BIO--NIO-AIO(IOCP在Java7中的实现)
背景
在 Java 的早期,JVM 在解释字节码时往往很少或没有运行时优化。这就意味着,Java 程序往往拖得很长,其运行速率大大低于本地编译代码,因而对操作系统I/O 子系统的要求并不太高。 如今在运行时优化方面,JVM 已然前进了一大步。现在 JVM 运行字节码的速率已经接近本地编译代码,借助动态运行时优化,其表现甚至还有所超越。这就意味着,多数 Java 应用程序已不再受 CPU 的束缚(把大量时间用在执行代码上),而更多时候是受 I/O 的束缚(等待数据传输)。
然而,在大多数情况下,Java 应用程序并非真的受着 I/O 的束缚。操作系统并非不能快速传送数据,让 Java 有事可做;相反,是 JVM 自身在 I/O 方面效率欠佳。 操作系统与 Java 基于流的 I/O模型有些不匹配。操作系统要移动的是大块数据(缓冲区),这往往是在硬件直接存储器存取(DMA)的协助下完成的。而 JVM 的 I/O 类喜欢操作小块数据——单个字节、几行文本。结果,操作系统送来整缓冲区的数据,java.io 的流数据类再花大量时间把它们拆成小块,往往拷贝一个小块就要往返于几层对象。操作系统喜欢整卡车地运来数据,java.io 类则喜欢一铲子一铲子地加工数据。有了 NIO,就可以轻松地把一卡车数据备份到您能直接使用的地方(ByteBuffer 对象)。
一 流IO---块IO的区别
1)面向流I/O的系统:
一次处理一个字节的数据。一个输入流每次会读入一个字节的数据,一个输出流同样每次次消费一个字节的数据。对于流式数据,很容易创建过滤器。可以相对简单地把几个过滤器连接在一起,每个过滤器完成自己的工作,也是按字节进行过滤,精细的处理机制。另一方面,面向流I/-O的通信往往比较缓慢。
2)面向块I/O的系统:
以块为单位处理数据。每个操作步骤会生成或消费一个块的数据。以块为单位处理数据,其处理速度远快于以字节流为单位的方式。但是,与面向流I/O的通信相比,面向块I/O的通信缺乏优雅和简洁。
新的抽象把重点放在了如何缩短抽象与现实之间的距离上面。NIO 抽象与现实中存在的实体有着非常真实直接的交互关系。关于何时该采用传统io,何时应该采用nio:
1) 扩展性考虑:
例如在进行Socket编程通信时每一个Socket都应占据一个线程。使用NIO虽然更富有效率,但相对难以编码和扩展。(当然这一现象在不断的被新的设计和NIO库的特性所改善)
2) 性能考虑:
在处理成千上万的连接时,你可能需要更好的传统IO的扩展性;但是如果连接数量较低时,你可能更注重NIO的高吞吐率。
3) 当使用SSL (Secure Sockets Layer,安全套接字层) 工作时,
选择NIO则实现难度很大
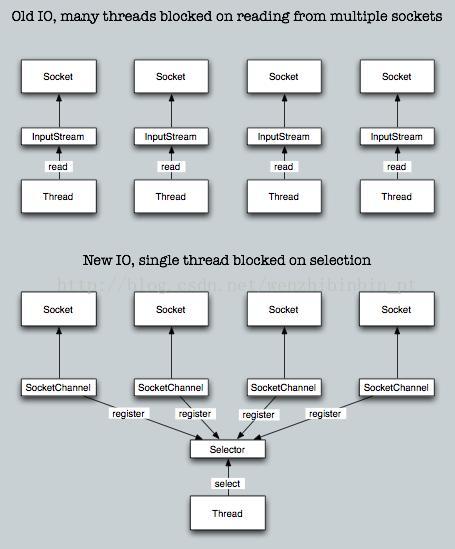
二 IOCP
2.1什么是 IOCP
随着计算机技术,尤其是网络技术的飞速发展,如今的程序开发人员不仅仅局限于基于单机运行或单一线程的应用程序的开发。服务器端 / 客户端模式的最显著的特点 是一个服务器端应用能同时为多个客户端提供服务。而传统的服务器端 / 客户端模式通常为每一个客户端创建一个独立的线程,这种实现方式在客户端数量不多的情况 下问题不大,但对于类似于铁路网络订票这样的瞬间客户数量巨大的系统来说,效率极端低下。这是因为一方面创建新线程操作系统开销较大,另一方面同时有许多线程 处于运行状态,操作系统内核需要花费大量时间进行上下文切换,并没有在线程执行上花更多的时间。因此,微软在 Winsocket2 中引入了 IOCP(Input/Output Completion Port)模型。IOCP 是 Input/Output Completion Port(I/O 完成端口)的简称。简单的说,IOCP 是一种高性能的 I/O 模型,是一种应用程序使用线程池处理异步 I/O 请求的机制。Java7 中对 IOCP 有了很好的封装,程序员可以非常方便的时候经过封装的 channel 类来读写和传输数据。
2.2同步 / 异步,阻塞 / 非阻塞
所谓同步,就是在发出一个功能调用时,在没有得到结果之前,该调用就不返回。按照这个定义,其实绝大多数函数或方法都是同步调用。
异步的概念和同步相对。当一个异步过程调用发出后,调用者不能立刻得到结果。实际处理这个调用的部件在完成后,通过状态、通知和回调来通知调用者。
通俗来讲,完成一件事再去做另外一件事就是同步,而一起做两件或者两件以上的事情就是异步了。
拿一个服务器与客户端通信的例子来说。
如果是同步:
Client 发送一条请求消息给 Server,这个时候 Client 就会等待 Server 处理该请求。这段时间内 Client 只有等待直到 Server 回复响应信息给 Client。Client 只
有收到该响应信息后,才能发起第二条请求消息。这样无疑大大降低了系统的性能。
而如果是异步:
Client 发送一条请求消息给 Server,Client 并不等待 Server 的处理结果,而是继续发送第二条甚至更多的请求消息。Server 会将这些请求都存入队列,逐条处理,并将处理完的结果回复给 Client。这样一来,Client 就可以不用等待,效率大大提高。
阻塞调用
是指调用结果返回之前,当前线程会被挂起。函数或方法只有在得到结果之后才会返回。阻塞和同步有点类似,但是同步调用的时候线程还是处于激活状态,而
阻塞时线程会被挂起。
非阻塞调用和阻塞的概念相对应,指在不能立刻得到结果之前,该函数或方法不会阻塞当前线程而是立刻返回。
清单 1. 传统的网络应用代码
try {
ServerSocket server = new ServerSocket(9080);
while (true) {
Socket client = server.accept();
new Thread(new SocketHandle(client)).start();
}
} catch (IOException e) {
e.printStackTrace();
}
相信只要写过网络应用程序的朋友,应该对这样的结构再熟悉不过了。Accept 后线程被挂起,等待一个客户发出请求,而后创建新线程来处理请求。当新线程处理客户请求时,起初的线程循环回去等待另个客户请求。在这个并发模型中,对每个客户都创建了一个线程。其优点在于等待请求的线程只需要做很少的工作,而大部分的时间,该线程在休眠,因为 recv 处于阻塞状态。如前文所述,创建线程的开销远远大于程序员的预计,尤其是在并发量巨大的情况下,这种传统的并发模型效率极端低下。解决这个问题的方法之一就是 IOCP,说白了 IOCP 就是一个消息队列。我们设想一下,如果事先开好 N 个线程,让它们 hold 住,将所有用户的请求都投递到一个消息队列中去。让后这 N 个线程逐一从消息队列中去取出消息并加以处理。这样一来,就可以避免对没有用户请求都开新线程,不仅减少了线程的资源,也提高了线程的利用率。
2.3IOCP 实现的基本步骤
那么 IOCP 完成端口模型又是怎样实现的呢?首先我们创建一个完成端口 CreateIOCompletionPort,然后再创建一个或多个工作线程,并指定它们到这个完成端口上去读取数据。再将远程连接的套接字句柄关联到这个完成端口。工作线程调用 getQueuedCompletionStatus 方法在关联到这个完成端口上的所有套接字上等待 I/O 的完成 ,再判断完成了什么类型的 I/O,然后接着发出 WSASend 和 WSARecv,并继续下一次循环阻塞在 getQueuedCompletionStatus。具体的说,一个完成端口大概的处理流程包括:
创建一个完成端口;
Port port = createIoCompletionPort(INVALID_HANDLE_VALUE, 0, 0, fixedThreadCount());
创建一个线程 ThreadA;
ThreadA 线程循环调用 GetQueuedCompletionStatus 方法来得到 I/O 操作结果,这个方法是一个阻塞方法;
While(true){
getQueuedCompletionStatus(port, ioResult);
}
主线程循环调用 accept 等待客户端连接上来;
主线程 accept 返回新连接建立以后,把这个新的套接字句柄用 CreateIoCompletionPort 关联到完成端口,然后发出一个异步的 Read 或者 Write 调用,因为是异
函数,Read/Write 会马上返回,实际的发送或者接收数据的操作由操作系统去做。
if (handle != 0L) {
createIoCompletionPort(handle, port, key, 0);
}
主线程继续下一次循环,阻塞在 accept 这里等待客户端连接。
操作系统完成 Read 或者 Write 的操作,把结果发到完成端口。
ThreadA 线程里的 GetQueuedCompletionStatus() 马上返回,并从完成端口取得刚完成的 Read/Write 的结果。
在 ThreadA 线程里对这些数据进行处理 ( 如果处理过程很耗时,需要新开线程处理 ),然后接着发出 Read/Write,并继续下一次循环阻塞在 GetQueuedCompletionStatus() 这里。
2.4 Java 中异步 I/O 和 IOCP
其实,JDK 中的 IOCP 的实现与前文中所描述的实现思想基本相同,唯一的区别是 JDK 中封装了相关的内部实现。Iocp 类:该类使用默认的访问修饰符,因此只能被同包(sun.nio.ch)的其他类访问。同时,创建 IOCP 端口的 createIoCompletionPort 方法也被封装在 Iocp 类的构造函数中,套接字的关联也不再需要调用 createIoCompletionPort 而是直接调用 Iocp 类的 associate 方法。
Iocp.CompletionStatus 类:Iocp 的内部类 CompletionStatus 用于存取完成端口的状态信息。
Iocp.EventHandlerTask 类:Iocp 的内部类 EventHandlerTask 用来将 I/O 操作的 Handle 关联到完成端口,循环的获取完成端口的状态,根据操作系统返回的完成端 口状态从任务队列中提取下一个要执行的任务并调用执行。
Iocp 的调用类:sun.nio.ch 包中的 WindowsAsynchronousSocketChannelImpl、WindowsAsynchronousServerSocketChannelImpl 和 WindowsAsynchronousFileChannelImpl 等类使用了 Iocp 类的相关方法,达到多并发量时的高性能 I/O 访问。
Native 方法:Iocp 类中的许多内部方法都是通过调用 JNI 方法实现的。
实例分析
从上节描述中,您或许会意识到,Java7 中对 IOCP 进行了很好的封装。我们可以直接使用 JDK 中众多的 ChannelImpl 类,这些类的读写操作都应用了 Iocp 类。当然,您也可以将自定义的逻辑实现类放置在 sun.nio.ch 包中以重用 Iocp 类,甚至还可以自己编写和实现 Iocp 类。本节中,我们通过一个 Log 传输的具体实例来看 Iocp 以及应用类在实际应用中的使用。
假设现在有建立了连接的服务器端和客户端,服务器端执行得到的大量 Log 信息需要传输到客户端的 console 中。这些信息的传输必须是异步的,也就是说服务器端不 等待传输的完成而是继续执行并产生更多的 Log 信息。同时,Log 信息在 channel 上传输的时候又必须是同步的,这样才能保证 Log 信息的时间次序保持一致。 首先,服务器端监听端口,建立与客户端通信的 channel。
清单 2. 建立 channel
final AsynchronousServerSocketChannel server = AsynchronousServerSocketChannel.open();
server.bind(new InetSocketAddress(port));
server.accept(
new Session(null), new CompletionHandler
{
public void completed(AsynchronousSocketChannel ch,Session session) {
Session s = new Session(ch);
server.accept(s, this);
}
public void failed(Throwable e, Session session) {
}
});
服务器端主线程并不直接将 Log 信息通过 channel 输出到客户端的 console 上。而是调用 writeMessage 方法将执行得到的 log 信息写入事先准备好的 messageQueue 里,并继续业务逻辑的执行。
清单 3. 写入 log 到 Queue
public synchronized void flush() throws IOException {
int size = buffer.position();
Message msg = new Message(this.msgType, new byte[size]);
buffer.rewind();
final Object mutex = new Object();
buffer.get(msg.body);
buffer.rewind();
session.writeMsg(msg);
}
Public void writeMessage(Message msg) {
synchronized(messageQueue) {
messageQueue.offer(msg);
}
}
同时,另一个线程负责不断从 messageQueue 中读取 Log 信息,顺序写到 channel 上传输给客户端 console。WriteCompletionHandler 是 CompletionHandler 接口的自定义实现类,用来控制每次 channel 上的写操作必须完成才返回,避免混淆输出的 Log 次序。
清单 4. 从 Queue 中读取并传输 Log 至客户端
Thread thread=new Thread(new Runnable(){
public void run(){
Message msg = null;
synchronized(messageQueue){
msg = messageQueue.poll();
ByteBuffer byteBuffer = msg.pasteByteBuffer();
synchronized(canWrite){
channel.write(byteBuffer, new WriteCompletionHandler(msg));
}
}
}
}).start();
这样一来,我们能很轻松的使用 channelImpl 类来网络应用,而且如果您深入到这些 channelImpl 类的内部去,您就会看到许多逻辑的实现都依赖了底层的 sun.nio.ch.Iocp 类。
三 对比Java.nio 和 Java.io
java.io 概览
这个包通过数据流和序列化机制来实现系统输入和输出。并且支持多种类型的数据流,包括简单的字节、原生数据类型、地区字符以及对象。流是一个数据的序列:一个程序使用输入流从一个源头读取数据;一次处理一个字节的数据。一个输入流每次会读入一个字节的数据,一个输出流同样每次次消费一个字节的数据
另一个程序使用输出流写入并发送数据到目的地。

这些程序都使用字节流来执行字节的输入和输出。所有涉及字节流的类都是继承自InputStream和OutputStream。
关于 InputStream 和 OutputStream
执行InputStream和OutputStream的操作一般都意味着不断循环的将字节逐一从输入流读出或写入到输出流。你可以使用缓冲I/O流来降低I/O成本(凡是I/O请求都经常触发磁盘访问、网络动作或其他一些成本昂贵的操作)。缓冲输入流则是从缓冲的内存区域读取数据,只有缓冲读完才会调用native input API(不同操作系统提供的本地输入流API——译者注)。同样的,缓冲输出流也将数据写入缓冲,只有缓冲写满才会调用native output API。这些带缓冲的API很好的封装了未缓冲的流操作: BufferedInputStream 和 BufferedOutputStream.
File I/O
上面一节主要是针对数据流,它提供一种数据读取和写入的简单模型。真实的数据流其实是涉及种类繁多的数据源和目的地,包括磁盘文件。但是,数据流并不支持所有磁盘文件操作。下面的链接介绍了非数据流的文件I/O:
- File 类可以编写平台无关的检查和处理文件、目录的代码。
- Random access files支持非序列化的磁盘文件数据访问。
java.net socket
两个在网络上运行的程序之间会建立双向通讯的链接,socket就是其中一个端点。Socket相关的类代表着客户端程序和服务端程序之间的连接。java.net包提供了两个类:Socket和ServerSocket。它们分别实现了连接的客户端和服务端。
客户端知道服务端运行机器的域名,以及服务器监听的端口,它尝试连接到服务器,如果一切正常,服务器接受并建立连接。当接受连接时,服务器在监听端口上绑定一个新的socket,并且通知远程端点设置客户端的地址和端口。之所以要建立一个新的socket是为了处理已连接客户端请求的同时还能继续监听原始socket上的连接请求。
服务器使用阻塞模式等待客户端连接:serverSocket.accept()是一个阻塞指令,当服务器等待接受连接时主线程不能做任何其他操作。由于这个原因,服务器想要达到多任务处理就只能通过实现一个多线程服务器:每当新建一个socket时就必须为它创建一个新线程。
NIO API
I/O性能经常是一个现代应用的痛处。操作系统持续优化改进I/O性能,JVM也提供了一套运行环境帮助Java程序员规避了绝大多数操作系统I/O之间的差异。这些都让I/O相关编码更加高效和简单,但是却隐藏了操作系统的功能特性。想要增强I/O性能,其实你可以通过一些特殊的编码直接访问操作系统的底层功能,但是这并不是最佳解决方案——你的代码将必须依赖某个操作系统。 Java.nio包应运而生来解决这个难题,它提供了高性能的I/O特性,并支持当今大多数常用的商用操作系统。
JDK1.4的NIO包介绍了一系列新的I/O操作的抽象概念。
java.nio 概览
Java.nio这个新增的包实现了Java平台新的 I/O API。NIO API 包含如下特性:
- 原生类型数据缓冲buffer (Buffer只能与Channel通信)
- 字符集的编码器和解码器
- 基于Perl风格正则表达式的模式匹配
- 通道(Channel),一种新的原生I/O抽象概念
- 支持锁和内存映射的文件接口
- 通过多路复用、非阻塞的I/O能力实现可伸缩的服务器架构
在SUN(现Oracle)的站点上可以找到java.nio的详细技术文档。这里我将解释一些nio的概念,并且和老的java.io库做下比较。建议不要把java.nio当作java.io的替代品,即使它是java.io的“扩展”。Nio的诞生导致了整个I/O类和接口的重新修订(详情请看)。
NIO中一个最重要的概念是在非阻塞模式下运行,与传统Java I/O类库完全不同。什么是非阻塞模式?
Non blocking mode 非阻塞模式
一个I/O流的字节必须序列化的访问。各种设备,打印机端口、网络连接等都是常见的例子。
数据流通常比阻塞式设备慢,而且经常断断续续。大多数操作系统允许将数据流设置为非阻塞模式,允许进程检查是否流上是否有可用数据,即使没有也不会导致进程阻塞。这种机制能让进程在输入流空闲等待时执行其他逻辑,但是数据到达时又能及时处理。操作系统能够观察一堆的数据流并且指示其中哪些处于可用状态。通过观察这些可用状态,一个进程可以采用常用的编码和单个线程就能同时处理多个活动的数据流。这在网络服务器处理大量网络连接时被广泛使用。
Buffers 缓冲
从简单的入手,首先的改进是一系列java.io包中新建的缓冲类。这些缓冲提供了一个可以在内存容器中存储一堆原生类型数据的机制。一个缓冲对象是一个固定容量的容器,容器中的数据可以被读写。
所有的缓冲都是可读的,但并非都是可写的。每个缓冲类都实现了isReadOnly()方法来表示缓冲内容是否允许被修改。
Channels
缓冲需要配合Channel来使用。Channel是I/O传输的入口,缓冲则是数据传输的源头或目的地。在写入时,你想发送的数据首先被放入缓冲,接着被传递至一个Channel;在读取时,Channel负责接收数据,然后寄存至你提供的缓冲中。(比如在网络传输时的过程:用户数据——>发送端缓冲——>发送端Channel——>网络传输——>接收端Channel——>接收端缓冲——>用户数据,译者注)
Channel就像一个管道一样,将数据在管道两端的字节缓冲之间进行高效率的传输。它就像是一个网关,通过它可以用最小的成本来访问操作系统本地的I/O服务,而缓冲则是在两端内部的端点,Channel使用它来发送和接收数据。
Channel能在非阻塞模式下运行。一个非阻塞模式下的Channel不会让调用线程睡眠。请求的操作要么立刻完成、要么返回一个结果告知什么都没做。
只有面向数据流的Channel,比如socket,能够在非阻塞模式下运行。
在java.nio中的Channel包括FileChannel、ServerSocketChannel以及SocketChannel;这些都是为文件和socket管理所提供的特定的Channel。
FileChannel
FileChannel是可读可写的Channel,它必须阻塞,不能用在非阻塞模式中。面向数据流I/O的非阻塞风格并不适合面向文件的操作,因为文件I/O有本质上的区别。
FileChannel对象不能被直接创建。一个FileChannel实例只能通过在打开的文件对象(RandomAccessFile、FileInputStream、或FileOutputStream)上调用getChannel()得到。GetChannel()方法返回一个连接到相同文件的FileChannel对象,与文件对象拥有相同的访问权限。FileChannel对象是线程安全的。多线程能够并发的调用同一个实例上的方法而不会导致任何问题,但是并非所有操作是支持多线程的。影响Channel位置或者文件大小的操作必须是单线程的。
使用FileChannel,可以让拷贝等操作变成Channel到Channel的传输(transferTo()和transferFrom()方法),而且读写操作更易于使用缓冲。
SocketChannel
SocketChannel与FileChannel不同:新的Socket Channel能在非阻塞模式下运行并且是可选择的。不再需要为每个socket连接指派线程了。使用新的NIO类,一个或多个线程能管理成百上千个活动的socket连接,只用到很小甚至0的性能损失。使用Selector对象可以选择可用的Socket Channel。
有3个Socket Channel类型:SocketChannel, ServerSocketChannel, 以及 DatagramChannel; SocketChannel和DatagramChannel是可读可写的,ServerSocketChannel 监听到来的连接,并且创建新的SocketChannel 对象。所有这些SocketChannel初始化时会创建一个同等的socket对象(java.net sockets)。这个同等的socket能从Channel对象上调用socket()方法获取。每个Socket Channel (in java.nio.channels)对象拥有一个相关的java.net.socket对象,反之并非所有的socket对象拥有相关的Channel对象。如果你使用传统方式创建一个socket对象,直接初始化它,它将不会拥有一个相关的Channel对象,它的getChannel()方法会返回null。
Socket Channel能在非阻塞模式下运行。传统Java Socket阻塞的本性曾经是影响Java应用可伸缩性的罪魁祸首之一。而基于非阻塞I/O则构建了很多复杂巧妙的、高性能的应用。设置或重置Channel的阻塞模式很简单,只要调用configureBlocking()即可。
非阻塞socket常在服务器端使用因为它能让同时管理多个socket变得简单。
Selector 选择器
选择器(Selector)提供了挑选可用状态Channel的能力,从而实现多路复用的I/O。我下面的例子将很好的解释选择器的优势:
设想你在一个火车站(non-selector,非选择器场景),有3个平台 (channels), 每个平台都有火车到达(buffer,缓冲)。每个平台上都有个管理员管理着到达的列车(worker thread,工作线程)。这是非选择器的场景。现在设想下选择器场景。有3个平台(channels),每个平台会有火车到达(缓冲),每个平台都有个指示器(比如一个响铃)指示着“火车到达”(selection key)。在这个场景下只有一个管理员就可以管理所有的3个平台。他只需查看指示器(selector.select())来判断是否有火车到达然后去处理一下到达的列车。
理解selector场景的优势很简单:一个单线程就可以实现多重任务处理的应用。除此之外,使用非阻塞选择器还能得到更多好处!设想火车管理员看着指示器时:他可以等待新的列车到达而不做其他事(使用selector.select()的阻塞模式);也可以在等待新的列车到达时(非阻塞模式使用selector.selectNow())去卖车票,这样selector就会返回null让线程执行其他代码逻辑。
IO vs. NIO
NIO使得I/O比传统I/O更加高效。在一个I/O操作占很高比例的程序中,想想看会有什么不同。比如,如果一个应用需要使用socket拷贝文件或者传输字节,使用NIO可能会得到更快的性能,因为它比I/O的API更接近操作系统。随着数据量的增大,性能提升将更可观。除了io API里,NIO还为数据流操作提供了其他的功能特性。但是,不可能用NIO取代IO,因为NIO的API是基于java.io之上扩展的功能。NIO通过扩展本地的IO API,为广大开发者使用更加强大的方式操作数据流带来了新的可能性。
四 Java Nio学习心得
普通 IO 类 Stream 流传输 IO = 流传输(单字节传输)
NIO 类 NIO 块传输 ( 输入通道、缓冲区、输出通道 ) NIO = 缓冲区 + 通道(块传输)
缓冲区
缓冲区 Buffer 是一个对象, 它包含一些要写入或者刚读出的数据。在 NIO 库中,所有数据都是用缓冲区处理的。在读取数据时,它是直接读到缓冲区中的。在写入数据时,它是写入到缓冲区中的。任何时候访问 NIO中的数据,您都是将它放到缓冲区中。 缓冲区实质上是一个数组。通常它是一个字节数组,但是也可以使用其他种类的数组。但是一个缓冲区不仅仅 是一个数组。缓冲区提供了对数据的结构化访问,而且还可以跟踪系统的读/ 写进程。
缓冲区的类型
最常用的缓冲区类型是 ByteBuffer 。一个 ByteBuffer 可以在其底层字节数组上进行 get/set 操作 ( 即字节的获取和设置 ) 。实际上针对 java 的每一种基本类型都有对应的一个缓冲区类型。
· ByteBuffer
· CharBuffer
· ShortBuffer
· IntBuffer
· LongBuffer
· FloatBuffer
· DoubleBuffer
每一 个 Buffer 类都是 Buffer 接口的一个实例。 除了 ByteBuffer ,每一个 Buffer 类都有完全一样的操作,只是它们所处理的数据类型不一样。因为大多数标准 I/O 操作都使 用 ByteBuffer ,所以它具有所有共享的缓冲区操作以及一些特有的操作。
通道
通道 Channel 是一个对象,可以通过它读取和写入数据。拿 NIO 与原来的 I/O 做个比较,通道就像是流。正如前面提到的,所有数据都通过 Buffer 对象来处理。您永远不会将字节直接写入通道中,相反,您是将数据写入包含一个或者多个字节的缓冲区。同样,您不会直接从通道中读取字节,而是将数据从通道读入缓冲区,再从缓冲区获取这个字节。
通道类型
通道与流的不同之处在于通道是双向的。而流只是在一个方向上移动 ( 一个流必须是 InputStream 或者OutputStream 的子类 ) , 而 通道 可以用于读、写或者同时用于读写。因为它们是双向的,所以通道可以比流更好地反映底层操作系统的真实情况。特别是在 UNIX 模型中,底层操作系统通道是双向的。
从文件中读取
如果使用原来的 I/O ,那么我们只需创建一个 FileInputStream 并从它那里读取。而在 NIO 中,情况稍有不同:我们首先从 FileInputStream 获取一个 FileChannel 对象,然后使用这个通道来读取数据。
在 NIO 系统中,任何时候执行一个读操作,您都是从通道中读取,但是您不是直接 从通道读取。因为所有数据最终都驻留在缓冲区中,所以您是从通道读到缓冲区中。
因此读取文件涉及三个步骤: (1) 从 FileInputStream 获取 Channel , (2) 创建 Buffer , (3) 将数据从Channel 读到 Buffer 中。
第一步是从 FileInputStream 获取通道:
FileInputStream fin = new FileInputStream( "readandshow.txt" );FileChannel fc = fin.getChannel();下一步是创建缓冲区:
ByteBuffer buffer = ByteBuffer.allocate( 1024 );最后,将数据从通道读到缓冲区中:
fc.read( buffer );您会注意到,我们不需要告诉通道要读多少数据 到缓冲区中。每一个缓冲区都有复杂的内部统计机制,它会跟踪已经读了多少数据以及还有多少空间可以容纳更多的数据。
写入文件
在 NIO 中写入文件类似于从文件中读取。
首先从 FileOutputStream 获取一个通道:
FileOutputStream fout = new FileOutputStream( "writesomebytes.txt" );
FileChannel fc = fout.getChannel();
下一步是创建一个缓冲区并在其中放入一些数据。
ByteBuffer buffer = ByteBuffer.allocate( 1024 );
for (int i=0; i
buffer.put( message[i] );
}
buffer.flip();
最后一步是写入缓冲区中:
fc.write( buffer );
注意在这里同样不需要告诉通道要写入多数据。缓冲区的内部统计机制会跟踪它包含多少数据以及还有多少数据要写入。
在从输入通道读入缓冲区之前,我们调用 clear() 方法。同样,在将缓冲区写入输出通道之前,我们调用 flip() 方法。
clear() 方法重设缓冲区,使它可以接受读入的数据。
flip() 方法让缓冲区可以将新读入的数据写入另一个通道。
参考:http://www.ibm.com/developerworks/cn/java/j-lo-iocp/
http://www.importnew.com/1178.html
http://blog.csdn.net/zhaozheng7758/article/details/5255400