本系列文章将介绍用户从 Spring Cloud,Dubbo 等传统微服务框架迁移到 Istio 服务网格时的一些经验,以及在使用 Istio 过程中可能遇到的一些常见问题的解决方法。
故障现象
该问题的表现是安装了 sidecar proxy 的应用在启动后的一小段时间内无法通过网络访问 pod 外部的其他服务,例如外部的 HTTP,MySQL,Redis等服务。如果应用没有对依赖服务的异常进行容错处理,该问题还常常会导致应用启动失败。下面我们以该问题导致的一个典型故障的分析过程为例对该问题的原因进行说明。
典型案例:某运维同学反馈:昨天晚上 Istio 环境中应用的心跳检测报 connect reset,然后服务重启了。怀疑是 Istio 环境中网络不稳定导致了服务重启。
故障分析
根据运维同学的反馈,该 pod 曾多次重启。因此我们先用 kubectl logs --previous 命令查询 awesome-app 容器最后一次重启前的日志,以从日志中查找其重启的原因。
kubectl logs --previous awesome-app-cd1234567-gzgwg -c awesome-app从日志中查询到了其重启前最后的错误信息如下:
Logging system failed to initialize using configuration from 'http://log-config-server:12345/******/logback-spring.xml'
java.net.ConnectException: Connection refused (Connection refused)
at java.net.PlainSocketImpl.socketConnect(Native Method)
at java.net.AbstractPlainSocketImpl.doConnect(AbstractPlainSocketImpl.java:350)
at java.net.AbstractPlainSocketImpl.connectToAddress(AbstractPlainSocketImpl.java:206)从错误信息可以得知,应用进程在启动时试图通过 HTTP 协议从配置中心拉取 logback 的配置信息,但该操作由于网络异常失败了,导致应用进程启动失败,最终导致容器重启。
是什么导致了网络异常呢?我们再用 Kubectl get pod 命令查询 Pod 的运行状态,尝试找到更多的线索:
kubectl get pod awesome-app-cd1234567-gzgwg -oyaml命令输出的 pod 详细内容如下,该 yaml 片段省略了其他无关的细节,只显示了 lastState 和 state 部分的容器状态信息。
containerStatuses:
- containerID:
lastState:
terminated:
containerID:
exitCode: 1
finishedAt: 2020-09-01T13:16:23Z
reason: Error
startedAt: 2020-09-01T13:16:22Z
name: awesome-app
ready: true
restartCount: 2
state:
running:
startedAt: 2020-09-01T13:16:36Z
- containerID:
lastState: {}
name: istio-proxy
ready: true
restartCount: 0
state:
running:
startedAt: 2020-09-01T13:16:20Z
hostIP: 10.0.6.161从该输出可以看到 pod 中的应用容器 awesome-app 重启了两次。整理该 pod 中 awesome-app 应用容器和 istio-proxy sidecar 容器的启动和终止的时间顺序,可以得到下面的时间线:
- 2020-09-01T13:16:20Z istio-proxy 启动
- 2020-09-01T13:16:22Z awesome-app 上一次启动时间
- 2020-09-01T13:16:23Z awesome-app 上一次异常退出时间
- 2020-09-01T13:16:36Z awesome-app 最后一次启动,以后就一直正常运行
可以看到在 istio-proxy 启动2秒后,awesome-app 启动,并于1秒后异常退出。结合前面的日志信息,我们知道这次启动失败的直接原因是应用访问配置中心失败导致。在 istio-proxy 启动16秒后,awesome-app 再次启动,这次启动成功,之后一直正常运行。
istio-proxy 启动和 awesome-app 上一次异常退出的时间间隔很短,只有2秒钟,因此我们基本可以判断此时 istio-proxy 尚未启动初始化完成,导致 awesome-app 不能通过istio-proxy 连接到外部服务,导致其启动失败。待 awesome-app 于 2020-09-01T13:16:36Z 再次启动时,由于 istio-proxy 已经启动了较长时间,完成了从 pilot 获取动态配置的过程,因此 awesome-app 向 pod 外部的网络访问就正常了。
如下图所示,Envoy 启动后会通过 xDS 协议向 pilot 请求服务和路由配置信息,Pilot 收到请求后会根据 Envoy 所在的节点(pod或者VM)组装配置信息,包括 Listener、Route、Cluster等,然后再通过 xDS 协议下发给 Envoy。根据 Mesh 的规模和网络情况,该配置下发过程需要数秒到数十秒的时间。由于初始化容器已经在 pod 中创建了 Iptables rule 规则,因此这段时间内应用向外发送的网络流量会被重定向到 Envoy ,而此时 Envoy 中尚没有对这些网络请求进行处理的监听器和路由规则,无法对此进行处理,导致网络请求失败。(关于 Envoy sidecar 初始化过程和 Istio 流量管理原理的更多内容,可以参考这篇文章 Istio流量管理实现机制深度解析) 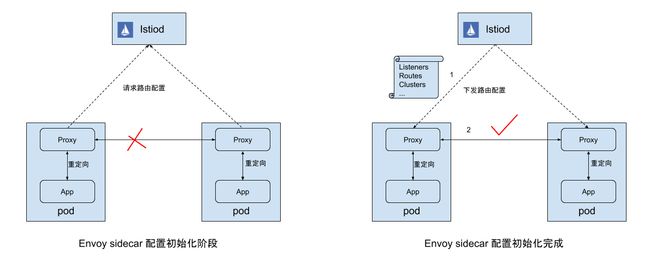
解决方案
在应用启动命令中判断 Envoy 初始化状态
从前面的分析可以得知,该问题的根本原因是由于应用进程对 Envoy sidecar 配置初始化的依赖导致的。因此最直接的解决思路就是:在应用进程启动时判断 Envoy sidecar 的初始化状态,待其初始化完成后再启动应用进程。
Envoy 的健康检查接口 localhost:15020/healthz/ready 会在 xDS 配置初始化完成后才返回 200,否则将返回 503,因此可以根据该接口判断 Envoy 的配置初始化状态,待其完成后再启动应用容器。我们可以在应用容器的启动命令中加入调用 Envoy 健康检查的脚本,如下面的配置片段所示。在其他应用中使用时,将 start-awesome-app-cmd 改为容器中的应用启动命令即可。
apiVersion: apps/v1
kind: Deployment
metadata:
name: awesome-app-deployment
spec:
selector:
matchLabels:
app: awesome-app
replicas: 1
template:
metadata:
labels:
app: awesome-app
spec:
containers:
- name: awesome-app
image: awesome-app
ports:
- containerPort: 80
command: ["/bin/bash", "-c"]
args: ["while [[ \"$(curl -s -o /dev/null -w ''%{http_code}'' localhost:15020/healthz/ready)\" != '200' ]]; do echo Waiting for Sidecar;sleep 1; done; echo Sidecar available; start-awesome-app-cmd"]该流程的执行顺序如下:
- Kubernetes 启动 应用容器。
- 应用容器启动脚本中通过
curl get localhost:15020/healthz/ready查询 Envoy sidcar 状态,由于此时 Envoy sidecar 尚未就绪,因此该脚本会不断重试。 - Kubernetes 启动 Envoy sidecar。
- Envoy sidecar 通过 xDS 连接 Pilot,进行配置初始化。
- 应用容器启动脚本通过 Envoy sidecar 的健康检查接口判断其初始化已经完成,启动应用进程。
该方案虽然可以规避依赖顺序的问题,但需要对应用容器的启动脚本进行修改,对 Envoy 的健康状态进行判断。更理想的方案应该是应用对 Envoy sidecar 不感知。
通过 pod 容器启动顺序进行控制
通过阅读 Kubernetes 源码 ,我们可以发现当 pod 中有多个容器时,Kubernetes 会在一个线程中依次启动这些容器,如下面的代码片段所示:
// Step 7: start containers in podContainerChanges.ContainersToStart.
for _, idx := range podContainerChanges.ContainersToStart {
start("container", containerStartSpec(&pod.Spec.Containers[idx]))
}因此我们可以在向 pod 中注入 Envoy sidecar 时将 Envoy sidecar 放到应用容器之前,这样 Kubernetes 会先启动 Envoy sidecar,再启动应用容器。但是还有一个问题,Envoy 启动后我们并不能立即启动应用容器,还需要等待 xDS 配置初始化完成。这时我们就可以采用容器的 postStart lifecycle hook来达成该目的。Kubernetes 会在启动容器后调用该容器的 postStart hook,postStart hook 会阻塞 pod 中的下一个容器的启动,直到 postStart hook 执行完成。因此如果在 Envoy sidecar 的 postStart hook 中对 Envoy 的配置初始化状态进行判断,待完成初始化后再返回,就可以保证 Kubernetes 在 Envoy sidecar 配置初始化完成后再启动应用容器。该流程的执行顺序如下:
- Kubernetes 启动 Envoy sidecar 。
- Kubernetes 执行 postStart hook。
- postStart hook 通过 Envoy 健康检查接口判断其配置初始化状态,直到 Envoy 启动完成 。
- Kubernetes 启动应用容器。
Istio 已经在 1.7 中合入了该修复方案,参见 Allow users to delay application start until proxy is ready #24737。
插入 sidecar 后的 pod spec 如下面的 yaml 片段所示。postStart hook 配置的 pilot-agent wait 命令会持续调用 Envoy 的健康检查接口 '/healthz/ready' 检查其状态,直到 Envoy 完成配置初始化。这篇文章Delaying application start until sidecar is ready中介绍了更多关于该方案的细节。
apiVersion: v1
kind: Pod
metadata:
name: sidecar-starts-first
spec:
containers:
- name: istio-proxy
image:
lifecycle:
postStart:
exec:
command:
- pilot-agent
- wait
- name: application
image: my-application该方案在不对应用进行修改的情况下比较完美地解决了应用容器和 Envoy sidecar 初始化的依赖问题。但是该解决方案对 Kubernetes 有两个隐式依赖条件:Kubernetes 在一个线程中按定义顺序依次启动 pod 中的多个容器,以及前一个容器的 postStart hook 执行完毕后再启动下一个容器。这两个前提条件在目前的 Kuberenetes 代码实现中是满足的,但由于这并不是 Kubernetes的 API 规范,因此该前提在将来 Kubernetes 升级后很可能被打破,导致该问题再次出现。
Kubernetes 支持定义 pod 中容器之间的依赖关系
为了彻底解决该问题,避免 Kubernetes 代码变动后该问题再次出现,更合理的方式应该是由 Kubernetes 支持显式定义 pod 中一个容器的启动依赖于另一个容器的健康状态。目前 Kubernetes 中已经有一个 issue Support startup dependencies between containers on the same Pod #65502 对该问题进行跟踪处理。如果 Kubernetes 支持了该特性,则该流程的执行顺序如下:
- Kubernetes 启动 Envoy sidecar 容器。
- Kubernetes 通过 Envoy sidecar 容器的 readiness probe 检查其状态,直到 readiness probe 反馈 Envoy sidecar 已经 ready,即已经初始化完毕。
- Kubernetes 启动应用容器。
解耦应用服务之间的启动依赖关系
以上几个解决方案的思路都是控制 pod 中容器的启动顺序,在 Envoy sidecar 初始化完成后再启动应用容器,以确保应用容器启动时能够通过网络正常访问其他服务。但这些方案只是『头痛医头,脚痛医脚』,是治标不治本的方法。因为即使 pod 中对外的网络访问没有问题,应用容器依赖的其他服务也可能由于尚未启动,或者某些问题而不能在此时正常提供服务。要彻底解决该问题,我们需要解耦应用服务之间的启动依赖关系,使应用容器的启动不再强依赖其他服务。
在一个微服务系统中,原单体应用中的各个业务模块被拆分为多个独立进程(服务)。这些服务的启动顺序是随机的,并且服务之间通过不可靠的网络进行通信。微服务多进程部署、跨进程网络通信的特定决定了服务之间的调用出现异常是一个常见的情况。为了应对微服务的该特点,微服务的一个基本的设计原则是 "design for failure",即需要以优雅的方式应对可能出现的各种异常情况。当在微服务进程中不能访问一个依赖的外部服务时,需要通过重试、降级、超时、断路等策略对异常进行容错处理,以尽可能保证系统的正常运行。
Envoy sidecar 初始化期间网络暂时不能访问的情况只是放大了微服务系统未能正确处理服务依赖的问题,即使解决了 Envoy sidecar 的依赖顺序,该问题依然存在。例如在本案例中,配置中心也是一个独立的微服务,当一个依赖配置中心的微服务启动时,配置中心有可能尚未启动,或者尚未初始化完成。在这种情况下,如果在代码中没有对该异常情况进行处理,也会导致依赖配置中心的微服务启动失败。在一个更为复杂的系统中,多个微服务进程之间可能存在网状依赖关系,如果没有按照 "design for failure" 的原则对微服务进行容错处理,那么只是将整个系统启动起来就将是一个巨大的挑战。对于本例而言,可以采用一个类似这样的简单容错策略:先用一个缺省的 logback 配置启动应用进程,并在启动后对配置中心进行重试,待连接上配置中心后,再使用配置中心下发的配置对 logback 进行设置。
小结
应用容器对 Envoy Sidecar 启动依赖问题的典型表现是应用容器在刚启动的一小段时间内调用外部服务失败。原因是此时 Envoy sidecar 尚未完成 xDS 配置的初始化,因此不能为应用容器转发网络请求。该调用失败可能导致应用容器不能正常启动。此问题的根本原因是微服务应用中对依赖服务的调用失败没有进行合理的容错处理。对于遗留系统,为了尽量避免对应用的影响,我们可以通过在应用启动命令中判断 Envoy 初始化状态的方案,或者升级到 Istio 1.7 来缓解该问题。但为了彻底解决服务依赖导致的错误,建议参考 "design for failure" 的设计原则,解耦微服务之间的强依赖关系,在出现暂时不能访问一个依赖的外部服务的情况时,通过重试、降级、超时、断路等策略进行处理,以尽可能保证系统的正常运行。
参考文档
- App container unable to connect to network before sidecar is fully running #11130(https://github.com/istio/istio/issues/11130)
- Delaying application start until sidecar is ready(https://medium.com/@marko.luksa/delaying-application-start-until-sidecar-is-ready-2ec2d21a7b74)
- Kubernetes Container Lifecycle Hooks(https://kubernetes.io/docs/concepts/containers/container-lifecycle-hooks/)
- Istio流量管理实现机制深度解析 (https://zhaohuabing.com/post/2018-09-25-istio-traffic-management-impl-intro/)