RFM模型的理解和python案例分析
RFM模型是什么
RFM是客户关系管理(CRM:Customer Relationship Management)中一种重要的分析模型,通过研究一个客户的交易时间、交易频率和交易总金额来衡量客户的价值,从而做出一些精细化营销的行为。
具体的RFM定义如下:
- R(Recency):最近的一次交易时间与现在的时间间隔
- F(Frequency):用户在一段时间内的交易次数
- M(Monetary):用户在一段时间内的交易金额总数
RFM客户分类
RFM模型的核心目的就是对用户黏性、忠诚度和收入这三个维度进行数值定量分析,然后和平均数(中位数)对比得到定性描述(高或低),最后将客户分成8个不同的种类,对各类客户实施精细化的营运方案。
具体分类如下
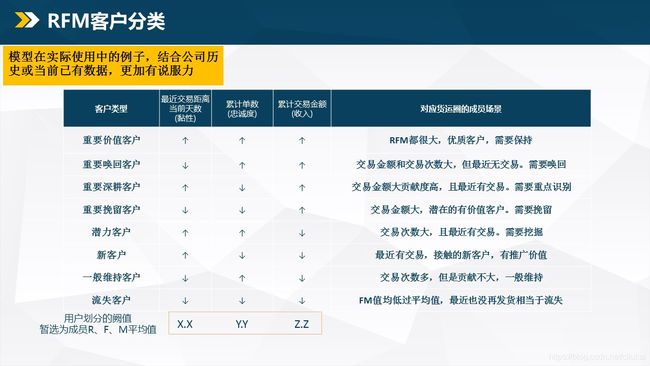
怎么使用RFM模型
数据准备
首先是通过数据清晰和加工得到如下的表格,得到RFM相关的一些指标。
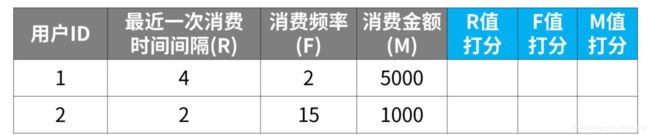
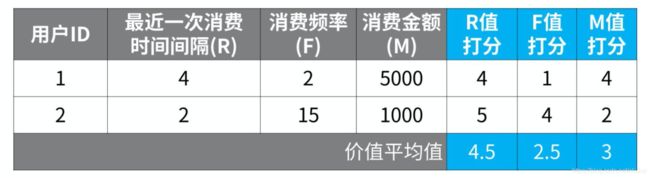
量化RFM指标
接着按照一定的规则对RFM这三个值进行打分(可以通过某种函数进行映射,也可指直接照搬或者归一化)

取标准值进行高低比较
对量化之后的数据进行统计,一般选择平均值means,或者中间数median作为一个高低的评判标准。
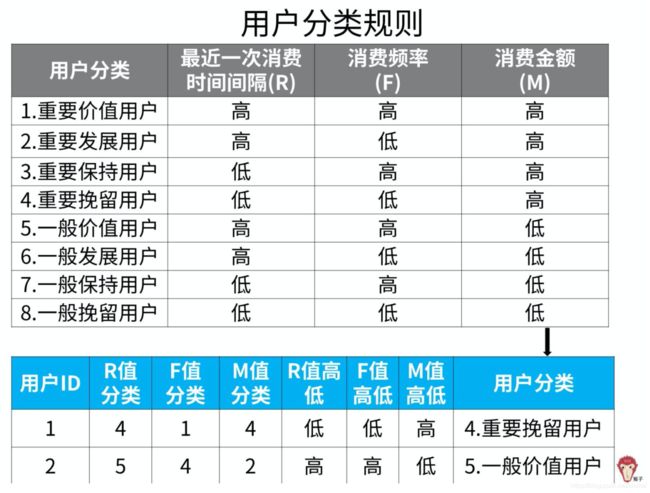
用户分类规则
通过和上面的标准值进行比较,可以得到某个分维度是高还是低的定性评判。最后根据用户分类规则表(类似于一个字典),将用户划分到相应的子类别中去。
python案例分析
用pandas读取excel数据
首先加载一组数据
import numpy as np
import pandas as pd
df = pd.read_excel("电商订单数据分析.xlsx")
df中的数据如下所示
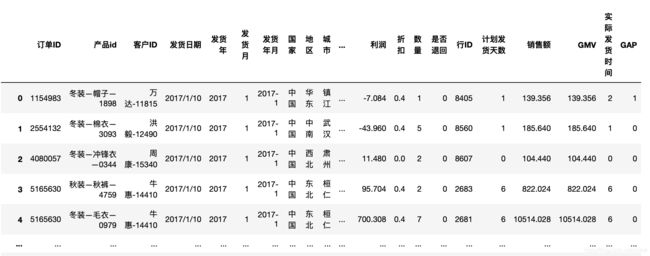
查看数据分布和特点
然后使用如下命令查看数据更多的一些细节
df.head(5)
df.info() # 查看数据的列数,即每一列的名称和数据类型
df.describe() # 查看每列数据的平均数、最值等统计数据
df.values
df.to_numpy() # 把DataFrame数据结构转换成numpy的结构
df.shape # 返回DataFrame数据结构的行数和列数
df.dtypes # 返回DataFrame数据结构每一个columns的数据类型
df['地区'].unique() # 查看一个具体的columns有哪些类目并去重
使用pivot_table观察数据
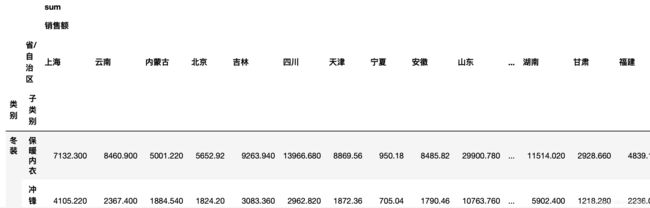
用透视表查看不同维度下的成交总额
pd.pivot_table(df,index=[u'类别',u'子类别'],columns=[u'省/自治区'],values=[u'销售额'],aggfunc=[np.sum],fill_value=0)
index中可以添加多个不同的类目,columns中还可以继续细分,values是要展示的数据,aggfunc是统计算法(例如是count统计次数,还是means平均数,或者是sum求和),u表示utf-8编码格式。
会得到类似这样的一组透视数据
日期格式转换和计算
data = df
# 将非标准时间转换成标准时间,然后在data中增加一列
data['ORDERDATE'] = pd.to_datetime(data['发货日期'])
# 设置一个标准的当前时间
dd = '2018-12-31 12:12:12'
# 计算当前时间和过去时间的差值
data['Datediff']=(pd.to_datetime(dd)-data['ORDERDATE']).dt.days
计算RFM指标
# 对客户ID进行分组,对Datediff数据应用min算法,然后重命名成近期活跃
RR = data.groupby(by=['客户ID'])['Datediff'].agg([('近期活跃','min')])
# 对客户ID分组,对订单ID数据应用count算法,然后重命名成频次
FF = data.groupby(by=['客户ID'])['订单ID'].agg([('频次','count')])
# 对客户ID分组,对GMV数据应用sum算法,然后重命名成金额
MM = data.groupby(by=['客户ID'])['GMV'].agg([('金额',sum)])
# 最后将三组数据连接在一起
rfm = RR.join(FF).join(MM)
得到的RFM数据如下所示

对RFM值定量处理
rfm['R'] = [1-(i-rfm.近期活跃.min())/(rfm.近期活跃.max()-rfm.近期活跃.min()) for i in rfm.近期活跃.tolist()]
rfm['F'] = [(i-rfm.频次.min())/(rfm.频次.max()-rfm.频次.min()) for i in rfm.频次.tolist()]
rfm['M'] = [(i-rfm.金额.min())/(rfm.金额.max()-rfm.金额.min()) for i in rfm.金额.tolist()]
# 按照一定的方式(一般是根据具体的业务)进行加权求和
rfm['score'] = 100*(0.2*rfm['M']+0.25*rfm['F']+0.55*rfm['R'])
得到归一化之后的RFM定量数值表
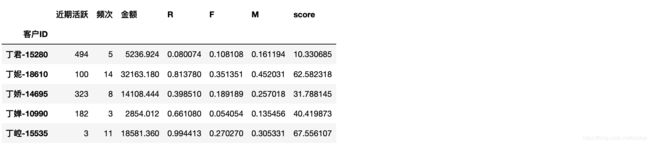
对RFM值定性处理
对RFM数值进行定性分析,按照中位数进行判断
rfm['RR'] = np.where(rfm.R<rfm.R.median(),'高','低')
rfm['FF'] = np.where(rfm.F>rfm.F.median(),'高','低')
rfm['MM'] = np.where(rfm.M>rfm.M.median(),'高','低')
rfm['RFM定性'] = rfm.RR + rfm.FF + rfm.MM # 连接字符串
得到如下的表格
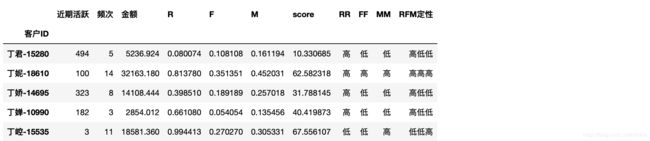
用户分类标准
最后建立一个分类规则,对客户进行分类
# 建立一个字典
RFM = {
'高高高':'重要价值用户','高低高':'重要保持用户','低高高':'重要发展用户','低低高':'重要挽留用户',
'高高低':'一般价值用户','高低低':'一般发展用户','低高低':'一般保持用户','低低低':'一般挽留用户'}
# 定性判断
rfm['level'] = [RFM[i] for i in rfm.RFM定性.tolist()]
得到最终的分析结果

参考文章
- 如何通俗易懂的理解和应用RFM分析方法(模型)? - 空白白白白的回答 - 知乎 https://www.zhihu.com/question/49439948/answer/254004098
- 如何通俗易懂的理解和应用RFM分析方法(模型)? - 猴子的回答 - 知乎 https://www.zhihu.com/question/49439948/answer/952087556
- 大数据处理课程https://learn.kaikeba.com/catalog/212116?type=1