Centos学习中遇到的的指令
Linux命令查询网站:https://www.linuxcool.com/。
1、删除文件或目录
- 强制删除目录:rm -rf 目录名(r参数表示递归处理文件,对应的英文是recursive,f参数表示强制意思,对应英文是force)。
- 删除一个空目录:rmdir 目录名(只能删除空目录)。
- 递归删除空目录:rmdir -p X1/X2/X3(X3必须是空目录,X2目录只能包含X3,X1只能包含X2)。
- 删除某个文件的时候询问是否删除该文件:rm -i 文件名。
- 使用统配符批量删除文件:rm -i 前缀*。
- 删除当前目录中第一个字符是“-”的文件:rm ./-文件名。
2、列出目录中的内容
- 显示目录中所有的文件和子目录:ls(ls是list的缩写)。
- 显示目录中所有的文件和子目录,且一行显示一条文件或子目录的详细信息:ls -l(其实ls -l命令等同于ll,即两个L的小写)。
- 显示目录中所有的文件和子目录包括带“.”开头的文件:ls -a。
- 显示目录中所有的文件和子目录包括带“.”开头的文件,且一行显示一条文件或子目录的详细信息:ls -al(显示的信息从左到右依次是权限、链接、拥有者、用户组、文件容量、修改日期和文件名)。
- 显示目录中所有的文件和子目录,并且文件或目录的日期是完整的格式:ls -l --full-time。
- 不显示文件或目录颜色,但显示出文件名代表的类型:ls -alF --color=never(-F表示根据文件、目录等信息,给予附加数据结构,*代表可执行文件,/代表目录,=代表socket文件,l代表FIFO文件)。
- 显示文件inode的号码:ls -i。
- 显示文件的建立时间:ls -l --time=mtime 文件名(由于默认的时间显示就是文件的建立时间,所以没有–time选项也是可以的)。
- 显示文件被读取内容的时间:ls -l --time=atime 文件名。
- 显示文件更新状态的时间(比如权限被修改,文件被创立):ls -l --time=ctime 文件名。
- 查看文件的inode号码:ls -i(-i选项表示显示文件inode号码)。
- 查看目录文件:ls -d(-d选项是显示所有的目录文件)。
- 查看自己安装的Linux支持的文件系统有哪些:ll /lib/modules/$(uname -r)/kernel/fs。
- 查看已经加在到内存中支持的文件系统:cat /proc/filesystems。
- 显示目录中所有的文件,并且所有的文件按照容量从小到大的顺序排序:ls -Sr 目录名(-r, --reverse,逆序排列目录内容。-S, --sort=size,按文件大小而不是字典序排序目录内容,大文件靠前)。
- 显示目录中所有的文件,并且将文件占用的区块容量和文件本身的大小显示出来:ls -lsh。
如下图所示。

上图第一行显示的总用量表示的就是所有文件使用的区块总大小。下面每一个文件的第一个选项就是该文件占用的区块数。可以看到虽然两个文件的大小加起来只有4.4K,但是他们占用的区块总大小却有8K,因此剩下的没有利用的部分空间就浪费掉了。 - 查看文件的基本信息,并显示安全上下文的内容:ls -Z(-Z选项可以将文件资源的SELinux的安全上下文的内容显示出来)。
如下图所示。

上图中用户组与文件名之间的内容就是安全上下文的内容。前两个冒号将其分隔成了三个字段,第一个字段表示身份识别【Identify】,第二个字段表示角色【role】,这两个不是很重要,最重要的是第三个字段,类型【type】,一个主体进程能否读取一个文件资源与这个类型字段有关。
3、显示时间
- 显示当前日期与时间:date。
- 以“2015/05/29”的格式输出时间:date +%Y/%m/%d。
- 以“14:33”的格式输出时分信息:date +%H:%M。
- 显示日历:cal。
- 显示2020年所有的日历:cal 2020。
- 显示2020年12月的日历:cal 12 2020。
4、查看字符集的方法
- 查看命令结果输出的字符集:locale(从某种意义上来说locale不能算是命令)。
如下图所示。
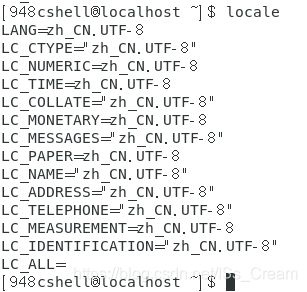
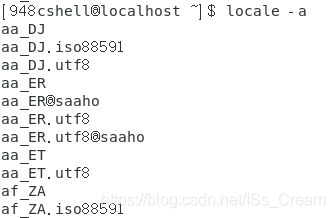
- 查看Linux支持的所有的语系:locale -a。
如下图所示。未截全图。
5、简单的计算器
- 使用简单的计算器:bc。
bc计算器作除法如果不配置的话会进行去整操作,不会输出小数。可以在计算其中设置“scale=number”来设置保留小数点的位数,如下图。

6、查找文件或目录
- 查找当前目录下所有文件及目录名称:find。
- 将系统中某个目录下24小时以内有修改过内容的文件列出来:find 目录名 -mtime 0(-mtime选项代表文件内容被修改的时间,后面要跟一个时间参数,0代表从当前时间到24小时之前的时间段)
- 寻找某目录下所有比某个文件的日期更新的文件:find 目录名 -newer 文件名(-newer选项后面要跟一个文件名作为参数,表示列出某个目录下所有比该文件更新的文件)。
- 寻列出某个目录下属于某个用户的所有文件:find 目录名 -user 用户名(-user选项后面要接参数用户名)。
- 寻找某个目录下不属于任何用户的文件:find 目录名 -nouser(-nouser选项表示没有用户的意思)。
- 找出某个目录下的特定文件名的文件:find 目录名 -name 文件名(-name选项后面要跟参数文件名,表示要查询的文件名)。
- 找出某个目录下的包含某个关键字的文件:find 目录名 -name " * 关键字 * "(-name选项后面要跟一个包含统配符的字符串)。
- 找出某个目录下文件类型为socket的文件:find 目录名 -type s(-type选项后面跟一个参数s表示的是socket文件类型,也可以接d表示目录,l表示链接文件等)。
- 找出某个目录下满足某个中权限的所有文件:find 目录名 -perm 参数(-perm选项后面的参数接数字参数)。
- 找出某个目录下大于一定大小的所有文件:find 目录名 -size +规格(-size选项后面的规格要以数字加上c、k等,c表示B,k表示1024B)。
- 找出某个目录下小于一定大小的所有文件:find 目录名 -size -规格(-size选项后面的规格要以数字加上c、k等,c表示B,k表示1024B)。
7、在线查询命令
- 查询某个命令的说明文档:man 命令名。
- 查询所有与某个命令有关的说明文档:man -f 命令名。
- 通过说明文档中的关键字查询相关命令的说明文档:man -k 命令名。
8、创建目录
- 创建一个目录:mkdir 目录名(创建出来的目录会采用默认权限umask)。
- 递归创建多层目录:mkdir -p XX/XX/XX/XX。
- 创建目录时指定权限:mkdir -m 数字权限或文字权限 目录名。
9、查询用户
- 查看目前正在使用计算机的用户:who 或者 w。
命令【who】如下图所示。

命令【w】如下图所示。

上图中第一行中的第一栏显示的是目前的时间,up后面的数字是已经启动机器多久的时间。 - 产看目前正在以什么身份使用系统:whoami。
如下图所示。

10、查看网络联网状态
- 查看网络联网状态:netstat -a。
11、查看后台执行的程序
- 查看后台执行的程序:ps aux。
12、关机
- 关机:shutdown。
- 立刻关机:shutdown -h now。
- 在20:25分关机:shutdown -h 20:25。
- 在十分钟之后关机:shutdown -h +10。
- 立刻重新开机:shutdown -r now。
- 30分钟后重启并显示警告信息:shutdown -r +30 ‘The system will reboot’
关机:poweroff。
13、用户帐号管理
-
创建一个新用户:adduser 用户名。
-
完全参考默认值创建一个新目录:useradd 用户名。
效果如下图所示。
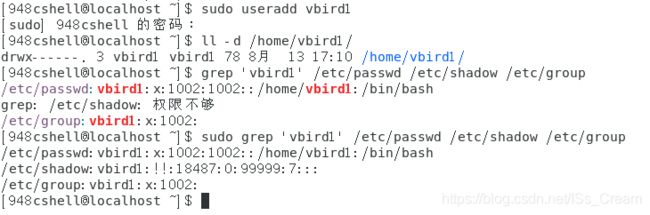
上图中默认建立用户的家目录为【/home/用户名】,权限是700,该用户登陆时使用的shell为bash,并且会创建一个与该用户名相同的用户组。 -
创建一个指定UID和初始用户组的用户:useradd -u 未使用UID -g 已经存在的用户组 用户名(-u选项后面跟一个未使用的UID作为新用户的UID,-g选项后面跟一个已经存在的用户组作为新用户的初始用户组)。
如下图例子所示。
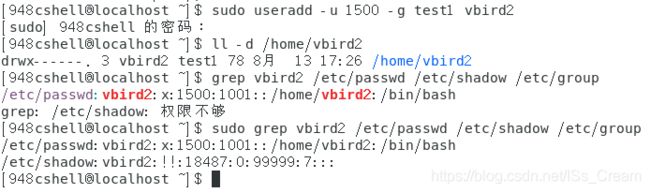 从上图中可以看出UID和初始用户组被设置成指定的值,由于初始用户组被指定,所以系统没有自动创建一个同名用户组。
从上图中可以看出UID和初始用户组被设置成指定的值,由于初始用户组被指定,所以系统没有自动创建一个同名用户组。 -
创建一个指定家目录的新用户:useradd -d /home/用户名 用户名(-d选项后面跟上一个目录,是家目录路径)
-
创建一个系统帐号:useradd -r 用户名(-r选项表示创建的帐号是一个系统帐号)
例子如下图所示。

上图中可以看出系统帐号的UID和初始用户组GID都是小于1000的,由于系统帐号是用来执行系统所需服务的权限设置,所以系统帐号默认都不会主动建立家目录。 -
查看useradd命令创建新用户时使用的默认值:useradd -D。
效果图如下。
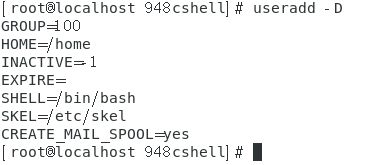
这些数据记录在目录【/etc/default/useradd】中。 -
给用户的帐号添加说明信息:usermod -c “说明信息” 用户名(-c选项可以修改用户在/etc/passwd文件中第5栏的说明信息)。
如下图所示。

-
设置用户的帐号在某个日期(YYYY-MM-DD)后失效:usermod -e “YYYY-MM-DD” 用户名(-e选项可以修改/etc/shadow文件第8栏的信息)。
效果图如下。

-
删除已经创建的一个用户:userdel -r 用户名(-r选项表示连同家目录也一并删除)
-
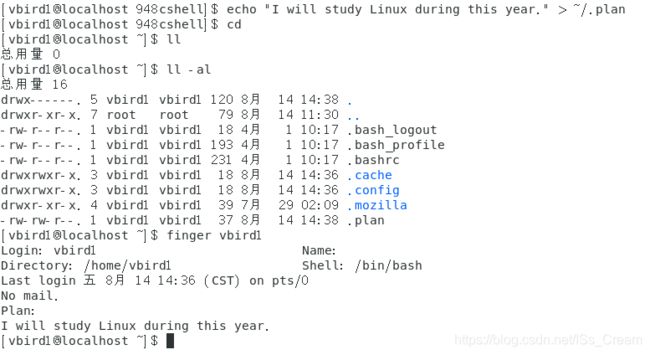
显示某个用户的帐号属性:finger 用户名。
效果如下图所示。

上图中倒数第二栏的mail是读取的文件【/var/spool/mail】中的邮件数据。
上图中的最后一栏中的Plan,是finger命令读取的文件【~/.plan】中的内容,用户可以把自己想写入的东西写入该文件,之后finger会将内容读出来。效果如下图所示。
-
显示目前在系统上登陆的使用者与登陆时间:finger。
如下图所示。

-
某个用户修改自己的相关信息,比如全名,办公室号码,办公室电话,家里电话等:chfn 用户名。
效果如下所示。

上图中可以看到这些和用户的相关信息被写入到文件【/etc/passwd】的第五栏说明信息中,并且用逗号进行分隔。
之后在使用命令【finger 用户名】可以看到更全用户相关信息。如下图。
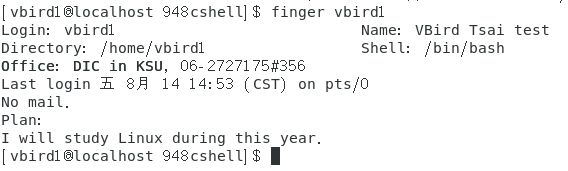
14、更改用户密码
- root权限下更改用户密码:passwd 用户名。
- 用户登陆后更改自己的密码:passwd。
- 将前一个命令的标准输出作为标准输入设置密码:echo ‘密码’ | passwd --stdin 用户名。
首先passwd中的–stdin选项不一定所有的Linux发行版有,这个命令安全性不是很好,可以通过查看历史信息的文档查找到密码,主要是用在脚本中批量创建帐号时使用。
效果图如下。

- 显示出某个用户密码的相关参数:passwd -S 用户名(-S选项表示显示出某个用户密码的相关参数)
效果图如下。
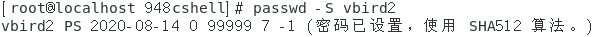
上图中的【2020-08-14】表示最近一次修改密码的时间,【0】这一栏表示更改一次密码后不可修改密码的天数,【99999】这一栏表示多少天之后必须修改密码,【7】这一栏表示密码过期的前多少天显示提示信息,【-1】这一栏表示密码多少天之后失效。 - 让某个用户帐号失效:passwd -l 用户名(-l选项表示lock,将帐号上锁)。
效果图如下。
- 让失效的用户帐号有效:passwd -u 用户名(-u表示unlock,解锁的意思)。
效果图如下。

- 显示出某个用户详细的密码参数:chage -l 用户名(-l选项表示列出帐号的详细密码参数)。
效果图如下所示。

- 让一个新建立的用户在第一次登陆时强制修改密码:chage -d 0 用户名(-d选项是修改shadow文件第三栏的信息,即最近一次修改密码的日期,后面的0表示的日期是1970/1/1)。
我也不时很明白为什么-d选项后面跟0可以强制修改密码。
该功能最常用在学校给学生批量创建帐号,学生用原始密码登陆之后,可以修改密码。
效果图如下所示。

15、对用户组的相关操作
- 创建一个新的用户组:groupadd 用户组名。
如下图所示。

- 修改某个用户组的名称为指定字符串,GID为指定数值:groupmod -g 指定GID -n 指定用户组名 原用户组名(-g后面跟指定的GID,-n后面跟指定的用户组名)。
如下图所示。

- 删除某个用户组:groupdel 用户组名。
如下图所示。

有的用户组不能删除的原因在于该用户组是其他用户的初始用户组。如果硬要将这个用户组删除需要修改该用户组对应的用户的初始用户组,或者将这个用户删除。 - 给某个用户组创建一个密码:gpasswd 用户组名。
如下图所示。

上图中输入两次相同的密码就行。 - 给含有密码的用户组分配一个用户组管理员:gpasswd -A 用户名 含有密码的用户组名(-A选项后面跟的用户名为分配给用户组的用户组管理员)
如下图所示。

- 用户组管理员将用户添加到自己管理的用户组中:gpasswd -a 用户名 自己管理的用户组名(-a选项是添加用户进入自己管理的用户组,-d选项是将自己管理的用户组中删除用户)。
如下图所示。

上图可以看出一开始vbird1用户并没有进入用户组testgroup。
16、将用户添加到用户组中
- 将一个用户追加到一个用户组中:usermod -a -G 用户组名 用户名(一定要有-a选项,表示append的意思,如果没有会将该用户原来所在的用户组清除,再加到新的用户组,有-a选项就是追加,-G选项表示将用户添加到用户组的列表)。
17、修改文件/目录所属的组
- 修改文件所属的组:chgrp 用户组名 文件名(chgrp是change group的缩写)。
- 修改目录所属的组:chgrp -R 用户组名 目录名(-R选项表示递归处理的意思)。
- 使用命令chown修改文件或目录所属用户的同时顺便可以修改所属用户组:chown 用户名:用户组名 文件名或-R 目录名。
- 使用命令chown修改文件或目录所属用户的同时顺便可以修改所属用户组:chown 用户名.用户组名 文件名或-R 目录名。
- 使用命令chown可以直接修改所属用户组:chown .用户组名 文件名或-R 目录名。
- 使用命令chown可以直接修改所属用户组:chown :用户组名 文件名或-R 目录名。
18、修改文件拥有者
- 修改某个文件的所属用户:chown 用户名 文件名 (chown是change owner的缩写)
- 修改某个目录的所属用户:chown 用户名 -R 目录名 (chown是change owner的缩写)
- 使用命令chown修改文件或目录所属用户的同时顺便可以修改所属用户组:chown 用户名:用户组名 文件名或-R 目录名。
- 使用命令chown修改文件或目录所属用户的同时顺便可以修改所属用户组:chown 用户名.用户组名 文件名或-R 目录名。
19、复制文件或目录
- 将文件复制一份到某个目录并重新命名:cp XX1/XX2/旧文件名 XX1/XX2/新文件名。
- 将文件复制一份到某个目录并重新命名,并在有同名文件时提示是否进行覆盖:cp -i XX1/XX2/旧文件名 XX1/XX2/新文件名。
- 将文件复制一份到当前目录:cp XX1/XX2/旧文件名 . 。
- 将文件复制到某一目录并重命名,且保留文件的所有信息,包括权限,修改时间:cp -a XX1/XX2/旧文件名 XX1/XX2/新文件名。
- 创建某个文件的符号链接:cp -s X1/文件名 X2/链接文件名(创建的符号链接又称为软链接或者快捷方式)。
- 创建某个文件的硬链接:cp -l X1/文件名 X2/链接文件名。
- 复制多个文件到同一个目录:cp 文件名1 文件名2 … 目录(最后一个是目录即可)。
- 复制某个目录到某个目录中:cp -a 目录名 X1/X2/目录名 或者 cp -r 目录名 X1/X2/目录名 (-a选项包括选项dpr,-r选项表示递归的意思)。
- 复制某个符号链接文件到某个目录中:cp -a 目录名 X1/X2/目录名 或者 cp -d 目录名 X1/X2/目录名 (-a选项包括选项dpr,-d选项表示当复制符号连接时,把目标文件或目录也建立为符号连接,并指向与源文件或目录连接的原始文件或目录)。
- 复制某个文件到某个目录中,并且属性和原文件相同:cp -a 文件名 X1/X2/目录名 或者 cp -p 文件名 X1/X2/目录名 (-a选项包括选项dpr,-p选项表示保留源文件或目录的属性)。
20、修改文件/目录权限
- 使用数字进行权限的修改:chmod 数字 文件名或-R 目录名(chmod是change mod 的缩写。读对应的数字是4,写对应的是2,执行对应的是1,那么一个身份(用户、用户组、其他人)的权限就是三者累和,比如如果读写执行三种权限都有就是4+2+1=7,如果三种身份的读写执行三种权限都有,那么命令中的数字就应该是777)
- 使用符号进行权限的修改:chmod u=rwx,g=rwx,o=rwx 文件名 或 -R 目录名(u表示user,即用户,g表示group,即用户组,o表示others,即其他人,“=”表示设置的意思) 或者 chmod o-r 文件名 或 -R 目录名(表示让使用该文件或者目录的其他人失去读权限)
21、创建一个空文件
- 命令touch的功能是改变文件或目录的时间,但是如果什么选项都不选直接跟文件名可以直接创建一个空的文件:touch 文件名(touch命令后面如果跟文件名,那么三个变动时间,即atime/ctime/mtime都会被更新成目前的时间)。
- 如何将文件的读取时间和修改时间回退两天:touch -d “2 days ago” 文件名(-d选项表示自定义文件的读取时间和修改时间,后面接一定格式的日期和时间)。
- 如何将文件的读取时间和修改时间改成2014/06/15 2:02 :touch -t 201406150202 文件名(-t后面接一个自定义的时间,格式为YYYYMMDDhhmm)。
- 使用vi程序编辑器创建一个空文件:/bin/vi 文件名。
由于现在的centos7已经将命令vi自动题换成了命令vim,所以如果想要直接使用命令vi需要加上绝对路径。
22、查看一个文件中的内容
- 读取一个文件的内容到终端上:cat 文件名。
- 读取一个文件的内容到终端上,并显示包括空白行的行号:cat -n 文件名(-n选项表示显示行号且显示空白行的行号) 或者 nl -b a 文件名。
- 读取一个文件的内容到终端上,并显示不包括空白行的行号:cat -b 文件名(-n选项表示显示行号但不显示空白行的行号) 或者 nl 文件名。
- 读取一个文件的内容到终端上,并显示特殊的字符:cat -A 文件名(-A表示显示像Tab、空白、换行等特殊字符的参数)。
- 反向读取一个文件的内容,从内容的最后一行到第一行反向在屏幕上显示出来:tac 文件名。
- 读取一个文件的内容,并且行号在屏幕最左侧,但空白行不加行号:nl -n ln 文件名。
- 读取一个文件的内容,并且行号在自己栏位的最右方,但空白行不加行号:nl -n rn 文件名。
- 读取一个文件的内容,并且行号在自己栏位的最右方,且空白处补0,但空白行不加行号:nl -n rz 文件名。
- 读取一个文件的内容,并且行号在自己栏位的最右方,且空白处补0,空白行也加行号,并且设置前面补0的位数:nl -b a -n rz -w 3 文件名(选项-b后面跟参数a,表示显示行号且显示空白行的行号,如果参数是t则不显示空白行的行号。-n选项表示列出行号的表示方法,后面要跟参数,如果参数是ln,表示行号在屏幕的最左方显示,如果参数是rn,表示行号在自己栏位的最右方显示且不加0,如果参数是rz,行号在自己栏位的最右方显示前方空白补0。-w选项用来指名行号栏占用的字符数目,后面要跟数字参数,如果是3,表示行号占3位)。
- 翻页查看一个文件的内容:more 文件名(会进入more页面,空格表示向下翻一页,回车表示向下翻一行,/字符串表示向下检索字符串,q表示离开more页面,b表示往回翻一页)。
- 翻页查看一个文件的内容:less 文件名(空格表示向下翻一页,上下箭头按键也可以进行翻页,/字符串表示向下检索字符串,?字符串表示向上检索字符串,n表示重复前一次的查找,和/和?有关,q表示离开)。
- 显示某个文件前10行的内容:head 文件名(head命令默认情况下显示文件前10行的内容)
- 显示某个文件前20行的内容:head -n 20 文件名(-n选项后面接一个正数20,表示显示一个文件前20行的内容,如果接一个负数20,表示除了最后20行的内容,其他都显示)
- 除了最后100行不显示,其他内容都显示:head -n -100 文件名。
- 显示某个文件后10行的内容:tail 文件名(tail命令默认情况下输出最后10行)。
- 显示某个文件后20行的内容:tail -n 20 文件名(-n选项后面加上一个没有正号的正数20表示显示后20行数据)。
- 显示从100行以后的内容:tail -n +100 文件名(-n选项后面集上一个带有正号的正数+100可以显示从100行以后的数据)。
- 对于非文本文件使用ASCII的方式进行输出:od -t c 文件名(-t选项后面如果跟参数c表示按照ASCII的方式输出,如果是a表示按照默认字符来输出)。
23、切换目录
-
切换当前所在的目录:cd 相对路径或绝对路径。
-
移动到当前帐号的家目录:cd 或 cd ~。
-
root帐号下移动到某一用户的家目录:cd ~用户名。
如下图所示。

-
回到刚刚使用过的目录:cd -。
24、显示所在的目录
- 显示当前所在的目录:pwd。
- 显示链接文件的真实目录:pwd -P。
25、输出指定字符串或变量的值
- 输出某个shell变量的值:echo $变量名或echo ${变量名}(其中 $表示后面的字符串是一个变量)。
用第二种用的比较多。
如下图所示。

- 输出当前用户使用的bash的PID:echo $$。
如下图所示。

26、将文件移动到一个目录
- 将文件从一个目录移动到另一个目录:mv 文件名 目录名(这里移动的过程分解以一下可以是先将原文件复制一份到新目录,然后将原文件删除)。
- 将一批文件移动到一个目录中:mv 文件名1 … 文件名n 目录名。
27、更改某个文件的文件名
- 更改文件名:mv 旧文件名 新文件名。
28、获取完整文件名中的目录名
- 获取完整文件名中的目录名:dirname 目录名1/目录名2/文件名(必须是完整的文件名,如果只是文件名,没用)。
29、获取完整文件名中的文件名
- 获取完整文件名中的文件名:basename 目录名1/目录名2/文件名。
30、如何查看建立文件或目录是的权限默认值
- 查看建立文件或目录是的权限默认值:umask(显示的四位数字,默认是0022,第一个0是特殊权限,后三个数是一般权限) 或 umask -S(会直接显示一般权限)。
31、如何修改建立文件或目录是的权限默认值
- 修改建立文件或目录是的权限默认值:umask 三位7以内数字。
32、如何设置文件的隐藏属性
- 给一个文件设置隐藏权限i,该文件不能被删除、改名、设置链接以及无法写入和新增数据:chattr +i 文件名。
- 给一个文件取消隐藏权限i,该文件重新可以被删除、改名、设置链接以及无法写入和新增数据:chattr -i 文件名。
33、观察文件的类型
- 查看某个文件的类型:file 文件名。
34、命令与文件的查找
- 查找命令的绝对路径:which 命令名。
- 查找文件的路径:whereis 文件名(whereis命令一般查找系统某些特定目录下的文件)。
- 查找只有在man里面的文件名才显示出来:whereis -m passwd(-m选项表示只有在man里面的文件才能显示出来)。
- 显示whereis查询文件的目录:whereis -l(-l选项表示显示所有的whereis命令查询目录)。
- 显示某个文件前5条查询结果:locate -l 5 文件名。
- 列出locate命令查询所使用的数据库文件的文件名与各数据的数量:locate -S(-S选项表示列出数据库文件的文件名和各种数据的数量)。
35、切换命令行模式下的用户
-
使用non-login shell的方式切换到root用户:su(往往需要输入root密码)。
使用这种方式是以non-login shell的方式登陆root。效果如下图所示。

从上图中可以看出,当前使用的用户的UID是0,也就是root,说明已经成功切换到了root用户。
重点如下图所示。

虽然已经成功切换到了root,可是众多环境变量还是和之前使用的一般用户的环境变量保持一致,因此可以得出结论,使用命令【su】切换到root用户,很多变量还是切换之前的一般用户的,所以还是有很多数据无法被使用。所以建议使用命令【su -】来切换到root用户。如下图所示。

从上图中可以看出,当前用户是root,并且变量也从一般用户的转变成root使用的。 -
使用login shell的方式切换到root用户:su -。
相比于命令【su】,命令【su -】除了会将当前的用户切换到root,还会将一些变量也切换为root用户所使用的。如下图所示。

而如果使用命令【su】,则是如下图所示。

-
以root身份执行一次命令,不切换使用的用户:su - -c “命令”(-c选项后面接命令,该命令会以前面指定的用户身份执行一次,且不切换当前用户)。
如下图所示。

从上图中可以看出,-c选项后面的命令虽然是以root身份执行的,可是并没有切换用户身份,用户还是948cshell。 -
使用login shell方式切换到一般用户:su -l 用户名(需要输入切换的用户的密码)。
使用login shell方式进行登陆,切换的同时会配置好切换后的用户使用的变量。
如下图所示。

-
使用non-login shel方式切换到一般用户:su 用户名(需要输入切换的用户的密码)。
该命令和命令【su】类似,是以non-login的 shell的方式进行登陆的,变量还是之前的用户使用的变量,因此最好是使用命令【su -l 用户名】进行切换。
如下图所示。

36、查看XFS文件系统的描述数据
- 查看XFS文件系统的描述数据:xfs_info 挂载点或者文件设备名。
此命令可以显示如下图内容。
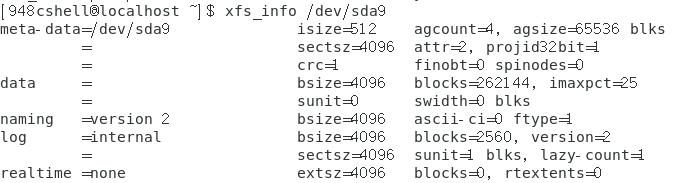
上面输出的信息可以这样解释:- 第 1 行里面的 isize 指的是 inode 的容量,每个有 256Bytes 这么大。至于 agcount 则是 前面谈到的储存区群组 (allocation group) 的个数,共有 4 个, agsize 则是指每个储 存区群组具有 65536 个 block 。配合第 4 行的 block 设置为 4K,因此整个文件系统的容 量应该就是 4655364K 这么大!
- 第 2 行里面 sectsz 指的是逻辑扇区 (sector) 的容量设置为 512Bytes 这么大的意思。
- 第 4 行里面的 bsize 指的是 block 的容量,每个 block 为 4K 的意思,共有 262144 个 block 在这个文件系统内。
- 第 5 行里面的 sunit 与 swidth 与磁盘阵列的 stripe 相关性较高。这部份我们下面格式化 的时候会举一个例子来说明。
- 第 7 行里面的 internal 指的是这个登录区的位置在文件系统内,而不是外部设备的意 思。且占用了 4K * 2560 个 block,总共约 10M 的容量。
-第 9 行里面的 realtime 区域,里面的 extent 容量为 4K。不过目前没有使用。
37、列出文件系统的整体磁盘使用量、查看文件系统的磁盘使用量以及目录所占磁盘空间
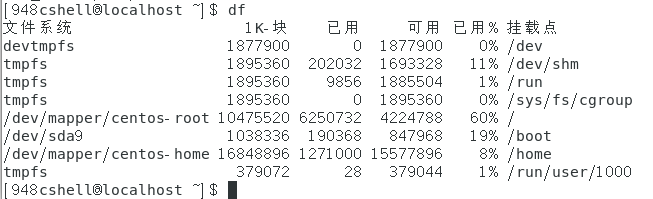
-
将系统内所有的文件系统都列出来:df(在Linux下如果df不加任何参数,默认会将系统内所有的都以1KBytes的容量列出来)。
如下图所示。
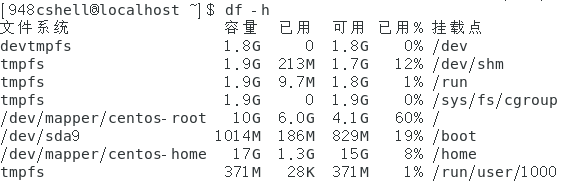
-
将系统内所有的文件系统以易读的格式列出来:df -h。
如下图所示。
-
将系统内所有的文件系统(包括特殊文件)的格式及名称都列出来:df -aT(-a选项列出包括特殊文件在内的所有文件,这些特殊文件几乎都在内存中,不占用磁盘,-T选项则列出文件系统的格式及名称)
如下图所示。

-
将/etc下面的可用的磁盘容量以易读的容量格式显示:df -h /etc。
df后面如果加上目录或者文件时,df会自动分析该目录或者文件的硬盘分区,并将该硬盘分区的容量显示出来,这样可以知道某个目录下还有多少容量可供使用。
命令执行如下图。

-
将各个硬盘分区可用的inode数量显示出来:df -ih。
命令执行如下图。
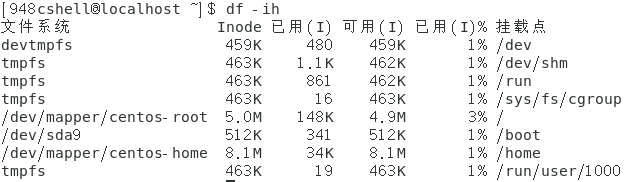
-
以易读的方式显示某个目录的文件系统等信息:df -hT 目录名。
如下图所示。

-
列出当前目录下所有目录的容量:du(直接输入du而不加任何选项时,du默认会分析当前目录下所有目录的容量,而不分析文件的容量,输出的数据单位是1KBytes)。
执行的效果如下图所示(部分截图)。

-
列出当前目录下所有目录及文件的容量(数据单位是1KBytes):du -a。
和命令(du)类似,只是增加了文件。 -
检查根目录下每个目录所占用的容量:du -sm /*(-s选项只会显示目录的总容量而不会详细的显示该目录下的每个文件的容量,比如上面的命令只会显示/usr的总量而不会显示/usr/bin的详细情况,-m选项是将显示的数据单位改成MBytes)。
以上命令常用来检查每个目录下的子目录的容量,目录的子目录可以通过通配符来表示,例如根目录的子目录就是 / *。如下图所示。

-
列出/etc目录下所有目录本身的容量,不包括子目录的容量累和:du -S /etc。
一定要注意命令(du)和命令(du -S)的区别,du显示的某个目录的容量是将所有子目录的容量和自身的容量相加得到的,而du -S显示的容量是某个目录自身的容量。下面是两者分别运行的截图。

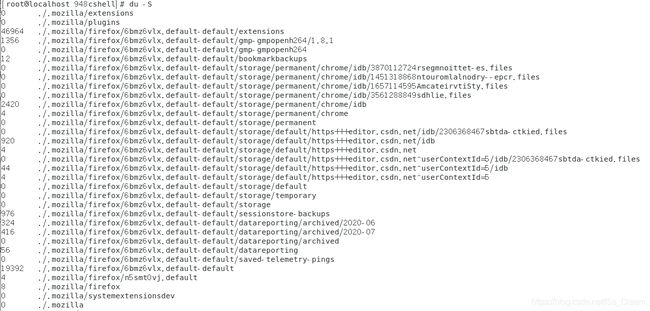
从命令(du)的图可以看出:目录(./.mozilla/firefox)总容量=(./.mozilla/firefox/6bmz6vlx.default-default)总容量 + (./.mozilla/firefox/n5smt0vj.default)总容量 + (./.mozilla/firefox)自身容量 = 73476。由于(./.mozilla/firefox/6bmz6vlx.default-default)总容量 + (./.mozilla/firefox/n5smt0vj.default)总容量为73468,所以可以得到(./.mozilla/firefox)自身容量为8,与du -S 的执行效果相符。所以可以得出结论,du -S显示的目录容量为自身容量而不是包括子目录容量的总容量。一个目录本身的容量来源于其记录的文件名与指向这些文件inode的指针的大小之和,如果不相信的话,写个脚本建立几千个空目录之后再执行该命令就可以看出效果了。 -
显示当前目录使用的磁盘总量:du -sb(-s或–summarize 仅显示总计,只列出最后加总的值,-b或-bytes 显示目录或文件大小时,以byte为单位)。
38、创建文件或目录的链接
- 创建某个文件的硬链接:ln X1/文件名 X1/文件名-hd(后缀-hd表示指明该文件是一个硬链接文件)。
- 创建某个文件的软链接:ln -s X1/文件名 X1/文件名-so(-s, --symbolic 对源文件建立符号链接,而非硬链接。后缀-so表示指明该文件是一个硬链接文件)。
39、列出系统上所有的磁盘列表
-
列出本系统下所有的磁盘与磁盘内的分区信息:lsblk。
如下图所示。
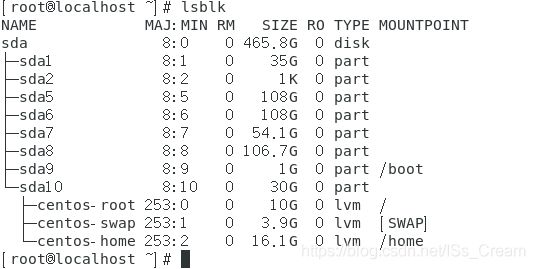
- NAME : 这是块设备名。
- MAJ:MIN : 本栏显示主要和次要设备号。
- RM : 本栏显示设备是否可移动设备。注意,在本例中设备sdb和sr0的RM值等于1,这说明他们是可移动设备。
- SIZE : 本栏列出设备的容量大小信息。例如298.1G表明该设备大小为298.1GB,而1K表明该设备大小为1KB。
- RO : 该项表明设备是否为只读。在本案例中,所有设备的RO值为0,表明他们不是只读的。
- TYPE :本栏显示块设备是否是磁盘或磁盘上的一个分区。在本例中,sda和sdb是磁盘,而sr0是只读存储(rom)。
- MOUNTPOINT : 本栏指出设备挂载的挂载点。
-
列出/dev/sda设备内的所有数据的完整文件名:lsblk -ip /dev/sda(-i, --ascii, use ascii characters only。-p选项表示列出该设备完整的文件名,而不是最后的名字)。
-
列出设备的UUID,文件类型等参数:blkid。
如下图所示。

-
列出磁盘的分区类型与分区信息(比如/dev/sdb):parted /dev/sdb print。
如下图所示。
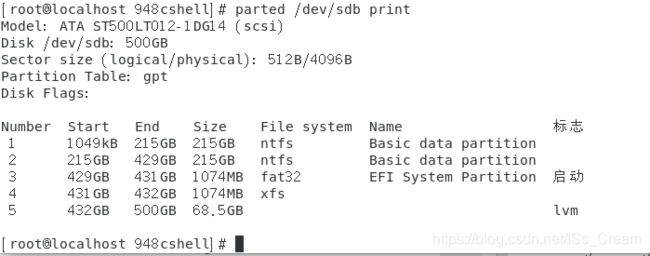
上图中的Partition Table一栏显示的就是磁盘的分区类型。
40、压缩 / 解压文件
- 将文件压缩成.gz的格式,并且显示压缩比:gzip -v 文件名。
- 将.gz压缩文件解压后的内容打印到终端上(前提是压缩前的文件是文本文件):zcat 压缩文件名.gz。
- 解压.gz文件:gzip -d 压缩文件名.gz。
- 将某个文件压缩成.gz,并且采用最高压缩,保留源文件:gzip -9 -c 源文件名 > 压缩文件名.gz(-<压缩效率>:压缩效率是一个介于1~9的数值,预设值为“6”,指定愈大的数值,压缩效率就会愈高,-c选项是将压缩的数据输出到屏幕上,可通过数据流重定向来进行处理)。
- 在.gz压缩文件中搜索某个关键字,并把含有这个关键字的内容打印到终端上(前提是压缩前的文件是文本文件):zgrep -n ‘关键字字符串’ 压缩文件名.gz。
- 将文件压缩成.bz2的格式,并且显示压缩比:bzip2 -v 文件名。
bzip2命令几乎和gzip命令一样。 - 将.bz2压缩文件解压后的内容打印到终端上(前提是压缩前的文件是文本文件):bzcat 压缩文件名.bz2。
- 解压.bz2文件:bzip2 -d 压缩文件名.gz。
- 将某个文件压缩成.bz2,并且采用最高压缩,保留源文件:bzip2 -9 -c 源文件名 > 压缩文件名.bz2。
- 将文件压缩成.xz的格式,并且显示压缩比:xz -v 文件名。
- 列出.xz格式的压缩文件的基本信息:xz -l 压缩文件名.xz(-l, --list,列出有关.xz文件的信息)。
- 将.xz压缩文件解压后的内容打印到终端上(前提是压缩前的文件是文本文件):xzcat 压缩文件名.xz。
- 解压.xz文件:xz -d 压缩文件名.xz。
- 将某个文件压缩成.xz,并且保留源文件:xz -k services(-k, --keep,保留,即不要删除输入文件)。
- 将某个目录打包压缩成.tar.gz格式:tar -zcv -f 压缩目录名.tar.gz(-z选项表示采用gzip压缩,-c选项表示打包,-v选项表示显示正在被处理的文件,-f选项后面跟上一个.tar.gz的文件名,代表最后压缩完毕的压缩目录名)。
- 将某个目录打包压缩成.tar.bz2格式:tar -jcv -f 压缩目录名.tar.bz2(-j选项表示采用bzip2压缩,-c选项表示打包,-v选项表示显示正在被处理的文件)。
- 将某个目录打包压缩成.tar.xz格式:tar -Jcv -f 压缩目录名.tar.xz(-J选项表示采用xz压缩,-c选项表示打包,-v选项表示显示正在被处理的文件)。
- 将某个目录进行打包备份:tar -zcvp -f 压缩目录名.tar.gz 待压缩目录名(-p选项表示保留原文件的所有权限和属性)。
- 查看tar打包的.bz2格式的压缩包中的文件信息:tar -jtv -f 压缩目录名.tar.bz2(-t选项表示查看压缩包中的文件名)。
- 解压tar打包的.bz2格式的压缩包到当前目录:tar -jxv -f 压缩包名.bz2(-x表示解压的意思)。
- 解压tar打包的.bz2格式的压缩包到指定目录:tar -jxv -f 压缩包名.bz2 -C 指定目录名(-x表示解压的意思)。
- 解压tar打包的.bz2格式的压缩包中的一个文件:tar -jxv -f 压缩包名.tar.bz2 待解压文件名。
待解压的文件名一定要注意路径是带有根目录的还是不带有根目录的。 - 将某个目录进行打包,但几个特殊的文件除外:tar -jcv -f 压缩目录名.tar.bz2 --exclude=除外的文件/目录名 待压缩文件名(–exclude后面跟不进行压缩的文件名)。
- 打包某些比某个时刻要新的目录:tar -jcv -f 压缩目录名.tar.bz2 --newer-mtime=“XXXX/X/XX” 待压缩的目录(–newer-mtime="XXXX/X/XX"表示修改时间)。
41、XFS文件系统的备份与还原
- 对/boot文件系统进行完整备份(前提是/boot必须是XFS文件系统,并且/boot必须是挂载点):xfsdump -l 0 -L 备份文件名的session label -M 存储媒介标头 -f 备份文件名 需要备份的文件(-l选项用来指定级别,级别0表示完整备份,-L选项会记录session标头,用来对文件系统进行说明,-M选项记录存储媒介标头,用来对存储媒介进行说明,-f选项后面跟文件名参数,是最后生成的备份文件的文件名,最后面的/boot是要被备份的文件系统)。
- 列出目前被备份的xfs文件系统的信息:xfsdump -I(-I选项会显示出目前备份信息的状态)。
- 列出目前被备份的xfs文件系统的信息:xfsrestore -I(-I选项会显示出目前备份信息的状态)。
此命令和xfsdump -I输出一样的内容。 - 对/boot文件系统进行增量备份(前提是/boot必须是XFS文件系统,并且/boot必须是挂载点,/boot文件系统必须进行过一次完整备份):xfsdump -l 1 -L session label -M 存储媒介的标头 -f 备份文件名 需要备份的文件(-l选项后面跟参数1表示进行一次增量备份)。
- 还原level 0的文件系统:xfsrestore -f 备份文件名 -L 备份文件名的session label 还原目录名(-f选项后面的参数是备份文件名,-L选项后面的一个参数是备份文件名的session label,最后一个是要恢复的文件系统名称)。如下图。
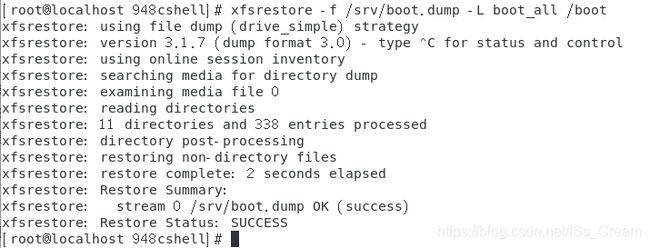
- 还原level 0文件系统中的某一个文件:xfsrestore -f 备份文件名 -L 备份文件的session labal -s grub2 还原的目录名(-s选项后面的参数是备份文件中的文件名)。
- 恢复增量备份数据:xfsrestore -f 备份文件名 还原的目录名。
注意恢复增量备份数据是不需要session label的,也就是不需要-L选项。 - 通过交互的方式批量恢复备份文件:xfsrestore -f 备份文件名 -i 还原的目录名。
如下图所示。
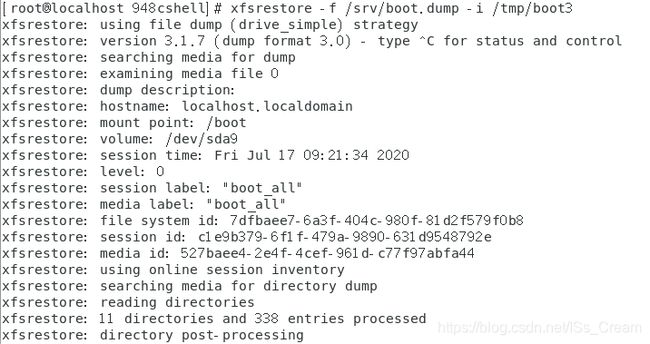

上图中的pwd、ls和cd等等都是这个交互界面中可以使用的命令。add可以将一个文件添加到需要还原的文件列表中,delete可以从还原文件列表中删除一个需要被还原的文件,extract命令表示进行文件还原。
- 直接复制扇区实现文件的备份:dd if=需要备份的文件名 of=备份文件名.back。
dd命令是直接进行扇区的读取然后进行数据备份的。 - 将整个/boot文件系统进行备份:dd if=/dev/sda9 of=/tmp/sda9.img。
通过命令(df -h /boot)可知/boot的文件系统是/dev/sda9,如下图所示。

之后在使用dd命令就可以了。 - 将一个分区的内容直接复制到另一个扇区上:dd if=分区1的设备文件名 of=分区2的设备文件名。
如果是gpt格式的分区表,可以使用gdisk命令进行分区的创建,创建之后就不必进行格式化了,因为命令dd是直接对一个分区的扇区进行复制,会将超级块等信息一并复制到新的扇区中,故不要对输出的扇区进行格式化。
如下图所示。

上图的/dev/sdb5是没有进行格式化的,也不需要格式化。
复制完成后需要将日志文件清理一下。如下图所示。

将/dev/sdb5进行挂载,不过在挂载之前一定要给新复制的分区重新分配一个全局唯一标示,因为是扇区复制所以会将原文件的全局唯一标识也复制过来,导致无法挂载。如下图所示。
![]()
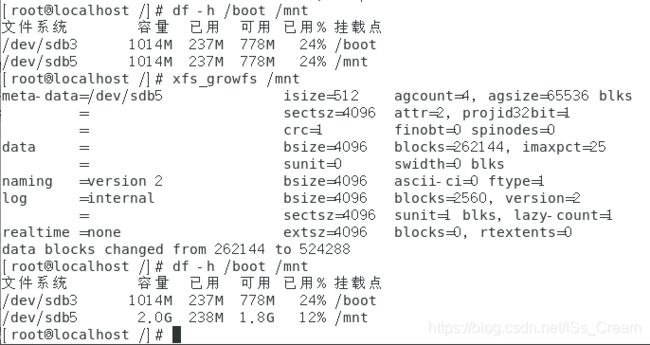
之后查看两个分区对应的挂载点对应的磁盘容量和大小。如下图所示。

从上图可知两个文件系统的信息一幕一样,因为是直接扇区复制的。
有一点需要注意,两者的容量都是1014M,我记得我当时分区是分了2个G,但却只有1014M,可能是我不记得df命令读取机制了,不过我猜应该df是直接读文件系统超级块的信息然后显示出来的吧?。
如果想要将/mnt的容量改成当时分区时设置的2G,可以通过使用命令(xfs_growfs)来实现。如下图所示。
42、比较两个文件(或目录)之间的差异
- 比较两个目录文件之间的差异:diff -r 目录1 目录2。
如下图所示。
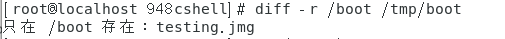
- 比较两个文件新旧文件之间的差异:diff 旧文件 新文件。
diff是以行为单位进行比较。
例子效果图如下。
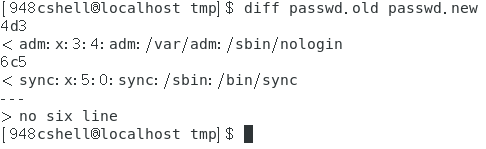
上图中的命令在执行之前将旧文件做了一些处理形成了一个新文件,处理是将第四行删除,第六行进行修改。图中【4d3】表示的意思是旧文件相比于新文件第四行被删除了,d表示删除delete。图中的【6c5】表示旧文件相比于新文件第六行被修改了,c表示change的意思。 - 按字节为单位比较两个文件,并返回两个文件第一个不相同的位置:cmp 文件1 文件2。
cmp命令默认返回第一个不相同的地方,如果要返回全部地方,需要添加参数-l。由于是以字节为单位进行比较,所以cmp可以用来比较二进制文件。
效果图如下。

上图中的两个文件是用上面diff命令的例子的中的两个文件。
43、对GPT格式的磁盘进行的相关操作。
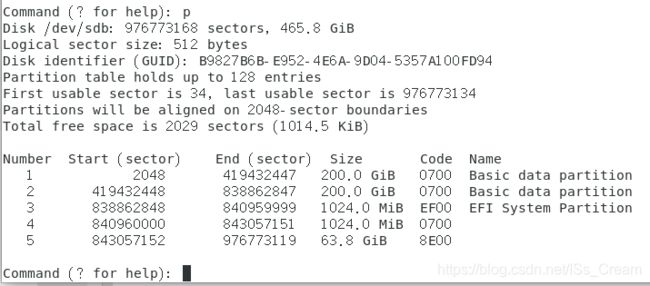
- 显示gpt磁盘的分区信息:gdisk 磁盘名称。
如下图所示。

在命令行中输入下上命令后会进入gdisk的命令模式,输入?可以显示所有的可以使用的命令,如果输入p可以查看磁盘分区的信息。如下图所示。
- 在gpt格式的文件系统中创建一个分区:gdisk 磁盘文件名。
出现如下图所示。

输入命令p先查看一下磁盘中的分区信息。
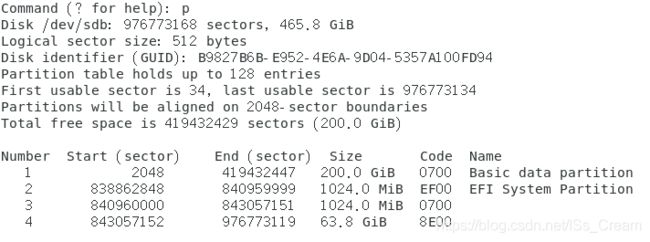
输入n命令可以创建一个新的分区。
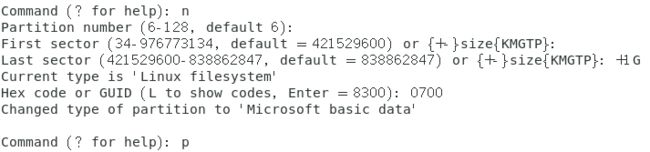
上图中的Partition number一栏可以直接采用默认值,直接回车就行,First sector也可以直接采用默认值,直接回车,Last sector就不要直接回车了,默认值会将剩下的所有空间全部分配出去,需要1G就直接在冒号后面输入+1G然后按回车就可以了,系统自动分配1G空间的分区出来,最后要选择可能的分区文件系统类型,默认是8300,如果要看所有的文件类型可以按L键回车查看。
创建分区成功之后输入w命令进行保存会有一个警告。如下图所示。

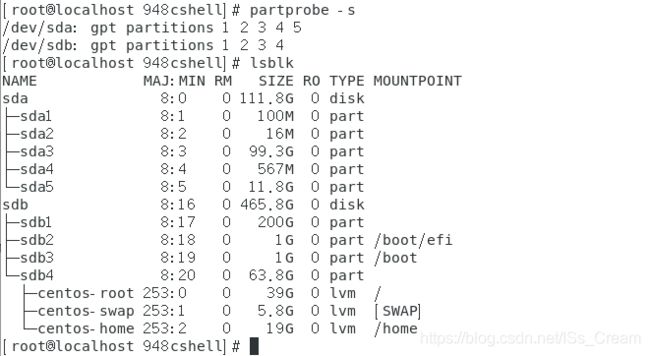
原因在于进行分区的是一块正在使用的磁盘,为了安全起见,暂时不会更新磁盘中的分区信息。可以通过重起系统或者命令(partprobe -s)进行更新。
另外需要注意磁盘的分区信息记录在路径(/proc/partitions)中。如下图所示。
- 删除一个gpt文件系统的分区:gdisk 磁盘文件名。
如下图所示。



44、创建文件系统(磁盘格式化)
- 创建一个xfs文件系统(前提是要有一个的分区,可以是gdisk命令创建的分区,假设分区是/dev/sdb5):mkfs.xfs /dev/sdb5(什么选项都不设置会采用默认的参数)。
如下图所示。

- 创建一个xfs文件系统,并且将agcount设置为2(设置之前最好查询cpu内核的个数):mkfs.xfs -f -d agcount=2 分区名(-f选项用在对之前已经创建过的文件系统进行格式化,防止出现警告,-d选项后面接agcount参数表示设置存储群组的意思)。
- 创建一个ext4文件系统(前提是要有一个分区):mkfs.ext4 分区目录。
- 查看系统支持格式化的文件系统有哪些:mkfs[tab][tab]。
效果如下图所示。

45、查看关于cpu的信息
- 查看电脑的cpu内核数目:grep ‘processor’ /proc/cpuinfo。
如下图所示。有四个cpu内核。

46、文件系统检验
- 对错乱的xfs文件系统的分区进行检查:xfs_repair 分区名。
如下图所示。

47、查看文件系统超级块的相关信息
- 查看ext4文件系统分区超级块的相关信息:dumpe2fs 分区名。
如下图所示。

- 查看ext4文件系统分区的备份超级块的块号:dumpe2fs -h 分区名 | grep ‘Blocks per group’。
如下图所示。
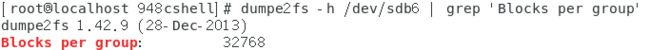
如果区块的大小是1K,那么备份超级块的放在8193,2K的区块则放置在16384,4K的区块放置在32768。
48、创建某个文件系统的挂载
- 创建xfs/ext4/vfat文件系统的挂载:mount UUID=“分区的全局唯一标示” 挂载目录名。
如下图所示。

- 显示所有的挂载信息:mount。
如下图所示。

- 将某个分区文件系统进行卸载:umount 分区名。
如下图所示。

49、自定义磁盘/文件系统参数
- 创建块设备文件(比如,磁盘):mknod /dev/设备文件名 b major minor(b表示创建的这个文件是一个块设备文件,major主要设备代码,minor表示次要设备代码)。
major和minor不能随便设置,设置之前需要用命令(lsblk)来查看一下当前已经使用过的major和minor各是多少。 - 创建FIFO文件:mknod FIFO文件名 p(p表示这是一个FIFO文件)。
- 修改xfs文件系统的标头:xfs_admin -L 新标头名称 xfs文件系统对应的设备文件名。
如下图所示。

- 列出xfs文件系统的标头:xfs_admin -l xfs文件系统对应的设备文件名。
如下图所示。
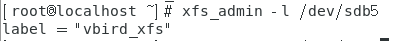
- 修改xfs文件系统的全局唯一标识:xfs_admin -U 全局唯一标识号码 xfs文件系统对应的设备文件名。
可以通过命令(uuidgen)生成一个全局唯一标识。
如下图所示。
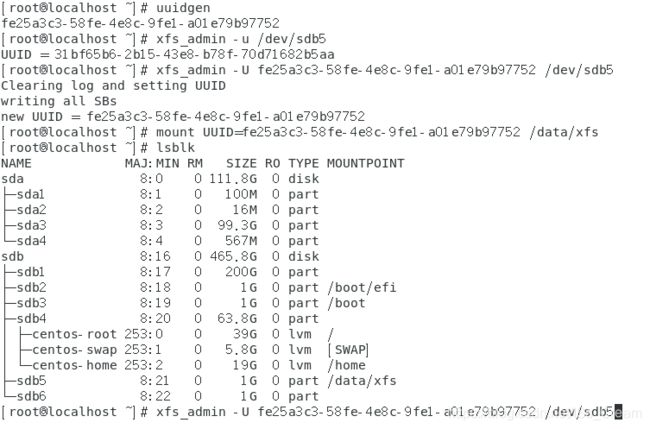
- 列出xfs文件系统的UUID:xfs_admin -u xfs文件系统对应的设备文件名。
如下图所示。

- 修改ext4文件系统的标头:tune2fs -L 标头名称 ext4文件系统对应的设备文件名。
如下图所示。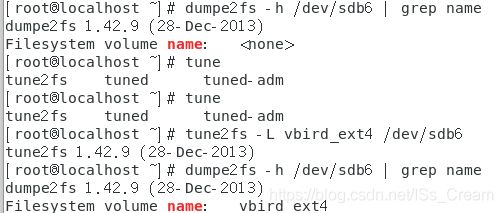
50、产生一个新的全局唯一标示
- 产生一个新的全局唯一标示:uuidgen。
如下图所示。

51、显示内存使用情况
- 显示内存使用情况:free。
free命令默认显示的单位是KB,可通过选项【-b】、【-m】、【-k】和【-g】来分别设置显示的单位为B、MB、KB和GB。
如下图所示。

total:内存总数;
used:已经使用的内存数;
free:空闲的内存数;
shared:当前已经废弃不用;
buffers Buffer:缓存内存数;
cached Page:缓存内存数。
52、自动扩展XFS文件到最大可用大小
- 自动扩展XFS文件到最大可用大小:xfs_growfs 文件系统挂载点。
一般是使用命令dd进行了硬盘分区的复制的案例。将文件系统超级块记录的文件系统容量大小改成分区大小。如下图所示。
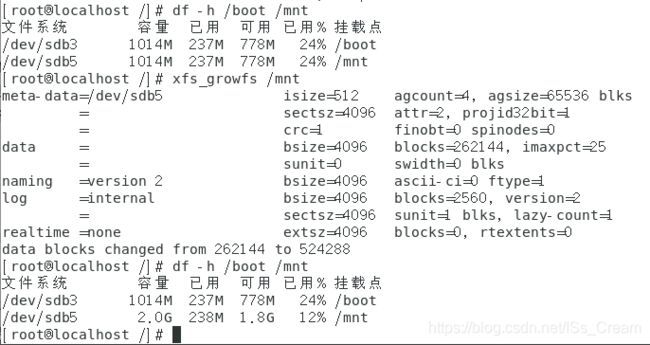
上图已经是将/boot对应的分区复制到/mnt之后所进行的操作。
53、文本文件格式转换
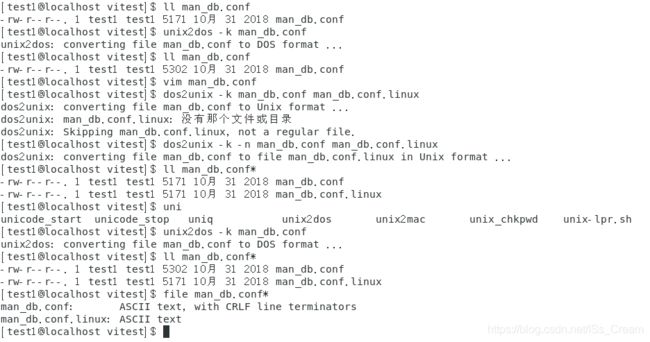
- 将dos文本文件转换成unix格式的:dos2unix -k 文件名(-k选项是保持原文件的mtime不变)。
该命令主要是针对dos文本文件中的换行符与类unix不同设置的转换命令。 - 将类unix的文本文件转换成dos格式的:unix2dos -k 文件名。
如下图所示。
54、命令别名
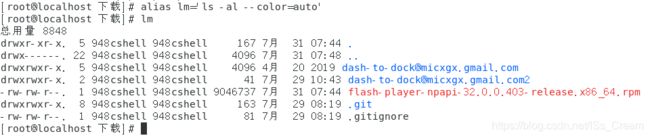
- 查看当前有哪些命令别名:alias。
如下图所示。

- 设置新的命令别名:alias 命令别名=‘命令’。
如下图所示。
55、查询命令的种类
- 查询命令是否为bash内置命令:type 命令名。
如下图所示。

上图中的-t选项可以将命令通过三个字眼显示,分别是alias,file,builtin,分别表示别名,外部命令,bash内置命令。
-a选项是按照PATH中的路径将所有名为‘命令名’的命令显示出来。 - bash中会有很多同名命令,显示这些命令的执行顺序:type -a 命令名。
56、为shell变量或函数设置导出属性(让普通变量变成环境变量)
- 将普通变量变成环境变量:export 变量名。
一个普通的变量可能只对创建它的用户有效,如果要让所有的用户都使用这个变量需要将这个变量变成环境变量。
57、对变量的操作
- 查看目前系统中所有的环境变量:env。
env是evironment的缩写。效果图如下。

- 判断一个变量是否为环境变量(全局变量):env | grep 变量名。
- 查看目前系统中所有的变量:set。
效果图如下。只截图了一部分。

- 查看目前系统中所有的环境变量:export。
如下图所示。未截全图。
58、声明变量,设置或显示变量的值和属性
- 声明一个变量,给他赋予整型属性,并给他赋值:declare -i 变量名=一个数值(-i选项表示增加整型属性)。效果图如下。

- 声明一个整型变量,并给他赋一个运算表达式:declare -i 变量名=运算表达式 ;echo $变量名
如下图所示。

- 将自定义变量变成环境变量:declare -x 变量。
如下图所示。
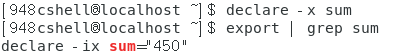
- 将变量设置为只读属性:declare -r 变量名。
如下图所示。

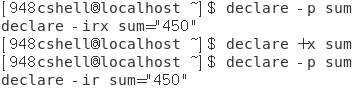
- 将环境变量变成自定义变量:declare +x 变量名。
这里的加号有点儿特殊,表示取消的意思。如下图所示。
59、读取来自键盘输入的变量
- 通过交互的方式,将用户键盘输入的内容创建一个变量:read 变量名。
输入这个命令按下回车之后,会出现一个空白行等待用户输入变量的内容。如下图所示。

- 通过交互的方式,将用户键盘输入的内容创建一个变量,并且给予提示信息和设置等待用户秒数:read -p “提示信息” -t 数字 变量名(-p选项后面接提示信息,-t后面的数字是等待的秒数)。
效果图如下所示。

60、控制shell程序的资源
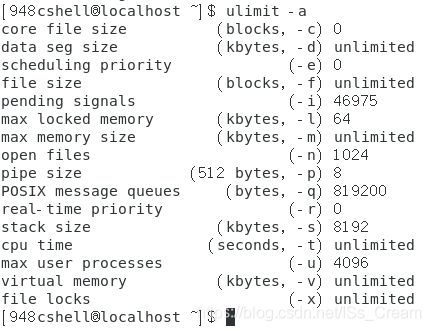
- 列出当前身份的所有的资源限制数值:ulimit -a。
如下图所示。
- 设置当前用户单次创建文件的最大限制(单位是KB):ulimit -f 数据。
数据如下图所示。如果单次创建的文件数超过下图规定的10G,就报错了。

61、查看历史命令
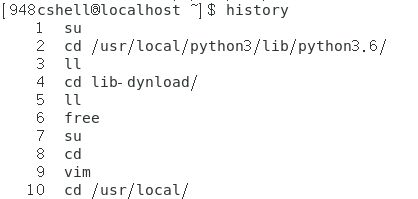
- 显示曾今使用过的历史命令:history。
显示的最大数量和环境变量HISTSIZE有关。如下所示。
- 显示最近使用的三条命令:history n(n表示数字的意思)。

- 立即将目前使用命令的情况写入到记录历史命令的默认文件(~/.bash_history)中:history -w。
因为在历史命令信息会在bash登陆linux时在相关的记录命令信息的文件进行读取,在注销的时候将更新的历史信息写回记录历史命令信息的文件,而命令(history -w)则相当于是强制写回。
62、在当前shell环境中从指定文件中读取或执行
- 在当前的shell环境中读入环境配置文件:source 配置文件名。
63、终端环境设置
- 显示出终端所有的按键以及按键的内容:stty -a。
如下图所示。前面的"^"表示”ctrl“键。

- 修改终端中的某个操作的快捷键:stty 操作名 快捷键名(操作名根据命令(stty -a )在终端中的显示结果进行填写)。示例如下。

64、设置bash自己的终端设置值
- 显示目前所有开启的set设置值:echo $-。
效果图如下图所示。

- 通过set设置,当使用未定义的变量时,bash给予提示信息:set -u。
如下图所示。
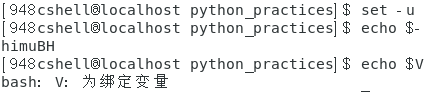
- 取消bash的一个set的设置值:set +字母。
如下图所示。

65、管道命令中的选取命令
- 取出PATH变量中的第五个目录:echo $PATH | cut -d ‘:’ -f 5(-d选项后面紧跟一个分隔符,将第一个命令的标准输出用该分割符进行分割,-f选项经常和-d选项一起用,后面跟一个数字,表示取出被分割后的标准输出的第几块的意思)
该命令是以":"来进行分割。cut命令的处理是以行为单位。
如下图所示。

- 取出PATH变量中的第三个和第五个目录:echo $PATH | cut -d ‘:’ -f 3,5(-d选项后面紧跟一个分隔符,将第一个命令的标准输出用该分割符进行分割,-f选项经常和-d选项一起用,后面跟一个数字,表示取出被分割后的标准输出的第几块的意思)
该命令是以":"来进行分割。cut命令的处理是以行为单位。
如下图所示

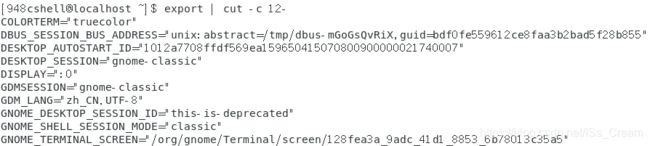
- 在export命令的标准输出中,只显示每行第12个字符以后的字符: export | cut -c 12-(-c选项表示以字符为单位取出固定的字符区间)。
因为export命令的标准输出的内容中,前12个字符几乎都是"declare -x",所以最后显示的结果就是将"declare -x"去掉。
-c选项后面的区间使用"-"来表示的,比如"1-5"表示第一个字符到第五个字符,"5-"表示第五个字符到最后一个字符。
使用cut之前如下图所示。

使用cut之后如下图所示。
- 在last命令(可以使其他拥有标准输出的命令)的标准输出中,查找含有某关键字的行:last | grep ‘查找字符’。
如下图所示。

- 在last命令(可以使其他拥有标准输出的命令)的标准输出中,查找不含有某关键字的行:last | grep -v ‘查找字符’。
如下图所示。

66、列出目前与过去登入系统的用户相关信息
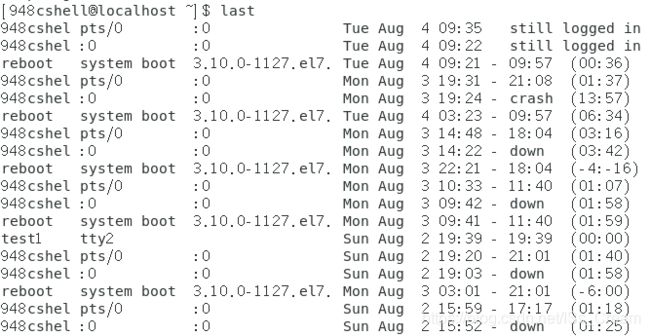
- 显示用户最近登陆的信息:last。
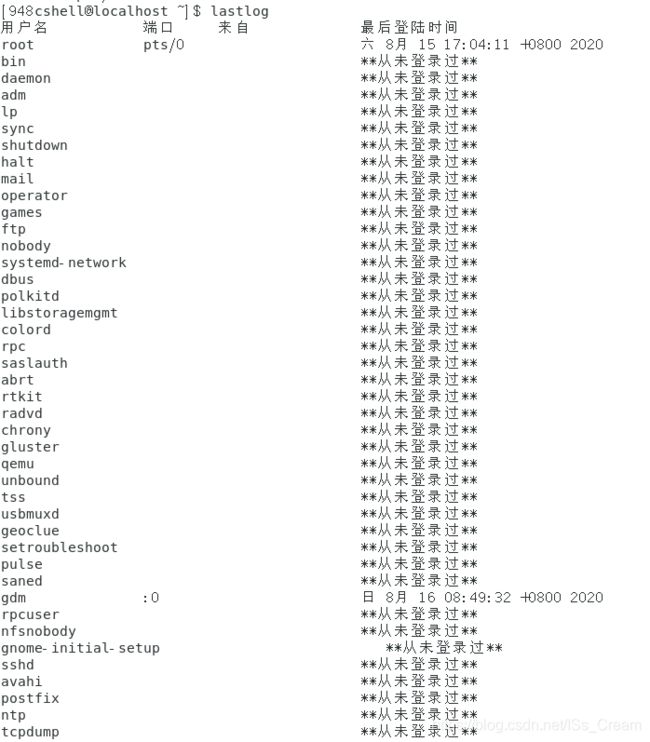
- 显示所有帐号最近登陆的时间:lastlog。
该命令会读取文件【/var/log/lastlog】的内容。如下图所示。
与命令【last】不同的是,该命令连从未登陆的用户的信息也会显示出来。
67、管道命令中的排序命令
-
显示排序之后的所有用户:cat /etc/passwd | sort。
sort默认情况是以文字进行排序。
如下图所示。
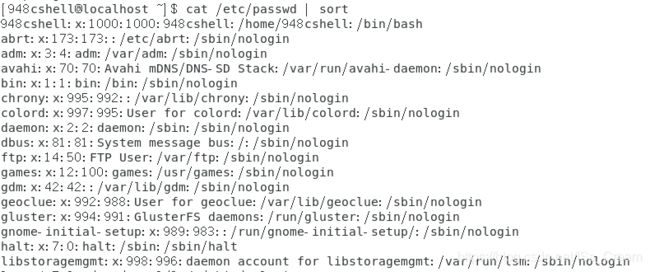
-
由于/etc/passwd记录的每一条信息是以":"分割成很多栏,显示以第三栏来排序的结果:cat /etc/passwd | sort -t ‘:’ -k 3(-t选项表示每条信息的分割符,默认是tab,-k选项经常和-t选项搭配着使用,一条信息可以被分割成好几栏,-k就是指定按照第几栏进行排序的意思,后面跟数字)。
如下图所示。

-
利用last显示登陆的用户,只显示用户名,并对这些用户名进行排序:last | cut -d ’ ’ -f 1 | sort。
如下图所示。

-
利用last显示登陆的用户,只显示用户名,对这些用户名进行排序,并将重复的用户名去掉:last | cut -d ’ ’ -f 1 | sort | uniq。
排序之后的去重利用的示uniq命令。
如下图所示。

-
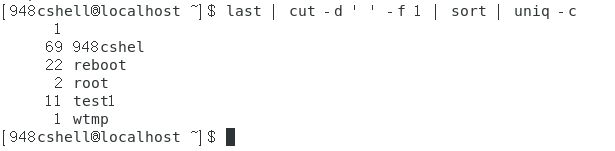
利用last显示登陆的用户,只显示用户名,对这些用户名进行排序,将重复的用户名去掉,并显示出每个用户出现的次数:last | cut -d ’ ’ -f 1 | sort | uniq -c(uniq命令的-c选项可以显示每一天数据出现的次数)
如下图所示。
-
显示某个文件有多少相关字、行、字符数:cat 文件名 | wc
如下图所示。

上面显示的三个数分别是行、字数、字符数。 -
显示当前注册的用户数目:wc /etc/passwd。
如下图所示。

上面显示的三个数分别是行、字数、字符数。由于/etc/passwd中每一行代表一个用户,所以行数就是注册的用户数。 -
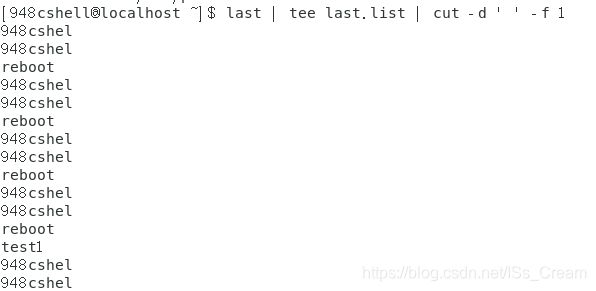
利用last显示登陆的用户并保存到指定文件,同时在屏幕上只将用户名显示显示出来:last | tee last.list | cut -d ’ ’ -f 1。
tee命令示双向重定向命令,可以实现同时将数据保存到文件(相当于示数据重定向)和在屏幕上显示信息。
如下图所示。

68、管道命令中的字符转换命令
-
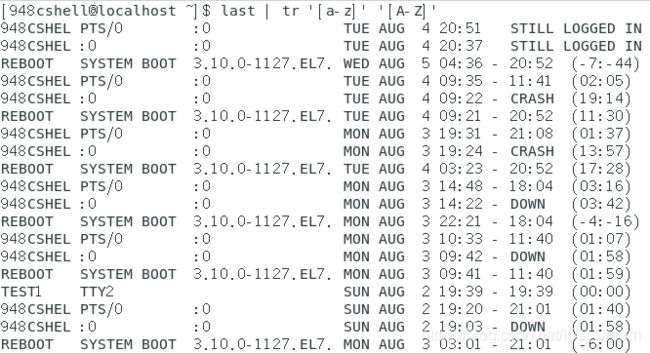
将last命令输出的内容中所有的小写字母变成大写字母:last | tr ‘[a-z]’ ‘[A-Z]’。
tr命令的作用是将一段文字中的字符进行替换和删除。
比如上面命令的意思就是将last输出的内容作为标准输出给tr命令,第一个表示要替换的字符(或字符串),’[a-z]'表示a到z中的任何一个字符都应该被替换,第二个表示用来替换的字符。
效果如下图所示。
-
将cat命令的输出作为标准输出,将标准输出中的某个字符(或字符串)删除:cat 文件名 | tr -d ‘字符’(-d选项表示删除的意思,后面紧跟一个字符,将该字符从标准输出中删除后,再将文件内容显示出来)
效果如下图所示。
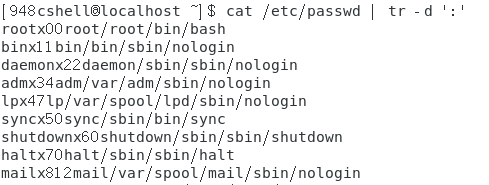
-
将cat打开的文件中,所有的[tab]变成同等数量的空格:cat 文件名 | col -x | cat -A | more。
col命令的作用是进行控制字符的过滤,最常见的就是搭配-x选型将[tab]转换成等量的空格。
转化之前如下图所示。

从上图中可以发现非常多的’^I’,这个就是[tab]。
使用col命令处理之后如下图所示。

可以发现所有的[tab]都变成了等量的空格。 -
将两个文件中的相关数据整合成一行:join -t ‘分割符’ 文件名1 文件名2(-t选项后面紧跟分割符,用这个分割符将两个文件每行的数据进行分割,之后比较两个文件第一栏的数据)。
以上命令的具体的工作流程是:将两个文件的每行用分割符进行分割,分割成许多栏,比较两个文件第一栏的数据,如果相同,就将两个文件的第一栏的数据合并成一个(即,只显示一个第一栏数据,剩下的两个文件的数据也放到这一行上)。
效果如下图所示。
合并前。

合并后

-
将两个文件中的相关数据整合成一行,且相关的数据不在同一栏:join -t ‘:’ -1 n 文件名1 -2 n 文件名2(-1选项后面紧跟数字,表示第一个文件用第n栏和第二个文件进行比较,-2选项后面紧跟数字,表示第二个文件用第n栏和第一个文件进行比较)。
效果图如下。
合并前。

合并后

上面好像第一行的数据合并有点不成功。 -
直接将两个文件同一行的数据贴在一起:paste 文件名1 文件名2(没有选项默认将两个文件同一行的数据用[tab]进行分割)。
如下图所示。

-
将标准输入的数据和其他的文件数据粘贴在一起:cat 文件名1 | paste 文件名2 文件名3 - | head -n 3(命令中的文件名3后面的-表示标准输入的意思)
效果图如下。

-
将某个文件中所有的[tab]设置成n个空格并输出:cat 文件名1 | expand -t n - | cat -A(expand命令中的选项-t后面紧跟数字n,表示将[tab]用n个字符代替,后面的-表示标准输入。cat 中的-A选项可以显示向[tab]这样的特殊字符,[tab]会被显示成’^I’)
示例如下图所示。
69、管道中的划分命令
-
将一个较大文件,按照指定的大小,划分成多个小文件:split -b n(单位:b, k, m) 被划分的文件名 划分后的文件名(-b选项用来指定划分大文件的大小,后面紧跟一个数字,数字后面紧跟单位)。
效果如下。
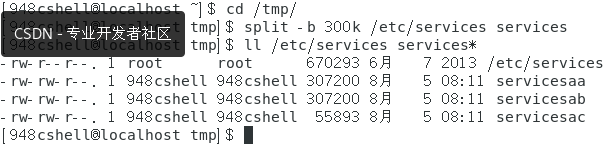
从上图中可以看出被划分出来的小文件后面对了个a、b、c。
如果要将上面的三个小文件进行还原的话,可以进行以下操作。

上图中利用了累加的数据重定向。 -
将第一个命令的标准输出作为标准输入,对标准输入的内容按行划分并保存到相关的文件中:ls -al / | split -l n - 文件名(-l选项后面紧跟数字表示按多少行来划分)
效果图如下所示。
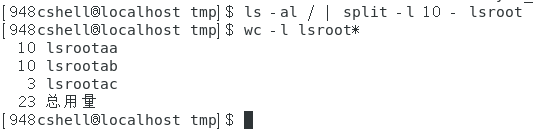
70、查询用户的UID和GID
- 查询某个用户的UID和GID:id 用户名。
如下图所示。

- 查询当前用户的UID和GID:id。
如下图所示。

71、管道命令中的参数代换
- 将前面的命令的标准输出进行作为后一个非管道命令的参数,让后一个非管道命令执行。
比如命令:cut -d ‘:’ -f 1 /etc/passwd | head -n 3 | xargs -n 1 id。
由于命名id并不是管道命令,他不能直接利用前一个命令(head -n 3)的标准输出作为参数,这时就需要使用参数代换命令xargs了,他可以将前面命令产生的标准输出用换行符或者空格进行分割,将最后分割的出来的数据作为非管道命令的id的参数,由于id命令执行一次只需要一个参数,因此xargs命令需要通过-n选项来指定一下一次传给id几个参数,因为id命令一次只需要一个,所以上面命令中-n选项后面跟的是1。
效果如下图所示。

xargs除了上面的-n选项外,还有-p参数,用来和用户交互,询问是否执行这一次的非管道命令。还有-e选项后面跟一个字符串,表示当xargs在标准输入中读到了该字符串的时候,就停止执行该命令,需要注意的点就是-e选项后面跟的字符串之间是没有空格的。这两个选项就不再进行演示了。
总的来说,linux中的很多命令其实都不是管道命令,也就是说这些非管道命令是无法直接利用前面命令的标准输出作为自己的标准输入,那么xargs命令的作用就是将前面命令的标准输入进行分割,让后面的非管道命令使用上前面命令的标准输出作为自己的参数。
72、显示Linux系统启动信息
- 列出内核信息:dmesg。
如下图所示。

73、基础正则表达式练习
- 查找特定字符串
查找某个文件的特定字符串并显示行号:grep -n ‘字符串’ 文件名(-n选项表示显示行号)。
如下图。

反向选择,选出不包含某个字符串的行:grep -vn ‘字符串’ 文件名(-v选项表示反向选择)
如下图所示。

查找某个文件中的特定字符串,忽略大小写:grep -in ‘字符串’ 文件名(-n选项表示显示行号,-i表示忽略大小写)。
如下图。

- 利用中括号[]来查找集合字符
利用集合来查找多个相似的关键字(比如test和taste)的行:grep -n ‘t[ae]st’ 文件名。
中括号中可能有很多个字符,但是其只表示其中的某一个,因此只要有一个满足就行,类似于或。
如下图所示。
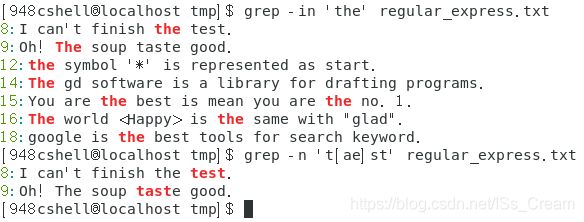
利用中括号查找开头不含有某些字符的字符串的行:grep -n ‘[^字符集]字符串’ 文件名。
如下图所示。

利用中括号查找开头不含有小写字母的字符串的行:grep -n ‘[^a-z]字符串’ 文件名。
上面的命令只适用于小写字母a-z是在语系中是连续的情况。推广一下,只要语系支持的大写字母连续,任意一个大小字母可以用[A-Z]表示,任意一个字母可以用[a-zA-Z]表示,任意一个字母或数字可以用[a-zA-Z0-9]表示。
如下图所示。


以上例子中,如果语系编码中的小写大写数字不是连续的,是会出错的。为了应对可能不连续的问题,可以参考下面的例子。


以上用特殊字符来进行替换就比较好的解决了语系中小写不连续的问题。 - 行首与行尾字符(^和$)
查找开头是某字符串的行:grep -n ‘^字符串’ 文件名。
如下图所示。

查找开头是小写字母的字符串的行:grep -n ‘^[a-z]’ 文件名 或者 grep -n ‘^[[:lower:]]’ 文件名 。
如下图所示。


查找开头是不是字母的字符串的行:grep -n ‘[[:alpha:]]’ 文件名。
如下图所示。

上图中的’^'符号在中括号内表示反向选择,在中括号外面表示开头的意思。
查找结尾是小数点的行:grep -n ‘\.$’ 文件名。
由于小数点是特殊字符需要进行转义。$符号表示结尾的意思。
如下图所示。

查找空白行:grep -n ‘^$’ 文件名。
如下图所示。

- 任意一个字符’.‘与重复字符’*’
查找某个长度为4,开头是字符1,结尾是字符2的行:grep -n ‘字符1…字符2’ 文件名。
如下图所示

查找连续有多个某字符的字符串的行:grep -n ‘字符*’ 文件名。
如下图所示。

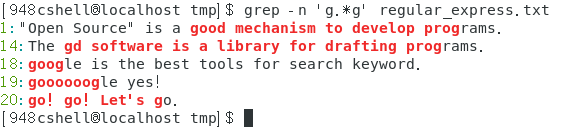
查找开头是字符1,结尾是字符2,中间是任意多个其他字符的字符串的行:grep -n ‘字符1.*字符2’ 文件名。
如下图所示。
- 限定连续字符的数目范围
查找指定个数n个连续某字符的字符串的行:grep -n ‘字符\{n\}’ 文件名。
由于{}在shell中有特殊含义,因此使用的时候要进行转义。
如下图所示。

查找开头是字符1中间是2到5个连续字符2,结尾是字符3的字符串的行:grep -n ‘字符1字符2{2,5}字符3’ 文件名 。
如下图所示。

74、功能强大的流式文本编辑器(sed工具)
-
以行为单位的新增 / 删除功能
将前一个命令的标准输出作为sed的标准输入,删除内容的n1~n2行,再将内容输出:nl 文件名 | sed -e ‘n1,n2d’(sed命令的 -e选项表示在命令行执行sed命令的意思,不过没有-e选项也可以在命令行执行 ,sed命令的操作一般用单引号阔起来,模板是【‘n1,n2操作名’】,n1和n2表示行,不一定会存在,都存在的时候表示行区间,n2行后面紧跟操作,例如上面命令中的"d"表示删除的意思)
效果如下图所示。
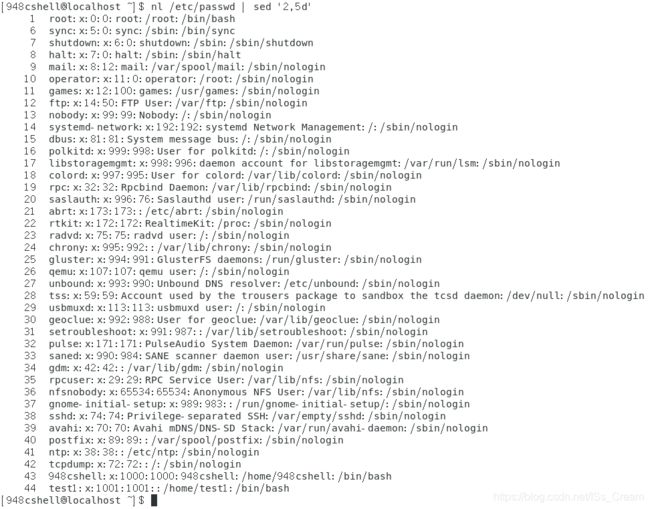
从上图中可以看出2到5行被删除了。
以上命令如果改成只删除第二行,操作部分可以这么写【‘2d’】。
以上命令如果改成删除第3行到最后一行,操作部分可以这么写【‘3,$d’】。
将前一个命令的标准输出作为sed的标准输入,在标准输入的n2的下一行加上某些内容后,再进行输出:nl 文件名 | sed ‘n2a 内容’(n2后面的a操作是表示在n2的下一行加数据的意思)。
效果如下图所示。

以上命令如果是在n2行的前一行加入内容,操作部分可以这么写【‘n2i 内容’】。
将前一个命令的标准输出作为sed的标准输入,在标准输入的n2的下两行(可以推广到多行)加上某些内容后,再进行输出:nl 文件名 | sed ‘n2a 内容(每输入完一行后输入’’,即可继续输入第二行,等所有内容输入完后再用单引号括回来)’(n2后面的a操作是表示在n2的下一行加数据的意思)。
如下图所示。
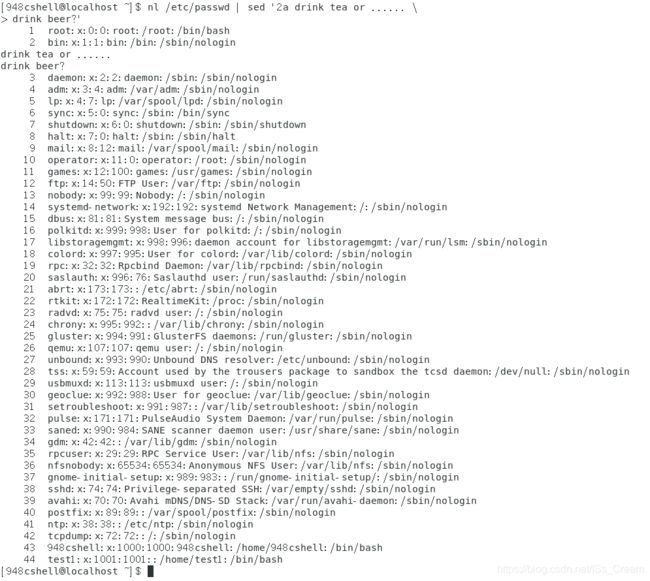
注意上图命令中的第二个单引号一定要最后打上,如果直接在单引号中添加反斜杠,是出不来效果的。 -
以行为单位的替换与显示功能
将前一个命令的标准输出作为sed的标准输入,替换标准输入的n1~n2行,再进行输出:nl 文件名 | sed ‘n1,n2c 替换的内容’(sed命令的 -e选项表示在命令行执行sed命令的意思,不过没有-e选项也可以在命令行执行 ,sed命令的操作一般用单引号阔起来,模板是【‘n1,n2操作名’】,n1和n2表示行,不一定会存在,都存在的时候表示行区间,n2行后面紧跟操作,例如上面命令中的"c"表示替换的意思)
效果图如下。

将前一个命令的标准输出作为sed的标准输入,显示其中的n1行到n2行的内容:nl 文件名 | sed -n ‘n1,n2p’(-n选项表示sed工具使用安静模式,这个名词有点儿抽象,没有它的时候,sed会将标准输入全部输出到屏幕上,有它的时候只会将被操作的那些行,即单引号中的n1和n2描述的行,进行输出)。
效果图如下图所示。

没有-n选项输出如下图。

-
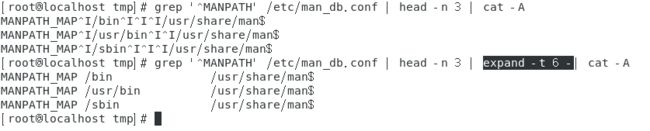
部分数据的查找并替换的功能
找出/etc/man_db.conf中所有含有MAN关键字的行,并且将含有注释,即’#‘的行去掉:nl /etc/man_db.conf | grep ‘MAN’ | sed ‘s/^.*#.*$//g’ | sed ‘/^$/d’。
每一步的效果图如下所示。
第一步,原始文件输出结果如下图。

第二步,筛选出含有MAN关键字的行。如下图。

第三步,将含有注释的行变成空白行。

上图中sed的操作用单引号阔起来,由于是将整个标准输入部分数据的替换,省略的可有可无的行号,s表示局部替换的操作,里面的写法类似于vim中的字符串替换的写法,上图中的sed命令的意思是将所有含有’#'的行变成空白行。
第四步,删除空白行。如下图所示。

上图中最后一个sed命令的意思是,查找所有的空白行,然后执行删除操作。 -
直接修改文件(危险操作)
直接对某个文件中的字符串进行替换:sed -i ‘s/被替换字符串/替换字符串/g’ 文件名(-i选项表示直接修改文件)。
直接在某个文件的最后一行添加内容:sed -i ‘$a 要增加的内容’ 文件名。
75、shell环境中测试条件表达式
- 测试一个文件是否存在:test -e 文件名 && echo “exist” || echo “Not exist”。
由于test命令不会显示任何信息,所以要搭配echo命令和&&以及||的逻辑关系来进行测试。
效果如图所示。

- 判断一个文件名是否是一个文件,如果是,则显示相关的信息:test -f 文件名 && echo “需要显示的信息”。
- 判断一个文件名是否是一个目录,如果是,则显示相关的信息:test -d 文件名 && echo “需要显示的信息”。
- 判断一个文件的拥有者是否拥有某种权限,如果是,则显示相关的信息:test -(r/w/x) 文件名 && echo “需要显示的信息”。
r、w、x分别对应读写执行。 - 判断一个字符串是否为空字符串,如果为真,则显示相关的信息:test -z 字符串 && echo “相关的信息”。
76、获得连续的数字
- 显示某个数到另一个数之间的所有连续整数:seq 首数 尾数。
例子如下图。换行显示1到10连续的整数。
以上操作常用于脚本编写中的for…do…done语句中。 - 直接通过bash的内置机制利用空格分割显示连续整数:echo {1…10}。
例子如下图所示。空格显示1到10的连续的数。

77、shell脚本的debug
- 检测某脚本有无语法错误:sh -n 脚本名称(-n选项表示不执行脚本,仅查询语法错误)。
如果没有语法错误,那么什么输出也不会有。
效果图如下。

- 将使用到的脚本内容显示到屏幕上(非常有用):sh -x 脚本名(-x选项表示将使用到的脚本内容显示到屏幕上)。
效果如下。
使用的脚本是
执行过程如下图所示。#!/bin/bash # Program: # Using for ... loop to print 3 animals # History: # 2020/08/12 VBird First release PATH=/bin:/sbin:/usr/bin:/usr/sbin:/usr/local/bin:/usr/local/sbin:~/bin export PATH for animal in dog cat elephant do echo "There are ${animal}s..." done
 上图中加号后面的是命令。
上图中加号后面的是命令。
78、查询/etc/shadow文件的密码加密机制
- 查询/etc/shadow文件的密码加密机制:authconfig --test | grep hashing。
效果如下图所示。
79、用户所属的用户组的操作
-
查看当前用户所属的用户组:groups。
输出的所有用户组中,第一个用户组是有效用户组,如果创建一个新文件或者目录,该文件或者目录的用户组就是有效用户组。
如下图所示。
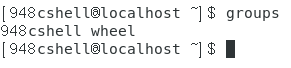
上图中的有效用户组是948cshell。 -
切换当前用户的有效用户组:newgrp 用户组名。
该命令后的用户组名必须是当前用户所属的用户组其中的一个。该命令会让当前用户以另一个shell环境进行登陆,如果用户在命令行输入exit或者ctrl + D之后,便会回到之前的shell环境。
效果图如下所示。

从上图中可以看到有效用户组已经切换了。
80、关于shell的相关操作
- 显示系统上所有合法的shell:chsh -l(-l选项实际上就是将文件【/etc/shells】中的内容输出出来)。
如下图所示。
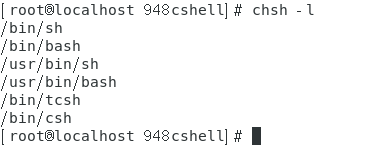
- 更改当前用户的shell为指定的某个shell:chsh -s shell的绝对路径(-s后面接shell的绝对路径更改当前用户的shell)。
如下图所示。

81、查看文件系统是否支持ACL,即访问控制列表
- 查看文件系统是否支持ACL,即访问控制列表:dmesg | grep -i acl。
如下图所示。
 上图中显示的文件系统是支持ACL的。
上图中显示的文件系统是支持ACL的。
82、ACL的设置与查看
-
针对某个文件,给特定用户设置权限:setfacl -m u:特定用户名:权限(r、w、x) 文件名(-m选项表示将后面的ACL参数给文件使用)。
如下图所示。

可以看到上途中的权限后面多了个【+】号。 -
针对某个文件,给当前用户设置权限:setfacl -m u::权限(r、w、x) 文件名(-m选项表示将后面的ACL参数给文件使用)。
-
针对某个文件,给特定用户组设置权限:setfacl -m u:特定用户组名:权限(r、w、x) 文件名(-m选项表示将后面的ACL参数给文件使用)。
如下图所示。

-
针对某个文件,设置他的有效权限,即mask:setfacl -m m:权限(r、w、x) 文件名。
有效权限mask表示的是用户或用户组所设置的权限必须要存在于mask的权限设置范围内才会生效。
如下图所示。

上图中的用户vbird1虽然有rx权限,但有限权限之后r,所以x权限是无效的。 -
针对某个目录,为特定用户或用户组设置默认ACL权限,并且让新建的子目录继承父目录的ACL权限:setfacl -m d:u(或g):用户名(或用户组):权限 父目录名。
只要在该目录中创建了目录,这些目录就会继承父目录的默认ACL权限。这些默认ACL权限只对目录有效(可能还没有遇到对文件有效的)。
总的来说,ACL权限可以分为普通权限和默认权限,两者的区别在于默认权限拥有继承属性,可以让子目录继承父目录的ACL默认权限,而对于普通权限,子目录无法继承父目录。
效果如下图所示。
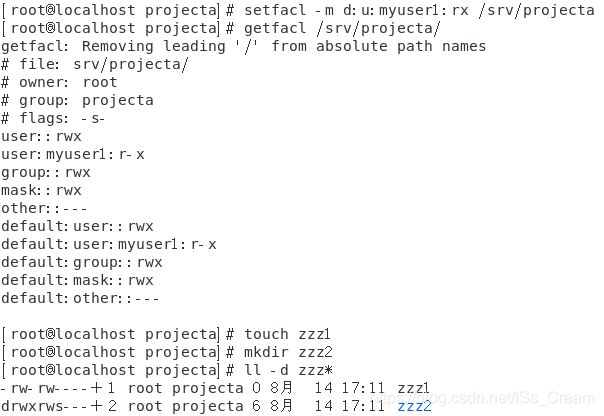

可以看到上图中子目录zzz2继承了父目录projecta的ACL权限。 -
显示某个文件acl权限的内容:getfacl 文件名。
如下图所示。
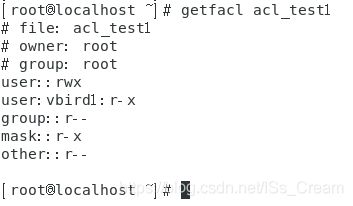
-
删除某个文件的所有ACL权限:setfacl -b 文件名(-b选项表示删除某个文件的所有ACL权限)。
-
删除某个文件的默认ACL权限:setfacl -k 文件名(-k选项表示删除某个文件的默认ACL权限)。
-
针对某个文件,删除某个用户(或用户组的)的ACL权限:setfacl -x u:用户名(或g:用户组名) 文件名(-x选项和-m选项相反,-m选项是将后面的权限参数对某个文件使用,-x选项是取消后面的权限参数对某个文件使用)。
83、命令解释器
- 在shell子程序中运行shell脚本:sh shell脚本名。
- 从字符串中解析出命令:sh -c “命令”(-c选项后面跟一个字符串表示从字符串中解析出命令)。
这种命令常用在sudo这种后面跟命令,且这些命令需要用【;】、【&&】和【||】等进行连接的情况。
如下图所示。

84、让一般用户使用root权限执行命令。
- 以某一用户的身份执行命令:sudo -u 用户名 命令(-u选项后面接用户名,表示暂时用该用户的权限执行命令)。
若没有-u选项,则表示使用的是root用户,将具有root的权限。
如下图所示。


85、用户之间的交流
-
某个在线用户给另一个在线用户发送信息:write 接受者用户名 所在的终端页面。
首先先用命令【who】查询一下在线用户与其使用的终端页面。如下图。

从上图中可以看出用户【948cshell】和用户【root】是在线的,用户名后面的选项就是终端界面。
通过用户【948cshell】给用户【root】发送消息如下图。

这下用户【root】就会立刻查看到用户【948cshell】给他发送的信息。由于用户【root】是通过终端登陆,不是图形界面,因此不好截图,所以用用户【root】给用户【948cshell】发行消息,用户【948cshell】如下图。

-
屏蔽用户发送的信息(针对write命令):mesg n。
使用命令【mesg n】可以其他用户发送的信息,除了root用户发送的。如果给一个屏蔽接受信息的用户发送信息会出现下图的情况。
重新开放接受信息,可以通过命令【mesg y】。
如何判断当前是不是允许接受信息,可以通过命令【mesg】,如下图。

出现信息【is y】表示允许接受,如果是信息【is n】表示屏蔽接受。 -
对所有用户广播发送信息:wall “信息”。
如下图所示

从上图可以看出发送者自己也会收到信息。 -
给某个本机用户发送邮件:mail -s “标题” 用户名(-s选项后面可以设置标题)。
会将邮件的内容发送到本机的文件【/var/spool/mail/用户名】下。 -
查看接收到的邮件:mail。
如下图所示。

上图中输入【?】可以查看有哪些可以使用的命令,图中的【message list】就是邮件前面的标号。如果要查看某个文件的内容,可以直接输入【n 邮件标号】就可以在这个maiil程序中查看。【q】是保存并退出,【x】是不保存退出。【h 数字】可以显示后面数字封邮件的标头。
86、帐号检测工具
- 检测系统中的帐号是否存在家目录,并且对比文件【/etc/passwd】和文件【/etc/shadow】的信息是否一直以及文件【/etc/passwd】中的数据是否有不合法:pwck。
如下图所示。

提示这些帐号家目录是不存在的,不过这些用户都是系统用户,所以不需要有家目录,正常报错。 - 将文件【/etc/passwd】中的密码栏写入文件【/etc/shadow】中:pwconv。
如果是使用命令【useradd】创建用户,这个命令就用不上了。 - 将文件【/etc/shadow】中的密码栏写入文件【/etc/passwd】中:pwunconv。
最好别用,他会在写入的过程中将文件【/etc/shadow】删除。 - 从标准输入读入信息,给某个用户修改密码:echo “用户名:密码” | chpasswd。
现在此命令用的不多了,因为passwd命令也能完成同样的功能。
87、磁盘配额的相关操作(以xfs文件系统的磁盘配额为例)
以下命令是以xfs文件系统为例进行的磁盘配额的相关操作,默认状态的xfs文件系统是支持磁盘配额的,不过没有开启,因此需要先在文件【/etc/fstab】中进行相应的配置。样例配置如下。只是一个样例,不一定非要这么配置,要依情况而定。
![]()
注意上图中的grpquota参数与prjquota参数不能同时存在。
- 列出目前系统的各个文件系统,以及文件系统的磁盘配额挂载参数支持:xfs_quota -x -c “print”(-x选项表示进入专家模式,-c选项只有使用了-x选项才能使用,后面跟命令,print就是其中一个命令,打印主机内文件系统参数有关的一些信息)。
如下图所示。

- 列出某个支持磁盘配额的挂载点的使用情况:xfs_quota -x -c “df -h” 挂载点目录。
如下图所示。

- 查看某个挂载点目录下的所有用户的磁盘配额限制值:xfs_quota -x -c "report -ubih 挂载点目录名(-u选项表示用户,-g选项表示用户组)。
如下图所示。
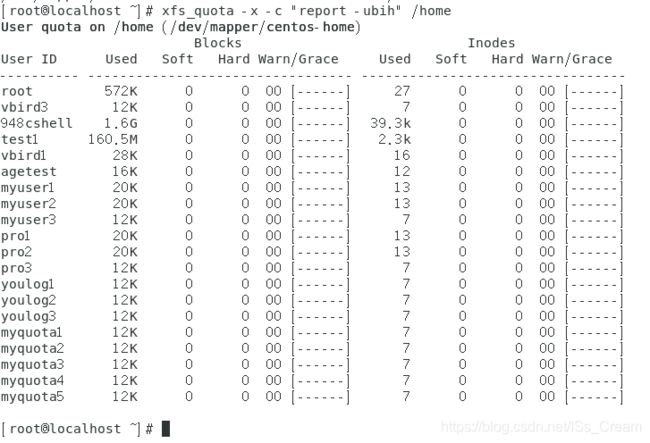
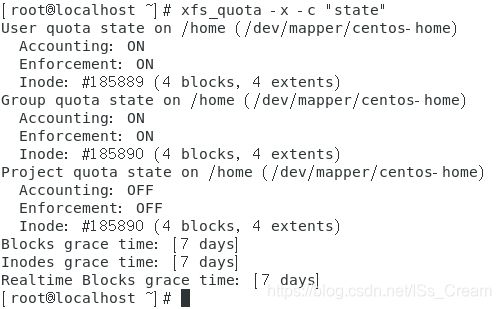
上图中的blocks表示blocks容量的限制,inodes表示文件数量的限制。 - 查看目前支持磁盘配额的文件系统是否启动了磁盘配额功能:xfs_quota -x -c “state”。
如果要查看某一被挂载的目录,可以使用命令【xfs_quota -x -c “state” 挂载目录名】。
如下图所示。
- 设置用户对于挂载点目录的block限制值:xfs_quota -x -c “limit -u bsoft=数字1M bhard=数字2M 用户名” 挂载点目录。
上图中数字后面的M是单位。
例子如下图所示。

- 设置用户组对于某个挂载点目录的block限制值(前提必须开启了用户组的磁盘配额功能):xfs_quota -x -c “limit -g bsoft=数字1M bhard=数字2G 用户组名” 挂载点目录名。
例子如下图所示。

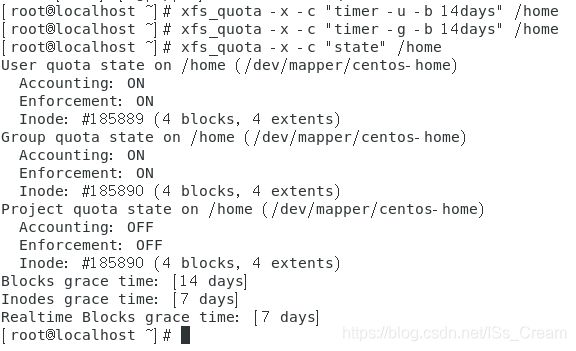
- 设置用户组和用户对于某个挂载点目录的磁盘配额限制超过soft的grace time为14天:xfs_quota -x -c “timer -u -b 14days” 挂载点目录名 ; xfs_quota -x -c “timer -g -b 14days” 挂载点目录名。
例子如下图所示。
- 例子:对家目录的子目录【/home/myquota】进行磁盘配额的设置,设置blocks的soft为450M,hard为500M,并进行测试。
第一步修改文件【/etc/fstab】中的配置。

参数prjquota不能和参数grpquota并存,保存后卸载目录【/home】之后重新挂载让配置文件【/etc/fstab】生效。
第二步规范目录、选项名称与选项标示符
如果要对某个非挂载点目录进行磁盘配额的设置,需要对两个文件进行配置,一个是【/etc/projects】和【/etc/projid】,在这两个文件中配置目标目录的选项名称和选项标示符,选项名称和选项标示符需要用户自行指定。
首先配置文件【/etc/projects】。配置项的格式为【选项标识符:目标目录】。如下图。

接下来配置文件【/etc/projid】。配置项格式为【选项名称:选项标识符】。如下图所示。

之后初始化方案名称。

查看是否配置成功。

第三步实际设置目标目录的磁盘配额。如下图所示。
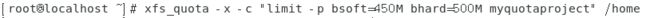
查看设置结果。

最终测试设置效果。

发现就算以root身份读入超过500M大小的文件也会报错。 - 暂时关闭某个挂载点目录的磁盘配额:xfs_quota -x -c “disable -up” 挂载点目录。
如下图所示。
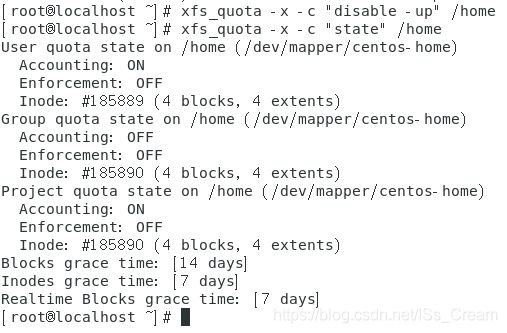
从上图中可以看出,Enforcement变成了OFF,磁盘配额的限制还是存在的,只是不会强制执行而以。
具体的测试如下图。
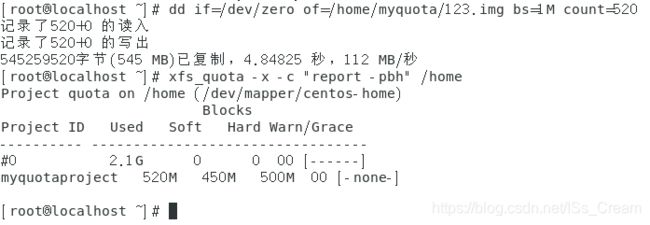
从上图可以看出之前设置的hard是500M,可是已经复制了超过500M的大小的文件也不会出现任何警告。
如果要重新启动磁盘配额需要使用命令【xfs_quota -x -c “enable -up” 挂载点目录】。如下图所示。

- 关闭某个挂载目录的磁盘配额功能:xfs_quota -x -c “off -up” 挂载目录名。
对于支持磁盘配额的xfs文件系统,如果要使用磁盘配额需要将其开启,上述命令就是将其关闭,如果想要将其恢复,可以先卸载,再将其挂载,或者重启。 - 删除project设置,针对挂载点目录中的非挂载目录:xfs_quota -x -c “remove -p” 挂载目录名(内置命令remove中的-p选项指的是project设置)。
以上命令删除了project设置之后如果想恢复需要一个一个重新设置,删除前三思。
88、关于软件磁盘阵列的操作。
-
创建一个软件磁盘阵列并将其格式化与挂载使用:案例如下。
案例的RAID 5级别的软件磁盘阵列的环境为:利用4个分区组成RAID 5。每个分区大小是1G,需确定每个分区一样大较佳。将1个分区设置为热备份磁盘。chunk设置为256KB这么大即可。这个热备份磁盘的大小与其他RAID所需分区一样大。将RAID 5设备挂载到目录【/srv/raid】下。
第一步:创建5个分区。如果是GPT格式的分区表,使用gdisk命令进行分区。分完之后如下图所示。
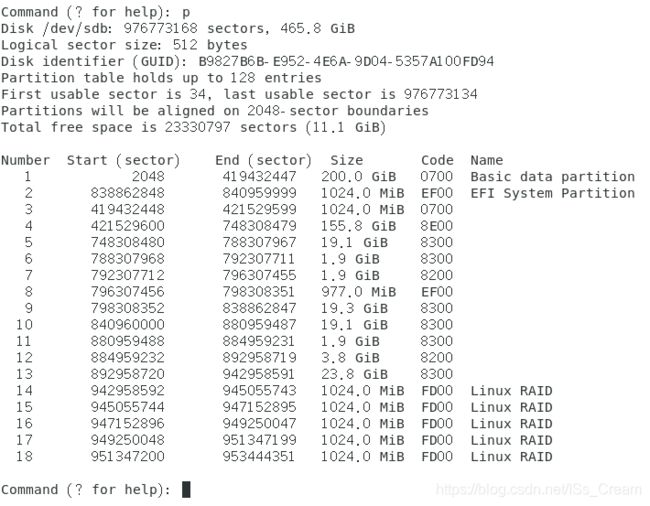

第二步使用mdadm命令创建RAID。如下图所示。

上图中的最后大括号内的14~18是分区编号,从第一步的图中可以看出。关于mdadm的参数参考【导学e479】。到此磁盘阵列的创建已经成功了。
列出刚刚创建的软件磁盘阵列的详细信息,如下图。

还可以通过查看内存中的文件【/proc/mdstat】文件来显示正在运行的软件磁盘阵列信息。如下图。

上图中的第二行分区后面有【(S)】的表示这是用来备份的。第三行的【[4/4]】表示此磁盘阵列需要4个设备,其中有4个设备正常运行,后面的【[UUUU]】中的U表示正常运行的意思,如果是不正常运行则会是【_】。
第三步,格式化软件磁盘阵列并使用。如下图。
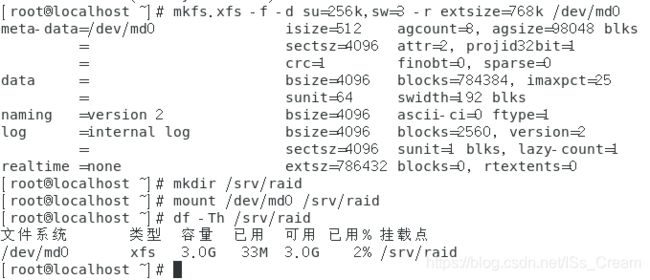
关于上图中的命令【mkfs.xfs】的使用参考【导学a240】。到此完成了软件磁盘阵列的挂载使用。 -
模拟RAID错误的恢复模式
1、模拟软件磁盘阵列出错并恢复的案例(以14.2.3创建的软件磁盘阵列为例)。
第一步:设置磁盘为错误。
先复制一些数据到软件磁盘阵列挂载的的目录中。如下图所示。

可以看到上图中的目录已经存入了数据。
假设分区【/dev/sdb14】出错了,将分区【/dev/sdb14】设置为出错状态模拟出现了错误。如下图所示。
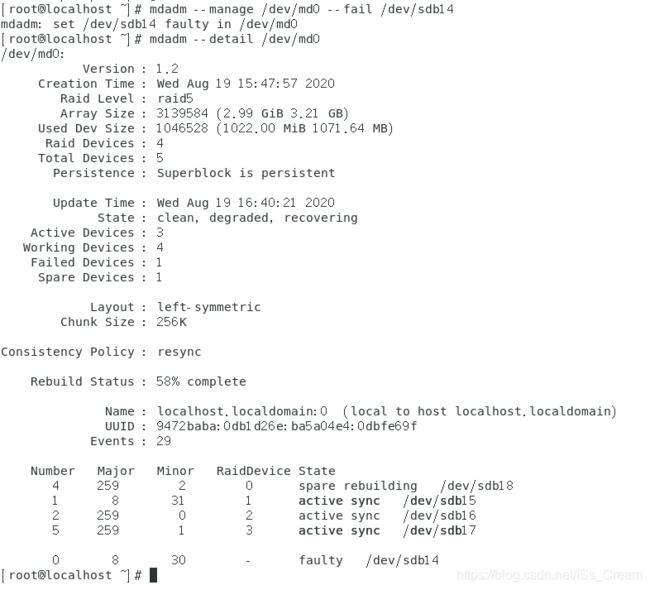
上图中可以看到【Failed Devices】变成了1,然后从最后一行可以看出原来是热备份的分区,现在顶替了坏掉的分区14,状态是【spare rebuilding】。热备份磁盘重建完毕后会出现下图。

上图中的热备份已经变为了活跃状态。
第二步:将出错的磁盘删除并加入新磁盘。
先从软件磁盘阵列中删除坏掉的磁盘或分区。如下图。

由于操作目标是分区,所以不需要关机更换磁盘。如果是磁盘坏掉了,在移除出磁盘阵列之后,需要更换磁盘。
将新的磁盘加入到磁盘阵列中,设备名一般还是和之前移出的设备名相同。如下图所示。
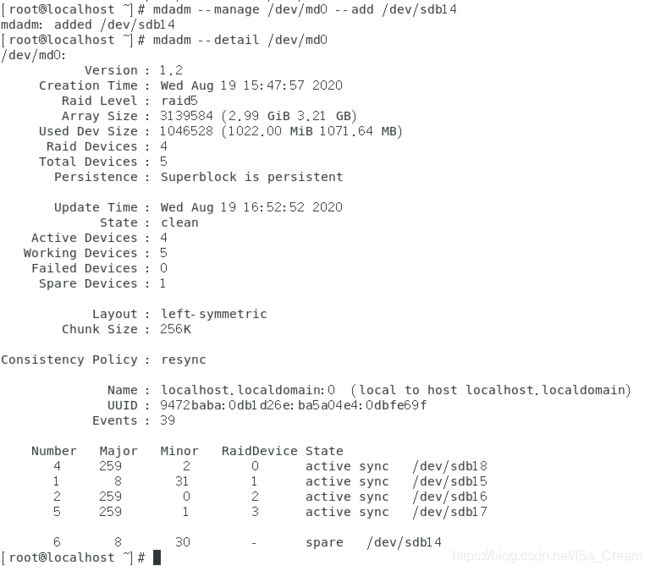
将新的完好的分区或磁盘作为备份,如上图最后一行所示。
- 开机自动启动RAID并自动挂载
1、设置开机自动启动RAID并自动挂载(以14.2.3创建的磁盘阵列为例)。
第一步:获得磁盘阵列的UUID。如下图。

第二步:配置文件【/etc/mdadm.conf】。如下图。

第三步:配置文件【/etc/fstab】。如下图。

通过vim配置文件【/etc/fstab】中的内容,在最后一行加上如下图内容。


从上图中可以看出顺利挂载了。 - 将不需要的软件磁盘阵列删除:承接上面的案例。
第一步:先卸载,并且将文件【/etc/fstab】中的对应的信息删除。如下图所示。

第二步:覆盖掉RAID的metadata以及XFS的超级块,之后在关闭【/dev/md0】,这里覆盖使用命令【dd】。如下图。

通过查看文件【/proc/mdstat】可以发现,已经将磁盘阵列删除了。如下图。

第四部:将文件【/etc/mdadm.conf】中的对应信息删除即可。
89、关于LVM的相关操作
-
通过LVM创建LV并格式化挂载使用:例子,建立一个名为vbirdvg的卷组,在这个卷组中划出一个名为vbirdlv的分区,并将其挂载到目录【/srv/lvm】。
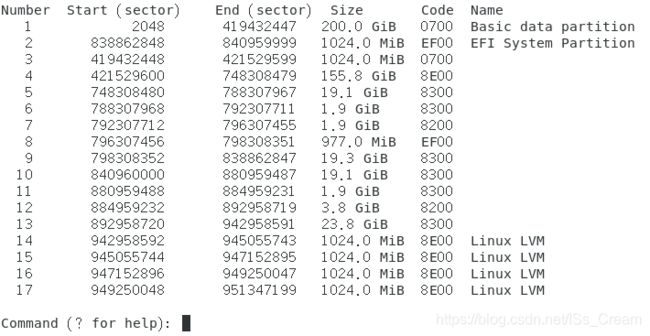
第一步:disk阶段,即实际的磁盘。
使用命令gdisk随便划分5个分区,将他们的分区编码设置为8e00,即Linux LVM。如下图,分区14到17所示。
第二步:PV阶段,将分区变成物理卷。
使用到的命令有如下:
pvcreate:将物理分区建立为物理卷(PV)。
pvscan:查找目前系统里面任何具有物理卷(PV)的磁盘。
pvdisplay:显示出目前系统上面的PV状态。
pvremove:将PV属性移除,让该分区不具有PV属性。
具体操作如下。
先扫描看系统中有没有PV。如下图。

从上图中可以发现有一个PV存在,这是系统安装时候创建的。
将第一步划分的物理分区(分区14到17)建立成为PV。如下图。

上图中利用大括号,一口气创建了4个PV。再进行一次PV的扫描,如下图。

上图中检索到了刚刚创建的4个分区。
可以查看更加详细的PV的状态信息。下面以分区【/dev/sdb14】举例。
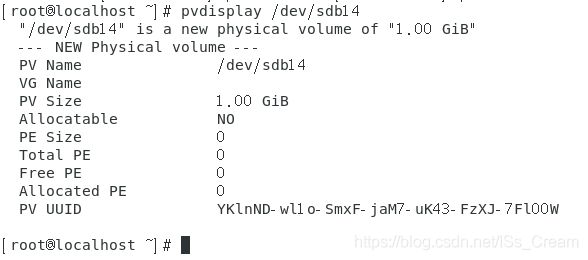
Allocatable字段表示是否被分配,NO表示没有被分配,PE Size表示一个PE的大小,Total PE表示PV共分了多少个PE出来,Free PE表示未被LV用掉的PE数量,Allocated PE表示尚可分配出去的PE数量。这些有关PE的字段的信息会在将该PV分配给VG时进行更新。
第三步:VG阶段,创建VG大磁盘
使用到的命令如下:
vgcreate:主要建立VG的命令。
vgscan:查找系统上面是否有VG存在。
vgdisplay:显示目前系统上面的VG状态。
vgextend:在VG内增加额外的PV。
vgreduce:在VG内删除PV。
vgchange:设置VG是否启动。
vgremove:删除一个VG。
具体操作如下。
创建一个VG。如下图。

上图中命令【vgcreate】的选项【-s】后面跟一个数字用来指定PE的大小(单位是m,g,t),倒数第二个参数是自定义的VG名称(vbirdvg),最后一个参数是用到的PV名称。
查看系统中的有多少VG。

从上图中查看到了刚刚创建的vbirdvg。之后在扫描以下系统中所有的PV,如下图。

可以发现上图中的PV14到PV16都属于名称为vbirdvg的卷组(VG),这是在创建卷组vbirdvg时指定的。
查看vbirdvg卷组的详细信息。
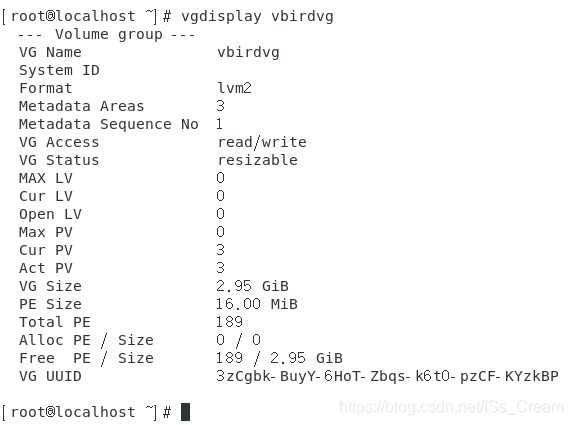
从上图中可以看出,字段PE Size的大小时16M,这是创建时指定的,Total PE表示总的PE数目,Free PE表示商可配置给LV的PE数量,由于目前还没有建立LV,所以PE可自由使用。PE是在建立卷组后自动创建的。
可以查看以下分配给卷组的物理卷的详细信息,如下图。
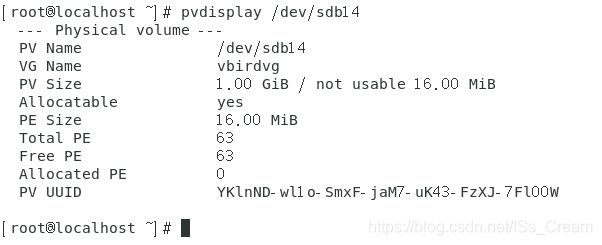
刚创建PV的时候字段Total PE等都是0,由于没有分配给卷组,当分配给卷组后就会有PE的数目了。
可以对一个创建好的卷组进行容量的扩充。如下图。
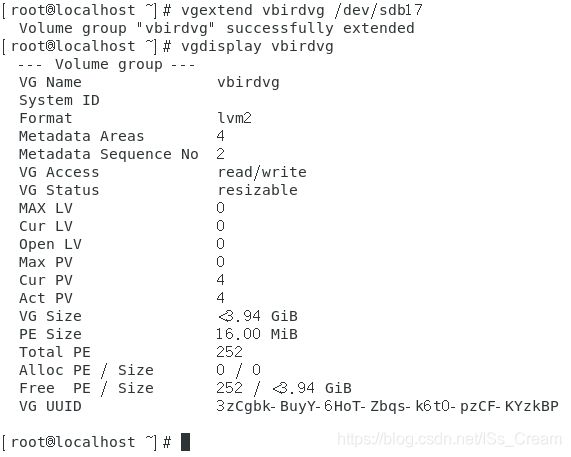
上图中的命令vgextend后面一个参数是卷组,最后面一个参数是被加入的PV。
第三步:LV阶段,对大磁盘VG进行分区(LV)
使用的命令如下:
lvcreate:建立LV。
lvscan:查询系统上面的LV。
lvdisplay:显示系统上面的LV状态。
lvextend:在LV里面增加容量。
lvreduce:在LV里面减少容量。
lvremove:删除一个LV。
lvresize:对LV进行容量大小的调整。
具体操作如下。
在一个已经创建好的卷组中创键一个LV分区。如下图。

上图中命令lvcreate的选项-L后面跟数字用来指定划分的LV分区的大小,该倒数第二个选项是要创建的LV分区的名称,最后一个参数是被划分的已经创建的卷组。
查看系统中所有的LV分区。如下图。
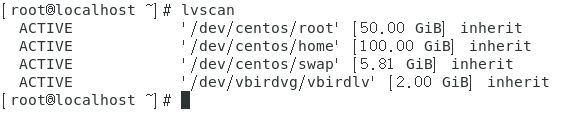
可以看到刚刚创建的LV分区vbirdlv处于活跃状态。
查看LV分区vbirdlv的详细信息。如下图。

上图中可以看出这个LV分区的大小时2G。
第四步:文件系统阶段,将LV分区格式化并挂载。
进行xfs文件系统的格式化。如下图。

将其进行挂载。如下图。

测试是否可以使用。如下图。

从上图可以看出,的确可以使用。 -
放大文件系统容量:比如给上个案例的目录【/srv/lvm】增加500MB的容量。
第一步:查看卷组【vbirdvg】有多少容量。如下图。

从上图可以看出卷组的容量足够500M,可以直接放大LV分区的大小。
第二步:放大LV,利用命令lvresize来增加。如下图。

从上图可以看出原来vbirdlv分区是2G,放大后变成了2.5G了。虽然LV分区放大到了2.5G,可是可以发现文件系统并没有增加容量。如下图,依然还是2G大小。

第三步:增加文件系统的容量。
先查看以下文件系统的信息。如下图。

增加文件系统的大小,使用命令【xfs_growfs】命令。如下图。

发现容量变成了2.5G了。 -
磁盘容量存储池(LVM thin Volume)使用范例。
范例内容:将上面例子中创建出来的卷组vbirdvg的剩余容量取出1GB来做出一个名为vbirdtpool的thin pool LV设备,这就是所谓的磁盘容量存储池,由vbirdvg内的vbirdtpool产生一个名为vbirdthin1的10GB LV设备,将此设备格式化未xfs文件系统,并且挂载于目录【/srv/thin】。
第一步:使用命令lvcreate建立一个vbirdtpool的thin pool设备。

上图中命令lvcreate的选项-T表示创建一个磁盘容量存储池,该选项后面跟的参数格式为【卷组名/待创建的磁盘容量存储池名称】。
显示一下磁盘容量存储池的详细信息。如下图。
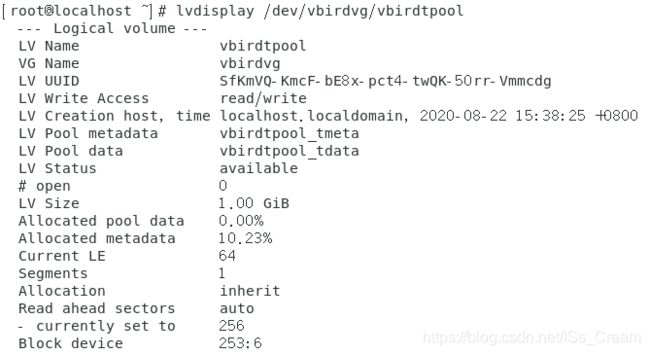
从上图中可以看到还有Allocated的选项,这是存储池的标志。或者可以更加直观的看一下,如下图。
 第二步:建立vbirdthin1这个有10GB的设备,必须使用–thin(即-T选项)与vbirdtpool链接。如下图。
第二步:建立vbirdthin1这个有10GB的设备,必须使用–thin(即-T选项)与vbirdtpool链接。如下图。

从上图中可以看出明明没有10G以上的容量,可是却能够通过thin pool进行创建。上图中的lvcreate命令的-V选项用来指定虚拟容量,经常和和-T选项连用,-n选项是指定创建的设备的文件名。
第三步:建立文件系统。如下图。
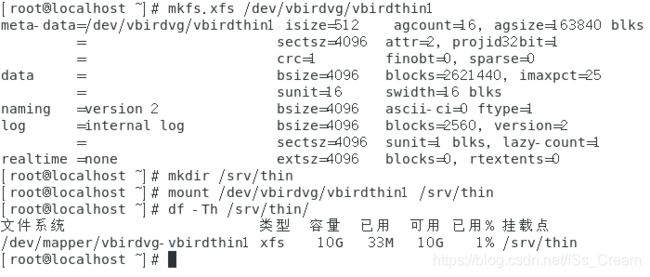
可以看到虽然真实容量只有1G,可是文件系统信息显示却有10G。
第四步:测试容量的使用情况。如下图。
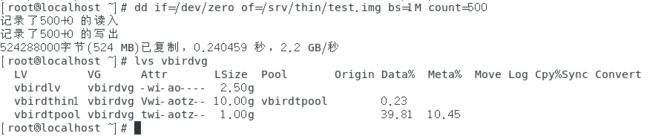
从上图中可以看出设备vbirdthin1只使用了0.23%的容量(应该是5%左右才对,不知道为什么会这样),而存储池用了39.81%(应该是50%左右才对),毕竟只有1G。如果往存储池增加容量,可以看到下图的情况。

从上图中可以看出存储池的容量使用率变成25%左右了,而在存储池基础上创建的设备还是5%左右。 -
建立LV快照区给上面例子中的逻辑卷vbirdlv作备份。
第一步:查看卷组vbirdvg还剩下多少容量。如下图。
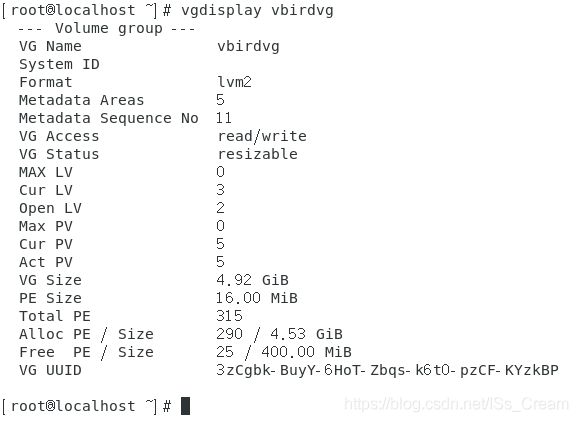
从上图中可以看出只剩下25PE了。
第二步:利用lvcreate建立逻辑卷vbirdlv的快照区,命名为vbirdsnap1,且给予25个PE。如下图。

上图中的lvcreate命令的-s选项表示创建的是一个快照文件的意思,-l选项后面跟一个数字,表示使用多少个PE的意思,-n选项用来指定创建的快照的名称,最后一个参数是创建快照的目标文件。查看一下快照的详细信息,如下图。

上图中的LV Size表示原始文件的大小,在这里的例子中指的是vbirdlv的大小,COW-table size是快照可以记录的最大容量,Allocated to snapshot是目前已经被用掉的容量。将快照文件进行挂载,查看文件系统的信息。如下图。

从上图中的可以看出被快照的文件与快照文件是一样的,这里有个细节就是在挂载快照文件的时候由于快照文件与被快照的文件拥有相同的uuid所以在使用挂载命令mount的时侯要忽略相同uuid的影响。 -
使用快照功能恢复系统的例子,拿上面案例的逻辑卷vbirdlv和它的快照vbirdsnap1举例。
第一步:将逻辑卷vbirdlv做一点修改。注意修改的容量不要超过快照文件的大小。
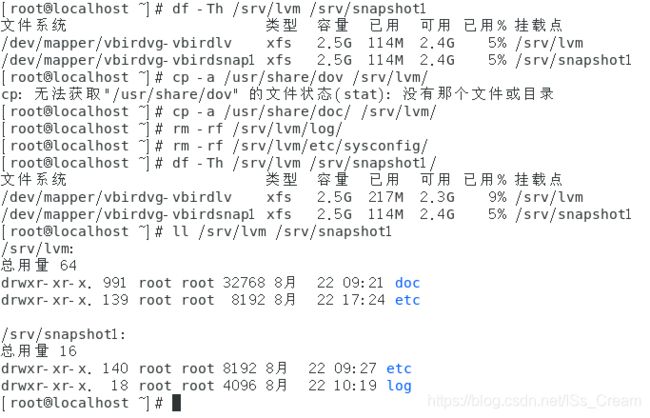
经过修改之后可以发现这两个文件已经是不一样的了。检测一下快照文件,如下图所示。
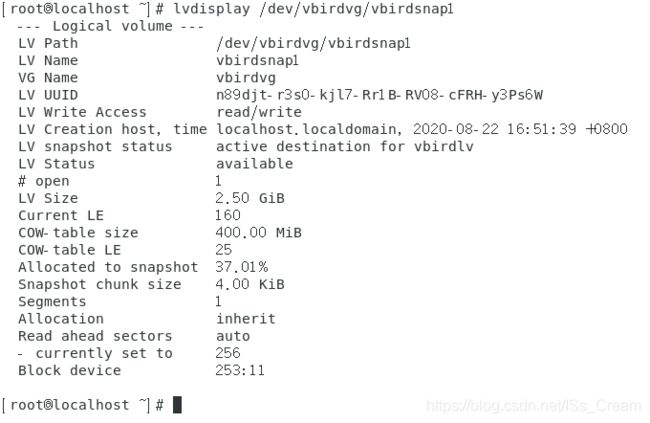
从上图中可以发现快照已经使用了37%左右的容量。
第二步:利用快照将原来的文件系统进行备份,使用命令xfsdump。如下图。
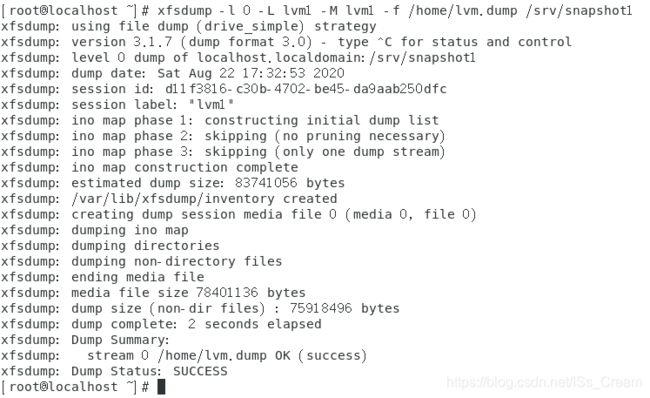
从上图中可以看出成功根据快照创建了vbirdlv的备份文件【/home/lvm.dump】文件。
第三步:删除快照vbirdsnap1,因为备份文件已经建立了,之后恢复逻辑卷vbirdlv对应的文件。
删除快照。如下图。

之后将逻辑卷vbirdlv重新格式化。如下图。
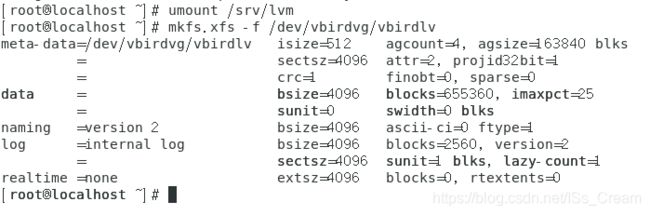
将vbirdlv设备重新挂载,并进行数据的恢复。如下图。
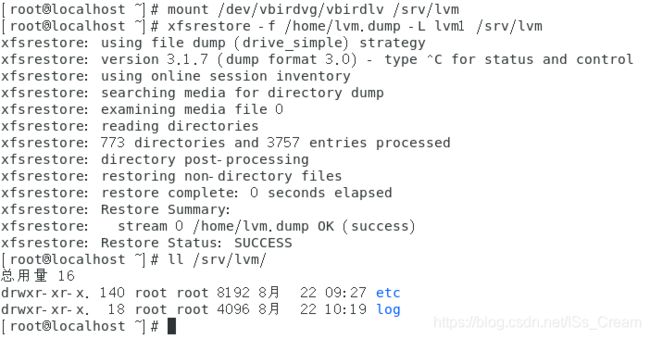
可以看到,已经恢复成功了。
补充一点:在进行数据的测试时,可以将快照区作为测试用的文件,原系统作为备份数据,这样子就算搞砸了,直接将快照删了,在根据原系统建一个新的快照就行,非常的方便。 -
删除系统中的某LVM:以删除上面建立的LV、VG和PV为例。
删除LVM的流程如下:
先卸载系统上面的LVM文件系统(包括快照和所有的LV)。
使用lvremove删除LV。
使用vgchange -a n VGname让该卷组不具有Active标志。
使用vgremove删除VG。
使用pvremove删除PV。
最后使用gdisk或者fdisk将分区的System ID改回来。
具体操作如下图。

删除存储池,存储上的设备,逻辑卷的顺序是:存储池、存储上的设备、逻辑卷(快照之前已经删了,如果还有快照也要删除)。
接下来将分区的System ID改回来就行了。如下图。
90、实际运行单一计划任务
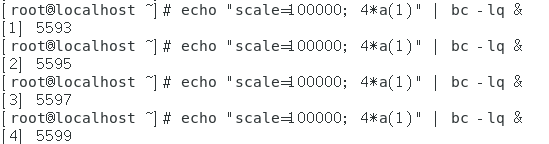
- 从当前时刻开始,再过5分钟将文件【/root/.bashrc】发送给用户【root】:命令【at】的范例。
在at命令的at shell环境中如果要使用路径的话,最好使用绝对路径,包括要用到的bash命令也要使用绝对路径。at命令的执行与终端环境是无关的,所有的标准输出和标准错误输出都会发送到执行者的mailbox中,在终端看不到任何信息,并且at命令执行完命令也不会通知其使用的用户,如果要想让at命令在执行完通知其用户可以加入-m选项,让at命令执行完后向执行at命令的用户发送邮件。

从上图中可以发现,执行at命令后会进入at的at shell环境中,按【ctrl + d】可以进行退出。job 1表示第一个任务,后面的时间是任务执行的时间,在这个时间,的确执行了at设置的任务,如下图。

- 查看某个编号为【n】的任务内容:at -c 编号n(-c选项后面跟任务编号,可以列出该任务的详细内容)。
如下图所示。

上图中最重要的是下图中的内容。

- 设置某个时间定时关机:at 指定的时间(之后进入at shell环境编写关机命令)。
范例,如下图。

从上图中可以看出,at的at shell中可以执行多个bash命令。 - 列出目前所有的at任务:atq。
如下图所示。

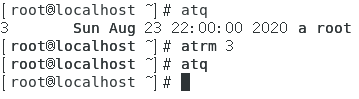
- 删除某个at任务:atrm 任务编号。
如下图所示。
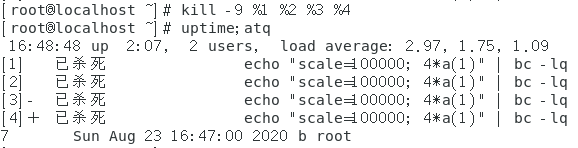
如上图所示,使用命令atq查看目前有一个at任务,任务编号是3,使用atrm将其删除,然后在使用atq命令查看,发现其已经被删除了。 - 使用batch命令让at命令设置的任务在系统比较空闲的时候运行。
batch命令实际上就是at命令,只不过他可以检测执行at命令设置的任务时系统是否空闲,如果空闲,那么便执行命令,如果系统不空闲,那么将会延时执行任务。batch判定系统空闲的方式是通过判定系统的任务负载是否低于0.8,任务负载是指CPU在一个时间点执行的任务数,如果CPU需要一直进行一个计算任务,此时的CPU使用率可能达到100%,CPU任务负载趋近于1,如果有两个这样的任务,那么CPU的任务负载就会趋近于2。batch命令不再支持时间参数。
下面是一个测试batch命令执行效果的案例。
先通过让系统计算pi的值让系统负载变高。如下图。
使用uptime命令查看系统负载的相关信息,如下图。

上图中每一行的倒数大三个参数表示最近一分钟系统的负载,可以发现超过了0.8。
使用batch命令设置任务。如下图。

从上图中可以发现,应该在16:47:00执行的任务在16:47:54还没有执行,因为现在系统比较忙碌。
使用命令jobs查看当前作业的情况。如下图。

从上图中可以看出这4个任务都在执行,将他们杀死让系统空闲下来。如下图。
不断查询系统的负载,和任务执行情况。如下图。

发现任务在16:52:12的时候得到了执行。这时系统空闲。
91、查看系统启动时间与任务负载
- 查看系统启动时间与任务负载:uptime。
效果如下图所示。

倒数三个参数从左到右分别是最近1分钟、5分钟、15分钟的负载。
92、任务管理相关的操作
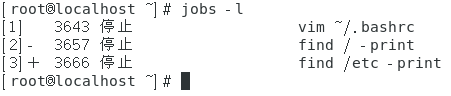
- 显示目前所有的后台任务:jobs。
可以在一个命令后面加上一个【&】将该命令放到后台去执行,如【命令 &】。可以通过组合按键【ctrl + z】将一个前台任务放到后台并将其置于暂停状态。这些放入后台的任务都可以通过jobs命令进行查看。
效果如下图所示。

上图中第一个方括号中的编号是后台任务的任务号,任务号后面如果有【+】,表示这个任务是最近被放入后台的任务,如果有【-】,表示这是最近第二个被放置到后台中的任务号。
如果没有作业的话jobs命令什么都不会输出。 - 显示目前所有的后台任务并显示他们的PID:jobs -l(-l选项表示显示出该命令的PID)。
效果如下图所示。
上图中停止这一栏前面的号码就是PID。 - 将某个后台任务拿到前台来运行:fg %任务号 或者 fg 任务号 或者 fg 或者 fg -。
【fg %任务号 或者 fg 任务号】可以将指定的后台任务拿到前台来运行。
【fg】会默认将最近被加入后台的任务,即含有【+】的任务,拿到前台来运行。
【fg -】会将最近第二个放置到后台的任务,即含有【-】的任务,拿到前台来运行。 - 让某个后台任务的状态变成运行态:bg %任务号(【%】尽量别省略)。
我估计应该也可以使用【+】和【-】来指定是哪个后台任务。
效果图如下。

从上图中可以看出,使用bg命令将原来被停止的3号任务变为运行态,并且相关的命令后面多了一个【&】表示这是在后台进行运行。 - 强制删除一个后台任务:kill -9 %任务号(-9选项是一个信号,表示立即强制删除一个任务)
kill命令所有的信号可通过命令【kill -l】来显示出来。如下图。

信号【-9】应该在实在是不知道如何终止后台任务时才使用,不然应该用正常的方式让任务终止,即使用默认的信号【-15】。
如果kill后面想要跟任务号,一定要带【%】,因为kill命令后面直接跟数字的话,这个数字值的时进程的PID。
命令【kill -9 %任务号】的执行效果如下图。
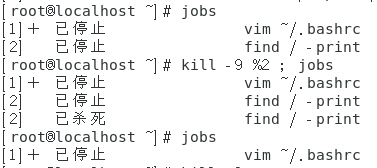
从上图中可以看出任务2被强制删除了。 - 让某个后台任务正常终止:kill -15 %任务号(-15选项可以省略,因为其是默认值)。
- 让某个外部命令(非bash内置命令)在系统的后台执行:nohup 命令 &。
如果直接使用【命令 &】将命令放置到后台运行,这个后台指的时bash的后台,如果是通过远程连接登陆主机,此时发生了脱机(断开连接)或者直接在主机登陆,然后注销帐号,所有的bash后台任务都会停止,因为这两种行为都会导致运行bash的进程的终止,从而导致bash后台的任务也终止(连bash都没了,后台也就不存在了)。如果想要在这种脱机状态或者注销状态让任务继续执行,需要将任务添加到系统后台,可以使用at命令,也可以使用nohup命令,nohup命令比较常用,不过该命令后面跟的命令不能是bash的内置命令,可以是由bash内置命令构成的脚本。如下图中的例子。


上图中编写了一个脚本,脚本中编写在延迟了500s后在终端输出一段话,当运行这个脚本的时候,最后会给出一个说明,因为涉及到标准输出和标准错误输出,由于nohup与终端是无关的,所以不会将标准输出和标准错误输出显示到终端,而是会将他们定向到目录【~/nohup.out】中。
之后登出帐号,再重新登陆。可以看到下图所示。

从上图中可以发现即便是登出之后在登陆,脚本【sleep500.sh】还是在正常执行。
93、循环型计划任务的相关操作。
- 当前用户设定每天12:00发信息给自己:crontab -e(-e选项表示编辑crontab的任务内容,编辑器将使用vi)。
执行这个命令后会进入一个vi界面,可以在这个vi界面中编辑任务的内容,任务包括六个字段的信息分别是【分 时 日 月 周 命令串】,用空格进行分隔,除此之外,这些字段中有的可以使用一些特殊字符,【*】表示任何时刻都接受的意思。【,】代表分隔时段,比如任务执行时3时和6时都要执行,那么任务的第二个字段可以写成【3,6】,【-】表示一段时间范围,比如8时到12时,可以把任务的第二个字段写成【8-12】,【/n】表示每隔n单位间隔的意思,比如每5分钟执行一次可以将任务的第一个字段写成【*/5】。使用vi编辑好的信息会保存到文件【/var/spool/cron/任务归属的用户名】中,
用户设定每天12:00发信息给自己在执行完命令【crontab -e】之后,会进入vi编辑模式,任务编辑如下图。

上图中的任务会保存到文件【/var/spool/cron/948cshell】中,因为是948cshell用户编辑的任务,所以该任务归属于948cshell。 - 查看某个用户的crontab任务内容:crontab -l(查看当前用户) 或者 crontab -u 用户名 -l(查看指定用户)(-l选项会将对应用户的crontab任务列出来,-u选项可以指定一个用户,只有root用户从能够使用该命令)。
- 删除某个用户所有的crontab任务:crontab -r(查看当前用户的) 或者 crontab -u 用户名 -r(查看指定用户的)(-r选项会将所有的crontab任务都删除)
如果只是想删除一个crontab任务,那么不能使用-r选项,这时可以使用编辑命令【crontab -e】,进入vi编辑直接将对应的crontab命令删除即可。
94、进程管理相关的操作
- 仅查看与当前用户自己的bash相关的进程:ps -l(-l选项可以将与当前用户自己的bash有关的信息列出来)。

上图中的各个字段的含义是如下。
其中显示的在终端的是【新PRI】,【新PRI】= 内核指定的【老PRI】 + 【NI】。也就是说内核指定的PRI是不会显示给用户的,不过用户可以根据显示出来的【新PRI】减去【NI】就可以得到内核指定给进程的PRI了。F:代表这个进程旗标 (process flags),说明这个进程的权限,常见有: 若4 表示此进程的权限 root ; 若1 則表示此子进程仅能fork。 S:代表这个进程的状态 (STAT),主要的状态有: R (Running):该进程正在运行; S (Sleep):该进程正在睡眠,可被唤醒。 D :不可被唤醒 T :停止状态(stop); Z (Zombie):僵尸进程。 UID/PID/PPID:代表【此进程被该 UID 所拥有/进程的 PID 号/此进程的父进程 PID 】 C:代表 CPU 使用率,单位为百分比; PRI/NI:Priority/Nice 的缩写,代表此进程被 CPU 所执行的优先顺序,数值越小代表该进程越快被 CPU 执行。 ADDR/SZ/WCHAN:都与内存,ADDR 是 kernel function,指出该进程在内存的哪個部分,如果是个 running 进程,一般就会显示【 - 】 ; SZ 代表此进程用掉多少内存 ; WCHAN 表示目前进程是否工作,同样的, 若为 - 表示正在工作中。 TTY:登入者的终端机位置,若为远程登入则使用动态終端介面 (pts/n); TIME:使用掉的 CPU 时间,注意,是实际花费掉的 CPU 运作的时间,而不是系統时间; CMD:就是 command 的缩写,造成此进程的指令。 - 查看系统所有的进程:ps aux 或者 ps -lA(-A选项表示将所有的进程均显示出来,aux前面没有【-】)。
命令【ps aux】如下图所示,只是一部分。
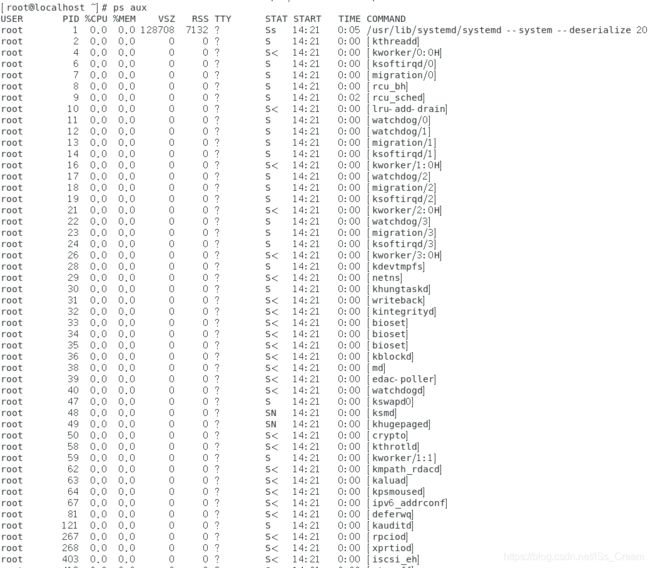
上图中各个字段的含义如下。USER: 进程所属的用户名。 PID: pid。 %CPU: 进程用掉的 CPU 资源百分比。 %MEM: 该进程所占用的物理内存百分比。 VSZ: 该进程使用掉的虚拟内存量。 RSS: 该进程占用的固定内存量。 TTY: 该进程是哪个终端上面运行的,若与终端无关则显示【?】,tty1~tty6是本机上的登陆进程,若为pts/0等,则表示是由网络连接进入主机的进程。 STAT: 该行程的状态,linux的进程有5种状态: D 不可中断 uninterruptible sleep (usually IO) R 运行 runnable (on run queue) S 中断 sleeping T 停止 traced or stopped Z 僵死 a defunct (”zombie”) process 注: 其它状态还包括W(无驻留页), <(高优先级进程), N(低优先级进程), L(内存锁页). START: 进程开始时间(即,进程被出发启动的时间) TIME: 执行的时间(该进程实际使用CPU运行的时间) COMMAND:所执行的指令(即,该进程的实际命令是什么)
命令【ps -lA】如下图所示,只是一部分。
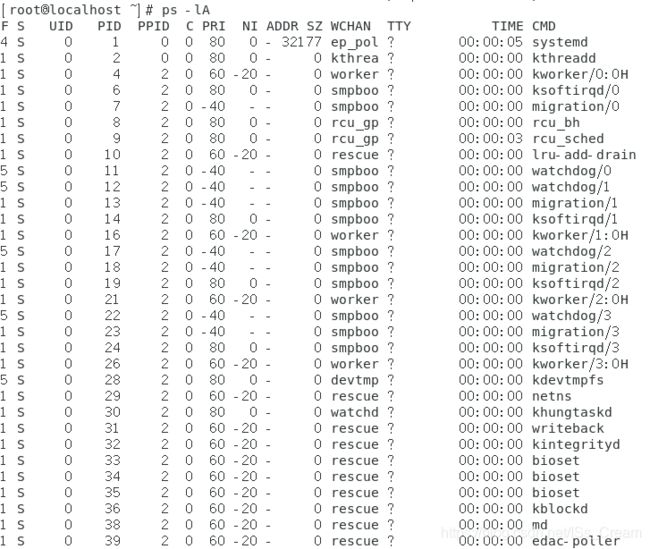
-
将进程信息以类似进程树的方式显示出来:ps axjf(axjf前面没有【-】)。
效果如下图所示,部分截图。

从上图中可以看出进程之间的相关性,以及父子进程的关系。 -
查看所有的进程并显示他们SELinux的安全上下文:ps -AZ。
效果如下图所示。

-
动态显示进程信息,每n秒刷新一次:top -d n(-d选项后面指定每隔几秒刷新一次top显示进程信息的界面,默认是5秒)。
大致的信息如下图所示。
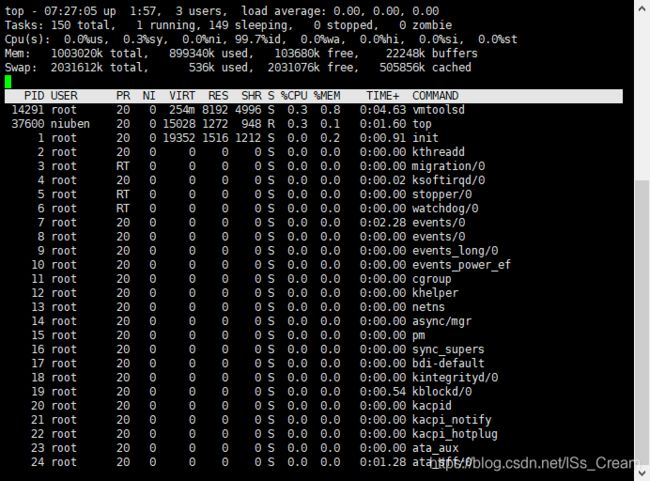
上图中每一行的信息如下。
第一行,任务队列信息,同 uptime 命令的执行结果。系统时间:07:27:05 运行时间:up 1:57 min, 当前登录用户: 3 user 负载均衡(uptime) load average: 0.00, 0.00, 0.00 average后面的三个数分别是1分钟、5分钟、15分钟的负载情况。 load average数据是每隔5秒钟检查一次活跃的进程数,然后按特定算法计算出的数值。如果这个数除以逻辑CPU的数量,结果高于5的时候就表明系统在超负荷运转了第二行,Tasks — 任务(进程)。
总进程:150 total, 运行:1 running, 休眠:149 sleeping, 停止: 0 stopped, 僵尸进程: 0 zombie第三行,cpu状态信息。
0.0%us【user space】— 用户空间占用CPU的百分比。 0.3%sy【sysctl】— 内核空间占用CPU的百分比。 0.0%ni【】— 改变过优先级的进程占用CPU的百分比 99.7%id【idolt】— 空闲CPU百分比 0.0%wa【wait】— IO等待占用CPU的百分比 0.0%hi【Hardware IRQ】— 硬中断占用CPU的百分比 0.0%si【Software Interrupts】— 软中断占用CPU的百分比第四行,内存状态。
1003020k total, 234464k used, 777824k free, 24084k buffers【缓存的内存量】第五行,swap交换分区信息
2031612k total, 536k used, 2031076k free, 505864k cached【缓冲的交换区总量】 备注: 可用内存=free + buffer + cached 对于内存监控,在top里我们要时刻监控第五行swap交换分区的used,如果这个数值在不断的变化,说明内核在不断进行内存和swap的数据交换,这是真正的内存不够用了。 第四行中使用中的内存总量(used)指的是现在系统内核控制的内存数, 第四行中空闲内存总量(free)是内核还未纳入其管控范围的数量。 纳入内核管理的内存不见得都在使用中,还包括过去使用过的现在可以被重复利用的内存,内核并不把这些可被重新使用的内存交还到free中去,因此在linux上free内存会越来越少,但不用为此担心。第六行,空行
第七行以下:各进程(任务)的状态监控PID — 进程id USER — 进程所有者 PR — 进程优先级 NI — nice值。负值表示高优先级,正值表示低优先级 VIRT — 进程使用的虚拟内存总量,单位kb。VIRT=SWAP+RES RES — 进程使用的、未被换出的物理内存大小,单位kb。RES=CODE+DATA SHR — 共享内存大小,单位kb S —进程状态。D=不可中断的睡眠状态 R=运行 S=睡眠 T=跟踪/停止 Z=僵尸进程 %CPU — 上次更新到现在的CPU时间占用百分比 %MEM — 进程使用的物理内存百分比 TIME+ — 进程使用的CPU时间总计,单位1/100秒 COMMAND — 进程名称(命令名/命令行)如果想要让top中的进程按照CPU使用率、内存使用率、PID或者进程使用CPU总时间进行排序的话可以分别按下按键【P】、【M】、【N】或者【T】。可以通过按键【?】查看top界面还有哪些可以使用的按键。退出top界面可以通过按键【q】。
-
将top显示的进程信息刷新n次,将结果重定向到一个文件中:top -b -n n(数字n) > 文件名(-b选项表示以批量的方式执行top,可以搭配选项-n指定刷新top界面的次数,再搭配数据流重定向【>】将批量处理结果写入到文件中,-b选项很重要,如果没有的话重定向到文件中的进程信息是不全的,只会显示一个屏幕的进程信息,只有加上了-b选项才会将所有的进程信息都重定向到文件中)。
-
每隔n秒持续动态显示某个进程的信息:top -d n -p PID(-p选项后面跟一个PID,持续显示该进程的相关信息)。
例如显示当前用户的bash进程的相关信息。如下图所示。
获取等前用户bash的PID,如下图。

持续显示该进程的相关信息。如下图。

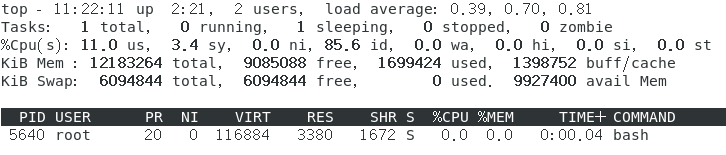
如果还想要修改这个进程的NI(nice)数值,可以在top界面中按下r,之后先输入进程PID回车,在输入想要设置的nice值在回车,就可以修改成功了。 将上图中的进程5640的nice从0改成10,如下图所示。
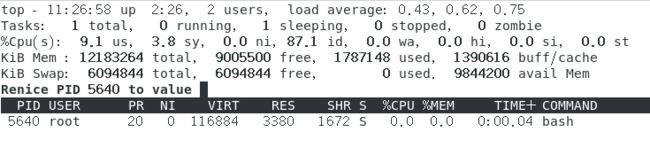
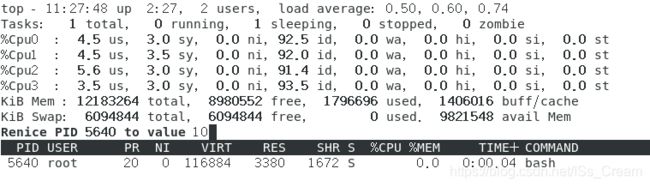

从上图中可以发现已经将其修改成功了,nice值和进程执行的先后顺序有关,越小优先级越高。 -
以进程树的形式显示出系统中进程的相关性,进程之间的连接采用ASCII字符:pstree -A(-A表示指定连接符是ASCII,-U表示指定连接符是Unicode)。
如下图所示。
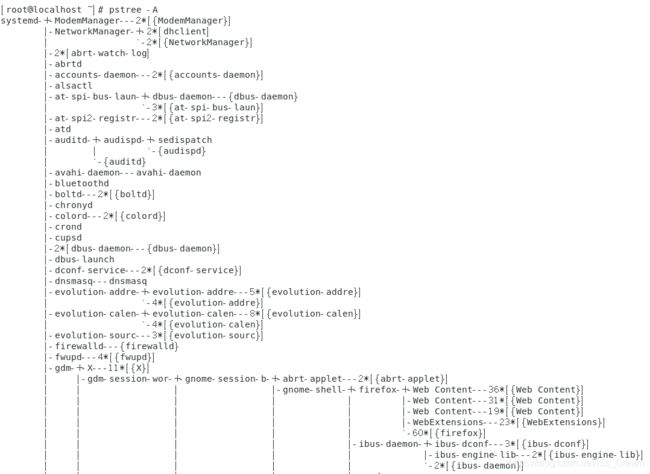
-
以进程树的形式显示出系统中进程的相关性,进程之间的连接采用ASCII字符,同时显示出进程的PID和所属的用户:pstree -Aup(-u和-p选项分别表示显示进程的拥有者和PID)。
如下图所示。

用户名和PID会在一对圆括号内显示出来,两者用逗号进行分隔。 -
先用ps查询某个进程的PID,之后让该进程重新读取自己的配置文件,即类似于重新启动:例子如下图。
先用ps查询进程【rsyslogd】的进程PID,之后让这个服务(名称结尾有d)重新读取配置文件。

上图中让进程重新读取自己的配置文件对应的信号是【SIGHUP】,也就是【-1】,执行完之后查询日志文件,从最后一行的信息可知,服务rsyslogd的确是重起了。 -
将一个信号传递给指定的一个命令(或服务),让该命令(或服务)启动的所有的进程重新加载配置文件,重新启动:killall -1 命令名称或服务名称。
kill命令在使用的时候需要指定对应进程的PID,从而精准的将某个信号给这个进程。而killall命令则是根据命令名称对因这个命令(或者服务)启动的进程进行批量操作。常用在要删除某个服务是,将因这个服务而启动的所有进程都删除。 -
将一个信号传递给指定的一个命令(或服务),删除该命令(或服务)启动的所有的进程:killall -9 命令(或服务)名称。
效果图如下。

上图中欲将bash启动的进程都删除,-i选项用来进行询问,因为一开始我使用普通帐号登陆的,对应一个bash,之后切换到root用户,对应另一个bash,所以上面的命令会询问两次。如果没有-i选项,那么会强制直接删除。 -
执行一个新的命令,并在执行的开始就给它设置一个nice值:nice -n 数字 命令(-n选项后面跟的数字与设置NI值有关,根据该数字算出来的NI值的范围一定是在【-20~19】之间)。
该新命令的最后通过命令【ps -Al】显示在终端的NI值是【默认的NI】加上命令【nice】设置的数字。最终显示在终端的的PRI值是默认的PRI加上最终的NI值。该新执行的命令的默认的PRI值和nice值往往会继承父进程的这两个值。
效果图如下。

上图中命令【nice】后面跟的数字是【-5】,由于是在bash的后台中执行的vim,所以vim默认的PRI和NI继承了bash的【80】和【10】,由于命令【nice】后面的数字是【-5】,所以显示在终端的最终的NI值为【10-5=5】,显示在终端最终的PRI值为默认的PRI加上最终显示在终端的NI值,即【80+5=85】。 -
给一个已经存在的进程进行nice值的重新调整:renice 数值 进程的PID。
可以将一个进程通过命令【ps -Al】显示在终端的NI设置为命令【renice】指定的数值,而不需要进行任何计算。和命令【top】异曲同工。
效果如下图所示。

从上图中可以看出改变了bash这个父进程,子进程ps的NI也跟着改变了。因此可以看出更改进程执行的优先级是具有继承效果的。
95、查看系统与内核相关的信息
- 输出所有系统的基本信息,即包括系统内核名称、内核版本、系统的硬件架构、CPU类型以及硬件平台:uname -a(选项-a可以显示所有的系统信息,除此之外选项-s、-r、-m、-p和-i分别可以显示系统内核名称、内核版本、系统的硬件架构、CPU类型以及硬件平台的信息)。
如下图所示。

96、显示Linux系统启动时的信息 - 输出所有内核启动时的信息:dmesg | more。
由于信息太多,所以搭配more命令来进行查看。信息包括内核启动时的硬件检测有关的信息,还有一些内核运行时会产生的信息,这些信息会保存到内存的某个特殊的区域,命令【dmesg】可以将这个区域的特殊信息读出来。 - 查找启动时,与磁盘有关的信息:dmesg | grep -i ‘磁盘设备名’。
如下图所示。
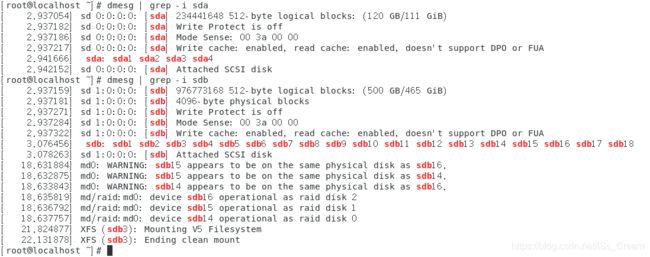
97、检测系统资源的变化
- 统计目前主机的CPU、内存、IO和交换分区等的状态,每n秒刷新一次,共计m次:vmstat n m。
比如每秒刷新一次,共计3次,如下图所示。

如果上图中的命令最后一个【共计多少次m】参数如果不指定的话,会无穷的更新,直到按下【ctrl + c】结束。
上图中各个字段的意思如下。procs r:列表示运行和等待cpu时间片的进程数,如果长期大于1,说明cpu不足,需要增加cpu,即处于就绪态的进程数量。 b:列表示在等待资源的进程数,比如正在等待I/O、或者内存交换等,即处于阻塞态的进程数量。 cpu 表示cpu的使用状态 us:显示了用户方式下所花费 CPU 时间的百分比,即非内核层的CPU使用状态。us的值比较高时,说明用户进程消耗的cpu时间多,但是如果长期大于50%,需要考虑优化用户的程序。 sy:显示了内核进程所花费的cpu时间的百分比,即内核层的CPU使用状态。这里us + sy的参考值为80%,如果us+sy 大于 80%说明可能存在CPU不足。 wa:显示了IO等待所占用的CPU时间的百分比。这里wa的参考值为30%,如果wa超过30%,说明IO等待严重,这可能是磁盘大量随机访问造成的,也可能磁盘或者磁盘访问控制器的带宽瓶颈造成的(主要是块操作)。 id:显示了cpu处在空闲状态的时间百分比。 st:显示被虚拟机所使用的CPU时间百分比。 system in:每秒进程被中断的次数。 cs:每秒执行的上下文切换次数,即线程切换与进程切换次数。例如我们调用系统函数,就要进行上下文切换,线程的切换,也要进程上下文切换,这个值要越小越好,太大了,要考虑调低线程或者进程的数目,例如在apache和nginx这种web服务器中,我们一般做性能测试时会进行几千并发甚至几万并发的测试,选择web服务器的进程可以由进程或者线程的峰值一直下调,压测,直到cs到一个比较小的值,这个进程和线程数就是比较合适的值了。系统调用也是,每次调用系统函数,我们的代码就会进入内核空间,导致上下文切换,这个是很耗资源,也要尽量避免频繁调用系统函数。上下文切换次数过多表示你的CPU大部分浪费在上下文切换,导致CPU干正经事的时间少了,CPU没有充分利用,是不可取的。 注意:进程之间的切换是通过中断来进行的,通过中断保存一些寄存器的数据信息。如果这两个数值比较大,说明IO操作频繁。 memory swpd:切换到内存交换区的内存容量,即虚拟内存被使用的容量。如果swpd的值不为0,或者比较大,比如超过了100m,只要si、so的值长期为0,系统性能还是正常,也就是说系统虽然进程比较多,但不怎么进行进程之间的切换,所以性能也还算可以。 free:未被使用的内存容量。 buff:作为buffer cache的内存数量,一般对块设备的读写才需要缓冲。 cache:作为page cache的内存数量,一般作为文件系统的cache,如果cache较大,说明用到cache的文件较多,如果此时IO中bi比较小,说明文件系统效率比较好。 swap si:进程由内存进入交换区的容量。 so:进程由内存交换区进入内存的容量。 注意:如果si和so的数值太大,表示内存中的数据常常在磁盘与内存之间传输,系统性能会很差。 IO bi:从磁盘(块设备)读入的区块数量。 bo:向磁盘(块设备)写入的区块数量。 如果该部分数值比较高说明,IO比较忙碌,阻塞的进程会很多。 - 显示系统上面所有磁盘的读写状态:vmstat -d(-d选项表示列出磁盘的读写总量统计表)
效果如下图所示。

98、查询已使用文件或已执行进程使用的文件
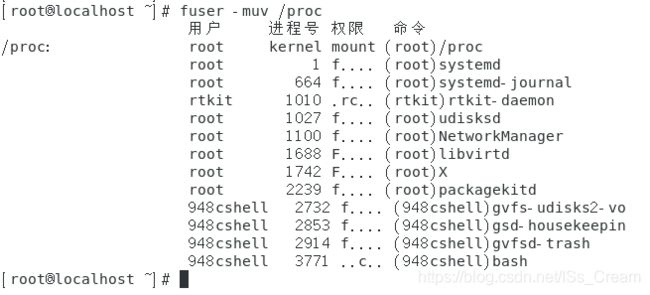
- 查看目前使用某个目录的进程的PID、进程所属的帐号以及权限:fuser -uv 目录名(-u选项表示除了列出进程的PID之外,还列出它的拥有者,可以列出每个文件与进程还有命令的完整相关性)
效果如下图所示。

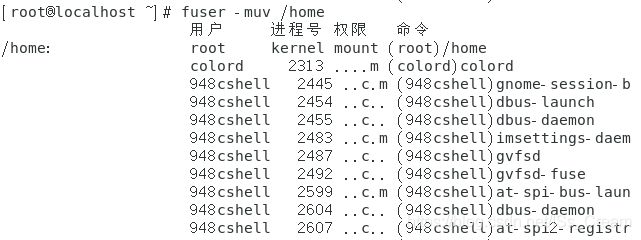
上图中的权限(ACCESS)一栏的解释如下。c:代表当前目录 e:将此文件作为程序的可执行对象使用 f:打开的文件。默认不显示。 F:打开的文件,用于写操作。默认不显示。 r:指示该目录为进程的根目录。 m:指示进程使用该文件进行内存映射,抑或该文件为共享库文件,被进程映射进内存。 s:将此文件作为共享库(或其他可装载对象)使用 - 指定一个已经挂载的文件系统,列出所有使用该文件系统的进程:fuser -muv 挂载目录名(-m选项可以列出所有使用后面指定的挂载目录的进程,注意如果有该选项,后面一定要是挂载目录,就算指定的不是挂载目录,也会显示该目录所属挂载目录的内容)
如下图所示。
- 以信号【-9】的方式杀死所有使用某个文件系统的进程(最好不要这么做):fuser -mki 挂载目录名(-i选项表示询问,-k选项可以将使用该文件系统的进程默认以信号【-9】的方式杀死)
- 查看正在使用某个文件的所有进程(非挂载目录文件):fuser -uv 文件名。
如下如所示。

- 查看目前系统所有已经被开启的文件与设备:lsof。
效果如下图所示。
上图中的内容太多了,截不完。 - 仅列出关于某个用户的所有进程使用的socket文件:lsof -u 用户名 -U -a(-u选项后面跟用户名,用来选出所有的属于该用户的进程,-U选项表示选出类UNIX系统的被打开的socket文件,-a选项是让该命令中出现的选项同时成立,即将每个选项筛选出的结果集进行求交集)。
效果如下图所示。
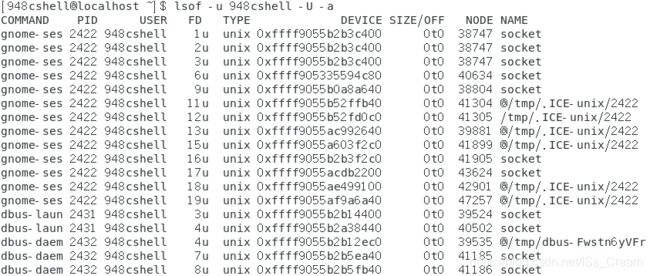
- 列出某个目录下已经被使用的文件或设备:lsof +d 目录名(+d选项后面接目录,显示出该目录下已经被开启的文件与设备)。
查看目录【/dev】下被使用的设备的范例如下。

- 找出所有属于某个用户的的某个进程打开的文件:lsof -u 用户名 | grep ‘进程名’。
比如查找属于root这个用户的bash进程打开的所有文件,如下图所示。

- 找出系统中某个正在执行的进程的所有PID:pidof 进程名。
进程名接受正则表达式。同名进程有不同的PID有可能是因为所属的用户不同。
比如找出名为bash的命令的PID。如下图所示。

99、与SELinux有关的操作
-
查看目前主机上面的SELinux模式:getenforce。
效果如下图所示。

-
列出目前的SELinux使用的策略是什么:sestatus。
效果如下图所示。
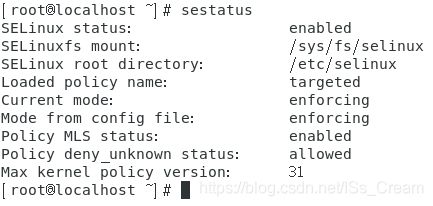
上图中的第一栏的信息分别是:
是否启动SELinux。
SELinux的相关文件挂载点。
SELinux的根目录所在。
目前的SELinux策略是什么。
目前的SELinux模式是什么。
目前配置文件内规范的SELinux模式。
是否含有MLS的模式机制。
是否默认阻止未知的主体进程。
最大的内核策略版本。 -
将SELinux的模式在enforcing与permissive之间进行切换:setenforce 0(切换至permissive),setenforce 1(切换至enforcing)。
注意一开始的SELinux模式如果是disable的话,可能需要重启才会生效,如果不是disable将会立刻生效。
效果如下图所示。
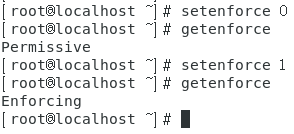
-
查看系统上所有的规则,并以布尔值的形式显示他们是否被启动:getsebool -a 或 sestatus -b。
如下图所示。

上图只是其中的一个命令,两个都差不多,就是形式有所不同。 -
查看SELinux在采用命令【sestatus】输出的策略下的统计信息,包括SELinux的状态、规则布尔值、身份识别、角色等信息:seinfo(-u选项可以查看当前策略下的所有身份种类,-r选项可以查看当前策略下的所有角色种类,-r选项可以查看当前策略下所有的类型种类,-b选项可以查看所有的规则种类)。
该命令需要下载:yum install setools-console-*。
效果图如下所示。

上图中的Types字段显示的就是当前策略下的类型种类数,Booleans字段显示的是当前策略下规则的总数。 -
查询某个主体进程类型可以读取哪些文件类型,即一个进程SELinux类型可以与哪些文件SELinux类型配对:sesearch -A -s 进程SELinux类型名(-A参数表示列出后面数据中,允许【读取或放行】的相关信息,-s选项后面跟进程的SELinux类型名)。
效果如下图所示。

从上图中可以看出进程SELinux的类型【crond_t】可以支持【system_cron_spool_t】等文件SELinux类型的文件。allow后面跟的是主体进程以及文件的SELinux类型,之后后面的【:】后面表示该文件SELinux类型支持的是文件还是目录。上图中的数据只是截取的一部分。再如下图所示。

从上图中可以看出进程SELinux的类型【crond_t】支持的文件SELinux类型为【admin_home_t】的文件是链接文件和目录,也就是说如果有个普通文件的SELinux类型为【admin_home_t】,含有进程SELinux的类型【crond_t】的进程是读取不了的。 -
查看某个规则的功能是什么:semanage boolean -l | grep 规则名。
如下图所示。
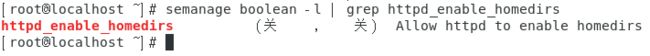
-
查看含有某个规则的进程能够读取的文件SELinux类型:sesearch -A -b 规则名(-b选项后面跟规则名)。
如下图所示。
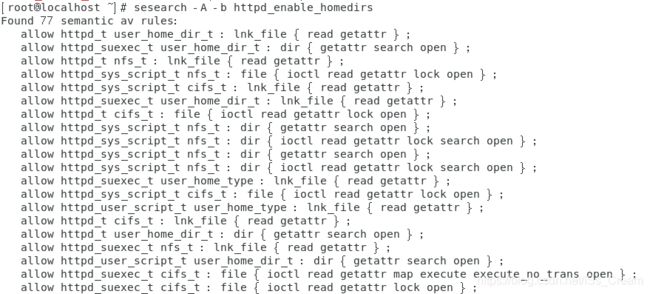
上图中总共有77条记录,太多了,没有截全。 -
修改某个规则的布尔值,从而控制规则的开启与关闭:setsebool -P 规则名 1或0(1表示开启,0表示关闭,-P选项会将设置值直接写入配置文件)。
如下图所示。

-
指定某个文件SELinux类型并将其套用在某个文件上:chcon -v -t 文件SELinux类型名 文件名(-v选项会将修改变化显示出来,-t选项后面接文件SELinux类型名,用来指定最后一个文件名参数的文件SELinux类型,-R选项会连同目录下的子目录也一同修改)。
如下图所示。

-
将某个文件1使用的文件SELinux类型套用到另一个文件2上:chcon -v --reference=文件名1 文件名2(–reference选项后面跟文件名)。
如下图所示。

-
自动将某个目录下的文件的文件SELinux类型转变成正确的默认类型:restorecon -Rv 目录名(-R选项会将目录下的子目录也一同修改,-v显示修改的过程)。
如下图所示。
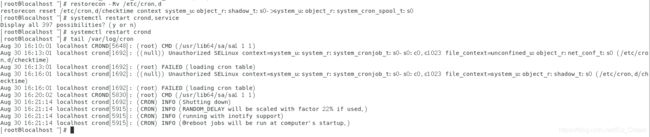
上图中的文件【/etc/cron.d/checktime】由于文件SELinux类型与进程SELinux类型对不上,再重起crond服务后,该服务无法正确读取,使用上面命令恢复正确的默认文件SELinux类型之后再重启crond服务就可以正常读取了。 -
查询某个目录默认的SELinux类型:semanage fcontext -l | grep ‘目录名’(fcontext是命令semanage的一个功能选项,后面的查找命令可以搭配扩展正则表达式命令【egrep】或【grep -E】,-l选项表示查询之意)。
如下图所示,我要查询目录【/etc/cron.d】的默认SELinux类型。

从上图中可以提取目录【/etc/cron.d】的SELinux类型为下图。
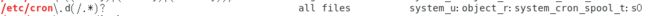
-
使用semanage命令修改某个目录的默认SELinux类型:范例。
第一步,先建立一个测试用的目录【/srv/mycron】,同时放入一些配置文件。如下图所示。

第二步,查看一下目录【/srv】的SELinux类型,如下图所示。
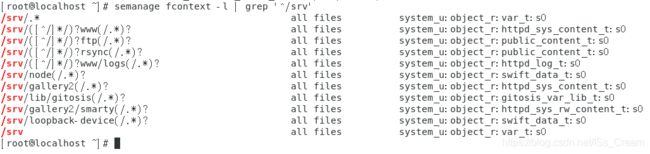
从上图中可以总结:在某个目录下面建立文件会继承父目录的默认的SELinux类型。
第三步,将mycron默认的SELinux值改为system_cron_spool_t,如下图所示。

上图中的命令【semanage fcontext -a -t system_cron_spool_t “/srv/mycron(/.*)?”】中的选项-a表示增加一些SELInux安全上下文类型设置,-t选项用来指定需要增加的文件SELinux类型,最后面一个参数是文件名或者目录名。
第四步,恢复目录【srv/mycron】及其子目录的相关的SELinux类型,如下图所示。

从上图中可以看出已经修改成功了。