分布式文件系统 IPFS 与 FileCoin
分布式文件系统 IPFS 与 FileCoin
在这篇文章中,我想聊一聊最近比较热门的 IPFS(InterPlanetary File System),一个点对点的分布式文件系统;从 HTTP 协议出现到今天已经过去了半个多世纪,很少有一些设计能够增强整个 HTTP 网络或者为它带来新的功能。

使用 HTTP 协议传递相对小的文件其实是非常廉价和方便的,但是随着计算资源和存储空间的指数增长,我们面临了需要随时获取大量数据的问题,而 IPFS 就是为了解决这一问题出现的。
架构设计
作为一个分布式的文件系统,IPFS 提供了一个支持部署和写入的平台,同时能够支持大文件的分发和版本管理;为了达到上述的目的,IPFS 协议被分成如下的几个子协议:
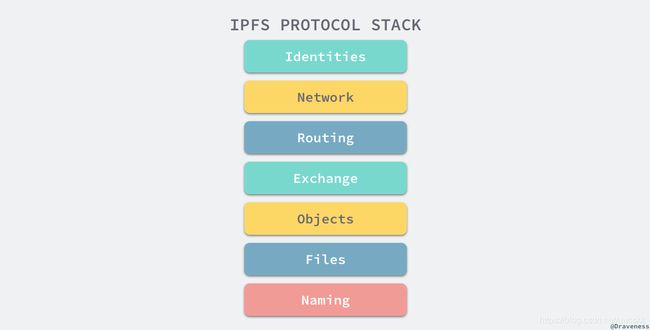
上述的七个子协议分别负责 IPFS 中的不同功能,我们将在接下来的章节中分别介绍各个协议分别做了哪些工作以及 IPFS 是如何实现的。
身份
在 IPFS 网络中,所有的节点都通过唯一的 NodeId 进行标识,与 Bitcoin 的地址有一些相似, 它其实是一个公钥的哈希,然而为了增加攻击者的成本,IPFS 使用 S/Kademlia 中提到的算法增加创建新身份的成本:
difficulty = <integer parameter>
n = Node{
}
do {
n.PubKey, n.PrivKey = PKI.genKeyPair()
n.NodeId = hash(n.PubKey)
p = count_preceding_zero_bits(hash(n.NodeId))
} while (p < difficulty)
每一个节点在 IPFS 代码中都由 Node 结构体来表示,其中只包含 NodeId 以及一个公私钥对:
type NodeId Multihash
type Multihash []byte
type PublicKey []byte
type PrivateKey []byte
type Node struct {
NodeId NodeId
PubKey PublicKey
PriKey PrivateKey
}
总之,身份系统的主要作用就是表示 IPFS 网络中的每一个节点,代表每一个使用 IPFS 的『用户』。
网络
作为一个分布式的存储系统,节点之间的通信和信息传递都需要通过网络进行,同时能够使用多种传输层协议并保证可靠性、连通性、信息的完整性以及真实性。
IPFS 可以使用任意的网络进行通信,它并没有假设自己一定运行在 IP 协议上,而是通过 multiaddr 的格式来表示目标地址和使用的协议,以此来兼容和扩展未来可能出现的其他网络协议:
/ip4/10.20.30/40/sctp/1234/
/ip4/5.6.7.8/tcp/5678/ip4/1.2.3.4/sctp/1234/
路由
在一个分布式系统中,检索或者访问其他节点中存储的资源就需要通过一个路由系统,IPFS 使用了基于 S/Kademlia 和 Coral 中的 DSHT 实现了路由系统,我们能够在 libp2p/go-libp2p-routing/routing.go 中找到 IPFS 路由系统的接口:
type IpfsRouting interface {
ContentRouting
PeerRouting
ValueStore
Bootstrap(context.Context) error
}
type ContentRouting interface {
Provide(context.Context, *cid.Cid, bool) error
FindProvidersAsync(context.Context, *cid.Cid, int) <-chan pstore.PeerInfo
}
type PeerRouting interface {
FindPeer(context.Context, peer.ID) (pstore.PeerInfo, error)
}
type ValueStore interface {
PutValue(context.Context, string, []byte) error
GetValue(context.Context, string) ([]byte, error)
GetValues(c context.Context, k string, count int) ([]RecvdVal, error)
}
从这里我们可以看到 IPFS 中的路由需要实现三种基本的功能,内容路由、节点路由以及数据存储。实现了这几些接口的『路由器』就可以在底层进行替换,不会影响系统其他部分的工作。目前 IPFS 使用全局 DHT 和 DNS 来解析路由记录,而 Kademlia DHT 有以下的优点:
- 在批量节点中快速找到目标地址,时间复杂度是 l o g 2 ( n ) log_2(n) log2(n),也就是说,在 10,000,000 节点中只需要 20 次查询;
- 优化了节点之间的控制消息长度,降低了信息协调的开销;
- 通过优先选择长期节点抵御多种网络攻击;
- 在点对点的应用中被广泛应用,例如 BitTorrent 和 Gnutella,技术也比较成熟;
数据交换
在 IPFS 中,数据的分发和交换使用 BitSwap 协议,BitSwap 负责两件事情:向其他节点请求需要的 Block 以及为其他节点提供 Block。

当我们需要向其他节点请求 Block 或者为其他节点提供 Block 时,都会发送 BitSwap 消息,其中主要包含了两部分内容:发送者的 wantlist 以及数据块,整个消息都是使用 Protobuf 进行编码的:
message Message {
message Wantlist {
message Entry {
optional string block = 1; // the block key
optional int32 priority = 2; // the priority (normalized). default to 1
optional bool cancel = 3; // whether this revokes an entry
}
repeated Entry entries = 1; // a list of wantlist entries
optional bool full = 2; // whether this is the full wantlist. default to false
}
optional Wantlist wantlist = 1;
repeated bytes blocks = 2;
}
在 BitSwap 系统中,有两个非常重要的模块需求管理器(Want-Manager)和决定引擎(Decision-Engine);前者会在节点请求 Block 时在本地返回相应的 Block 或者发出合适的请求,而后者决定如何为其他节点分配资源,当节点接收到包含 Wantlist 的消息时,消息会被转发至决定引擎,引擎会根据该节点的 Ledger 决定如何处理请求。
想要了解跟多 BitSwap 的实现细节以及 Spec 的读者可以阅读 BitSwap Spec 其他内容。
IPFS 除了定义节点之间互相发送的消息之外,还引入了激励和惩罚来保证整个网络中不会有『恶意』的节点,通过 Ledger 来存储两个节点之间的数据来往:
type Ledger struct {
owner NodeId
partner NodeId
bytes_sent int
bytes_recv int
timestamp Timestamp
}
决定引擎会通过两个节点之间的 Ledger 计算出一个负债比率(debt ratio):
负债比率是用来衡量节点之间信任的,它不仅能够阻止攻击者创建大量的节点、还能在节点短时间不可用时保护已有的交易关系并且在节点关系恶化之前终止交易。
IPFS 使用 Ledger 创建了一个具有激励和惩罚的网络,保证了网络中的大部分节点能够交换数据并且正常运行。
文件系统
DHT 和 BitSwap 允许 IPFS 构建一个用于存储和分发数据块的大型点对点系统;在这之上,IPFS 构建了一个 Merkle DAG,每一个 IPFS 对象都可能包含一组链接和当前节点中的数据:
type IPFSLink struct {
Name string
Hash Multihash
Size int
}
type IPFSObject struct {
links []IPFSLink
data []byte
}
我们可以使用如下的命令列出该对象下的全部链接:
$ ipfs ls QmYwAPJzv5CZsnA625s3Xf2nemtYgPpHdWEz79ojWnPbdG
QmZTR5bcpQD7cFgTorqxZDYaew1Wqgfbd2ud9QqGPAkK2V 1688 about
QmYCvbfNbCwFR45HiNP45rwJgvatpiW38D961L5qAhUM5Y 200 contact
QmY5heUM5qgRubMDD1og9fhCPA6QdkMp3QCwd4s7gJsyE7 322 help
QmdncfsVm2h5Kqq9hPmU7oAVX2zTSVP3L869tgTbPYnsha 1728 quick-start
QmPZ9gcCEpqKTo6aq61g2nXGUhM4iCL3ewB6LDXZCtioEB 1102 readme
QmTumTjvcYCAvRRwQ8sDRxh8ezmrcr88YFU7iYNroGGTBZ 1027 security-notes
原始数据加上通用的链接是在 IPFS 上构造任意数据结构的基础,键值存储、传统的关系型数据库、加密区块链都可以在 IPFS 的 Merkle DAG 上进行存储和分发。
在这之上,IPFS 定义了一系列的对象构建了支持版本控制的文件系统,它与 Git 的对象模型非常类似,并且所有文件对象其实都通过 Protobuf 进行了二进制编码:

IPFS 文件可以通过 list 和 blob 进行表示:
- 其中 blob 不包含任何的链接,只包含数据;
- 但是 list 却包含了一个 blob 和 list 的有序队列
- 而 tree 文件对象与 Git 中的 tree 非常相似,它表示一个从名字到哈希的文件目录;
- 最后的 commit 表示任意对象的快照;
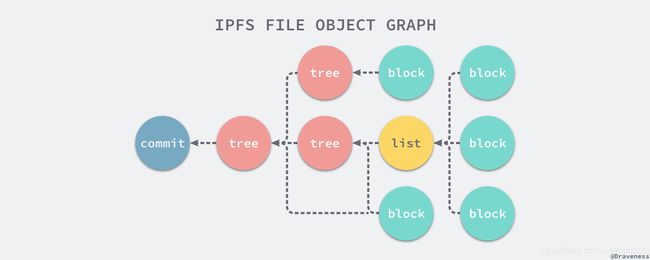
在上述文件对象图中,最顶层的 commit 就表示历史的某一次快照,对比两次 commit 以及子节点构成的树就能得到两次快照之间的差别,我们可以认为 Merkle DAG 和文件对象构成了整个 IPFS 中的文件系统。
命名系统
到目前为止,IPFS 技术栈已经提供了一个点对点的数据交换系统,能够在节点之间发送 DAG 对象,并且可以推送和取回不可变的对象,但是可变的命名系统也是网络不可缺少的一部分,我们终究需要使用同一个地址获取不同的状态,因为不能因为网站的更新而改变域名,所以 IPFS 需要提供一种『域名服务』解决这一问题。
在 IPFS 中可以使用如下的可变命名空间来解决这些问题,用户可以发布一个对象,其他节点就可以通过 ipns 加上该用户的节点地址访问到这些发布到网络中的对象:
/ipns/XLF2ipQ4jD3UdeX5xp1KBgeHRhemUtaA8Vm/
当然,我们也可以在现有的 DNS 系统中添加 TXT 记录,这样就能通过域名访问 IPFS 网络中发布的文件对象了:
ipfs.benet.ai. TXT "ipfs=XLF2ipQ4jD3UdeX5xp1KBgeHRhemUtaA8Vm"
/ipns/XLF2ipQ4jD3UdeX5xp1KBgeHRhemUtaA8Vm
/ipns/ipfs.benet.ai
在 IPFS 不仅能够使用哈希访问可变对象,也能嵌入现有的 DNS 服务中很好的运行,解决了底层服务无缝切换的问题。
激励
在今天,当我们讨论 IPFS 这种底层的区块链技术时,就不得不提构建在 IPFS 上的 FileCoin,它提供了一个给宿主和上传者交易的市场,通过市场可以调节存储的成本,上传者能够根据价格选择速度、冗余和成本。
节点
大多数的区块链网络中都只具有单一类型的标准节点,但是 FileCoin 中却有两种不同的节点:存储节点和检索节点。

所有人都可以成为存储节点,将自己磁盘上额外的存储空间租赁出去,FileCoin 会使用这些磁盘存储一些较小的加密文件的一部分;而检索节点则需要尽可能靠近更多的存储节点,也需要更高的带宽和更低的延迟,用户会支付最快返回文件的检索节点。
当我们想要上传文件时,需要支付一定的存储费用,存储节点会为存储文件的权利给出报价,FileCoin 会选择价格最低的存储节点保存文件;存储的文件会被加密并分割成多个部分并发送给多个节点,文件的位置会存储在全局的表中,在这之后只有拥有私钥的节点才能查询、组装并且解密上传的文件。
共识算法
我们可以说所有的区块链应用都需要 共识算法 保证多个节点对某一结果达成共识,并在发生冲突时进行解决,Bitcoin 和 Ethereum 目前都使用了 Proof-of-Work 作为共识算法,而 FileCoin 使用 Proof-of-Replication(PoRep) 解决其网络内部存在的问题。
We introduce Proof-of-Replication (PoRep) schemes, which allow a prover P to (a) commit to store n distinct replicas (physically independent copies) of D, and then (b) convince a verifier V that P is indeed storing each of the replicas.
PoRep 允许证明者 P 提交存储 n 个 D 的不同副本,然后说服验证人 V,P 确实保存了这些副本。
在 Proof of Replication 一文中能够找到更多与 PoRep、PoS(Proof-of-Storage) 等用于验证磁盘空间提供方确实存储资源的共识算法,在这里就不展开介绍了。
总结
IPFS 是一个非常有意思的区块链底层技术,它在兼容现有互联网协议的基础上,实现了点对点的文件存储系统并且为大数据存储提出了方案,作者尝试了一下 IPFS 的官方客户端 go-ipfs 也确实比较好用,但是目前也是在项目的早期阶段,很多模块和功能还没有定型,而基于 IPFS 发布的 FileCoin 也没有要发布的确切日志 Proof of Replication 这篇白皮书还被标记为 WIP(Work In Process),有一些部分也没有完成,所以等待这门技术的成熟也确实需要比较长的一段时间。