
介绍
容器的兴起改变了我们开发,部署和维护软件的方式。容器使我们能够将构成应用程序的不同服务打包到单独的容器中,并在一组虚拟机和物理机上部署这些容器。这就产生了容器编排工具,可以自动执行基于容器的应用程序的部署,管理,扩展和可用性。Kubernetes允许大规模部署和管理基于容器的应用程序。
Kubernetes的主要优点之一是如何通过使用容器的动态调度为基于容器的分布式应用程序带来更高的可靠性和稳定性。但是,当组件或其主节点出现故障时,如何确保Kubernetes本身保持正常运行?
那就需要HA来完成了,相信大家也比较熟悉
为什么我们需要Kubernetes高可用性(HA)?
Kubernetes高可用性是关于建立Kubernetes及其支持组件的方式,它没有单点故障。单个主群集很容易发生故障,而多主群集则使用多个主节点,每个主节点都可以访问相同的工作节点。在单个主集群中,重要组件(如API服务器,控制器管理器)仅位于单个主节点上,如果失败,则无法创建更多服务,pod等。但是,在Kubernetes HA环境下,这些重要组件将复制到多个主机(通常是三个主机),如果任何一个主机发生故障,其他主机将保持群集正常运行。
高可用性是可靠性工程的重要组成部分,重点在于使系统可靠并避免整个系统出现任何单点故障。乍一看,其实现看似相当复杂,但是高可用性为需要增强稳定性和可靠性的系统带来了巨大优势。使用高可用性群集是构建可靠基础架构的最重要方面之一。
所以这里我自己写了一套基于Ansible的kubeadm高可用k8s集群,并覆盖了在生产当中的多个方方面面
说到集群部署方式这里也有很多人去使用二进制也有一部分人去使用kubeadm,这里我非常建议大家去使用kubeadm去部署k8s集群,也是官方推荐去使用的
为什么建议使用kubeadm部署k8s集群?
2015年夏天。Kubernetes1.0刚刚发布,但存在一个巨大的用户体验问题:没有简单的安装方法。愿意尝试Kubernetes的每个人都必须忍受弄清楚如何自行创建集群的麻烦。这不是一件容易的事,因为Kubernetes由多个服务组成,每个服务都必须以正确的方式进行配置。
最初,仅提供kube-up。这是一个仅用于测试目的的小型Shell脚本。但是很快就出现了各种各样的解决方案-一些诸如kube-up之类的shell脚本,而其他工具(如Ansible,Chef,Puppet等)开始发挥作用。由于有了这些解决方案,kops,kubernetes-anywhere和kubespray变得更加广泛地被使用和采用。但是,它们都不是完美的。社区开始在外界寻找灵感,并以Docker Swarm的形式找到了灵感。
是的,没错,Swarm易于部署。只需在单个节点上运行“ init”命令,然后使用打印的“ join”命令附加所有其他节点即可。Kubernetes社区中的许多人问自己:“为什么我们不能有一个同样简单的部署过程?” 这就是kubeadm的起源。
目的是提供尽可能简单的用户界面,但保留Kubernetes模块化设计的一些好处。在设计过程的早期,决定由用户负责提供CRI,kubelet守护程序和网络插件-这些已超出了kubeadm的范围。
除了处理最初的集群部署之外,kubeadm的设计还允许无缝升级,修改和拆除现有集群。用户也可以选择提供自己的etcd集群,也可以依靠kubeadm进行设置。
确定了这些设计目标后,Kubernetes的SIG(特殊兴趣小组)集群生命周期就开始了kubeadm的工作。首次发布的版本是Kubernetes 1.5的一部分。从那时起,kubeadm一直稳步发展
目前,kubeadm可以单或多主(高可用性)模式部署,升级,修改和拆除Kubernetes集群。可以同时使用kubeadm创建的现有配置和etcd配置。Kubeadm还部署Kube-proxy和DNS插件(kube-dns或CoreDNS,后者为默认设置)。除了Docker外,kubeadm和Kubernetes还可使用许多不同的CRI,其中容器式和CRI-O是最受欢迎的。
当然社区也是在集群部署层面给予最大的支持使kubeadm实现普遍可用性、完整性,在高可用方面k8s官方给出了一部分文档,几乎都是手动去部署的,部署一套完整的kubernetes集群确实让你浪费很多的时间,所以我这里准备了Devops自动化运维工具Ansible部署了一套完整的k8s集群,完全基于离线方式
适用于企业当中,无网也可以安装,当然也适合当做你的学习环境
集群设计
其中我在设计部署集群当中也加入了不少生产当中最佳实践以及集群优化的部分给集群带来稳定性、可靠性做了不少相关工作
目前是第一个版本1.0,集群版本是19.2,后续也会继续完善
1、Ansible自动化部署v1.0版本 集群19.2
一、kubeadm集群离线高可用
支持Calico(BGP、IPIP)
支持Node节点扩容
支持Docker大规模稳定性、安全调优
支持kubernetes集群大规模稳定性调优、安全调优
支持kubernetes水平pod自动缩放HPA
支持集群nodelocaldns解决5s延迟问题
支持NFS动态存储实现pv自动供给
支持一键证书到期续期
支持集群升级
支持kuboard UI
支持集群卸载
2、v2.0版本 集群xxx
一、kubeadm单节点master、多节点master
支持Calico(BGP、IPIP、RR)
支持Master节点扩容
支持Node节点扩容
支持Harbor高可用
支持Docker大规模稳定性、安全调优
支持kubernetes大规模集群稳定性、安全调优
支持kubernetes水平pod自动缩放HPA
支持kubernetes垂直容器缩放VPA
支持集群nodelocaldns解决5s延迟问题
支持NFS动态存储实现pv自动供给
支持一键证书到期续期
支持集群升级
支持联邦集群
支持kuboard UI
支持集群卸载
支持Docker、kubernetes安全合规基准检测
支持kubernetes集群部署配置最佳实践web
3、v3.0版本 集群xxx
一、kubeadm单节点master、多节点master
支持Calico(BGP、IPIP、RR)
支持Weave网络CNI
支持Node节点扩容
支持Harbor高可用
支持Docker大规模稳定性、安全调优
支持kubernetes大规模集群稳定性、安全调优
支持kubernetes水平pod自动缩放HPA
支持kubernetes垂直容器缩放VPA
支持kubernetes故障检测能力NPD
支持集群nodelocaldns解决5s延迟问题
支持NFS动态存储实现pv自动供给
支持Ceph-CSI动态实现pv自动供给
支持一键证书到期续期
支持集群升级
支持联邦集群
支持Kuboard UI
支持集群卸载
支持集群故障排除工具kube-Debug
支持Docker、kubernetes安全合规基准检测
支持kubernetes集群部署配置最佳实践web
支持高可用prometheus-operator以及告警
支持高可用elasticsearch-operator以及告警
5、5.0版本 集群xxx
一、kubeadm单节点master、多节点master
支持Calico(BGP、IPIP、RR)
支持Weave网络CNI
支持Macvlan网络CNI
支持Multus pod多网卡多CNI集成
支持Node节点扩容
支持Harbor高可用
支持Docker大规模稳定性、安全调优
支持kubernetes大规模集群稳定性、安全调优
支持kubernetes水平pod自动缩放HPA
支持kubernetes垂直容器缩放VPA
支持kubernetes故障检测能力NPD
支持kubernetes事件驱动自动缩放KEDA
支持集群nodelocaldns解决5s延迟问题
支持NFS动态存储实现pv自动供给
支持Ceph-CSI动态实现pv自动供给
支持Ceph-Rook
支持一键证书到期续期
支持集群升级
支持联邦集群
支持Kuboard UI
支持集群卸载
支持Descheduler平衡调度
支持容器可视化小工具
支持集群故障排除工具kube-Debug
支持集群灾难备份
支持Docker、kubernetes安全合规基准检测
支持kubernetes集群部署配置最佳实践web
支持高可用prometheus-operator
支持高可用elasticsearch-operator
支持对接jenkins 完成CI/CD
部署相对来讲比如容易,我封装的就3条命令,几乎小白也可以听懂
Devops工具介绍:Ansible

如果需要并行部署数百个服务器或客户端节点(可能是本地或在云中),并且需要配置它们中的每一个,那么该怎么办?你怎么做呢?你从哪里开始?存在许多配置管理框架来解决大多数的问题,而Ansible是这样一种框架。
可能已经听说过Ansible,但是对于那些不知道或不知道Ansible是什么的人,我可以这么说,Ansible是配置管理和供应工具。它与其他工具(例如Puppet,Chef和Salt)非常相似。
Ansible可以使个人以及团队轻松快速上手。这是因为Ansible使用YAML作为基础来配置,配置和部署。并且由于这种方法,任务以特定顺序执行。在执行过程中,如果您遇到语法错误,一旦遇到错误,它将失败,从而可能更易于调试,也方便企业运维人员或者开发人员来维护这么一套框架,对于目前kubernetes以及像Ceph集群这样的多台服务器组成的集群,非常适合用它来实现与管理,而很多企业也要求这项技能是必会的,相信你使用了这套我部署的k8s集群的框架也会学习到很多的语法以及Ansible-playbook的最佳实践
步入主题,环境要求
节点规模 Master规格
- 1-5个节点 4C8G(不建议2C4G)
- 6-20个节点 4C16G
- 21-100个节点 8C32G
- 100-200个节点 16C64G
Node节点规格 根据个人业务量而定,不建议2C4G(生产环境)
部署介绍
一、自动化安装Ansible
设置主机名
hostnamectl set-hostname m1
hostnamectl set-hostname m2
hostnamectl set-hostname m3
hostnamectl set-hostname n1执行
#bash kubefetch.sh
则会自动安装Ansible 2.9.10的版本
二、配置部署集群的hosts文件
使用Ansible的都知道hosts它是让我们定义哪些节点将成为控制节点的远程节点的一个作用,当然部署我一般将ansible也部署在master节点上,这样也会节省服务器的开支。
这里kubefetch组需要将你的所有的主机都填写上,ha-master需要写一个VIP虚拟的地址来作为HA的地址
master可以写5台或者3台,node节点根据你的节点数量进行配置,add-node如果你想增加扩容节点的时候可以写上它
all:vars里面则是全部的变量,这里我拿了出来就是方面你自己去组网,也可以按上面默认的配置,默认网络采用的Calico的BGP模式,docker 0的地址我通过bip的方式重新定义了docker 0网段,就是因为企业当中的内网地址可能会冲突,所以部署的过程中需要你个人去注意一下,如果内网不冲突则可以使用,这里作为默认值来使用
下面是hosts文件的示例,可以根据以下配置来完成你的集群部署
#cat hosts
#The IP from the managed side can also use Ansible as the managed side
[kubefetch]
192.168.30.61
192.168.30.62
192.168.30.63
192.168.30.64
[ha-master]
192.168.30.150
[master]
192.168.30.61
192.168.30.62
192.168.30.63
[node]
192.168.30.64
[add-node]
192.168.30.65
192.168.30.27
[all:vars]
#Declare the address pool for the Calico network
pod_cidr = 10.244.0.0
#Calico network mode selected, default is BGP, if switched to IPIP then set to Always
network_model = Never
#Address pools for cluster service exits
service_cidr = 10.96.0.0
#The address of the nodelocaldns,If the address of Service_CIDR is not changed, the default NodelocalDNS address is 10.96.0.10, the file of /var/lib/kubelet/config.yaml
nodelocaldns_address = 10.96.0.10
#Segment addresses of NFS Exports were generally used for PV and PVC storage
nfs_exports_segment = 192.168.30.0/24
#Docker0 bridge address, it is recommended to modify the address without conflict, here is the default value
docker_cidr = 172.17.0.1/16
#Harbor warehouse's address. By default, this fills in the default address, which you can use if available
docker_register_url = 127.0.0.1
#Keepalived subnet mask, try to use the same as your IP address
subbnet_mask = 24三、执行系统初始化操作,并且包含内核的优化
我们知道如何使用AdHoc方法运行Ansible任务 。尽管对于在所有服务器上安装软件包或执行命令之类的简单任务很有用,但在处理多个任务时却无济于事。
Ansible Playbook则就是此类方案的解决方案,主要用来解决复杂的流程化任务
从基本形式来说,剧本是由一个或多个任务组成的YAML文件。除了任务之外,我们还可以包含变量,文件,模板等。很容易理解YAML文件,如果你使用过playbook,那就更好了
在高级形式中,剧本中会有很多剧本,相应的任务(剧本)位于不同的文件夹中,每个文件夹包含因变量,文件,模板,自定义模块等。当然部署中为了嵌套每个playbook以及roles角色,我已经在此剧本中清晰到具体细节,方便你知道具体执行了哪些操作,调用了哪个playbook以及roles角色
这里介绍了执行时输入的远程主机的密码,默认设置的都是一样的,也可以-k 也可以执行[root@m1 kubefetch]# ansible-playbook init-host.yml --ask-pass
四、开始正式部署完整的kubernetes集群
此剧本包含了所有的引用,执行所有的playbook,都调用到此脚本当中[root@m1 kubefetch]# ansible-playbook site-all.yml
部署完成之后看到此页面就相当于一组高可用的kubeadm集群已经部署起来了
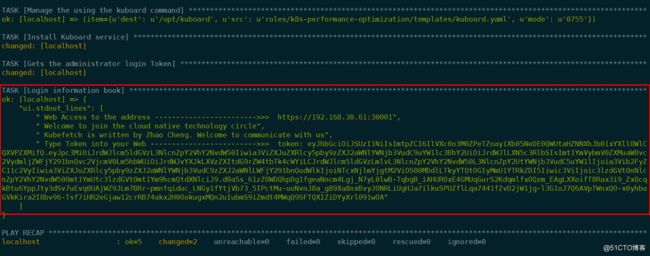
访问192.168.30.61:30001,则直接会进入UI的页面,这里登陆之后需要将输出的Token的值添加到页面当中就可以使用了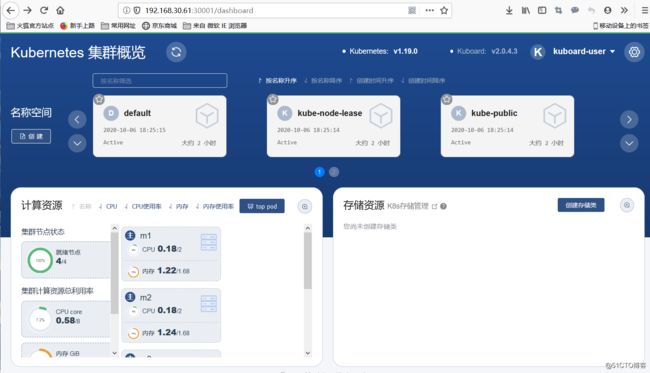
进入终端查看当前的节点信息
[root@m1 kubefetch]# kubectl get node
NAME STATUS ROLES AGE VERSION
m1 Ready master 119m v1.19.2
m2 Ready master 117m v1.19.2
m3 Ready master 117m v1.19.2
n1 Ready 116m v1.19.2 calicoctl允许您从命令行创建,读取,更新和删除Calico对象。calico会将对象存储存在etcd或Kubernetes的两个数据存储之一中。在安装Calico时通常会确定数据存储的选择。
[root@m1 kubefetch]# calicoctl node status
Calico process is running.
IPv4 BGP status
+---------------+-------------------+-------+----------+-------------+
| PEER ADDRESS | PEER TYPE | STATE | SINCE | INFO |
+---------------+-------------------+-------+----------+-------------+
| 192.168.30.62 | node-to-node mesh | up | 13:06:13 | Established |
| 192.168.30.63 | node-to-node mesh | up | 13:06:13 | Established |
| 192.168.30.64 | node-to-node mesh | up | 13:06:13 | Established |
| 192.168.30.65 | node-to-node mesh | up | 13:07:27 | Established |
+---------------+-------------------+-------+----------+-------------+
IPv6 BGP status
No IPv6 peers found.
[root@m1 kubefetch]# calicoctl get ippool -owide
NAME CIDR NAT IPIPMODE VXLANMODE DISABLED SELECTOR
default-ipv4-ippool 10.244.0.0/16 true Never Never false all() 查看部署之后所有的pod列表
[root@m1 ~]# kubectl get po -A
NAMESPACE NAME READY STATUS RESTARTS AGE
kube-system calico-kube-controllers-6d5c8f4db4-dgcmk 1/1 Running 0 124m
kube-system calico-node-6n9r7 1/1 Running 0 124m
kube-system calico-node-cd8zp 1/1 Running 0 123m
kube-system calico-node-ncfww 1/1 Running 0 124m
kube-system calico-node-qrl7g 1/1 Running 0 124m
kube-system coredns-f9fd979d6-lr5m8 1/1 Running 0 126m
kube-system coredns-f9fd979d6-mjqrx 1/1 Running 0 126m
kube-system etcd-m1 1/1 Running 0 126m
kube-system etcd-m2 1/1 Running 0 124m
kube-system etcd-m3 1/1 Running 0 123m
kube-system kube-apiserver-m1 1/1 Running 0 126m
kube-system kube-apiserver-m2 1/1 Running 0 124m
kube-system kube-apiserver-m3 1/1 Running 1 124m
kube-system kube-controller-manager-m1 1/1 Running 2 126m
kube-system kube-controller-manager-m2 1/1 Running 0 124m
kube-system kube-controller-manager-m3 1/1 Running 0 124m
kube-system kube-proxy-bhm9r 1/1 Running 0 126m
kube-system kube-proxy-f5xjq 1/1 Running 0 124m
kube-system kube-proxy-gwfqr 1/1 Running 0 123m
kube-system kube-proxy-hfwp8 1/1 Running 0 124m
kube-system kube-scheduler-m1 1/1 Running 1 126m
kube-system kube-scheduler-m2 1/1 Running 0 124m
kube-system kube-scheduler-m3 1/1 Running 0 124m
kube-system kuboard-756bb445c7-dgtt2 1/1 Running 0 122m五、扩容Node节点
生产环境中如果你的节点资源不够用了,想扩容节点的话,支持扩容
执行以下配置,当然你的hosts文件中需要添加对应扩容Node节点的IP,这样ansible才能安排执行的工作
[add-node]
192.168.30.65
[root@m1 kubefetch]# ansible-playbook site-addnode.yml --ask-pass安装完之后会发现多了一个节点,你也可以直接添加多个节点进行一同执行
[root@m1 kubefetch]# kubectl get node
NAME STATUS ROLES AGE VERSION
m1 Ready master 153m v1.19.2
m2 Ready master 151m v1.19.2
m3 Ready master 151m v1.19.2
n1 Ready 150m v1.19.2
n2 Ready 88s v1.19.2 六、大规模k8s集群、稳定性、安全性调优
我还做了一些集群的优化的工作对你的集群进行加固,稳定性、可靠性、安全性的调优
包含了ETCD、Docker、Kubernetes、DNS+nodelocaldns
大规模调优会单独拿出一篇博文来介绍这里暂时不占有大幅篇文
如果你想进行集群调优的话可以执行这条playbook并包含了上述优化条件[root@m1 kubefetch]# ansible-playbook site-all-optimize.yml
执行结束之后会自动重启你的主机,让所有的pod缓存命中nodelocaldns cache的地址,解决5s延迟问题,具体详细博文,如何产生的延迟可以参考我之前的博客coredns+nodelocaldns解决5s延迟
[root@m1 ~]# kubectl get po -A
NAMESPACE NAME READY STATUS RESTARTS AGE
kube-system calico-kube-controllers-6d5c8f4db4-dgcmk 1/1 Running 2 3h1m
kube-system calico-node-2t4fb 1/1 Running 1 31m
kube-system calico-node-6n9r7 1/1 Running 2 3h1m
kube-system calico-node-cd8zp 1/1 Running 2 3h
kube-system calico-node-ncfww 1/1 Running 2 3h1m
kube-system calico-node-qrl7g 1/1 Running 2 3h1m
kube-system coredns-f9fd979d6-lr5m8 1/1 Running 2 3h3m
kube-system coredns-f9fd979d6-mjqrx 1/1 Running 2 3h3m
kube-system etcd-m1 1/1 Running 4 3h3m
kube-system etcd-m2 1/1 Running 2 3h1m
kube-system etcd-m3 1/1 Running 3 3h1m
kube-system kube-apiserver-m1 1/1 Running 1 24m
kube-system kube-apiserver-m2 1/1 Running 1 24m
kube-system kube-apiserver-m3 1/1 Running 1 23m
kube-system kube-controller-manager-m1 1/1 Running 2 24m
kube-system kube-controller-manager-m2 1/1 Running 1 24m
kube-system kube-controller-manager-m3 1/1 Running 1 24m
kube-system kube-proxy-bhm9r 1/1 Running 2 3h3m
kube-system kube-proxy-cwgfr 1/1 Running 1 31m
kube-system kube-proxy-f5xjq 1/1 Running 2 3h1m
kube-system kube-proxy-gwfqr 1/1 Running 2 3h
kube-system kube-proxy-hfwp8 1/1 Running 2 3h1m
kube-system kube-scheduler-m1 1/1 Running 4 3h3m
kube-system kube-scheduler-m2 1/1 Running 5 3h1m
kube-system kube-scheduler-m3 1/1 Running 3 3h1m
kube-system kuboard-756bb445c7-dgtt2 1/1 Running 2 179m
kube-system node-local-dns-2crt5 1/1 Running 1 24m
kube-system node-local-dns-7stq5 1/1 Running 1 24m
kube-system node-local-dns-h4z8x 1/1 Running 1 24m
kube-system node-local-dns-qqswn 1/1 Running 1 24m
kube-system node-local-dns-zfhk9 1/1 Running 1 24m七、证书到期更换
我们知道使用 kubeadm 安装 kubernetes 集群非常方便,但是也有一个比较烦人的问题就是默认的证书有效期只有一年时间,所以需要考虑证书升级的问题,kubeadm 会在控制面板升级的时候自动更新所有证书,所以使用 kubeadm 搭建得集群最佳的做法是经常升级集群,这样可以确保你的集群保持最新状态版本并保持合理的安全性。但是对于实际的生产环境我们可能并不会去频繁得升级集群,所以这个时候我们就需要去手动更新证书。
当然升级集群我这里已经准备了自动化部署playbook的剧本,一键执行则直接更换证书
[root@m1 kubefetch]# ansible-playbook site-cluster-certs-update.yml
ok: [192.168.30.62] => {
"check_expiration.stdout_lines": [
"[check-expiration] Reading configuration from the cluster...",
"[check-expiration] FYI: You can look at this config file with 'kubectl -n kube-system get cm kubeadm-config -oyaml'",
"",
"CERTIFICATE EXPIRES RESIDUAL TIME CERTIFICATE AUTHORITY EXTERNALLY MANAGED",
"admin.conf Oct 06, 2021 10:27 UTC 360d no ",
"apiserver Oct 06, 2021 10:27 UTC 360d ca no ",
"apiserver-etcd-client Oct 06, 2021 10:27 UTC 360d etcd-ca no ",
"apiserver-kubelet-client Oct 06, 2021 10:27 UTC 360d ca no ",
"controller-manager.conf Oct 06, 2021 10:27 UTC 360d no ",
"etcd-healthcheck-client Oct 06, 2021 10:27 UTC 360d etcd-ca no ",
"etcd-peer Oct 06, 2021 10:27 UTC 360d etcd-ca no ",
"etcd-server Oct 06, 2021 10:27 UTC 360d etcd-ca no ",
"front-proxy-client Oct 06, 2021 10:27 UTC 360d front-proxy-ca no ",
"scheduler.conf Oct 06, 2021 10:27 UTC 360d no ",
"",
"CERTIFICATE AUTHORITY EXPIRES RESIDUAL TIME EXTERNALLY MANAGED",
"ca Oct 04, 2030 10:25 UTC 9y no ",
"etcd-ca Oct 04, 2030 10:25 UTC 9y no ",
"front-proxy-ca Oct 04, 2030 10:25 UTC 9y no "替换更新证书之后,则时间又换到了364d,并成功替换了证书
ok: [192.168.30.62] => {
"renew_result.stdout_lines": [
"[check-expiration] Reading configuration from the cluster...",
"[check-expiration] FYI: You can look at this config file with 'kubectl -n kube-system get cm kubeadm-config -oyaml'",
"",
"CERTIFICATE EXPIRES RESIDUAL TIME CERTIFICATE AUTHORITY EXTERNALLY MANAGED",
"admin.conf Oct 06, 2021 14:08 UTC 364d no ",
"apiserver Oct 06, 2021 14:08 UTC 364d ca no ",
"apiserver-etcd-client Oct 06, 2021 14:08 UTC 364d etcd-ca no ",
"apiserver-kubelet-client Oct 06, 2021 14:08 UTC 364d ca no ",
"controller-manager.conf Oct 06, 2021 14:08 UTC 364d no ",
"etcd-healthcheck-client Oct 06, 2021 14:08 UTC 364d etcd-ca no ",
"etcd-peer Oct 06, 2021 14:08 UTC 364d etcd-ca no ",
"etcd-server Oct 06, 2021 14:08 UTC 364d etcd-ca no ",
"front-proxy-client Oct 06, 2021 14:08 UTC 364d front-proxy-ca no ",
"scheduler.conf Oct 06, 2021 14:08 UTC 364d no ",
"",
"CERTIFICATE AUTHORITY EXPIRES RESIDUAL TIME EXTERNALLY MANAGED",
"ca Oct 04, 2030 10:25 UTC 9y no ",
"etcd-ca Oct 04, 2030 10:25 UTC 9y no ",
"front-proxy-ca Oct 04, 2030 10:25 UTC 9y no "八、自动部署Metrics Server采集指标器
Metrics server是一种可伸缩的、高效的容器资源指标源,用于Kubernetes内置的自动缩放管道。
Metrics server从Kubelets收集资源指标,并通过Metrics API在Kubernetes apiserver中公开它们,以便HPA和VPA使用。Metrics API也可以被kubectl top访问,这使得它更容易调试自动排序管道。
Metrics server并不用于非自动加码的目的。例如,不要使用它将指标转发到监视解决方案,或者将其作为监视解决方案指标的来源。
在大多数集群上工作的单一部署,可扩展支持最多5,000个节点集群 资源效率:Metrics server每个节点使用0.5m核心CPU和4 MB内存
部署metrics server有的集群部署可能会遇到问题,这里我找到合适的方法来部署,这里你无需知道如何部署的,直接知道playbook则会帮助你正确安装metrics server服务指标采集器
[root@m1 kubefetch]# ansible-playbook site-metrics-server.yml
[root@m1 kubefetch]# kubectl top no
NAME CPU(cores) CPU% MEMORY(bytes) MEMORY%
m1 189m 9% 1277Mi 74%
m2 137m 6% 1255Mi 72%
m3 126m 6% 1213Mi 70%
n1 61m 3% 624Mi 36%
n2 67m 3% 597Mi 34%
kube-system metrics-server-5f4d886f76-z5rzg 1/1 Running 2 31m 10.244.139.194 m2 九、自动化实现NFS动态存储实现pv自动供给
Kubernetes Storage允许容器化的应用程序无缝访问存储资源,而无需知道容器在消耗数据。Kubernetes允许应用程序访问存储的一种方式是标准的网络文件服务(NFS)协议。在本文中,将实现直接从Kubernetes容器中的容器安装NFS文件共享。
Kubernetes volumes 和NFS Kubernetes volumes是抽象的存储单元,它允许集群中的节点在它们之间写入,读取和共享数据。Kubernetes提供了许多存储插件,可用于访问存储服务和平台。其中之一是NFS插件。网络文件系统(NFS)是一种标准协议,可让将存储设备安装为本地驱动器。Kubernetes允许将卷作为本地驱动器安装在容器上。NFS集成对于将工作负载迁移到Kubernetes非常有用,因为代码通常会通过NFS访问数据。有两种方法可以通过Kubernetes中的NFS访问数据:临时NFS卷-这使您可以连接到已经拥有的现有NFS存储。带有NFS的持久卷-这使您可以在群集中设置可通过NFS访问的托管资源。
在Kubernetes上使用NFS的优势您应考虑在Kubernetes中使用NFS的一些原因:使用现有存储-你可以使用标准接口在本地或云中挂载当前正在使用的现有数据卷。持久性-常规的Kubernetes Volume是短暂的,这意味着当其pod关闭时,它会被拆除。但是,可以在Pod定义中定义的NFS卷为你提供持久性,而不必定义持久卷。即使Pod关闭,通过NFS保存的所有数据也将存储在连接的存储设备中。还可以选择定义一个Kubernetes持久卷,以通过NFS接口公开其数据。共享数据-由于其持久性,NFS卷可用于在同一Pod或不同Pod中的容器之间共享数据。同时安装-NFS卷可以同时由多个节点安装,并且多个节点可以同时写入同一NFS卷。一个重要的警告是,要使NFS卷正常工作,必须设置一台通过NFS公开存储的服务器。Kubernetes将不会为你管理现有的NFS卷。
部署的时候需要注意exports出去的网段,需要在公共变量写上对应的,默认Master1作为NFS的服务端地址
具体NFS 数据卷的使用可参考我之前的博客
#Segment addresses of NFS Exports were generally used for PV and PVC storage
nfs_exports_segment = 192.168.30.0/24
[root@m1 kubefetch]# ansible-playbook site-nfs-client.yml
[root@m1 kubefetch]# kubectl get po -owide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nfs-client-provisioner-66bbdf6495-shkv4 1/1 Running 0 23s 10.244.217.0 n2
其他的节点都会作为客户端来使用并挂载上。默认客户端地址都在/mnt下
192.168.30.61:/opt/nfs 48G 11G 37G 23% /mnt 以上就是V1版本的全部内容,如有需要可评论并添加kubefetch,获取安装包地址