HDFS HA(HDFS高可用QJM方式)
HDFS HA(HDFS高可用QJM方式)
HDFS中NameNode用于存储元数据信息,元数据信息包括了文件名称、文件路径、文件的所有者、文件的所属组、文件的权限、文件的副本数等等等。这样NameNode会存在单点瓶颈问题。
此外考虑到NameNode有的时候需要进行集群内服务器升级、NameNode宕机等动态因素,一种
HA机制迫切需要!
HA机制(
不需要SecondaryNameNode,将合并工作交给standby的NameNode去做
)
问题分析:
之前使用的NameNode和SecondaryNameNode的架构虽然能够通过更新元数据保证元数据的高可靠性,但是
由于只有一台NameNode对客户端提供服务,那么,在遇到该NameNode宕机时,客户端的请求到来的时候就不能够做出响应,不能够保证高可用性。
解决思路:
提供两台NameNode进行响应客户端请求的任务。
但是这样的话存在以下问题:
首先:两台NameNode,由于NameNode需要及时更新元数据,两台NameNode的话都会往元数据里面添加信息,那么如何保证这两台NameNode能够正常响应客户端的请求?
-------应该保证在同一时间段内,只有一台NameNode对外提供响应服务,可以通过状态位进行标志,
只有状态为active的NameNode节点能够响应。而另外一台NameNode状态为standby,两台NameNode的功能完全相同。
然后:如果状态为active的NameNode宕机,应该如何让状态为standby的节点迅速无缝的切换成active的NameNode节点?
-------必须保证两个NameNode之间的元数据信息时刻保持一致(同步)。
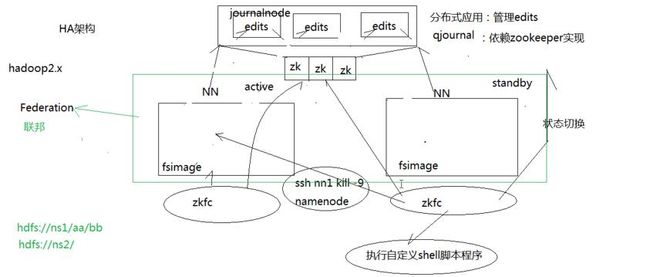
HA架构就是解决上面的问题:
将两个NameNode节点的edits通过JournalNode守护进程进行同步,客户端进行访问写操作更新的edits在独立的集群上面,该框架是基于zookeeper实现的,保证edits的实时同步性,状态为active的NameNode向其中写edits,而状态为standby的NameNode从中读取,状态为standby的NameNode会定期从集群上更新edits文件,然后把edits文件和fsimage文件合并成一个新的fsimage,合并完成之后会通知active NameNode获取这个新的fsimage,从而状态为active的namenode会替换掉旧的fsimage,启动了HA之后,
SecondaryNameNode、checkpointnode这些就都不需要了
。
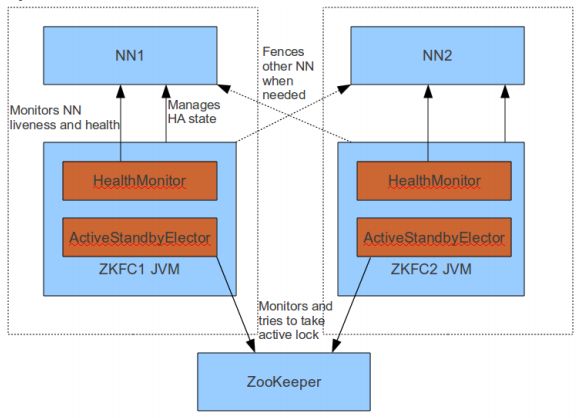
同时,两个NameNode会分别起进程zkfc,用于监听,做
两个NameNode之间的状态切换,状态为active的NameNode会经常往zookeeper写一些数据,zkfc监听这些数据,状态为standby的NameNode读取到这些数据。当状态为active的NameNode宕机,状态为standby的NameNode会知道,这个时候它会切换自己的状态为active。
对于DataNode,需要向状态为active和standby的NameNode发送心跳和块报告!即NN中要时刻保持文件系统和元数据的一致和同步。
但是,如果状态为active的NameNode是假死的话,也就是说它过一会又活了,专业术语即
“脑裂”这个时候集群中会又会出现两个NameNode,这显然是不行的。解决办法是,之前状态为standby的nameNode不会立即进行切换,而是
通过zkfc进程向状态为active的NameNode发送kill指令,杀掉其NameNode进程,状态为standby的NameNode收到了杀掉成功的响应后,会进行状态的切换。然而还是会有一些问题,假如网络出现问题,状态为standby的NameNode发送的kill指令发不过去或者接收不到响应,这个时候zkfc还提供了相应的解决方案,它
会执行一段自定义的shell脚本程序,该程序是由人员进行定义,这就比较自主,可以通过脚本关闭状态为active的NameNode的电源等。
此外,两个NameNode构成一个Federation(联邦)
总结一下配置HA的主要几个点:
①配置edits,通过JournalNode守护进程进行相关NameNode之间的数据共享。
两个NameNode为了数据同步,会通过一组称作JournalNodes的独立进程进行相互通信。当active状态的NameNode的命名空间有任何修改时,会告知大部分的JournalNodes进程。
②配置NameNode(active和standby)
③配置客户端的代理proxy,目的是在客户端发送请求的时候可以通过proxy找到状态为active的NameNode进行发送。
④NameNode之间的隔离:保证同一时刻仅仅有一个NameNode对外提供服务。
实践:
首先配置hdfs-site.xml文件
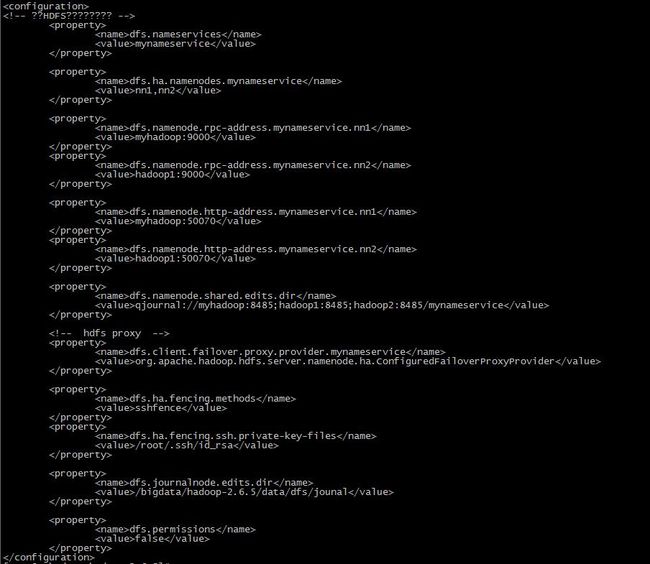
具体每一步代表什么意思可以参照官方文档
http://hadoop.apache.org/docs/r2.6.5/hadoop-project-dist/hadoop-hdfs/HDFSHighAvailabilityWithQJM.html
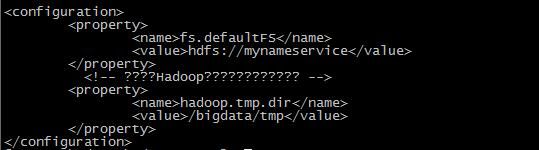
可见,将配置HA之前的fs.defaultFS的内容由之前的具体namenode的ip和端口改为HA中多个namenode组成的命名服务。在hdfs执行任务的时候会先到这里找到位置,然后在hdfs-site.xml中通过代理进一步寻找。
最后配置slaves文件,添加相应的DataNode的名称。注意在这之前要可以实现SSH免密登录~~~~
启动(没有配置ZK,需要手动使用命令进行切换):
应该在journalnode节点上先启动journalnode服务
然后在配置的nn1节点(这里是myhadoop节点)上对namenode进行格式化
并启动namenode服务:
然后在nn2(这里就是hadoop1节点)同步nn1的元数据信息:
再启动nn2节点的namenode:
再启动各个datanode
这样启动多个namenode,初始状态都是standby
最后将namenode状态进行切换:
这样就保证了nn1是处于Active状态。
在这里有一个坑。就是在进行状态切换的时候,会报错!
Incompatible namespaceID for journal Storage Directory /root/hadoop/hdfs/journal/hadoop-test: NameNode has nsId 229502726 but storage has nsId 1994970436
这主要是由于多次格式化namenode之后,导致的版本不一致问题。解决方案是将namenode的文件目录包括tmp/dfs/*以及logs/*删除后,然后重启集群即可!
启动(
配置ZKFC--即就是zookpper的客户端--zookpper故障转移控制器,真正实现高可用
):
由于启动namenode之后的初始状态都是standby,故首先需要zookpper选举一个leader作为active状态的namenode;
此外还额外的需要一个守护进程监控namenode的状态,这个守护进程就是ZKFC
具体配置如下:
在hdfs-site.xml中加上如下配置(目的是启动自动故障转移服务)

在core-site.xml中配置zookpper的主机和端口

启动zookpper集群的各个节点
然后初始化HA在zookpper集群中的状态--使用的命令:bin/hdfs zkfc -formatZK
然后启动hdfs文件系统!
经测试,人为的挂掉状态为active的namenode节点后,之前状态为standby的namenode节点会自动补上!
FAQ:很恼火的是,第一次启动起来后,挂掉状态为active的节点,状态并没有进行切换,查看日志得知是SSH的问题。百度后,感觉应该是jsch的jar包版本太低所致,修改jar包版本后,重新启动,然后测试还是不行;继续查看日志,才恍然大悟,原来是秘钥复制错误所致,应该是/root/.ssh/dsa而不是/root/.ssh/rsa