阿里云搭建Zookeeper集群
为什么要使用zookeeper集群
大部分分布式应用需要一个主控、协调器或者控制器来管理物理分布的子进程。目前,大多数都要开发私有的协调程序,缺乏一个通用机制,协调程序的反复编写浪费,且难以形成通用、伸缩性好的协调器,zookeeper提供通用的分布式锁(数据库,redis,zookeeper)服务,用以协调分布式应用。所以说zookeeper是分布式应用的协作服务。
zookeeper作为注册中心,服务器和客户端都要访问,如果有大量的并发,肯定会有等待。所以可以通过zookeeper集群解决。
下面是zookeeper集群部署结构图:
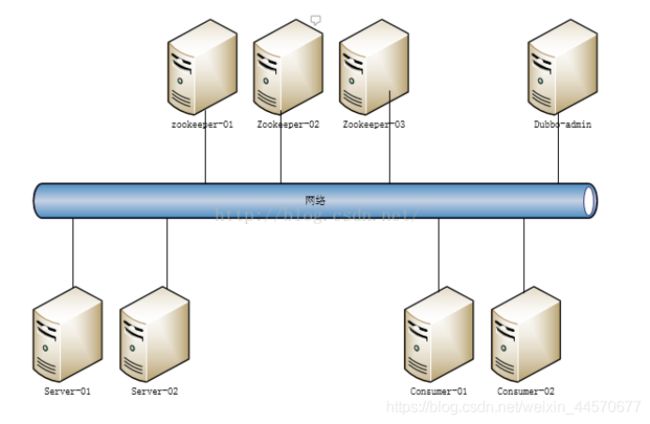
了解Leader选举:
Zookeeper的启动过程中leader选举是非常重要而且最复杂的一个环节。那么什么是leader选举呢?zookeeper为什么需要leader选举呢?zookeeper的leader选举的过程又是什么样子的?
首先我们来看看什么是leader选举。其实这个很好理解,leader选举就像总统选举一样,每人一票,获得多数票的人就当选为总统了。在zookeeper集群中也是一样,每个节点都会投票,如果某个节点获得超过半数以上的节点的投票,则该节点就是leader节点了。
以一个简单的例子来说明整个选举的过程.
假设有五台服务器组成的zookeeper集群,它们的id从1-5,同时它们都是最新启动的,也就是没有历史数据,在存放数据量这一点上,都是一样的.假设这些服务器依序启动,来看看会发生什么 。
1) 服务器1启动,此时只有它一台服务器启动了,它发出去的报没有任何响应,所以它的选举状态一直是LOOKING状态
2) 服务器2启动,它与最开始启动的服务器1进行通信,互相交换自己的选举结果,由于两者都没有历史数据,所以id值较大的服务器2胜出,但是由于没有达到超过半数以上的服务器都同意选举它(这个例子中的半数以上是3),所以服务器1,2还是继续保持LOOKING状态.
3) 服务器3启动,根据前面的理论分析,服务器3成为服务器1,2,3中的老大,而与上面不同的是,此时有三台服务器选举了它,所以它成为了这次选举的leader.
4) 服务器4启动,根据前面的分析,理论上服务器4应该是服务器1,2,3,4中最大的,但是由于前面已经有半数以上的服务器选举了服务器3,所以它只能接收当小弟的命了.
5) 服务器5启动,同4一样,当小弟
搭建Zookeeper集群
真实的集群是需要部署在不同的服务器上的,所以我们我们为了学习测试搭建伪集群,也就是把所有的服务都搭建在一台上,用端口进行区分。
准备工作
- 服务器安装jdk
- Zookeeper压缩包上传到服务器
- 将Zookeeper解压 ,创建data目录 ,将 conf下zoo_sample.cfg 文件改名为 zoo.cfg
- 建立/usr/local/zookeeper-cluster目录,将解压后的Zookeeper复制到以下三个目录
/usr/local/zookeeper-cluster/zookeeper1
/usr/local/zookeeper-cluster/zookeeper2
/usr/local/zookeeper-cluster/zookeeper3

5.(5)配置每一个Zookeeper 的dataDir(zoo.cfg) clientPort 分别为2182 ,
2183, 2184
配置每一个zookeeper的端口和data文件夹的位置:
/usr/local/java/zookeeper/zookeeper-cluster/zookeeper1/conf/zoo.cfg:
clientPort=2182
dataDir=/usr/local/java/zookeeper/zookeeper-cluster/zookeeper1/data
/usr/local/java/zookeeper/zookeeper-cluster/zookeeper2/ conf/zoo.cfg:
clientPort=2183
dataDir=/usr/local/java/zookeeper/zookeeper-cluster/zookeeper2/data
/usr/local/java/zookeeper/zookeeper-cluster/zookeeper3/ conf/zoo.cfg:
clientPort=2184
dataDir=/usr/local/java/zookeeper/zookeeper-cluster/zookeeper3/data
配置集群
1.(1)在每个zookeeper的 data 目录下创建一个 myid 文件,内容分别是 1、2、3 。这个文件就是记录每个服务器的ID
------知识点小贴士------
如果你要创建的文本文件内容比较简单,我们可以通过echo 命令快速创建文件
格式为:
echo 内容 >文件名
例如我们为第一个zookeeper指定ID为1,则输入命令

2.在每一个zookeeper 的 zoo.cfg配置客户端访问端口(clientPort)和集群服务器IP列表。
server.1=127.0.0.1:2882:3881
server.2=127.0.0.1:2883:3882
server.3=127.0.0.1:2884:3883
在这里改成本机地址是因为是用的服务器伪集群,如果是多台服务器连接,换成相应的服务器 ip就可以了。
解释:server.服务器ID=服务器IP地址:服务器之间通信端口:服务器之间投票选举端口
启动集群
启动集群就是分别启动每个实例。

启动后我们查询一下每个实例的运行状态
先查询第一个服务
![]() Mode为follower表示是跟随者(从)
Mode为follower表示是跟随者(从)
再查询第二个服务Mod 为follower表示是跟随者(从)
![]() 再查询第三个服务Mod 为leader表示是领导者(主)
再查询第三个服务Mod 为leader表示是领导者(主)
![]() 模拟集群异常
模拟集群异常
1.首先我们先测试如果是从服务器挂掉,会怎么样
把1号服务器停掉,观察2号,
![]() 3号,发现状态并没有变化
3号,发现状态并没有变化

然后我们把2号服务器给停掉:

然后我们再查看3号服务器的状态:
 已经停止运行了 。
已经停止运行了 。
由此得出结论,3个节点的集群,2个从服务器都挂掉,主服务器也无法运行。因为可运行的机器没有超过集群总数量的半数。
我们再次把2号服务器启动起来
发现3号服务器又开始正常工作了。而且依然是领导者。
![]()
我们再把1号服务器启动起来:

然后我们把3号服务器停掉:
然后再启动2号服务器:

发现新的leader产生了~
由此我们得出结论,当集群中的主服务器挂了,集群中的其他服务器会自动进行选举状态,然后产生新得leader
我们再次测试,当我们把3号服务器重新启动起来启动后,会发生什么?3号服务器会再次成为新的领导吗?
我们看结果:
 我们会发现,3号服务器启动后依然是跟随者(从服务器),2号服务器依然是领导者(主服务器),没有撼动2号服务器的领导地位。哎~退休了就是退休了,说了不算了,哈哈。
我们会发现,3号服务器启动后依然是跟随者(从服务器),2号服务器依然是领导者(主服务器),没有撼动2号服务器的领导地位。哎~退休了就是退休了,说了不算了,哈哈。
由此我们得出结论,当领导者产生后,再次有新服务器加入集群,不会影响到现任领导者。
zookeeper集群搭建
end