LeetCode--朋友圈(深度优先搜索+广度优先搜索+并查集)
朋友圈
班上有 N 名学生。其中有些人是朋友,有些则不是。他们的友谊具有是传递性。如果已知 A 是 B 的朋友,B 是 C 的朋友,那么我们可以认为 A 也是 C 的朋友。所谓的朋友圈,是指所有朋友的集合。
给定一个 N * N 的矩阵 M,表示班级中学生之间的朋友关系。如果M[i][j] = 1,表示已知第 i 个和 j 个学生互为朋友关系,否则为不知道。你必须输出所有学生中的已知的朋友圈总数。
示例 1:
输入:
[[1,1,0],
[1,1,0],
[0,0,1]]
输出: 2
说明:已知学生0和学生1互为朋友,他们在一个朋友圈。
第2个学生自己在一个朋友圈。所以返回2。
示例 2:
输入:
[[1,1,0],
[1,1,1],
[0,1,1]]
输出: 1
说明:已知学生0和学生1互为朋友,学生1和学生2互为朋友,所以学生0和学生2也是朋友,所以他们三个在一个朋友圈,返回1。
注意:
N 在[1,200]的范围内。
对于所有学生,有M[i][i] = 1。
如果有M[i][j] = 1,则有M[j][i] = 1。
0 树的深度优先以及广度优先讲解
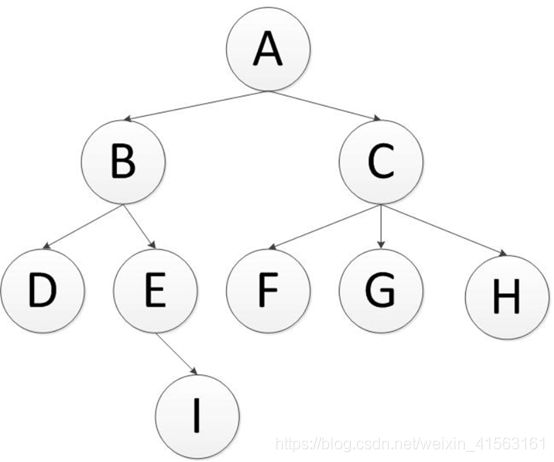
1.广度优先遍历
英文缩写为BFS即Breadth FirstSearch。其过程检验来说是对每一层节点依次访问,访问完一层进入下一层,而且每个节点只能访问一次。对于上面的例子来说,广度优先遍历的 结果是:A,B,C,D,E,F,G,H,I(假设每层节点从左到右访问)。
先往队列中插入左节点,再插右节点,这样出队就是先左节点后右节点了。广度优先遍历树,需要用到队列(Queue)来存储节点对象,队列的特点就是先进先出。例如,上面这颗树的访问如下:
首先将A节点插入队列中,队列中有元素(A);
将A节点弹出,同时将A节点的左、右节点依次插入队列,B在队首,C在队尾,(B,C),此时得到A节点;
继续弹出队首元素,即弹出B,并将B的左、右节点插入队列,C在队首,E在队尾(C,D,E),此时得到B节点;
继续弹出,即弹出C,并将C节点的左、中、右节点依次插入队列,(D,E,F,G,H),此时得到C节点;
将D弹出,此时D没有子节点,队列中元素为(E,F,G,H),得到D节点;
。。。以此类推。。
代码:这里以二叉树为例,遍历所有节点的值
/**
public class TreeNode {
int val = 0;
TreeNode left = null;
TreeNode right = null;
public TreeNode(int val) {
this.val = val;
}
}
*/
public class Solution {
public ArrayList PrintFromTopToBottom(TreeNode root) {
ArrayList lists=new ArrayList();
if(root==null)
return lists;
Queue queue=new LinkedList();
queue.offer(root);
while(!queue.isEmpty()){
TreeNode tree=queue.poll();
if(tree.left!=null)
queue.offer(tree.left);
if(tree.right!=null)
queue.offer(tree.right);
lists.add(tree.val);
}
return lists;
}
}
2、深度优先
英文缩写为DFS即Depth First Search.其过程简要来说是对每一个可能的分支路径深入到不能再深入为止,而且每个节点只能访问一次。对于上面的例子来说深度优先遍历的结果就是:A,B,D,E,I,C,F,G,H.(假设先走子节点的的左侧)。
深度优先遍历各个节点,需要使用到栈(Stack)这种数据结构。stack的特点是是先进后出。整个遍历过程如下:
先往栈中压入右节点,再压左节点,这样出栈就是先左节点后右节点了。首先将A节点压入栈中,stack(A);
将A节点弹出,同时将A的子节点C,B压入栈中,此时B在栈的顶部,stack(B,C);
将B节点弹出,同时将B的子节点E,D压入栈中,此时D在栈的顶部,stack(D,E,C);
将D节点弹出,没有子节点压入,此时E在栈的顶部,stack(E,C);
将E节点弹出,同时将E的子节点I压入,stack(I,C);
...依次往下,最终遍历完成。
代码:也是以二叉树为例。非递归
/**
public class TreeNode {
int val = 0;
TreeNode left = null;
TreeNode right = null;
public TreeNode(int val) {
this.val = val;
}
}
*/
public class Solution {
public ArrayList PrintFromTopToBottom(TreeNode root) {
ArrayList lists=new ArrayList();
if(root==null)
return lists;
Stack stack=new Stack();
stack.push(root);
while(!stack.isEmpty()){
TreeNode tree=stack.pop();
//先往栈中压入右节点,再压左节点,这样出栈就是先左节点后右节点了。
if(tree.right!=null)
stack.push(tree.right);
if(tree.left!=null)
stack.push(tree.left);
lists.add(tree.val);
}
return lists;
}
}
深度优先的递归实现:
public void depthOrderTraversalWithRecursive()
{
depthTraversal(root);
}
private void depthTraversal(TreeNode tn)
{
if (tn!=null)
{
System.out.print(tn.value+" ");
depthTraversal(tn.left);
depthTraversal(tn.right);
}
}
-
思路 dfs深度优先搜索
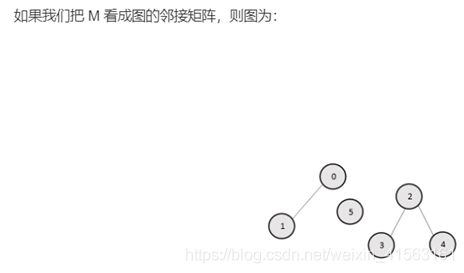
在这个图中,点的编号表示矩阵 M 的下标,ii 和 jj 之间有一条边当且仅当 M[i][j]M[i][j] 为 1。
为了找到连通块的个数,一个简单的方法就是使用深度优先搜索,从每个节点开始,我们使用一个大小为 NN 的 visitedvisited 数组(MM 大小为 N \times NN×N),这样 visited[i]visited[i] 表示第 i 个元素是否被深度优先搜索访问过。
我们首先选择一个节点,访问任一相邻的节点。然后再访问这一节点的任一相邻节点。这样不断遍历到没有未访问的相邻节点时,回溯到之前的节点进行访问。
class Solution {
public int findCircleNum(int[][] M) {//使用深度优先搜索,类似岛屿个数的题目
int length = M.length;//二维数组长度,即所有人的个数
int count = 0;//统计朋友圈个数
boolean[] flag = new boolean[length];//访问标志
for(int i = 0;i < length;i++){//对于每个人
if(flag[i] == false){//如果未被访问
DFS(i,M,flag);//深度优先搜索,访问
count++;//朋友圈个数+1
}
}
return count;
}
//深度优先搜索
public void DFS(int i,int[][] M,boolean[] flag){
flag[i] = true;
for(int j = 0;j < M[i].length;j++){
if(flag[j] == false && M[i][j] == 1){
DFS(j,M,flag);
}
}
}
}
2 广度优先搜索(未完,待续)