Partial Multi-View Clustering论文笔记
Partial Multi-View Clustering (AAAI2014)
Shao-Yuan Li, Yuan Jiang, Zhi-Hua Zhou
Nanjing University.
论文链接:https://www.aaai.org/ocs/index.php/AAAI/AAAI14/paper/viewFile/8241/8837
1 论文主要贡献
首次提出了一种偏多视图聚类方法(partial multiview clustering),PVC 通过 NMF 构建潜在子空间来工作,在该潜在子空间中,不同视图中与同一 example 相对应的 instances 彼此靠近,并且同一视图中的相似 instances(属于不同 examples)应进行合理分组。在两视图数据上进行的实验证明了 PVC 方法的优势。
2 论文主要内容
2.1 Introduction
多视图聚类旨在将 X i X_i Xi聚类到其相应的族群 y i y_i yi中,聚类的数目通常是预先确定的。请注意,在 multi-view clustering 中,每个视图都具有相同的特征,并利用了“feature grouping” 信息。这使得它与 multi-dimensional clustering 显著不同,在多维聚类中每个维度都是单个功能。
多视图聚类可以粗略地分为两类:
• Spectral approaches:借助一些相似性度量对单视图频谱聚类方法的扩展;
• Subspace approaches:尝试在多个视图之间学习潜在子空间。
值得注意的是,先前对多视图聚类的研究都假定所有的样本的视图信息都是完整的,或者至少有一个视图包含所有的样本。但是,在实际任务中,通常每个视图都有一些缺失的信息,这导致了很多局部样本(偏样本)。如果直接将现有的多视图聚类方法应用到 Partial MultiView 上,无非有两种方法:1) 丢弃视图缺失的样本;2) 对缺失的信息进行预补全。方法 1) 违背了聚类的初衷,方法 2) 会引入较大的的误差。
基于以上讨论,PVC 应运而生。
2.2 Related Work
A. Co-training
协同训练是多视图半监督学习中最著名的代表。它从一个视图构造两个学习者(learners), 然后让他们为另一个学习者提供伪标签。一些研究表明,这种基于分歧的(disagreement-based) 方法实际上并不需要多种视图,而且学习者(learners)之间的差异才是真正的本质。然而,通过适当的多视图研究,即使是带有单个标签的示例,半监督学习也被证明是可行的。在许多具体研究中利用来自多个来源的信息,例如主动学习,多任务学习,多实例学习等。
B. Spectral approaches
借助示例之间的一些相似性度量,频谱聚类(von Luxburg 2007)已扩展到多视图数据。 deSa(2005)构造了部分相似度图,并基于最小化-分歧观点提出了它们的频谱聚类算法。 Zhou and Burges(2007)定义了马尔可夫链的混合 在每个视图的相似度图上进行归纳,并将频谱聚类推广到多个视图。 Kumar 和 Daume(2011)提出了一种协同训练方法,其中一个视图的相似性矩阵受另一视图的频谱嵌入约束。 Kumar 等(2011 年)进一步提出了两种共同约束方法,以加强不同视图之间的聚类假设,使 multiview 彼此一致。
C. Subspace approaches
假设从一个公共子空间生成多个视图,则子空间方法旨在学习一个潜在的固有子空间, 对于相似的示例,每个视图中实例的表示都接近。通过找到两个设定变量的两个投影,以使它们在投影空间中的相关性最大化,CCA 是应用于两个视图数据的最早技术之一。将每个视图视为共享的潜在表示和视图特定部分的线性组合,提出了几种方法。Salzmann(2010) 引入了视图私有部分的正交约束以惩罚视图之间的冗余;White(2012)和 Guo(2013)将子空间学习公式转化为具有稀疏范数正则化的凸优化问题。作为基于单视图潜在子空间的聚 类中最有效的技术之一,非负矩阵分解(NMF)( Lee 和 Seung 1999)最近被多视图学习所利用(Greene 和 Cunningham 2009; Akata,Thurau 和 Bauckhage 2011; Liu 等人 2013),表现良好。
2.3 PVC
个数为 c c c 的在两个视图中都出现的样本: X ^ ( 1 , 2 ) = [ ( x 1 1 , x 1 2 ) ; . . . ; ( x c 1 , x c 2 ) ] ∈ R c ∗ ( d 1 + d 2 ) \hat{X}^{(1,2)}=[(x_1^1,x_1^2);...;(x_c^1,x_c^2)]\in\R^{c*(d_1+d_2)} X^(1,2)=[(x11,x12);...;(xc1,xc2)]∈Rc∗(d1+d2);
个数为 m m m 的仅在第一个视图中出现的样本: X ^ ( 1 ) = [ x ( c + 1 ) 1 ; . . . ; x ( c + m ) 1 ] ∈ R m ∗ d 1 \hat{X}^{(1)}=[x_{(c+1)}^1;...;x_{(c+m)}^1]\in\R^{m*d_1} X^(1)=[x(c+1)1;...;x(c+m)1]∈Rm∗d1;
个数为 n n n 的仅在第二个视图中出现的样本: X ^ ( 2 ) = [ x ( c + m + 1 ) 2 ; . . . ; x ( c + m + n ) 2 ] ∈ R n ∗ d 2 \hat{X}^{(2)}=[x_{(c+m+1)}^2;...;x_{(c+m+n)}^2]\in\R^{n*d_2} X^(2)=[x(c+m+1)2;...;x(c+m+n)2]∈Rn∗d2. 样本总数 N = c + m + n . N=c+m+n. N=c+m+n. 为方便后续子空间的学习,将数据统一用 view 的角度来表示: X ^ ( 1 , 2 ) = [ X c 1 ; X c 2 ] , X c 1 ∈ R c ∗ d 1 , X c 2 ∈ R c ∗ d 2 \hat{X}^{(1,2)}=[X_c^1;X_c^2],X_c^1\in\R^{c*d_1},X_c^2\in\R^{c*d_2} X^(1,2)=[Xc1;Xc2],Xc1∈Rc∗d1,Xc2∈Rc∗d2;同一视图的数据统一起来: X ˉ ( 1 ) = [ X c 1 ; X ^ ( 1 ) ] ∈ R ( c + m ) ∗ d 1 ; X ˉ ( 2 ) = [ X c 2 ; X ^ ( 2 ) ] ∈ R ( c + n ) ∗ d 2 \bar{X}^{(1)}=[X_c^1;\hat{X}^{(1)}]\in\R^{(c+m)*d_1};\bar{X}^{(2)}=[X_c^2;\hat{X}^{(2)}]\in\R^{(c+n)*d_2} Xˉ(1)=[Xc1;X^(1)]∈R(c+m)∗d1;Xˉ(2)=[Xc2;X^(2)]∈R(c+n)∗d2;利用 NMF 得到初步的目标函数:
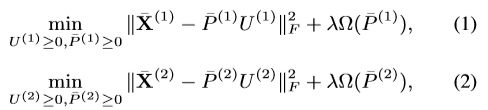
其中, U ( 1 ) ∈ R t ∗ d 1 , U ( 2 ) ∈ R t ∗ d 2 U^{(1)}\in\R^{t*d_1},U^{(2)}\in\R^{t*d_2} U(1)∈Rt∗d1,U(2)∈Rt∗d2是每个视图潜在子空间基础矩阵, P ˉ ( 1 ) = [ P c 1 ; P ^ ( 1 ) ] ∈ R ( c + m ) ∗ t ; P ˉ ( 2 ) = [ P c 2 ; P ^ ( 2 ) ] ∈ R ( c + n ) ∗ t \bar{P}^{(1)}=[P_c^1;\hat{P}^{(1)}]\in\R^{(c+m)*t};\bar{P}^{(2)}=[P_c^2;\hat{P}^{(2)}]\in\R^{(c+n)*t} Pˉ(1)=[Pc1;P^(1)]∈R(c+m)∗t;Pˉ(2)=[Pc2;P^(2)]∈R(c+n)∗t 是每个实例在潜在子空间中的表达,到目前为止,对于每个视图,潜在空间的学习都是独立的。。对于 partial views 设置,在两个 、视图中可用的示例 X c 1 , X c 2 X_c^1,X_c^2 Xc1,Xc2 它们的潜在表示形式 P c 1 , P c 2 P_c^1,P_c^2 Pc1,Pc2 也应接近。通过强制 P c 1 = P c 2 = P c P_c^1=P_c^2=P_c Pc1=Pc2=Pc将此思想与 Eq(1),Eq(2) 相结合,有以下最小化问题:

其中, P ˉ ( 1 ) = [ P c 1 ; P ^ ( 1 ) ] ∈ R ( c + m ) ∗ t ; P ˉ ( 2 ) = [ P c 2 ; P ^ ( 2 ) ] ∈ R ( c + n ) ∗ t \bar{P}^{(1)}=[P_c^1;\hat{P}^{(1)}]\in\R^{(c+m)*t};\bar{P}^{(2)}=[P_c^2;\hat{P}^{(2)}]\in\R^{(c+n)*t} Pˉ(1)=[Pc1;P^(1)]∈R(c+m)∗t;Pˉ(2)=[Pc2;P^(2)]∈R(c+n)∗t 是每个实例在潜在子空间中的表达, P = [ P c ; P ^ ( 1 ) ; P ^ ( 2 ) ] ∈ R ( c + m + n ) ∗ t P=[P_c;\hat{P}^{(1)};\hat{P}^{(2)}]\in\R^{(c+m+n)*t} P=[Pc;P^(1);P^(2)]∈R(c+m+n)∗t为所有 example 的潜在表示。Eq(3) 与传统的多视图聚类相比,传统的 multiview clustering 要求 P ˉ ( 1 ) = P ˉ ( 2 ) \bar{P}^{(1)}=\bar{P}^{(2)} Pˉ(1)=Pˉ(2),或者不要求 P ˉ ( 1 ) \bar{P}^{(1)} Pˉ(1) 与 P ˉ ( 2 ) \bar{P}^{(2)} Pˉ(2)部分相同;Eq(3)中, P ˉ ( 1 ) \bar{P}^{(1)} Pˉ(1) 与 P ˉ ( 2 ) \bar{P}^{(2)} Pˉ(2) 共享 P c P_c Pc 同时包含各自的 P ^ ( 1 ) ; P ^ ( 2 ) \hat{P}^{(1)};\hat{P}^{(2)} P^(1);P^(2). 。 U ( 1 ) U^{(1)} U(1) 与 U ( 2 ) U^{(2)} U(2) 通过 P c P_c Pc 联系起来。Lasso 是文本分析中最常用的正则化之一。
Optimization Strategy: 固定 P P P 优化 U U U 或者固定 U U U 优化 P P P 都是凸的,但是同时优化 P P P 和 U U U 是非凸的,所以使用交替迭代优化方法。优化阶段值得注意的是对潜在子空间 U ( 1 ) ; U ( 2 ) U^{(1)};U^{(2)} U(1);U(2) 的初始化,本文并没有采用随机初始化,而是利用在第一个视图和第二个视图中都出现的样本 X ^ ( 1 , 2 ) = [ X c 1 ; X c 2 ] \hat{X}^{(1,2)}=[X_c^1;X_c^2] X^(1,2)=[Xc1;Xc2],并使用传统 multiview clustering NMF 学习出来的,即

2.4 实验设置
Data Sets

四个数据集中都包含两个视图:content and citation
partial examples 设置:1) m > 0 m>0 m>0 同时 n > 0 n>0 n>0 表示两个视图中都有缺失的网页信息;2) m = 0 m=0 m=0 或者 n = 0 n=0 n=0,即至少一个视图(content 视图或 citation 视图)不会丢失任何信息,即“complete view”.
Baseline
CCA: use CCA kernel and k-means.
ConvexSub: The subspace-based multi-view clustering method developed by (Guo 2013).
MinDisSC: The multi-view spectral clustering method developed by (de Sa 2005).
CentroidSC: The centroid multi-view spectral method developed by (Kumar, Rai, and Daume 2011).
PairwiseSC: The pairwise multi-view spectral clustering method developed by (Kumar, Rai, and Daume 2011).
Evaluation
The normalized mutual information (NMI ↑ ↑ ↑).