一、 背景
集群容量不够了,这些年各大公司都在做机器资源利用率的事情,我司也不例外,好不容易申请了5台机器加入集群扩容,balance的正欢乐呢,Region Balance Ratio经过了1天半的时间刚刚降到93%,结果接到通知,5台机器的交换机升级,需重启机器,网卡要做bond。
集群配置
集群版本:v3.0.5
集群配置:普通SSD磁盘,128G内存,40 核cpu
tidb21 TiDB/PD/pump/prometheus/grafana/CCS
tidb22 TiDB/PD/pump
tidb23 TiDB/PD/pump
tidb01 TiKV
tidb02 TiKV
tidb03 TiKV
tidb04 TiKV
tidb05 TiKV
tidb06 TiKV
tidb07 TiKV
tidb08 TiKV
tidb09 TiKV
tidb10 TiKV
tidb11 TiKV
tidb12 TiKV
tidb13 TiKV
tidb14 TiKV
tidb15 TiKV
tidb16 TiKV
tidb17 TiKV
tidb18 TiKV
tidb19 TiKV
tidb20 TiKV
wtidb29 TiKV
wtidb30 TiKV
wtidb31 新加入的TiKV
wtidb32 新加入的TiKV
wtidb33 新加入的TiKV
wtidb34 新加入的TiKV
wtidb35 新加入的TiKV缩容流程:
缩容 TiKV 节点
例如,如果要移除一个 TiKV 节点(node9),IP 地址为 172.16.10.9,可以进行如下操作:
1. 查看 node9 节点的 store id:
/home/tidb/tidb-ansible/resources/bin/pd-ctl -u "http://172.16.10.1:2379" -d store
2. 从集群中移除 node9,假如 store id 为 10:
/home/tidb/tidb-ansible/resources/bin/pd-ctl -u "http://172.16.10.1:2379" -d store delete 10
2. 使用 Grafana 或者pd-ctl检查节点是否下线成功(下线需要一定时间,下线节点的状态变为 Tombstone 就说明下线成功了):
/home/tidb/tidb-ansible/resources/bin/pd-ctl -u "http://172.16.10.1:2379" -d store 10
3. 下线成功后,停止 node9 上的服务:
ansible-playbook stop.yml -l 172.16.10.9
4. 编辑inventory.ini文件,移除节点信息:
[tidb_servers]
172.16.10.4
172.16.10.5
[pd_servers]
172.16.10.1
172.16.10.2
172.16.10.3
[tikv_servers]
172.16.10.6
172.16.10.7
172.16.10.8
#172.16.10.9 # 注释被移除节点
[monitored_servers]
172.16.10.4
172.16.10.5
172.16.10.1
172.16.10.2
172.16.10.3
172.16.10.6
172.16.10.7
172.16.10.8
#172.16.10.9 # 注释被移除节点
[monitoring_servers]
172.16.10.3
[grafana_servers]
172.16.10.3
现在拓扑结构如下所示:
Name Host IP Services
node1 172.16.10.1 PD1
node2 172.16.10.2 PD2
node3 172.16.10.3 PD3, Monitor
node4 172.16.10.4 TiDB1
node5 172.16.10.5 TiDB2
node6 172.16.10.6 TiKV1
node7 172.16.10.7 TiKV2
node8 172.16.10.8 TiKV3
node9 172.16.10.9 TiKV4 已删除
5.更新 Prometheus 配置并重启:
ansible-playbook rolling_update_monitor.yml --tags=prometheus
打开浏览器访问监控平台:监控整个集群的状态balance情况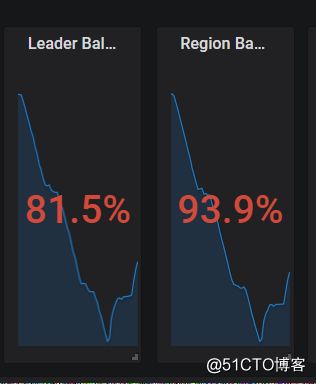
因为balance速度过大会影响业务,此时新加入的5台机器经历近两天的时间,region balance刚降至93.9%
二、实战演练
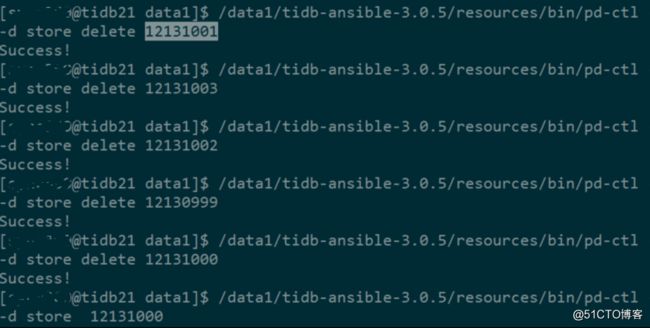
我们对TiKV实例执行缩容操作,正常下线都是一个个下的,当时我是5个一起执行的命令,好在并没有什么异常情况出现,不过并不推荐~
现在状态都是"state_name": "Offline",没有变Tombstone
状态含义
在下线的过程中,需要迁移region,之前迁移了一天才下降5%还得反迁移回去,当时是93%差不多快2天了,执行后可以看到region balance和leader balance都反向增长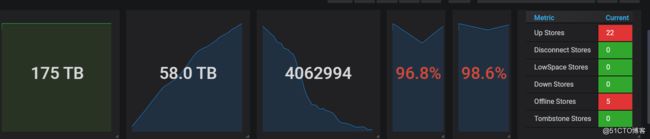
异常情况
我们发现下线迁移balance过程中,速度越来越慢
官方手册有如下一段话:
例如 Region 没均衡的情况下做下线节点操作,下线的调度与 Region Balance 会抢占 region-schedule-limit 配额,此时你可以调小 replica-schedule-limit 以限制下线调度的速度,或者设置 disable-replace-offline-replica = true 来暂时关闭下线流程。27号14点后速度放缓,按照手册中的说明,调大replica-schedule-limit 可以加快下线调度速度,为了加快迁移速度,尽快下线,我们调大了该参数到32。

此时可以看出,调度确实有了明显的增加,但是仅仅持续了没多久,我们发现调度速度又变慢了,这是为什么呢,其实是因为调度争用导致的。
我们能够通过下图看出,replace-offline-replica的速度短暂标高,后又下降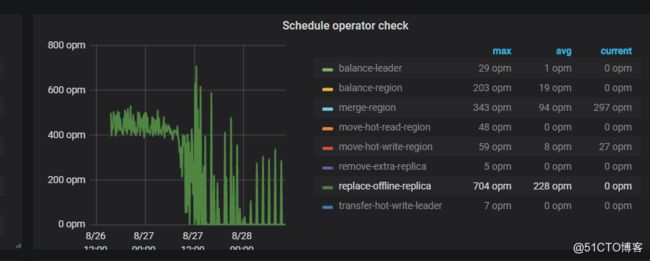
这时我们看一下,是不是手册中说到的,region balance抢占配额
果然,14点后,balance-region又有速度了,所以问题的关键已经找到了。
三、关键性参数
关闭调度
» config set replica-schedule-limit 64
Success!
» config set region-schedule-limit 0
Success!
我们目前的场景是,balance期间,如何尽快的下线目标机器,region分布在剩余的机器中是否均衡不是我们的首要任务,因此,我们关闭region-schedule在剩余机器中的balance,尽可能大的开启控制下线调度限制的参数replica-schedule-limit。就能够实现让指定的机器尽可能快的迁移走region来完成下线。
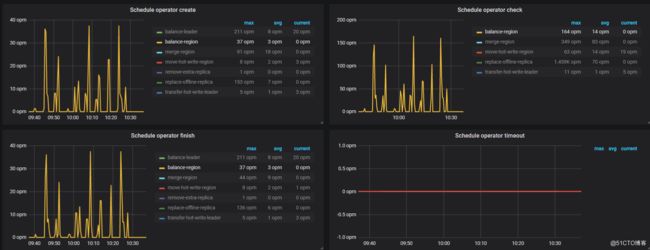
上图能够看出,当我们将region-schedule-limit配置为0禁用region调度时,balance-region的值降值0 opm
此时,下线速度获得了大幅度的提升:
那么同理,如果我们临时也禁止leader的调度,理论上调度器io将全部交给replica-schedule-limit
因此我们执行如下命令:
» config set leader-schedule-limit 0
Success!这是能看到待下线的机器balance速度又再次获得进一步的提升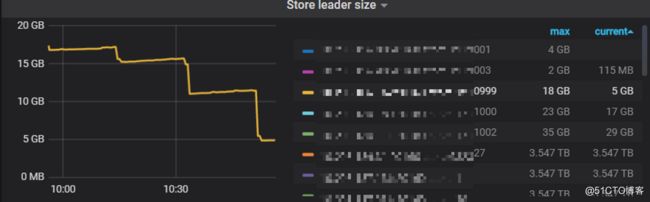
四、效果对比
我们把时间线拉长,与最开始未进行任何优化前的下线调度速度进行对比,可以发现提升的非常明显:
验证结果
文档这里其实也是有问题的,当变成tombstone后,pd-ctl store命令是看不到tombstone节点的,除非你记得id
[tidb21 ~]$ /data1/tidb-ansible-3.0.5/resources/bin/pd-ctl -i -u http://192.168.1.248:2379 ? store 12131001
{
"store": {
"id": 12131001,
"address": "192.168.1.249:20160",
"state": 2,
"version": "3.0.5",
"state_name": "Tombstone"
},
"status": {
"capacity": "5.904TiB",
"available": "5.902TiB",
"leader_weight": 1,
"region_weight": 1,
"start_ts": "2020-08-25T10:59:57+08:00",
"last_heartbeat_ts": "2020-08-28T10:49:55.144024892+08:00",
"uptime": "71h49m58.144024892s"
}
}
或者使用api
curl pd-addr:port/pd/api/v1/stores?state=2当然,监控也是能看到结果的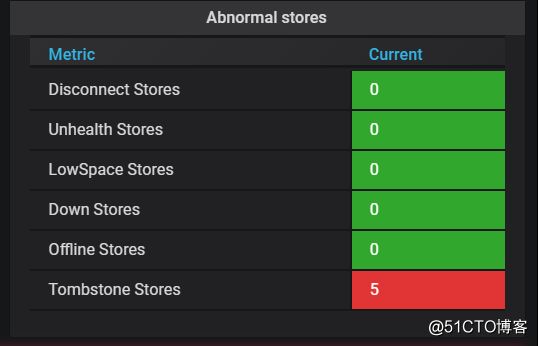
五、相关知识点
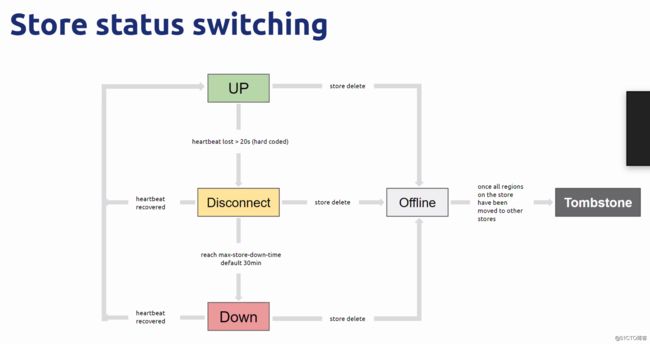
offline到tombstone这个过程本身是比较缓慢的,因为下线迁移的scheduler要和region balance scheduler抢占资源
缩容是指预备将某个 Store 下线,通过命令将该 Store 标记为 “Offline“ 状态,此时 PD 通过调度将待下线节点上的 Region 迁移至其他节点。
故障恢复是指当有 Store 发生故障且无法恢复时,有 Peer 分布在对应 Store 上的 Region 会产生缺少副本的状况,此时 PD 需要在其他节点上为这些 Region 补副本。
这两种情况的处理过程基本上是一样的。replicaChecker检查到 Region 存在异常状态的 Peer后,生成调度在健康的 Store 上创建新副本替换异常的副本。
系统中同时运行有其他的调度任务产生竞争,导致 balance 速度上不去。这种情况下如果 balance 调度的优先级更高,可以先停掉其他的调度或者限制其他调度的速度。例如 Region 没均衡的情况下做下线节点操作,下线的调度与 Region Balance 会抢占 region-schedule-limit 配额,此时你可以调小 replica-schedule-limit 以限制下线调度的速度,或者设置 disable-replace-offline-replica = true 来暂时关闭下线流程。五、后续操作
后面的操作就很常规了
停止节点
[sync360@tidb21 tidb-ansible-3.0.5]$ ansible-playbook stop.yml -l xx.xx.xx.xx,xx.xx.xx.xx,xx.xx.xx.xx,xx.xx.xx.xx,xx.xx.xx.xx
编辑inventory.ini
注释相关节点
重启监控
ansible-playbook rolling_update_monitor.yml --tags=prometheus
其实重启监控也一样能看到节点还是处于tombstone状态,这块也需要人为的去pd-ctl里删除,手册也写得不全,尤其是我们这个案例,是要重启后再加回集群的,不删除再加回来肯定后续信息会有异常
stores remove-tombstone
Tips:迁移完成后,不要忘记调回region-balance-limit和leader-balance-limit
调回参数后,各节点开始balance,直到评分一致
六、思考
本案例我们通过优化参数,达到大幅度提升下线调度速度,本案例是新加入集群的机器正在调度,且执行了store delete操作后的优化思路,但其实还有更优解:
临时下线维护操作:
主要利用tidb里只有leader提供服务
迁出leader比迁移region快很多,同时调整downtime阈值,避免region迁移,就可以快速下线维护,不过也要注意风险点,尤其是写入特点是非常分散的业务,具体的看原文,本文不在赘述
文章链接:
https://asktug.com/t/topic/33169