前言
在一个天朗气清的日子,小灰登上了线上的redis打算查询数据。然而他只记得前缀而不知道整个键是多少,于是在命令行敲入了“keys xxx*”命令。
瞬间服务卡死,报警邮件堆满了邮箱,而小灰,只能目瞪狗呆的等待着即将降临的case study。
基本上,keys *命令都是在线上是被运维禁止的。
redis的键在键值对大小大于hash-max-ziplist-value且个数小于hash-max-ziplist-entries的时候,是存放在散列表数据结构中的,在运行keys命令的时候,需要遍历数据库键空间,把所有键都取出来后与keys后面的pattern匹配。
在键很多的情况下,redis可能的卡顿会在秒级以上,导致所有流量都打到数据库,使得数据库雪崩。
那我们怎么才能够在查找到目标键呢?在redis2.8.0的时候加入了scan命令,可以分批次扫描redis键。虽然在应用的时候会使得要查询到全部符合要求的key的时间变长,但是大大大大减少了redis卡顿的几率
在这里先补充一下背景:
redis中的字典rehash是渐进式哈希,即不是一次性把所有的键都迁移到新的哈希表,而是在下面两种情况下迁移数据:
每次哈希表操作的时候,如果当前正在rehash,则迁移一个节点;
服务空闲时,会rehash一百个节点。
scan命令可以保证在(没有键修改的)字典正在rehash的过程中做到以下两点:
- 不出现重复数据
- 不遗漏数据
那scan命令是怎么做到在rehash过程中都能不重复不遗漏地遍历所有节点的呢?让我们来一起走读一下源码。
Let's GO!
在使用scan命令的时候,我们每次传入一个游标(从0开始),然后下一轮继续使用本轮redis返回的游标。scan字典的核心函数是dictScan,而dictScan的更新游标的核心代码如下:
v |= ~m0;//或者m1 /* Increment the reverse cursor */ v = rev(v); v++; v = rev(v);
其中m0、m1为当前哈希表大小减一,rev是二进制逆序。
看到这里,不知道在座的各位是不是也是跟我一样是下面这个表情
让我们来模拟一下问题,就清楚了。
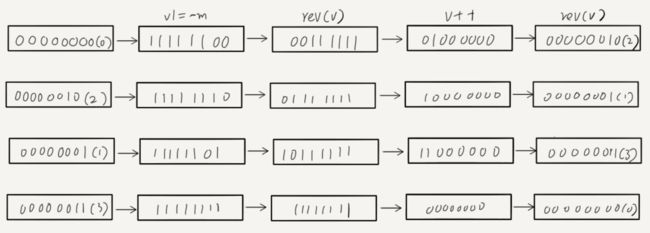
我们假设现在在一个四个节点的哈希表中遍历,如下图,游标的遍历节点为:0 -> 2 -> 1 -> 3 :
再来模拟8节点的情况:
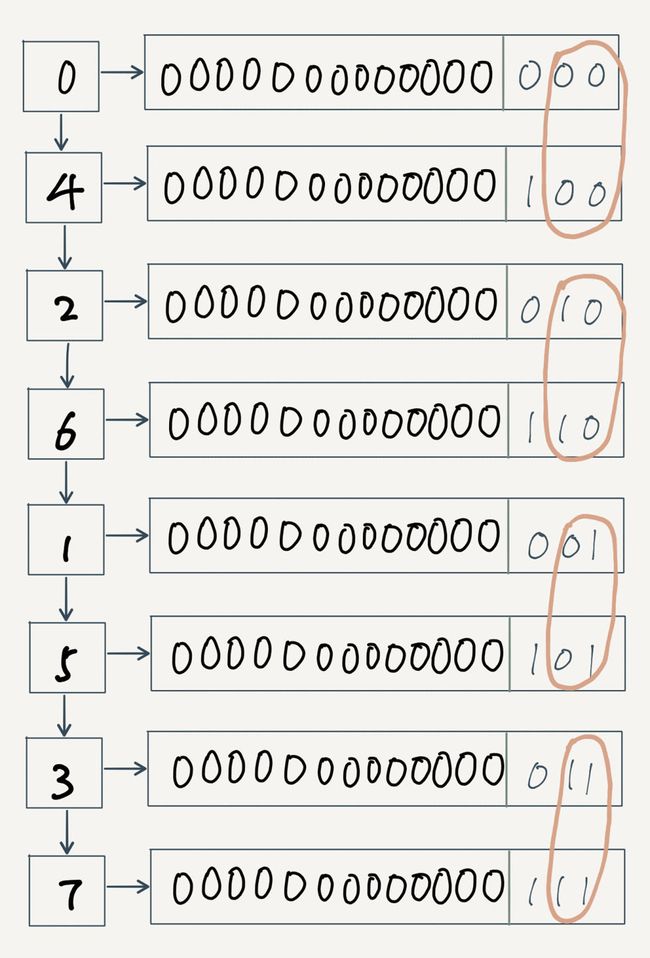
看到这里是不是稍微明白了,上面那段代码就是在当前的有效位数(比如四节点则有效位数2)范围内,从左到右进一位。
假设在遍历了0,返回2之后,字典进行了扩容,则接下来应该访问 2 -> 6 -> 1 -> 5 -> 3 -> 7。
小灰:咦,那4不是遗漏了吗?
4已经在第一轮遍历0的时候,把扩容后的4的数据也访问了。
所以,假设扩容前有效位为m,因为redis的哈希表扩容每次都是当前节点满了( use==size)的时候扩容为大于size的2^N,所以扩容后有效位则为m+1。
上面那段代码其实是保持低位的m位不变,高位一个为0一个为1。这样就保证了扩容后,跳过了的节点已经在之前被访问过,因为跳过的节点是被访问过的节点分出来的。
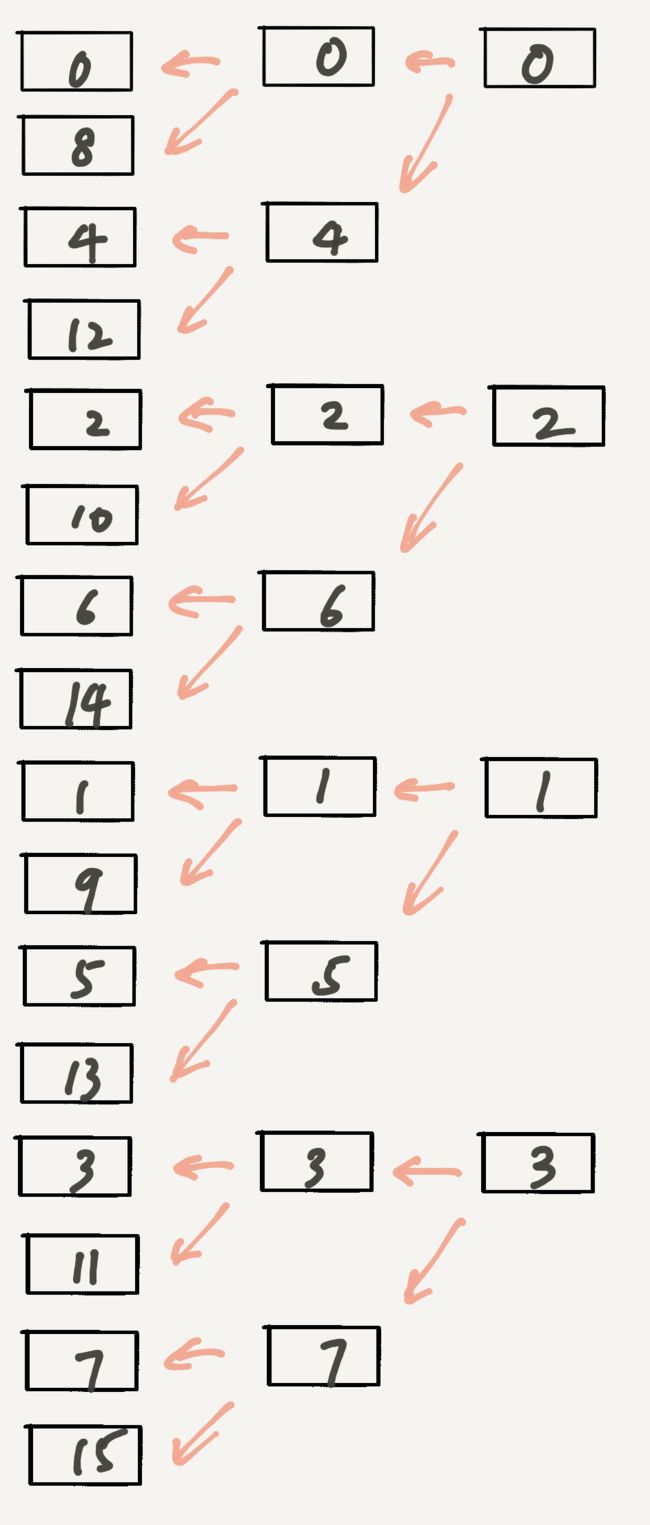
缩容同理,可以自己推一下。
看到这里,是不是觉得redis的scan游标设计的很巧妙呢?
小灰:原来如此,看来我又可以去查数据了呢!
最后附上完整的rehash过程中scan的代码:
// 指向两个哈希表
t0 = &d->ht[0];
t1 = &d->ht[1];
/* Make sure t0 is the smaller and t1 is the bigger table */
// 确保 t0 比 t1 要小
if (t0->size > t1->size) {
t0 = &d->ht[1];
t1 = &d->ht[0];
}
// 记录掩码
m0 = t0->sizemask;
m1 = t1->sizemask;
/* Emit entries at cursor */
// 指向桶,并迭代桶中的所有节点
de = t0->table[v & m0];
while (de) {//迭代第一张小hash表
next = de->next;
fn(privdata, de);
de = next;
}
/* Iterate over indices in larger table that are the expansion
* of the index pointed to by the cursor in the smaller table */
do {//迭代第二张大hash表
/* Emit entries at cursor */
if (bucketfn) bucketfn(privdata, &t1->table[v & m1]);
de = t1->table[v & m1];
while (de) {
next = de->next;
fn(privdata, de);
de = next;
}
//计算一个哈希表节点索引的方法 是 hash(key)&mask。哈希表容量为 8,则 mask 为 111,因此,节点的索引值就取决于哈希值的低 3 bit,
// 设索引值是 abc。如果哈希表容量为 16,则 mask 为 1111,该节点的哈希值不变,而索引值是 ?abc,其中 ? 取 0 或 1 中的一个,
// 也就是说,该节点在容量为 16 的哈希表中,索引要么是 0abc 要么是 1abc。以此类推,如果哈希表容量为32,
// 则该节点的索引可能是 00abc,01abc,10abc 或者 11abc 中的一个。/* Increment the reverse cursor not covered by the smaller mask.*/
v |= ~m1;//用于保留 v 的低 n 位数,其余位全置为 1
//下面这一段,最终得到的新 v,就是向最高位加 1,且向低位方向进位
v = rev(v);//将 v 的二进制位进行翻转,所以,v的低 n 位数成了高 n 位数,并且进行了翻转
v++;
v = rev(v);//再次二进制翻转
/* Continue while bits covered by mask difference is non-zero */
} while (v & (m0 ^ m1));//终止条件是 v的高位区别位没有1了,其实就是说到头了。
总结
到此这篇关于redis中scan命令的基本实现方法的文章就介绍到这了,更多相关redis中scan命令实现内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!