前言
java从零手写实现redis(一)如何实现固定大小的缓存?
java从零手写实现redis(二)redis expire 过期原理
java从零手写实现redis(三)内存数据如何重启不丢失?
java从零手写实现redis(四)添加监听器
java从零手写实现redis(五)过期策略的另一种实现思路
java从零手写实现redis(六)AOF 持久化原理详解及实现
java从零开始手写redis(七)LRU 缓存淘汰策略详解
java从零开始手写redis(八)朴素 LRU 淘汰算法性能优化
第二节中我们已经初步实现了类似 redis 中的 expire 过期功能,不过存在一个问题没有解决,那就是遍历的时候不是随机返回的,会导致每次遍历从头开始,可能导致很多 Keys 处于“饥饿”状态。
可以回顾:
java从零手写实现redis(二)redis expire 过期原理
java从零手写实现redis(五)过期策略的另一种实现思路
本节我们一起来实现一个过期的随机性版本,更近一步领会一下 redis 的巧妙之处。
以前的实现回顾
开始新的旅程之前,我们先回顾一下原来的实现。
expire 实现原理
其实过期的实思路也比较简单:我们可以开启一个定时任务,比如 1 秒钟做一次轮训,将过期的信息清空。
过期信息的存储
/**
* 过期 map
*
* 空间换时间
* @since 0.0.3
*/
private final Map expireMap = new HashMap<>();
@Override
public void expire(K key, long expireAt) {
expireMap.put(key, expireAt);
} 我们定义一个 map,key 是对应的要过期的信息,value 存储的是过期时间。
轮询清理
我们固定 100ms 清理一次,每次最多清理 100 个。
/**
* 单次清空的数量限制
* @since 0.0.3
*/
private static final int LIMIT = 100;
/**
* 缓存实现
* @since 0.0.3
*/
private final ICache cache;
/**
* 线程执行类
* @since 0.0.3
*/
private static final ScheduledExecutorService EXECUTOR_SERVICE = Executors.newSingleThreadScheduledExecutor();
public CacheExpire(ICache cache) {
this.cache = cache;
this.init();
}
/**
* 初始化任务
* @since 0.0.3
*/
private void init() {
EXECUTOR_SERVICE.scheduleAtFixedRate(new ExpireThread(), 100, 100, TimeUnit.MILLISECONDS);
} 这里定义了一个单线程,用于执行清空任务。
清空任务
这个非常简单,遍历过期数据,判断对应的时间,如果已经到期了,则执行清空操作。
为了避免单次执行时间过长,最多只处理 100 条。
/**
* 定时执行任务
* @since 0.0.3
*/
private class ExpireThread implements Runnable {
@Override
public void run() {
//1.判断是否为空
if(MapUtil.isEmpty(expireMap)) {
return;
}
//2. 获取 key 进行处理
int count = 0;
for(Map.Entry entry : expireMap.entrySet()) {
if(count >= LIMIT) {
return;
}
expireKey(entry);
count++;
}
}
}
/**
* 执行过期操作
* @param entry 明细
* @since 0.0.3
*/
private void expireKey(Map.Entry entry) {
final K key = entry.getKey();
final Long expireAt = entry.getValue();
// 删除的逻辑处理
long currentTime = System.currentTimeMillis();
if(currentTime >= expireAt) {
expireMap.remove(key);
// 再移除缓存,后续可以通过惰性删除做补偿
cache.remove(key);
}
} redis 的定时任务
流程
想知道我们的流程就什么问题,和 redis 的定时清理任务流程对比一下就知道了。
Redis内部维护一个定时任务,默认每秒运行10次(通过配置hz控制)。
定时任务中删除过期键逻辑采用了自适应算法,根据键的过期比例、使用快慢两种速率模式回收键,流程如下所示。
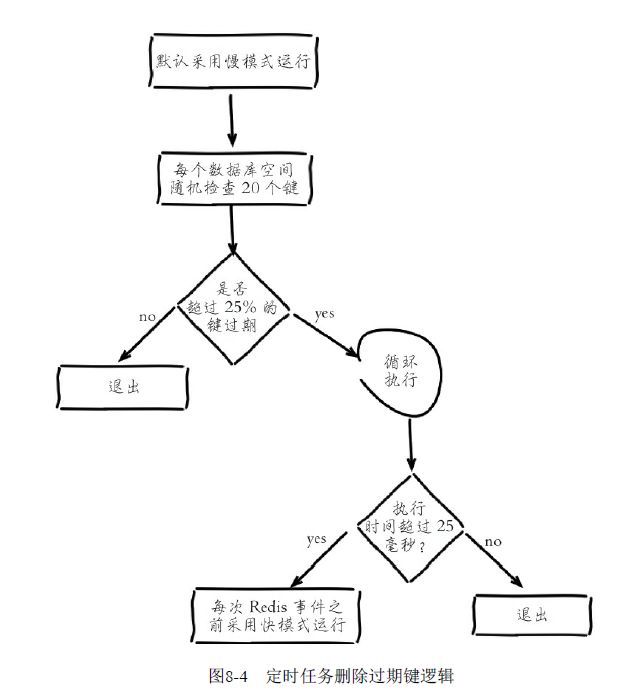
流程说明
1)定时任务在每个数据库空间随机检查20个键,当发现过期时删除对应的键。
2)如果超过检查数25%的键过期,循环执行回收逻辑直到不足25%或运行超时为止,慢模式下超时时间为25毫秒。
3)如果之前回收键逻辑超时,则在Redis触发内部事件之前再次以快模式运行回收过期键任务,快模式下超时时间为1毫秒且2秒内只能运行1次。
4)快慢两种模式内部删除逻辑相同,只是执行的超时时间不同。
ps: 这里的快慢模式设计的也比较巧妙,根据过期信息的比例,调整对应的任务超时时间。
这里的随机也非常重要,可以比较客观的清理掉过期信息,而不是从头遍历,导致后面的数据无法被访问。
我们接下来主要实现下随机抽取这个特性。
直接通过 Map#keys 转集合
实现思路
保持原来的 expireMap 不变,直接对 keys 转换为 collection,然后随机获取。
这个也是网上最多的一种答案。
java 代码实现
基本属性
public class CacheExpireRandom implements ICacheExpire {
private static final Log log = LogFactory.getLog(CacheExpireRandom.class);
/**
* 单次清空的数量限制
* @since 0.0.16
*/
private static final int COUNT_LIMIT = 100;
/**
* 过期 map
*
* 空间换时间
* @since 0.0.16
*/
private final Map expireMap = new HashMap<>();
/**
* 缓存实现
* @since 0.0.16
*/
private final ICache cache;
/**
* 是否启用快模式
* @since 0.0.16
*/
private volatile boolean fastMode = false;
/**
* 线程执行类
* @since 0.0.16
*/
private static final ScheduledExecutorService EXECUTOR_SERVICE = Executors.newSingleThreadScheduledExecutor();
public CacheExpireRandom(ICache cache) {
this.cache = cache;
this.init();
}
/**
* 初始化任务
* @since 0.0.16
*/
private void init() {
EXECUTOR_SERVICE.scheduleAtFixedRate(new ExpireThreadRandom(), 10, 10, TimeUnit.SECONDS);
}
} 定时任务
这里我们和 redis 保持一致,支持 fastMode。
实际上 fastMode 和慢模式的逻辑是完全一样的,只是超时的时间不同。
这里的超时时间我根据个人理解做了一点调整,整体流程不变。
/**
* 定时执行任务
* @since 0.0.16
*/
private class ExpireThreadRandom implements Runnable {
@Override
public void run() {
//1.判断是否为空
if(MapUtil.isEmpty(expireMap)) {
log.info("expireMap 信息为空,直接跳过本次处理。");
return;
}
//2. 是否启用快模式
if(fastMode) {
expireKeys(10L);
}
//3. 缓慢模式
expireKeys(100L);
}
}过期信息核心实现
我们执行过期的时候,首先会记录超时时间,用于超出时直接中断执行。
默认恢复 fastMode=false,当执行超时的时候设置 fastMode=true。
/**
* 过期信息
* @param timeoutMills 超时时间
* @since 0.0.16
*/
private void expireKeys(final long timeoutMills) {
// 设置超时时间 100ms
final long timeLimit = System.currentTimeMillis() + timeoutMills;
// 恢复 fastMode
this.fastMode = false;
//2. 获取 key 进行处理
int count = 0;
while (true) {
//2.1 返回判断
if(count >= COUNT_LIMIT) {
log.info("过期淘汰次数已经达到最大次数: {},完成本次执行。", COUNT_LIMIT);
return;
}
if(System.currentTimeMillis() >= timeLimit) {
this.fastMode = true;
log.info("过期淘汰已经达到限制时间,中断本次执行,设置 fastMode=true;");
return;
}
//2.2 随机过期
K key = getRandomKey();
Long expireAt = expireMap.get(key);
boolean expireFlag = expireKey(key, expireAt);
log.debug("key: {} 过期执行结果 {}", key, expireFlag);
//2.3 信息更新
count++;
}
}随机获取过期 key
/**
* 随机获取一个 key 信息
* @return 随机返回的 keys
* @since 0.0.16
*/
private K getRandomKey() {
Random random = ThreadLocalRandom.current();
Set keySet = expireMap.keySet();
List list = new ArrayList<>(keySet);
int randomIndex = random.nextInt(list.size());
return list.get(randomIndex);
} 这个就是网上最常见的实现方法,直接所有 keys 转换为 list,然后通过 random 获取一个元素。
性能改进
方法的缺陷
getRandomKey() 方法为了获取一个随机的信息,代价还是太大了。
如果 keys 的数量非常大,那么我们要创建一个 list,这个本身就是非常耗时的,而且空间复杂度直接翻倍。
所以不太清楚为什么晚上最多的是这一种解法。
优化思路-避免空间浪费
最简单的思路是我们应该避免 list 的创建。
我们所要的只是一个基于 size 的随机值而已,我们可以遍历获取:
private K getRandomKey2() {
Random random = ThreadLocalRandom.current();
int randomIndex = random.nextInt(expireMap.size());
// 遍历 keys
Iterator iterator = expireMap.keySet().iterator();
int count = 0;
while (iterator.hasNext()) {
K key = iterator.next();
if(count == randomIndex) {
return key;
}
count++;
}
// 正常逻辑不会到这里
throw new CacheRuntimeException("对应信息不存在");
} 优化思路-批量操作
上述的方法避免了 list 的创建,同时也符合随机的条件。
但是从头遍历到随机的 size 数值,这也是一个比较慢的过程(O(N) 时间复杂度)。
如果我们取 100 次,悲观的话就是 100 * O(N)。
我们可以运用批量的思想,比如一次取 100 个,降低时间复杂度:
/**
* 批量获取多个 key 信息
* @param sizeLimit 大小限制
* @return 随机返回的 keys
* @since 0.0.16
*/
private Set getRandomKeyBatch(final int sizeLimit) {
Random random = ThreadLocalRandom.current();
int randomIndex = random.nextInt(expireMap.size());
// 遍历 keys
Iterator iterator = expireMap.keySet().iterator();
int count = 0;
Set keySet = new HashSet<>();
while (iterator.hasNext()) {
// 判断列表大小
if(keySet.size() >= sizeLimit) {
return keySet;
}
K key = iterator.next();
// index 向后的位置,全部放进来。
if(count >= randomIndex) {
keySet.add(key);
}
count++;
}
// 正常逻辑不会到这里
throw new CacheRuntimeException("对应信息不存在");
} 我们传入一个列表的大小限制,可以一次获取多个。
优化思路-O(1) 的时间复杂度
一开始想到随机,我的第一想法是同时冗余一个 list 存放 keys,然后可以随机返回 key,解决问题。
但是对于 list 的更新,确实 O(N) 的,空间复杂度多出了 list 这一部分,感觉不太值当。
如果使用前面的 map 存储双向链表节点也可以解决,但是相对比较麻烦,前面也都实现过,此处就不赘述了。
其实这里的随机还是有些不足
(1)比如随机如果数据重复了怎么处理?
当然目前的解法就是直接 count,一般数据量较大时这种概率比较低,而且有惰性删除兜底,所以无伤大雅。
(2)随机到的信息很大可能过期时间没到
这里最好采用我们原来的基于过期时间的 map 分类方式,这样可以保证获取到的信息过期时间在我们的掌握之中。
当然各种方法各有利弊,看我们如何根据实际情况取舍。
小结
到这里,一个类似于 redis 的 expire 过期功能,算是基本实现了。
对于 redis 过期的实现,到这里也基本告一段落了。当然,还有很多优化的地方,希望你在评论区写下自己的方法。
开源地址:https://github.com/houbb/cache
觉得本文对你有帮助的话,欢迎点赞评论收藏关注一波。你的鼓励,是我最大的动力~
不知道你有哪些收获呢?或者有其他更多的想法,欢迎留言区和我一起讨论,期待与你的思考相遇。
原文地址
Cache Travel-09-从零手写 cache 之 redis expire 过期实现原理
参考资料
JAVA 随机选出MAP中的键
Selecting random key and value sets from a Map in Java