分析B站10万条弹幕后,发现了歪嘴战神的终极奥义!


作者 | 数据不吹牛
最近,歪嘴战神血洗b站,靠着“耐克式微笑"成功出圈,迷倒众生。
这次,小z爬取了10万条相关弹幕,从数据分析的角度,扒一扒歪嘴战神那该死的狷狂魅力。

歪嘴战神 何方神圣?
歪嘴战神,是一系列爽文改编的视频小广告主角,这些视频套路简单,短小精悍,演员不换,土到极致透着一股雅致:
前期20秒,主角背景介绍,手眼通天是常态,牛逼到玉帝见了都想拜把子。
中期30秒,主角(被猪油蒙了心)抛家舍业,非要上赶着当倒插门女婿。因为隐瞒了身份,所以在妻家饱受羞辱,据我统计,这30秒至少会被推倒在地1.5次,被3个人嘲讽3次,顺便挨3个大嘴巴子。
后期10秒,小弟滑跪戳破身份,中期有眼不识泰山的人纷纷磕头如捣蒜,最后,战神从兜里掏出结婚证撕个稀里哗啦,然后露出标志性的歪嘴笑,留给观众无尽的遐想。
歪嘴战神只是他一个身份,他!
时而是手握太乙玄针包治百病的神医;
时而是为战死北疆108位兄弟隐姓埋名的修罗王;
时而是百亿订单说送就送的帝都龙王;
千变万化的牛X身份背后,是不变的歪嘴笑。

小z诗云:歪嘴一笑百媚生,b站鬼畜无颜色。

战神到底有多火?
我爬取了b站“歪嘴战神”关键词下50页(最多只能爬这么多)视频,截至8月14日,累计播放量已经高达8207万。
播放量还在以每天2000万的速度飞跑....
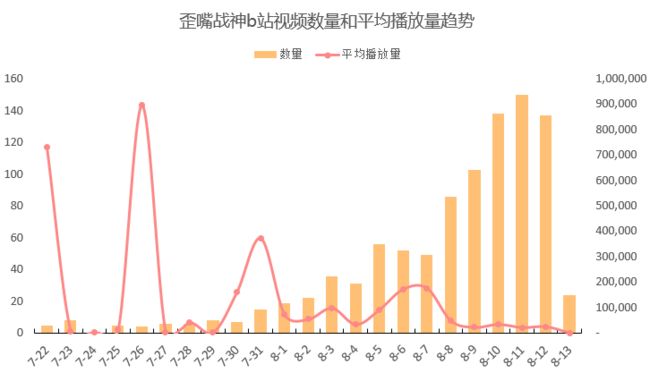
通过每天上传视频数量和平均播放量数据可以发现:
7月22日,是歪嘴战神在b站的生日,这一天UP主“Bullet蛋蛋”上传了标题为“歪嘴战神”的视频,实现小范围引爆。
26日,“李子alt”奉上“最强赘婿”佳作,再一次扩散歪嘴风采。
随后,关于歪嘴战神的创作热情也开始高涨,最近每天有超过100位UP主入场,用创作能力来致敬歪嘴奥义。
再看歪嘴战神和中年实力炸子鸡沈腾的百度指数对比,结果更一目了然。(点击可看大图)
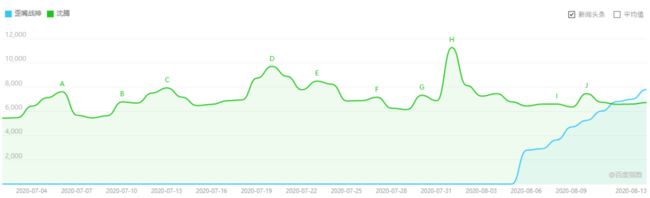
世界上本没有歪嘴战神,搜的人多了,也便有了战神。
8月5日“歪嘴战神”作为一个词条被收录,当天旱地拔葱,搜索指数从0飙升到2795,之后是波浪式飙升。
6天之后,搜索指数超过了沈腾叔叔,还在持续昂扬。
照这个趋势和斜率:
流量鲜肉,弹指可破!
歪嘴顶流,指日可待!
简单的剧情 是弹幕的狂欢
一哥们说他已经20刷了,根本停不下来....
看上去沙雕无比的剧情,为什么让这么多人沉迷其中无法自拔?
难道人类的本质不止是复读机,还是沙雕?
我决定从弹幕入手,基于爬取的10万条弹幕,提取关键信息做了个词云图:

弹幕大体分三层:
第一层,哈哈怪。用“哈哈哈”、“炫炫炫”和“???”三把神剑打遍天下无敌手。
第二层,歪嘴死忠粉。战神最后歪嘴一笑,用漫天的弹幕“√”来模拟龙王微笑的幅度。
第三层,剧情复读机。紧跟剧情,被嘲讽时狂发《loser》和《隐忍》,战神翻身时《家主有令》和《别后悔》,战神归位后《有眼无珠》、《弹指可灭》。
三类弹幕的加持下,歪嘴战神更加所向披靡。

Why 歪嘴战神
爽文和改编的小广告,套路都非常简单,无非是先抑后扬。
而歪嘴战神格外出圈!
靠的是恰到好处的浮夸演技,取材于成语大全的铿锵台词。
沙雕到全是破绽但就是好笑的人物设定和千篇一律演员不换的魔幻剧情。
当然,最最最重要的,还是每一集末尾,战神最后的歪嘴一笑。
这是一个无敌的视觉锤,每一捶都砸在观众的痒点,让人欲罢不能。
这一笑,看似简单,实则不然。我模仿了不下百次,还是四不像。
后来看了本尊“管云鹏”(本尊已入b站)的亲自讲解,才知道想要身形具备,必须严格遵守:
“一是转头果断,二是眼神坚定,三是叹气带笑”的歪嘴定律。
你学会了吗?

太魔性了,我要继续去刷歪嘴战神系列,没错,连喜羊羊都已经歪嘴化了....
最后,小z奉上B站爬取核心代码,逻辑并不复杂,有机会拎出来展开讲讲:
import pandas as pdimport osimport requestsfrom lxml import etreeimport randomimport time
#根据搜索关键字按点击量爬取视频数据def get_target(url,num = 10): result = pd.DataFrame()
for i in range(1,num + 1): headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36'} html = requests.get(url.format(i),headers = headers) bs = etree.HTML(html.text)
for sig in bs.xpath('//li[@class = "video-item matrix"]'): title = sig.xpath('div[@class = "info"]/div/a/@title')[0] click = sig.xpath('div[@class = "info"]/div[3]/span[1]')[0].xpath('string(.)').strip('\n ') danmu = sig.xpath('div[@class = "info"]/div[3]/span[2]')[0].xpath('string(.)').strip('\n ') date = sig.xpath('div[@class = "info"]/div[3]/span[3]')[0].xpath('string(.)').strip('\n ') up = sig.xpath('div[@class = "info"]/div[3]/span[4]')[0].xpath('string(.)').strip('\n ') df = pd.DataFrame({'标题':[title],'播放量':[click],'弹幕':[danmu],'日期':[date],'UP主':[up]}) result = pd.concat([result,df])
time.sleep(random.random() + 0.5) print('已经完成b站第 {} 页爬取'.format(i))
return result
#爬取单集单日弹幕def get_one_day(url,headers,cookies):
lst = [] html = requests.get(url,headers,cookies = cookies) bs = etree.HTML(html.text.encode('utf8'))
for i in bs.xpath('//d'): dm = i.text.encode('iso-8859-9').decode('utf8') lst.append(dm) df = pd.DataFrame({'弹幕':lst}) df['日期'] = url[-10:] df['oid'] = url[url.find('oid=') + 4:url.find('&date')]
time.sleep(1 + random.random())
return df

 更多精彩推荐
更多精彩推荐
☞英伟达收购,ARM也要变美国公司,国产芯出路几何?
☞作为一个前端,你需要会什么?| 每日趣闻
☞腾讯申请微信儿童版商标;苹果发布全球首款 5nm仿生芯片;Java 15 发布|极客头条
☞OpenCV 实现视频稳流,附Python与C++代码!| 防抖技术
☞“蚂蚁漫步”背后的定位原理思考
☞200美元变290000美元,这个DeFi用户经历了什么?
点分享点点赞点在看