SQL Server数据挖掘–如何将数据转化为有价值的信息
介绍 (Introduction)
In a past chat back in January 2015, we started looking at the fantastic suite of data mining tools that Microsoft has to offer. At that time, we discussed the concept of a data mining model, creating the model, testing the data and running an ad-hoc DMX query. For those folks that may have missed this article, the link may be found immediately below;
在2015年1月的一次聊天中,我们开始研究Microsoft必须提供的出色的数据挖掘工具套件。 当时,我们讨论了数据挖掘模型的概念,创建模型,测试数据并运行即席DMX查询。 对于那些可能错过了这篇文章的人,可以在下面立即找到链接。
Grab your pick and shovel and lets mine
抓住你的镐和铲子,让我的
In the second part of this article, we shall see how we may utilize the information emanating from the models, in our day to day reporting activities.
在本文的第二部分,我们将看到在日常报告活动中如何利用模型产生的信息。
So grab that pick and shovel and let us get to it!
因此,抓住那把铲子,让我们开始吧!
入门 (Getting Started)
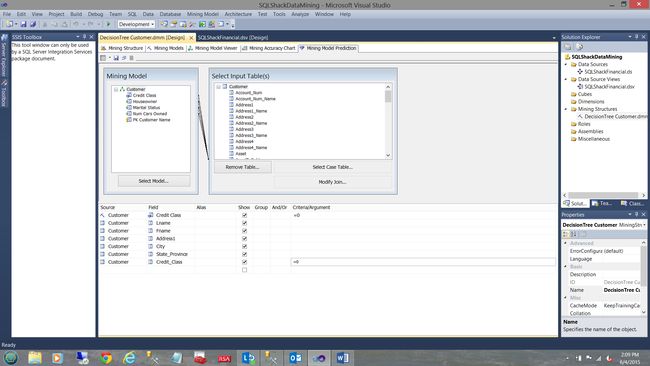
Based on the final screenshot of the first article (please see the hyperlink above) we are going to pick up from here with SQL Shack’s newest data (which came in this morning) and we are going to utilize the model that we created back in January 2015 to see how valid our model is, against the newest data.
基于第一篇文章的最终屏幕截图(请参见上面的超链接),我们将从此处获取SQL Shack的最新数据(今天上午),并将利用我们在一月份创建的模型看看2015年我们的模型相对于最新数据的有效性。
The reader will note that we have selected the mining model prediction of ‘a great credit class’ i.e. 0 (see the highlighted cell above) and we are going to pit this against the data from the newest data table “Customers”.
读者会注意到,我们选择了“良好信用等级”(即0)的挖掘模型预测(请参见上方突出显示的单元格),并将其与最新数据表“客户”中的数据进行比较。
In order to validate our results, we set the mining model predicted credit class to 0 and the actual “Customer” credit class (from the credit agencies) to 0 as well (see above).
为了验证我们的结果,我们将挖掘模型的预测信用级别设置为0,并将实际“客户”信用级别(来自信用机构)也设置为0(请参见上文)。
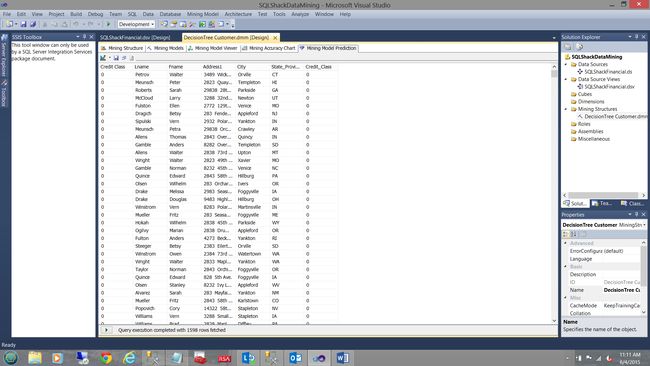
The results of the query are shown above and we note that these are the folks that are probably a safe credit risk. 0 being the best credit class.
查询结果如上所示,我们注意到这些人可能是安全的信用风险 。 0是最佳信用等级。
The astute reader (of the first part of this article) will have noted the similarities of the screenshot shown above and the last screenshot of the January article.
精明的读者(本文第一部分)将注意到上面显示的屏幕截图与1月文章的最后一个屏幕截图的相似之处。
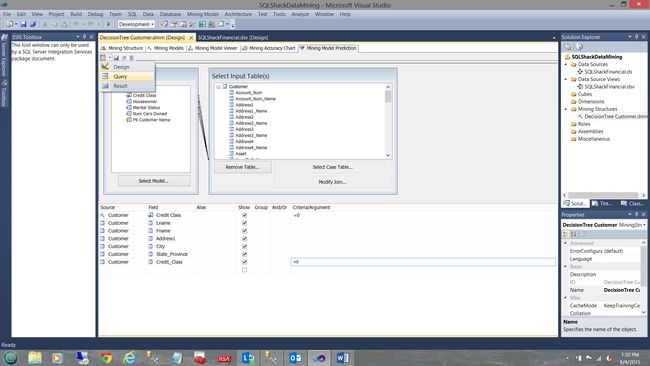
Selecting the query option shown in the screen dump above, we select “Query”.
选择上面屏幕转储中显示的查询选项,我们选择“查询”。
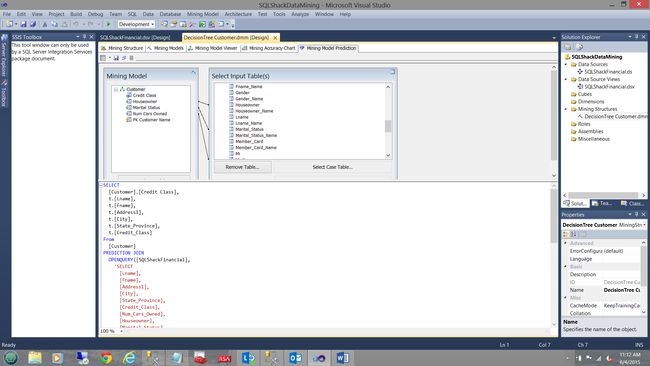
The DMX (Data Mining Expression) used to produce the results (that we just saw) is displayed.
显示用于生成结果(我们刚刚看到)的DMX(数据挖掘表达式)。
SELECT
[Customer].[Credit Class],
t.[Lname],
t.[Fname],
t.[Address1],
t.[City],
t.[State_Province],
t.[Credit_Class]
From
[Customer]
PREDICTION JOIN
OPENQUERY([SQLShackFinancial],
'SELECT
[Lname],
[Fname],
[Address1],
[City],
[State_Province],
[Credit_Class],
[Num_Cars_Owned],
[Houseowner],
[Marital_Status]
FROM
[dbo].[Customer]
') AS t
ON
[Customer].[Num Cars Owned] = t.[Num_Cars_Owned] AND
[Customer].[Houseowner] = t.[Houseowner] AND
[Customer].[Marital Status] = t.[Marital_Status]
WHERE
[Customer].[Credit Class] =0 AND
t.[Credit_Class] =0
This is our jumping off point for today’s discussion.
这是我们今天讨论的起点。
将我们的DMX数据转化为有价值的信息 (Turning our DMX data into valuable information)
Our first task is to address the most efficient and effective manner to create queries that may be utilized for reporting purposes.
我们的首要任务是解决最有效的方式来创建可用于报告目的的查询。
Most of us know the trials and tribulations of filtering data from MDX expressions. Somehow it is a nightmare. DMX queries are no easier nor as versatile nor as flexible as T-SQL.
我们大多数人都知道从MDX表达式过滤数据的试验和麻烦。 不知何故,这是一场噩梦。 DMX查询既不像T-SQL一样容易,通用或灵活。
We are going to attack our problem by utilizing the “Hamburger” method (see below).
我们将通过使用“汉堡包”方法来解决我们的问题(见下文)。

|
T-SQL Select statement |
| DMX | |
| T-SQL predicate |
| T-SQL Select语句 | |
| DMX | |
| T-SQL谓词 |
Our first task is to create a linked server through to our Data Mining Analysis database.
我们的首要任务是创建一个链接到我们的数据挖掘分析数据库的服务器。
Our database is shown in the screenshot above.
我们的数据库显示在上面的屏幕截图中。
The code to create the linked server (linking our relational database “SQLShackFinancial” on Server STEVETOPMULTI to the database “SQLShackDataMining” on the analysis server STEVETOPMULTI) is shown below:
创建链接服务器(将服务器STEVETOPMULTI上的关系数据库“ SQLShackFinancial”链接到分析服务器STEVETOPMULTI上的数据库“ SQLShackDataMining”)的代码如下所示:
USE master
GO
EXEC sp_addlinkedserver @server='SQLShackDataMining', -- local SQL name given to the linked server
@srvproduct='', -- not used
@provider='MSOLAP', -- OLE DB provider
@datasrc='R9-WXL90\STEVETOPMulti', -- analysis server name (machine name)
@catalog='SQLShackDataMining' -- default catalog/database
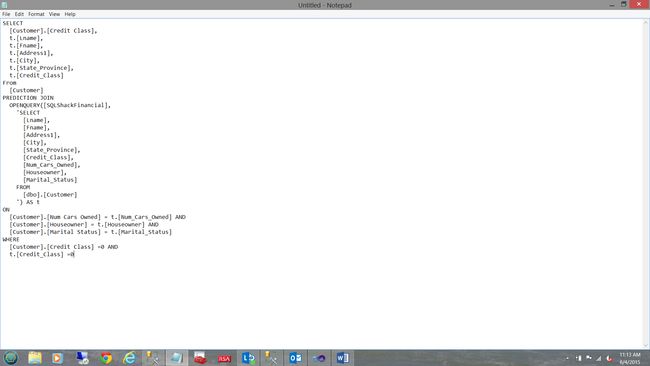
The screenshot above shows us the DMX code that we shall be using. This code is the “meat portion of the burger”.
上面的屏幕截图显示了我们将要使用的DMX代码。 此代码是“汉堡的肉部分”。
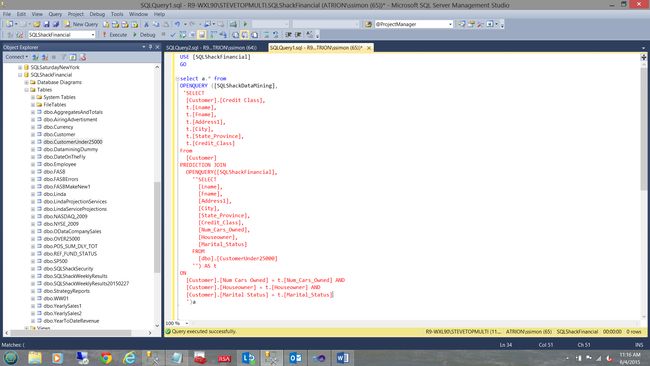
We change the code slightly as may be seen in the screenshot below:
我们对代码进行了一些更改,如下面的屏幕截图所示:
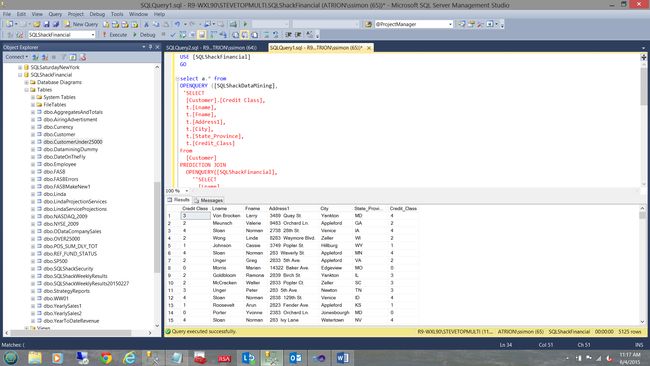
And the result set of this simple query may be seen in the screen dump below:
在下面的屏幕转储中可以看到此简单查询的结果集:
The code for our query may be found in Addenda 1.
我们的查询代码可以在附录1中找到。
让我们忙于花式腿的工作 (Let us get busy with the fancy leg work)
As described in the introduction, we wish to utilize our data mining “data” and to turn it into valuable information. This said let us take advantage of the “Hamburger” approach and modify our crude query to make reporting simpler and more effective.
如引言中所述,我们希望利用我们的数据挖掘“数据”并将其转化为有价值的信息。 这就是说,让我们利用“汉堡包”方法并修改粗略查询以使报告更简单,更有效。
By inserting the contents of the query (that we just ran into a table written to disk), we can see the field names as SQL Server Management Studio knows them (see below).
通过插入查询的内容(我们刚刚遇到了写入磁盘的表),我们可以看到SQL Server Management Studio知道的字段名称(请参见下文)。
USE [SQLShackFinancial]
GO
/****** Object: Table [dbo].[DataminingDummy] Script Date: 6/3/2015 1:03:53 PM ******/
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
CREATE TABLE [dbo].[DataminingDummy](
[Credit Class] [bigint] NULL,
[Lname] [ntext] NULL,
[Fname] [ntext] NULL,
[Address1] [ntext] NULL,
[City] [ntext] NULL,
[State_Province] [ntext] NULL,
[Credit_Class] [smallint] NULL
) ON [PRIMARY] TEXTIMAGE_ON [PRIMARY]
GO
We can now modify our query accordingly
现在,我们可以相应地修改查询
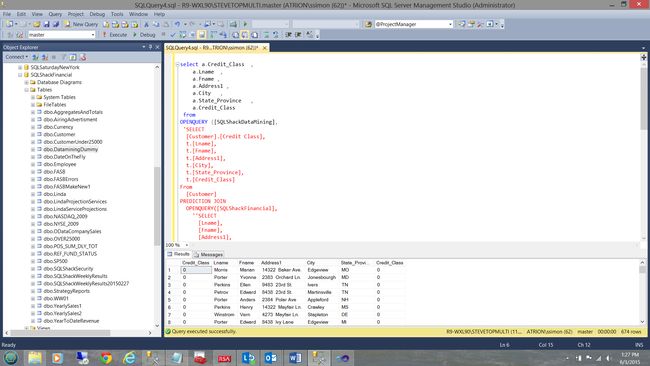
We can even remove the DMX predicate all together and let the report query define the final predicate.
我们甚至可以一起删除 DMX谓词,然后让报表查询定义最终谓词。
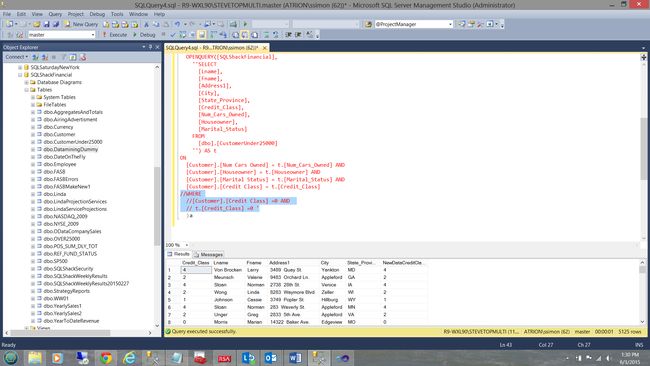
Further, we can create very dynamic predicates which may accept parameter (see below).
此外,我们可以创建可以接受参数的动态谓词(请参见下文)。
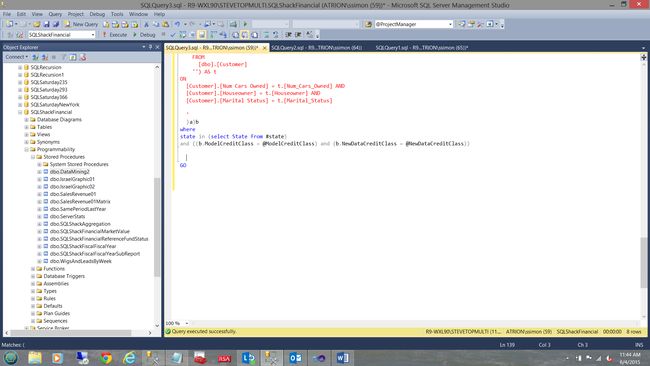
More on this topic in a few minutes after we construct our first report.
在构造第一份报告后的几分钟内,有关此主题的更多信息。
我们的采矿模型报告 (Reporting from our mining model)
Opening SQL Server Data Tools, we create a new Reporting Services Project. Should you not be familiar with the process, please do see one of my earlier articles on SQLShack.com where the process is described in detail.
打开SQL Server数据工具,我们创建一个新的Reporting Services项目。 如果您不熟悉该过程,请在SQLShack.com上参阅我的较早的文章之一,其中详细描述了该过程。
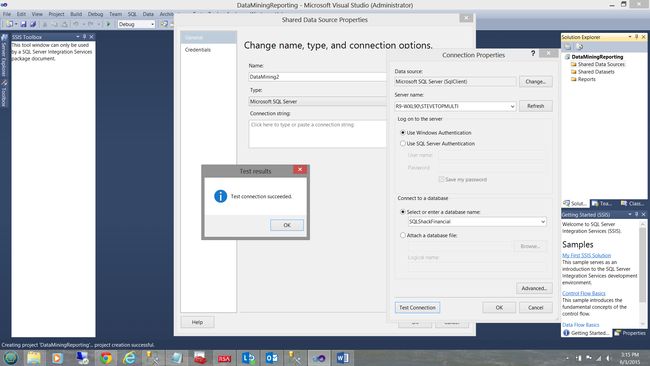
As always, we create a new Data Source to the “SQLShackFinancial” database (see above).
与往常一样,我们为“ SQLShackFinancial”数据库创建一个新的数据源(请参见上文)。
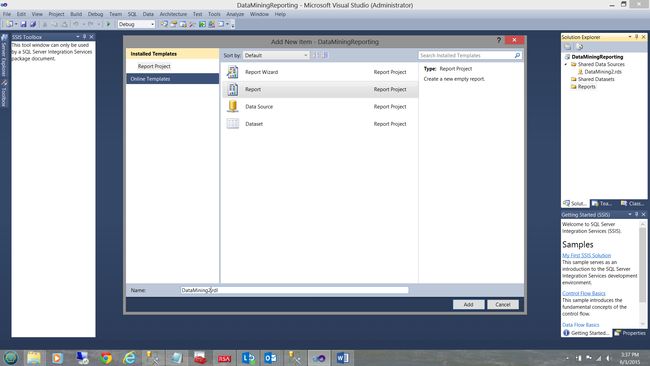
We add a new report and name it DataMining2 (see above).
我们添加一个新报告并将其命名为DataMining2(请参见上文)。
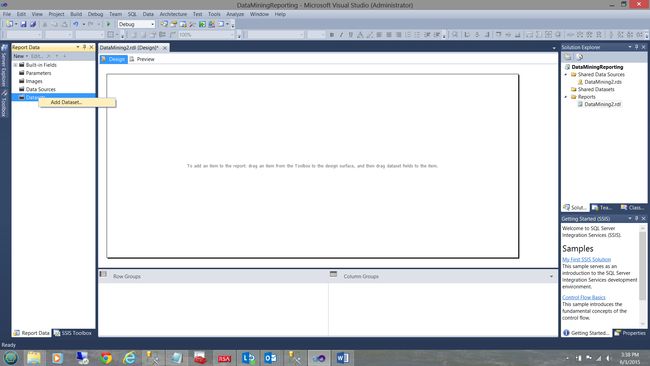
As always, our next task is to create a dataset (see above).
与往常一样,我们的下一个任务是创建数据集(请参见上文)。
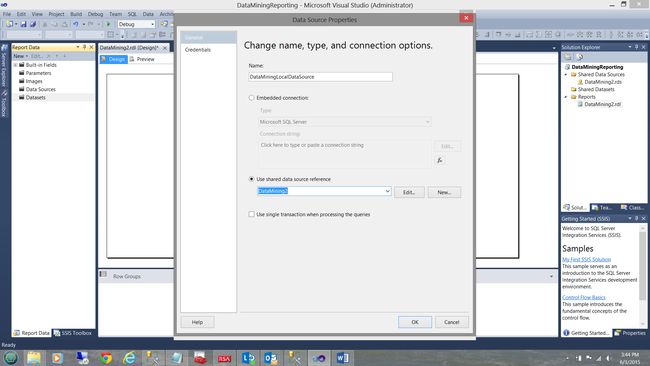
First we create a local data source which references our shared data source”DataMining2”.
首先,我们创建一个引用我们共享数据源“ DataMining2”的本地数据源。
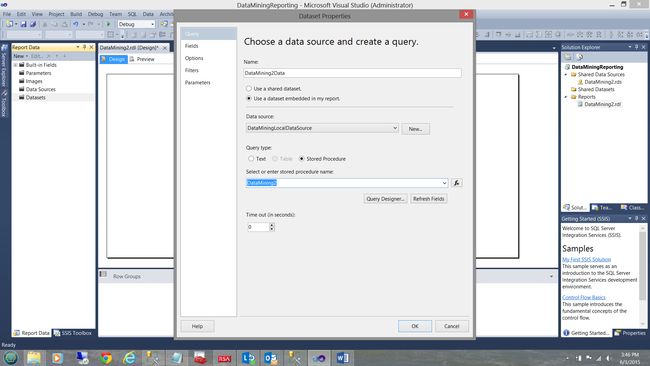
We set the data source to point to our stored procedure DataMining2 (which was created with the code that we just discussed). See the code listing in Addenda 2.
我们将数据源设置为指向存储过程DataMining2 (它是使用我们刚刚讨论的代码创建的) 。 请参阅附录2中的代码清单。
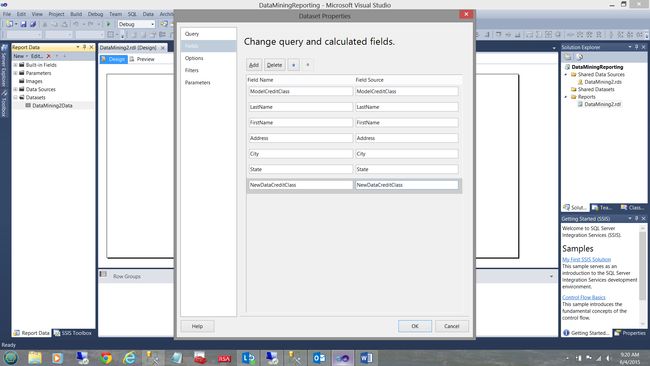
By clicking on the fields tab (see above), we note all the fields from the stored procedure, “DataMining2”. We click “OK” to leave the “Dataset Properties” dialog box.
通过单击字段选项卡(参见上文),我们注意到存储过程“ DataMining2”中的所有字段。 我们单击“确定”离开“数据集属性”对话框。
We are in now in the position to add a few parameters to our report.
我们现在可以在报告中添加一些参数。
The astute reader will note that these parameters have been added to the Parameters Tab due to the fact that Reporting Services has noted that the stored procedure requires three parameters.
精明的读者会注意到,由于Reporting Services已经注意到存储过程需要三个参数,因此这些参数已添加到“参数”选项卡中。
创建将提供“ ModelCreditClass”参数的参数值的数据集。 (Creating the dataset which will supply the parameter values for the “ModelCreditClass” parameter.)
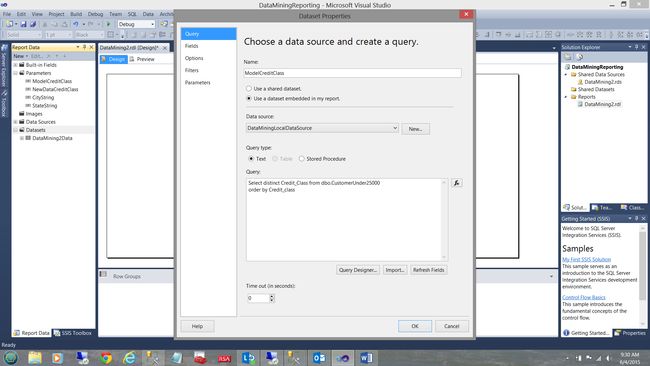
In a similar manner to which we created the DataMining2Data dataset, we create a “ModelCreditClass” dataset (see above). Note that the data that we require may be obtained by utilizing a simple SQL Statement.
以与创建DataMining2Data数据集类似的方式,我们创建了一个“ ModelCreditClass”数据集(请参见上文)。 请注意,我们需要的数据可以通过使用简单SQL语句获得。
Select distinct Credit_Class from dbo.CustomerUnder25000
order by Credit_class
In a similar manner, we create another dataset for “NewDataCreditClass”. As a reminder to the reader, “NewDataCreditClass” is the credit class that was assigned by a credit rating firm (within the new/ fresh data). This way we are able to validate our prediction with values from a professional firm.
以类似的方式,我们为“ NewDataCreditClass”创建另一个数据集。 在此提醒读者,“ NewDataCreditClass”是信用评级公司(在新/新数据中)分配的信用等级。 这样,我们就可以用专业公司的价值来验证我们的预测。
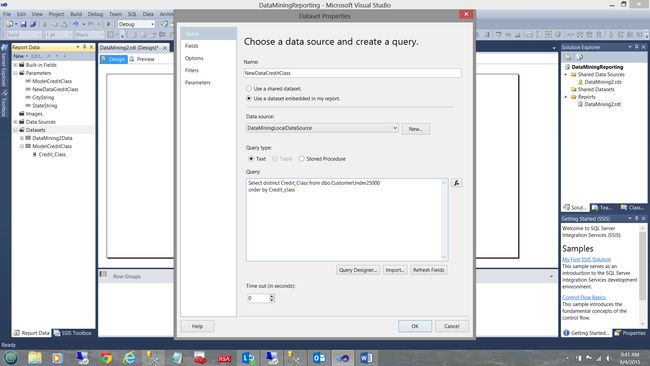
Once again, the astute reader will note that we use the same SQL query to populate this dataset and the numbers are same as the source of the number data is not really relevant.
再次,精明的读者会注意到,我们使用相同的 SQL查询来填充此数据集,并且数字与数字数据的来源并不真正相关。
Moving back to the “Parameter” tab, we double click the “ModelCreditClass” parameter.
回到“参数”选项卡,我们双击“ ModelCreditClass”参数。
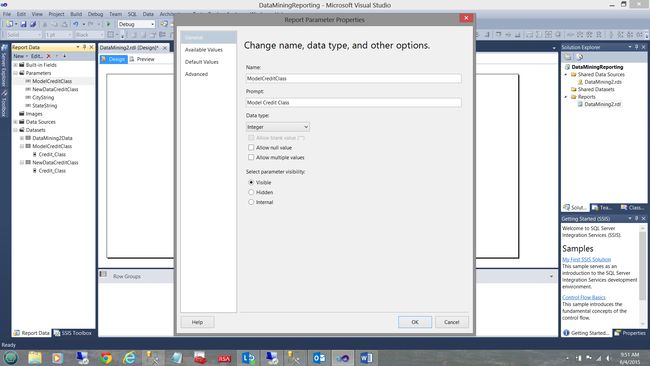
The “Report Parameter Properties” dialog box opens (see above).
“报告参数属性”对话框打开(请参见上文)。
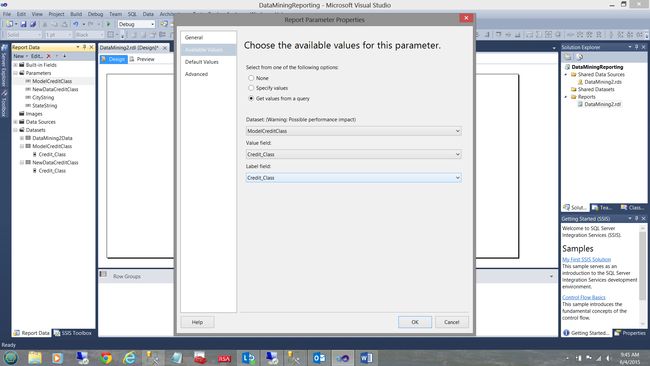
On the “Available Values” tab, we click the “Get Values from a query” box and set the “Dataset” to the “ModelCreditClass” dataset that we just created.
在“可用值”选项卡上,单击“从查询获取值”框,然后将“数据集”设置为我们刚刚创建的“ ModelCreditClass”数据集。
Finally, we set the “Value” and “Label Fields” to “Credit_Class”. We then click “OK” to exit the dialogue box.
最后,我们将“值”和“标签字段”设置为“ Credit_Class”。 然后,我们单击“确定”退出对话框。
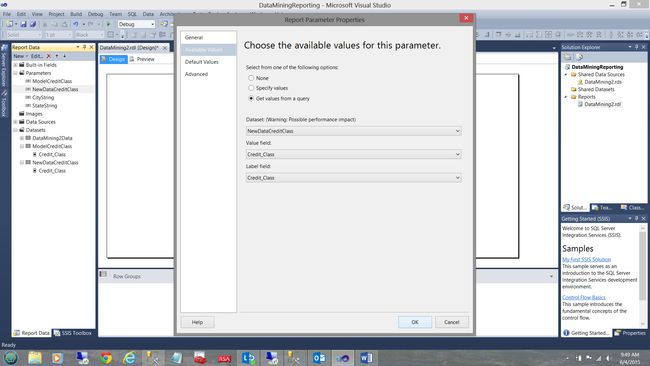
In a similar fashion we do the same tasks to provide the “NewDataCreditClass” parameter with values (see below).
我们以类似的方式执行相同的任务,以为“ NewDataCreditClass”参数提供值(请参见下文)。
使用“状态”参数 (Working with the “State” parameter)
We are going to handle the “State” parameter in a different fashion. We are going to initialize the parameter as a multi-select parameter. Before continuing with the configuration of this parameter, we must once again create a dataset.
我们将以不同的方式处理“ State”参数。 我们将把参数初始化为多选参数。 在继续配置此参数之前,我们必须再次创建一个数据集。
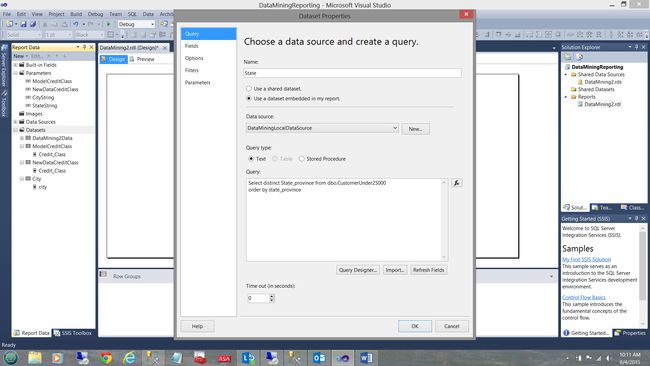
The “State_Province” dataset is shown above and is configured as we have configured the other datasets discussed above.
上面显示了“ State_Province”数据集,并按照我们上面讨论的其他数据集进行了配置。
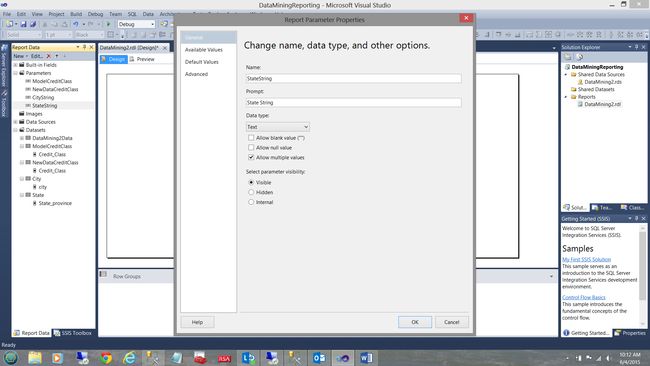
The setup of the “StateString” is similar to the other parameters described above. The only difference is that we check the “Allow multiple values” checkbox (see above).
“ StateString”的设置类似于上述其他参数。 唯一的区别是我们选中了“允许多个值”复选框(请参见上文)。
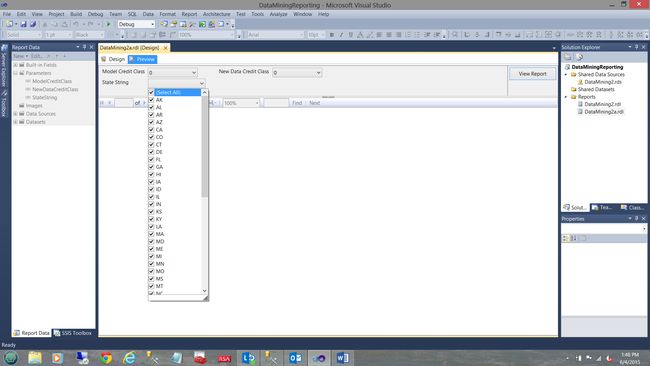
Having a preview of what we have created thus far, we click on the “Preview” tab. The report appears as shown above.
预览了到目前为止所创建的内容,我们单击“预览”选项卡。 该报告显示如上所示。
Our last and most important task is to configure the “DataMining2Data” dataset to handle multiple values for the “State”.
我们的最后也是最重要的任务是配置“ DataMining2Data”数据集以处理“ State”的多个值。
配置状态参数 (Configuring the State Parameter)
Why are we required to configure the remaining parameter in a special manner? The answer is simply that as we have opted to pass MULTIPLE states to the stored procedure. This being the case, we must “tell” the parameter to keep concatenating the values that we select AND then to pass those concatenated values onto the stored procedure. We shall discuss how the stored procedure handles that whopping big string in just a few moments, but let us not get ahead of ourselves.
为什么需要以特殊方式配置其余参数? 答案很简单,因为我们选择将MULTIPLE状态传递给存储过程。 在这种情况下,我们必须“告知”参数以继续串联我们选择的值,然后将这些串联的值传递到存储过程中。 我们将讨论存储过程如何在短时间内处理巨大的字符串,但让我们不要超越自己。
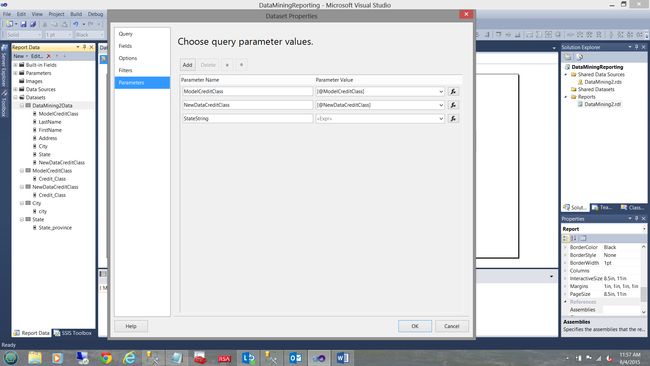
Opening the “DataMining2Data” dataset, we click on the “Parameters” tab (see above). We note that there is a “table” like configuration box with which we shall now work. For the “StateString” parameter, we click on the function button immediately to the right of the “Parameter Value” cell.
打开“ DataMining2Data”数据集,我们单击“ Parameters”选项卡(见上文)。 我们注意到,有一个“表”之类的配置框,我们现在将使用它。 对于“ StateString”参数,我们单击“ Parameter Value”单元格右侧的功能按钮。
The “Expression” dialogue box opens.
“表达”对话框打开。
We change the value “ =Parameters!StateString.values” to =JOIN(Parameters!StateString.Value,”,”)
我们将值“ = Parameters!StateString.values”更改为= JOIN( Parameters! StateString .Value ,”,”)
See below:
见下文:
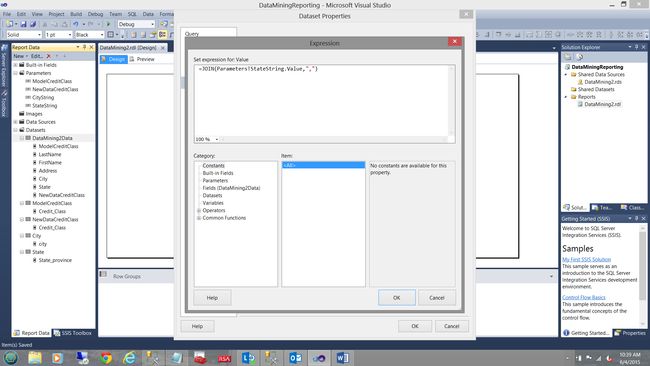
We click “OK” and the “Expressions” dialog box closes.
单击“确定”,“表达式”对话框关闭。
报告正文 (The Report Body)
Now that our infrastructure is complete, we are now in a position to design our report body. We begin by dragging and placing a “Matrix” (from the toolbox) onto the work surface (see below).
现在我们的基础架构已经完成,我们现在可以设计报告主体了。 我们首先将“矩阵”(从工具箱中)拖放到工作表面上(见下文)。
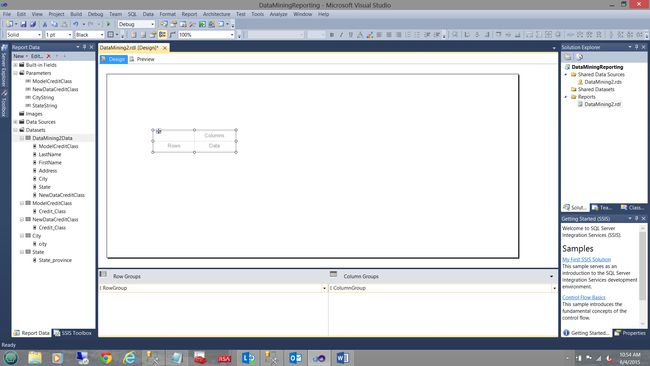
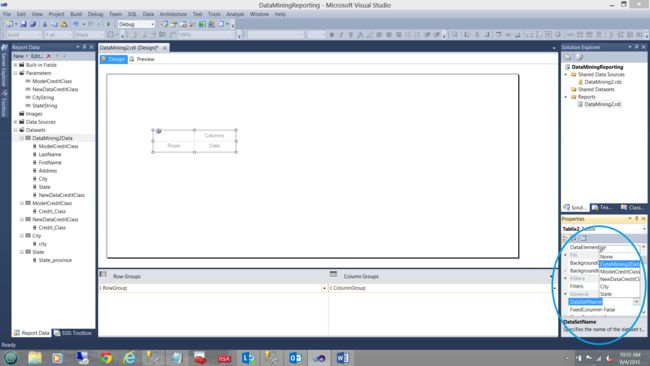
Our next task is to link the matrix to the dataset “DataMining2Data” (see below).
我们的下一个任务是将矩阵链接到数据集“ DataMining2Data”(见下文)。
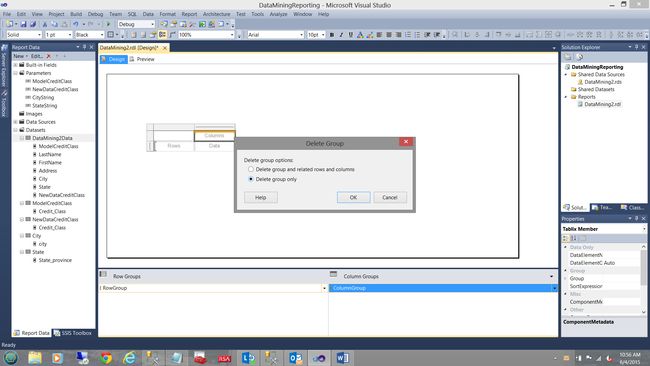
Our first task is to right click on the “Column Groups” tab (see above) and to “Delete” the group only.
我们的首要任务是右键单击“列组”选项卡(参见上文),然后仅“删除”该组。
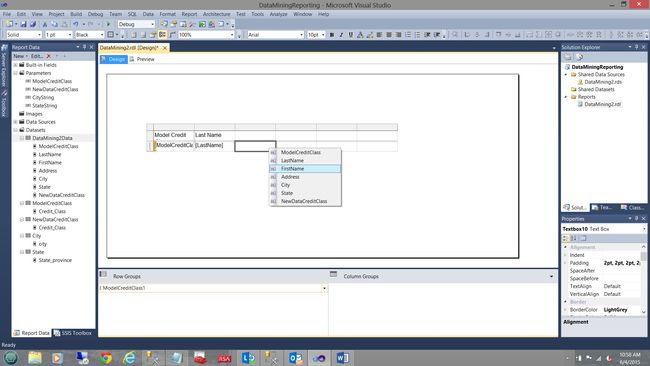
We then add a few more columns to our matrix and place our dataset fields into the matrix, one by one (see above).
然后,我们在矩阵中再添加几列,并将数据集字段一一放置到矩阵中(见上文)。
We are now in a position to configure the row grouping and as we are interested in viewing all rows in a non-aggregated state, then we must group by several fields. We double click the “ModelCreditClass1” Row Grouping.
现在,我们可以配置行分组,并且由于我们有兴趣查看处于非聚合状态的所有行,因此必须按几个字段分组。 我们双击“ ModelCreditClass1”行分组。
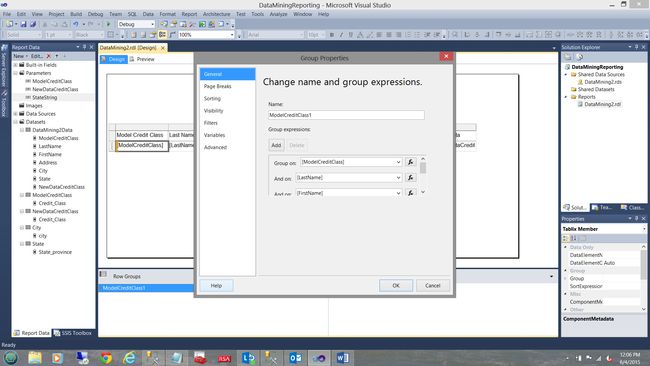
The “Group Properties” Dialog box opens. We add the following groupings by clicking on the Add button (see below). These grouping fields include “ModelClassCredit”, “LastName”, “FirstName”, Address, City, and State.
“组属性”对话框打开。 我们通过单击添加按钮添加以下分组(见下文)。 这些分组字段包括“ ModelClassCredit”,“姓氏”,“名字”,地址,城市和州。
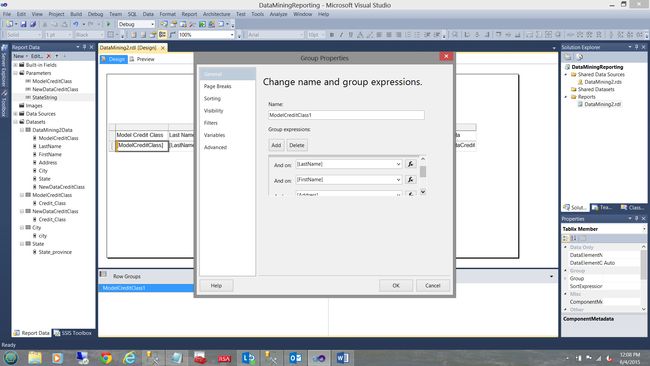
We click OK to leave the “Group Properties” dialogue box and find ourselves back on our work surface (see below).
我们单击“确定”离开“组属性”对话框,然后回到工作界面(请参见下文)。
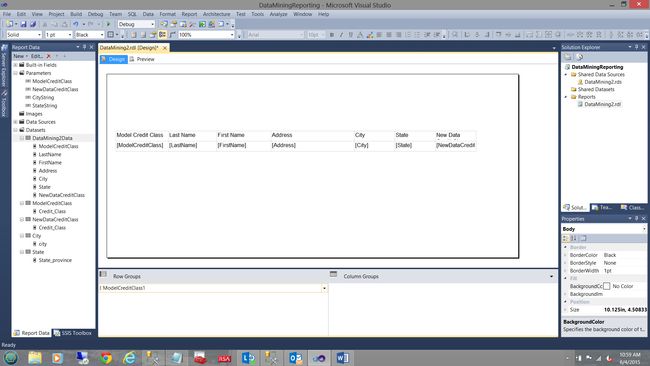
Our completed matrix may be seen above.
我们完整的矩阵可以在上面看到。
整理一点 (Tidying up a tad)
We first add a bit of color to our Matrix (see below).
我们首先在矩阵中添加一些颜色(见下文)。
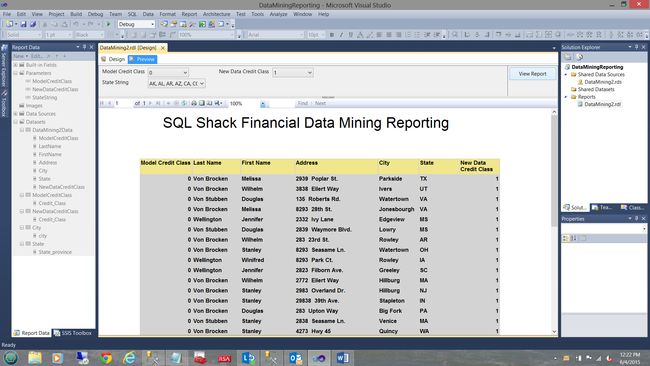
The one issue that most of us hate it when scrolling down on a report that the column headers tend to disappear. Let us changes to the header properties to scroll down with us, PLUS have them visible on each report page.
向下滚动到列标题趋于消失的报告时,我们大多数人讨厌它。 让我们更改标题属性以与我们一起向下滚动,再加上它们在每个报表页面上可见。
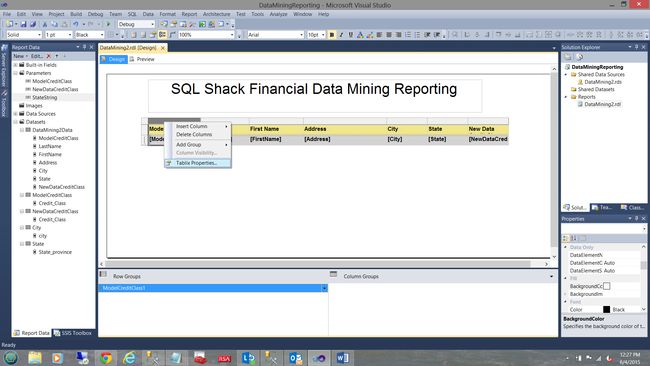
We right-click upon the Column Header as shown above within the grey box and bring up the “Tablix Properties” dialogue box.
我们如右图所示在灰色框中右键单击“列标题”,然后弹出“ Tablix属性”对话框。
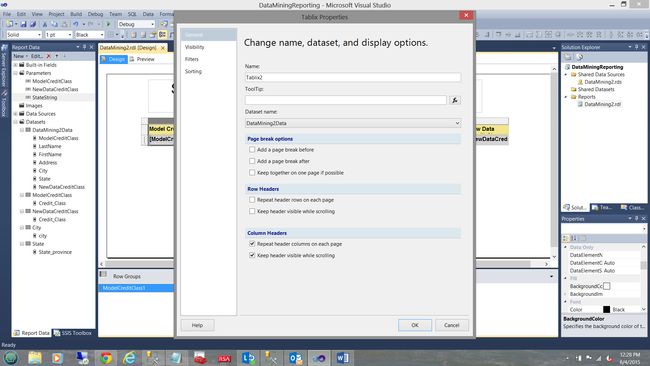
We then “check” the “Repeat Header columns on each page” and the “Keep header visible while scrolling” option within the “Column Header” dialogue box (see above). We then click “OK” to leave the “Tablix Properties” dialogue box.
然后,我们“检查”“每页上的重复标题列”和“列标题”对话框中的“滚动时保持标题可见”选项(见上文)。 然后,我们单击“确定”离开“ Tablix属性”对话框。
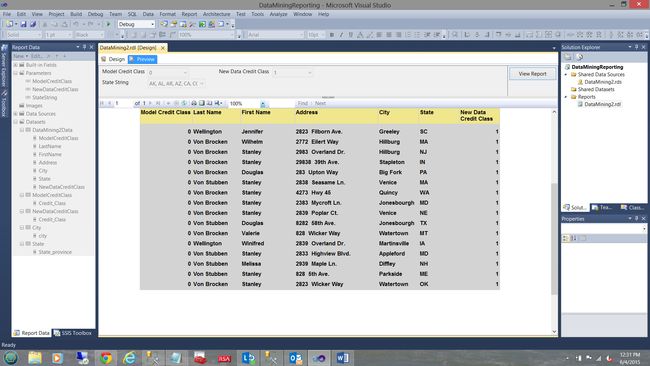
We note that the column headers are STILL visible as we approach the bottom of the page (see above).
我们注意到,当我们接近页面底部时,列标题仍然可见(请参见上文)。
结论 (Conclusions)
We have once again come to the end of another get-together. In this session we have looked at the constructive utilization of the “mined” data, turning it into valuable information.
我们再次走到了另一个聚会的尽头。 在本次会议中,我们研究了“挖掘”数据的建设性利用,将其转化为有价值的信息。
We saw the DMX code that is generated by the model based upon our business rules and we were introduced to the “Hamburger” approach to data extraction. This approach permitted us to mine the data and yet utilize standard T-SQL to define the predicate and re-format the data. Through using the code in Addenda3 we are able to strip the long selection of state names and place the respective values into a temporary table to be utilized by our report predicate.
我们看到了由模型根据我们的业务规则生成的DMX代码,并向我们介绍了“汉堡包”方法进行数据提取。 这种方法允许我们挖掘数据,但仍使用标准的T-SQL定义谓词并重新格式化数据。 通过使用Addenda3中的代码,我们可以剥离长时间选择的状态名称,并将相应的值放入临时表中,以供我们的报告谓词使用。
As always, should you have any questions or concerns, please feel free to contact me.
与往常一样,如果您有任何疑问或疑虑,请随时与我联系。
In the interim, happy programming!
在此期间,编程愉快!
翻译自: https://www.sqlshack.com/sql-server-data-mining-turn-data-into-valuable-information/