址空间中的各个条带对应于不同的内存段(memory segment),如:堆、栈之类的。记住,这些段只是简单的内存地址范围,与Intel处理器的段没有关系。不管怎样,下面是一个Linux进程的标准的内存段布局:
当计算机开心、安全、可爱、正常的运转时,几乎每一个进程的各个段的起始虚拟地址都与上图完全一致,这也给远程发掘程序安全漏洞打开了方便之门。一个发掘过程往往需要引用绝对内存地址:栈地址,库函数地址等。远程攻击者必须依赖地址空间布局的一致性,摸索着选择这些地址。如果让他们猜个正着,有人就会被整了。因此,地址空间的随机排布方式逐渐流行起来。Linux 通过对栈内存映射段、堆的起始地址加上随机的偏移量来打乱布局。不幸的是,32 位地址空间相当紧凑,给随机化所留下的空当不大,削弱了这种技巧的效果。
进程地址空间中最顶部的段是栈,大多数编程语言将之用于存储局部变量和函数参数。调用一个方法或函数会将一个新的栈桢(stack frame)压入栈中。栈桢在函数返回时被清理。也许是因为数据严格的遵从LIFO的顺序,这个简单的设计意味着不必使用复杂的数据结构来追踪栈的内容,只需要一个简单的指针指向栈的顶端即可。因此压栈(pushing)和退栈(popping)过程非常迅速、准确。另外,持续的重用栈空间有助于使活跃的栈内存保持在CPU缓存中,从而加速访问。进程中的每一个线程都有属于自己的栈。
通过不断向栈中压入的数据,超出其容量就有会耗尽栈所对应的内存区域。这将触发一个页故障(page fault),并被 Linux 的expand_stack()处理,它会调用acct_stack_growth()来检查是否还有合适的地方用于栈的增长。如果栈的大小低于RLIMIT_STACK(通常是8MB),那么一般情况下栈会被加长,程序继续愉快的运行,感觉不到发生了什么事情。这是一种将栈扩展至所需大小的常规机制。然而,如果达到了最大的栈空间大小,就会栈溢出(stack overflow),程序收到一个段错误(Segmentation Fault)。当映射了的栈区域扩展到所需的大小后,它就不会再收缩回去,即使栈不那么满了。这就好比联邦预算,它总是在增长的。
动态栈增长是唯一一种访问未映射内存区域(图中白色区域)而被允许的情形。其它任何对未映射内存区域的访问都会触发页故障,从而导致段错误。一些被映射的区域是只读的,因此企图写这些区域也会导致段错误。
在栈的下方,是我们的内存映射段。此处,内核将文件的内容直接映射到内存。任何应用程序都可以通过 Linux 的 mmap() 系统调用(实现)或 Windows 的 CreateFileMapping()/MapViewOfFile()请求这种映射。内存映射是一种方便高效的文件 I/O 方式,所以它被用于加载动态库。创建一个不对应于任何文件的匿名内存映射也是可能的,此方法用于存放程序的数据。在 Linux 中,如果你通过 malloc()请求一大块内存,C 运行库将会创建这样一个匿名映射而不是使用堆内存。‘大块’意味着比MMAP_THRESHOLD 还大,缺省是 128KB ,可以通过mallopt()调整。
说到堆,它是接下来的一块地址空间。与栈一样,堆用于运行时内存分配;但不同点是,堆用于存储那些生存期与函数调用无关的数据。大部分语言都提供了堆管理功能。因此,满足内存请求就成了语言运行时库及内核共同的任务。在 C 语言中,堆分配的接口是malloc()系列函数,而在具有垃圾收集功能的语言(如 C# )中,此接口是 new 关键字。
如果堆中有足够的空间来满足内存请求,它就可以被语言运行时库处理而不需要内核参与。否则,堆会被扩大,通过brk()系统调用(实现)来分配请求所需的内存块。堆管理是很复杂的,需要精细的算法,应付我们程序中杂乱的分配模式,优化速度和内存使用效率。处理一个堆请求所需的时间会大幅度的变动。实时系统通过特殊目的分配器来解决这个问题。堆也可能会变得零零碎碎,如下图所示:
最后,我们来看看最底部的内存段:BSS,数据段,代码段。在C语言中,BSS和数据段保存的都是静态(全局)变量的内容。区别在于BSS保存的是未被初始化的静态变量内容,它们的值不是直接在程序的源代码中设定的。BSS内存区域是匿名的:它不映射到任何文件。如果你写static int cntActiveUsers,则cntActiveUsers的内容就会保存在BSS中。
另一方面,数据段保存在源代码中已经初始化了的静态变量内容。这个内存区域不是匿名的。它映射了一部分的程序二进制镜像,也就是源代码中指定了初始值的静态变量。所以,如果你写static int cntWorkerBees = 10,则cntWorkerBees的内容就保存在数据段中了,而且初始值为10。尽管数据段映射了一个文件,但它是一个私有内存映射,这意味着更改此处的内存不会影响到被映射的文件。也必须如此,否则给全局变量赋值将会改动你硬盘上的二进制镜像,这是不可想象的。
下图中数据段的例子更加复杂,因为它用了一个指针。在此情况下,指针gonzo(4字节内存地址)本身的值保存在数据段中。而它所指向的实际字符串则不在这里。这个字符串保存在代码段中,代码段是只读的,保存了你全部的代码外加零零碎碎的东西,比如字符串字面值。代码段将你的二进制文件也映射到了内存中,但对此区域的写操作都会使你的程序收到段错误。这有助于防范指针错误,虽然不像在C语言编程时就注意防范来得那么有效。下图展示了这些段以及我们例子中的变量:
你可以通过阅读文件/proc/pid_of_process/maps来检验一个Linux进程中的内存区域。记住一个段可能包含许多区域。比如,每个内存映射文件在mmap段中都有属于自己的区域,动态库拥有类似BSS和数据段的额外区域。下一篇文章讲说明这些“区域”(area)的真正含义。有时人们提到“数据段”,指的就是全部的数据段 + BSS + 堆。
你可以通过nm和objdump命令来察看二进制镜像,打印其中的符号,它们的地址,段等信息。最后需要指出的是,前文描述的虚拟地址布局在Linux 中是一种“灵活布局”(flexible layout),而且以此作为默认方式已经有些年头了。它假设我们有值 RLIMIT_STACK。当情况不是这样时, Linux 退回使用“经典布局”(classic layout),如下图所示:
对虚拟地址空间的布局就讲这些吧。下一篇文章将讨论内核是如何跟踪这些内存区域的。我们会分析内存映射,看看文件的读写操作是如何与之关联的,以及内存使用概况的含义。
内存管理是操作系统的核心之一,最近在研究内核的内存管理以及C 运行时库对内存的分配和管理,涉及到进程在内存的布局,在此对进程的内存布局做一下总结:
1. 32 位模式下的 linux 内存布局
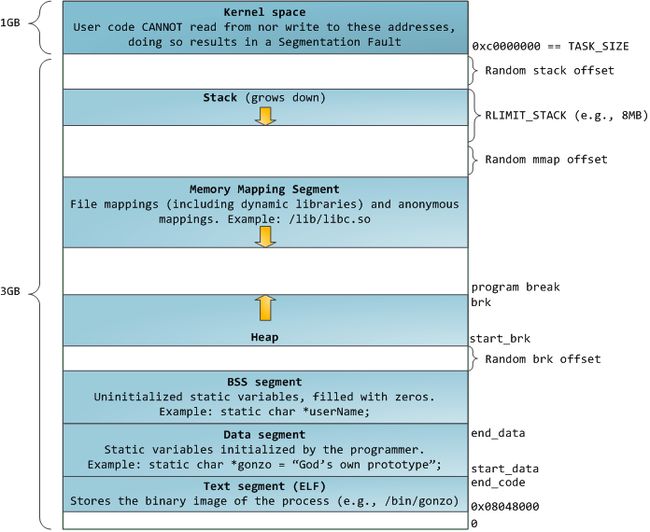
图上的各个部分描述得比较清楚,不需再做过多的描述。从上图可以看到,栈至顶向下扩展,并且栈是有界的。堆至底向上扩展,mmap 映射区域至顶向下扩展,mmap 映射区域和堆相对扩展,直至耗尽虚拟地址空间中的剩余区域,这种结构便于C 运行时库使用mmap 映射区域和堆进行内存分配。上图的布局形式是在内核2.6.7 以后才引入的,这是32 位模式下的默认内存布局形式。看看cat 命令在2.6.36 上内存布局:
08048000-08051000 r-xp 00000000 08:01 786454 /bin/cat
08051000-08052000 r--p 00008000 08:01 786454 /bin/cat
08052000-08053000 rw-p 00009000 08:01 786454 /bin/cat
08053000-08074000 rw-p 00000000 00:00 0 [heap]
b73e3000-b75e3000 r--p 00000000 08:01 400578 /usr/lib/locale/locale-archive
b75e3000-b75e4000 rw-p 00000000 00:00 0
b75e4000-b773b000 r-xp 00000000 08:01 1053967 /lib/libc-2.12.1.so
b773b000-b773c000 ---p 00157000 08:01 1053967 /lib/libc-2.12.1.so
b773c000-b773e000 r--p 00157000 08:01 1053967 /lib/libc-2.12.1.so
b773e000-b773f000 rw-p 00159000 08:01 1053967 /lib/libc-2.12.1.so
b773f000-b7742000 rw-p 00000000 00:00 0
b774f000-b7750000 r--p 002a1000 08:01 400578 /usr/lib/locale/locale-archive
b7750000-b7752000 rw-p 00000000 00:00 0
b7752000-b7753000 r-xp 00000000 00:00 0 [vdso]
b7753000-b776f000 r-xp 00000000 08:01 1049013 /lib/ld-2.12.1.so
b776f000-b7770000 r--p 0001b000 08:01 1049013 /lib/ld-2.12.1.so
b7770000-b7771000 rw-p 0001c000 08:01 1049013 /lib/ld-2.12.1.so
bfbed000-bfc0e000 rw-p 00000000 00:00 0 [stack]
可以看到,栈和mmap 映射区域并不是从一个固定地址开始,并且每次的值都不一样,这是程序在启动时随机改变这些值的设置,使得使用缓冲区溢出进行攻击更加困难。当然也可以让程序的栈和mmap 映射区域从一个固定位置开始,只需要设置全局变量randomize_v a_space 值为 0 ,这个变量默认值为 1 。用户可以通过设置 /proc/sys/kernel/randomize_va_space 来停用该特性,也可以用如下命令:
sudo sysctl -w kernel.randomize_va_space=0
设置randomize_va_space 为 0 后,再看看 cat 的内存布局:
08048000-08051000 r-xp 00000000 08:01 786454 /bin/cat
08051000-08052000 r--p 00008000 08:01 786454 /bin/cat
08052000-08053000 rw-p 00009000 08:01 786454 /bin/cat
08053000-08074000 rw-p 00000000 00:00 0 [heap]
b7c72000-b7e72000 r--p 00000000 08:01 400578 /usr/lib/locale/locale-archive
b7e72000-b7e73000 rw-p 00000000 00:00 0
b7e73000-b7fca000 r-xp 00000000 08:01 1053967 /lib/libc-2.12.1.so
b7fca000-b7fcb000 ---p 00157000 08:01 1053967 /lib/libc-2.12.1.so
b7fcb000-b7fcd000 r--p 00157000 08:01 1053967 /lib/libc-2.12.1.so
b7fcd000-b7fce000 rw-p 00159000 08:01 1053967 /lib/libc-2.12.1.so
b7fce000-b7fd1000 rw-p 00000000 00:00 0
b7fde000-b7fdf000 r--p 002a1000 08:01 400578 /usr/lib/locale/locale-archive
b7fdf000-b7fe1000 rw-p 00000000 00:00 0
b7fe1000-b7fe2000 r-xp 00000000 00:00 0 [vdso]
b7fe2000-b7ffe000 r-xp 00000000 08:01 1049013 /lib/ld-2.12.1.so
b7ffe000-b7fff000 r--p 0001b000 08:01 1049013 /lib/ld-2.12.1.so
b7fff000-b8000000 rw-p 0001c000 08:01 1049013 /lib/ld-2.12.1.so
bffdf000-c0000000 rw-p 00000000 00:00 0 [stack]
可以看出,栈和mmap 区域都从固定位置开始了,stack 的起始位置为0x c0000000, mmap区域的起始位置为 0x b8000000 ,可见系统为 stack 区域保留了 128M 内存地址空间。
在某些情况下,设置randomize_va_space 为 0 ,便于对系统做一些针对性的研究,例如:进程的内存映射有个叫 vdso的区域,也就是用 ldd 命令看到的那个” linux-gate.so.1 “,这块区域可以看成是内核用于实现 vsyscall 而创建的 virtual shared object ,遵循 elf 的格式,并且可以被用户程序访问。在设置 randomize_va_space 为 0 的情况下,使用如下命令就可以把这个区域 dump 出来看过究竟。如果不设置 randomize_va_space ,每次 vdso 的地址都是随机的,下面的命令也无能为力。
zhuang@ubuntu:~$ dd if=/proc/self/mem of=gate.so bs=4096 skip=$[0xb7fe1] count=1
dd: `/proc/self/mem': cannot skip to specified offset
1+0 records in
1+0 records out
4096 bytes (4.1 kB) copied, 0.00144225 s, 2.8 MB/s
zhuang@ubuntu:~$ objdump -d gate.so
gate.so: file format elf32-i386
Disassembly of section .text:
ffffe400 <__kernel_sigreturn>:
ffffe400: 58 pop %eax
ffffe401: b8 77 00 00 00 mov $0x77,%eax
ffffe406: cd 80 int $0x80
ffffe408: 90 nop
ffffe409: 8d 76 00 lea 0x0(%esi),%esi
ffffe40c <__kernel_rt_sigreturn>:
ffffe40c: b8 ad 00 00 00 mov $0xad,%eax
ffffe411: cd 80 int $0x80
ffffe413: 90 nop
ffffe414 <__kernel_vsyscall>:
ffffe414: 51 push %ecx
ffffe415: 52 push %edx
ffffe416: 55 push %ebp
ffffe417: 89 e5 mov %esp,%ebp
ffffe419: 0f 34 sysenter
ffffe41b: 90 nop
ffffe41c: 90 nop
ffffe41d: 90 nop
ffffe41e: 90 nop
ffffe41f: 90 nop
ffffe420: 90 nop
ffffe421: 90 nop
ffffe422: eb f3 jmp ffffe417 <__kernel_vsyscall+0x3>
ffffe424: 5d pop %ebp
ffffe425: 5a pop %edx
ffffe426: 59 pop %ecx
ffffe427: c3 ret
2. 32 为模式下的经典布局:

这种布局mmap 区域与栈区域相对增长,这意味着堆只有1GB 的虚拟地址空间可以使用,继续增长就会进入mmap 映射区域,这显然不是我们想要的。这是由于32 模式地址空间限制造成的,所以内核引入了前一种虚拟地址空间的布局形式。但是对 64 位模式,提供了巨大的虚拟地址空间,这个布局就相当好。如果要在 2.6.7 以后的内核上使用 32 位模式内存经典布局,有两种办法可以设置:
方法一:sudo sysctl -w vm.legacy_va_layout=1
方法二:ulimit -s unlimited
同时设置randomize_va_space 为 0 后, cat 的内存布局已经回到经典形式了:
08048000-08051000 r-xp 00000000 08:01 786454 /bin/cat
08051000-08052000 r--p 00008000 08:01 786454 /bin/cat
08052000-08053000 rw-p 00009000 08:01 786454 /bin/cat
08053000-08074000 rw-p 00000000 00:00 0 [heap]
40000000-4001c000 r-xp 00000000 08:01 1049013 /lib/ld-2.12.1.so
4001c000-4001d000 r--p 0001b000 08:01 1049013 /lib/ld-2.12.1.so
4001d000-4001e000 rw-p 0001c000 08:01 1049013 /lib/ld-2.12.1.so
4001e000-4001f000 r-xp 00000000 00:00 0 [vdso]
4001f000-40021000 rw-p 00000000 00:00 0
40021000-40022000 r--p 002a1000 08:01 400578 /usr/lib/locale/locale-archive
4002f000-40186000 r-xp 00000000 08:01 1053967 /lib/libc-2.12.1.so
40186000-40187000 ---p 00157000 08:01 1053967 /lib/libc-2.12.1.so
40187000-40189000 r--p 00157000 08:01 1053967 /lib/libc-2.12.1.so
40189000-4018a000 rw-p 00159000 08:01 1053967 /lib/libc-2.12.1.so
4018a000-4018e000 rw-p 00000000 00:00 0
4018e000-4038e000 r--p 00000000 08:01 400578 /usr/lib/locale/locale-archive
bffdf000-c0000000 rw-p 00000000 00:00 0 [stack]
3. 64 位模式下的内存布局
在64 位模式下各个区域的起始位置是什么呢?对于AMD64 ,内存布局采用的是经典模式, text 的起始地址为 0x0000000000400000 ,堆紧接着 BSS 段向上增长, mmap 映射区域开始位置一般设为 TASK_SIZE/3 ,
#define TASK_SIZE_MAX ((1UL << 47) - PAGE_SIZE)
#define TASK_SIZE (test_thread_flag(TIF_IA32) ? \
IA32_PAGE_OFFSET : TASK_SIZE_MAX)
#define STACK_TOP TASK_SIZE
#define TASK_UNMAPPED_BASE (PAGE_ALIGN(TASK_SIZE / 3))
计算一下可知,mmap 的开始区域地址为 0x0000 2AAAAAAAA000,栈顶地址为 0x00007FFFFFFFF000