大数据介绍和集群安装--hadoop
大数据介绍及集群安装
-
- 1、大数据概述
- 2、什么是大数据?(Big Data)
- 3、传统数据与大数据的对比
- 4、大数据的特点
- 5、大数据生态系统
- 6、大数据技术为什么快?
- 7、Hadoop详解
- 8、Hadoop三大公司发型版本介绍
- 9、Hadoop的架构模型(1.x,2.x的各种架构模型介绍)
- 10、CDH版本Hadoop重新编译
- 11、CDH 分布式环境搭建
- 浏览器查看启动页面
1、大数据概述
传统数据处理介绍
目标: 了解大数据到来之前,传统数据的通用处理模式。
数据来源:
1、企业内部管理系统 ,如员工考勤(打卡)记录。
2、客户管理系统(CRM)
数据特征:
1、数据增长速度比较缓慢,种类单一。
2、数据量为GB级别,数据量较小
数据处理方式:
1、数据保存在数据库中。处理时以处理器为中心,应用程序到数据库中检索数据再进行计算(移
动数据到程序端)
遇到的问题:
1、数据量越来越大、数据处理的速度越来越慢。
2、数据种类越来越多,出现很多数据库无法存储的数据,如音频、照片、视频等。
2、什么是大数据?(Big Data)
目标:掌握什么是大数据、传统数据与大数据的对比有哪些区别、大数据的特点
是指无法在一定时间范围内用常规软件工具进行捕捉、管理和处理的数据集合,是需要新处理模式才能具有更强的决策力、洞察发现力和流程优化能力的海量、高增长率和多样化的信息资产。
是指一种规模大到在获取、存储、管理、分析方面大大超出了传统数据库软件工具能力范围的数据集合,具有海量的数据规模、快速的数据流转、多样的数据类型和价值密度低四大特征。
数据的存储单位
最小的基本单位是bit
1 Byte =8 bit
1 KB = 1,024 Bytes = 8192 bit
KB MB GB TB PB EB ZB YB BB NB DB 进率1024
3、传统数据与大数据的对比

4、大数据的特点
数据集主要特点
Volume(大量): 数据量巨大,从TB到PB级别。
Velocity(高速): 数据量在持续增加(两位数的年增长率)。
Variety(多样): 数据类型复杂,超过80%的数据是非结构化的。
Value(低密度高价值): 低成本创造高价值。
其他特征
数据来自大量源,需要做相关性分析。
需要实时或者准实时的流式采集,有些应用90%写vs.10%读。
数据需要长时间存储,非热点数据也会被随机访问。
传统数据与大数据处理服务器系统安装对比
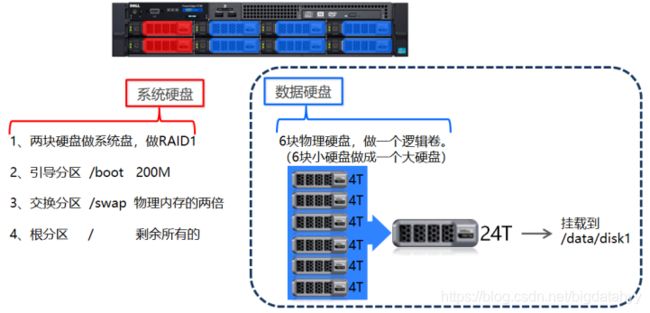
传统数据下服务器系统安装
在传统数据背景下,服务器系统安装中,系统硬盘、数据硬盘完全隔离。通常会将多块数据硬盘制作成LVM(逻辑卷),即将多块物理硬盘通过软件技术“拼接”在一起形成一个大的硬盘(逻辑上是一个硬盘)。
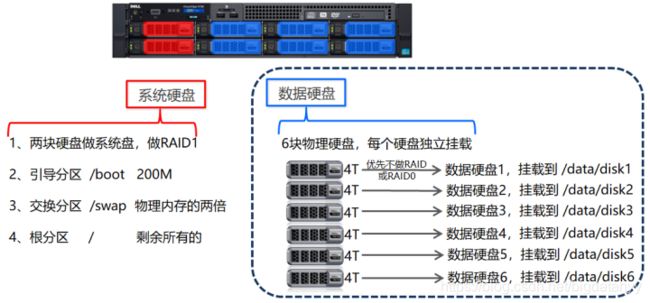
大数据下服务器系统安装
在大数据背景下,服务器系统安装中,系统硬盘、数据硬盘完全隔离。数据硬盘必须独立挂载,每个硬盘挂载到系统的一个独立的目录下。
5、大数据生态系统
目标:了解大数据生态系统,大数据技术列举
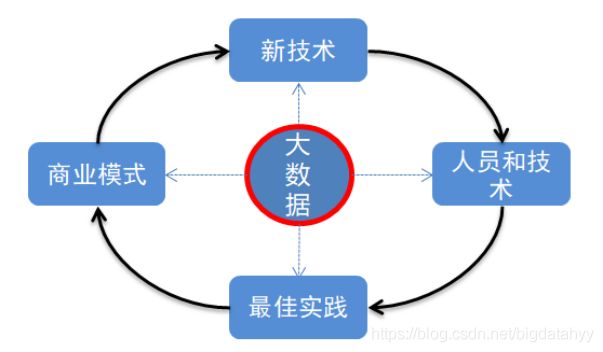
大数据:历史数据量逐渐攀升、新型数据类型逐渐增多。是企业必然会遇到的问题
新技术:传统方式与技术无法处理大量、种类繁多的数据,需要新的技术解决新的问题。
技术人员:有了问题,有了解决问题的技术,需要大量懂技术的人解决问题。
最佳实践:解决 问题的方法,途径有很多,寻找最好的解决方法。
商业模式:有了最好的解决办法,同行业可以复用,不同行业可以借鉴,便形成了商业模式。
新技术
HADOOP
HDFS: 海量数据存储。
YARN: 集群资源调度。
MapReduce: 历史数据离线计算。
Hive:海量数据仓库。
Hbase:海量数据快速查询数据库。
Zookeeper:集群组件协调。
Impala:是一个能查询存储在Hadoop的HDFS和HBase中的PB级数据的交互式查询引擎。
Kudu:是一个既能够支持高吞吐批处理,又能够满足低延时随机读取的综合组件
Sqoop:数据同步组件(关系型数据库与hadoop同步)。
Flume :海量数据收集。
Kafka:消息总线。
Oozie:工作流协调。
Azkaban: 工作流协调。
Zeppelin: 数据可视化。
Hue: 数据可视化。
Flink:实时计算引擎。
Kylin: 分布式分析引擎,提供Hadoop/Spark之上的SQL查询接口及多维分析。
Elasticsearch: 是一个分布式多用户能力的全文搜索引擎。
Logstash: 一个开源数据搜集引擎。
Kibana: 一个开源的分析和可视化平台。
SPARK
SparkCore:Spark 核心组件
SparkSQL:高效数仓SQL引擎
Spark Streaming: 实时计算引擎
Structured: 实时计算引擎2.0
Spark MLlib:机器学习引擎
Spark GraphX:图计算引擎
6、大数据技术为什么快?
目标:掌握传统数据与大数据相比在扩展性的区别、存储方式上的区别、可用性上
的区别、计算模型上的区别。
传统数据与大数据处理方式对比
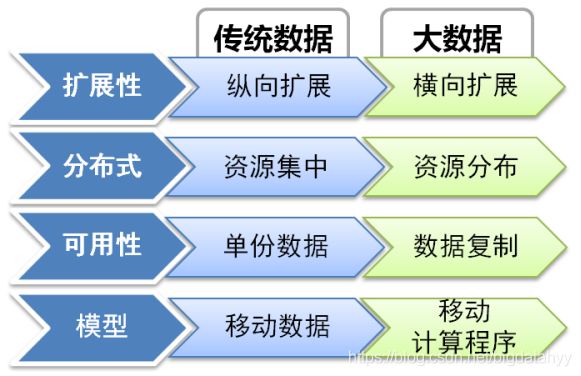
纵向扩展:
表示在需要处理更多负载时通过提高单个系统处理能力的方法来解决问题。最简单的情况就是为应用系统提供更为强大的硬件。例如如果数据库所在的服务器实例只有2G内存、低配CPU、小容量硬盘,进而导致了数据库不能高效地运行,那么我们就可以通过将该服务器的内存扩展至8G、更换大容量硬盘或者更换高性能服务器来解决这个问题
横向扩展
是将服务分割为众多的子服务并在负载平衡等技术的帮助下在应用中添加新的服务实例
例如如果数据库所在的服务器实例只有一台服务器,进而导致了数据库不能高效地运行,那么我们就可以通过增加服务器数量,将其构成一个集群来解决这个问题。
资源集中(计算与存储)
集中式计算:数据计算几乎完全依赖于一台中、大型的中心计算机的处理能力。和它相连的终端(用户设备)具有各不相同的智能程度。实际上大多数终端完全不具有处理能力,仅仅作为一台输入输出设备使用。
集中式存储:指建立一个庞大的数据库,把各种信息存入其中,各种功能模块围绕信息库的周围并对信息库进行录入、修改、查询、删除等操作的组织方式。
分布式(计算与存储)
分布式计算:是一种计算方法,是将该应用分解成许多小的部分,分配给多台计算机进行处理。这样可以节约整体计算时间,大大提高计算效率。
分布式存储:是一种数据存储技术,通过网络使用企业中的每台机器上的磁盘空间,并将这些分散的存储资源构成一个虚拟的存储设备,数据分散的存储在企业的各个角落,多台服务器。
大数据技术快的原因
1、分布式存储
2、分布式并行计算
3、移动程序到数据端
4、更前卫、更先进的实现思路
5、更细分的业务场景
6、更先进的硬件技术+更先进的软件技术
7、Hadoop详解
Hadoop的介绍以及发展历史
目标:了解Hadoop的起源,作者、发展历程
Hadoop之父Doug Cutting

1.?Hadoop最早起源于lucene下的Nutch。Nutch的设计目标是构建一个大型的全网搜索引擎,包括网页抓取、索引、查询等功能,但随着抓取网页数量的增加,遇到了严重的可扩展性问题——如何解决数十亿网页的存储和索引问题。
2.?2003年、2004年谷歌发表的三篇论文为该问题提供了可行的解决方案。
——分布式文件系统(GFS),可用于处理海量网页的存储
——分布式计算框架MAPREDUCE,可用于处理海量网页的索引计算问题。
——分布式的结构化数据存储系统Bigtable,用来处理海量结构化数据。
3.?Doug Cutting基于这三篇论文完成了相应的开源实现HDFS和MAPREDUCE,并从Nutch中剥离成为独立项目HADOOP,到2008年1月,HADOOP成为Apache顶级项目(同年,cloudera公司成立),迎来了它的快速发展期。
为什么叫Hadoop? Logo为什么是黄色的大象?
狭义上来说,Hadoop就是单独指代Hadoop这个软件(HDFS+MAPREDUCE)
广义上来说,Hadoop指代大数据的一个生态圈(Hadoop生态圈),包括很多其他的软件。

Hadoop的历史版本介绍
0.x系列版本:Hadoop当中最早的一个开源版本,在此基础上演变而来的1.x以及2.x的版本
1.x版本系列:Hadoop版本当中的第二代开源版本,主要修复0.x版本的一些bug等
2.x版本系列:架构产生重大变化,引入了yarn平台等许多新特性

8、Hadoop三大公司发型版本介绍
目标:了解最出名的三个Hadoop版本
1、免费开源版本apache:http://Hadoop.apache.org/
优点:拥有全世界的开源贡献者,代码更新迭代版本比较快,
缺点:版本的升级,版本的维护,版本的兼容性,版本的补丁都可能考虑不太周到,学习可以用,实际生产工作环境尽量不要使用
apache所有软件的下载地址(包括各种历史版本):
http://archive.apache.org/dist/
2、免费开源版本hortonWorks:https://hortonworks.com/
hortonworks主要是雅虎主导Hadoop开发的副总裁,带领二十几个核心成员成立Hortonworks,核心产品软件HDP(ambari),HDF免费开源,并且提供一整套的web管理界面,供我们可以通过web界面管理我们的集群状态,web管理界面软件HDF网址(http://ambari.apache.org/)
3、服务收费版本ClouderaManager: https://www.cloudera.com/
cloudera主要是美国一家大数据公司在apache开源Hadoop的版本上,通过自己公司内部的各种补丁,实现版本之间的稳定运行,大数据生态圈的各个版本的软件都提供了对应的版本,解决了版本的升级困难,版本兼容性等各种问题,生产环境推荐使用。
Hadoop的模块组成
1、HDFS:一个高可靠、高吞吐量的分布式文件系统。
2、MapReduce:一个分布式的离线并行计算框架。
3、YARN:作业调度与集群资源管理的框架。
4、Common:支持其他模块的工具模块。
9、Hadoop的架构模型(1.x,2.x的各种架构模型介绍)
目标:了解Hadoop1.x、2.x架构及两个版本架构的差异。
1.x的版本架构模型介绍

文件系统核心模块:
NameNode:集群当中的主节点,主要用于管理集群当中的各种数据
secondaryNameNode:主要能用于Hadoop当中元数据信息的辅助管理
DataNode:集群当中的从节点,主要用于存储集群当中的各种数据
数据计算核心模块:
JobTracker:接收用户的计算请求任务,并分配任务给从节点
TaskTracker:负责执行主节点JobTracker分配的任务
2.x的版本架构模型介绍
第一种:NameNode与ResourceManager单节点架构模型
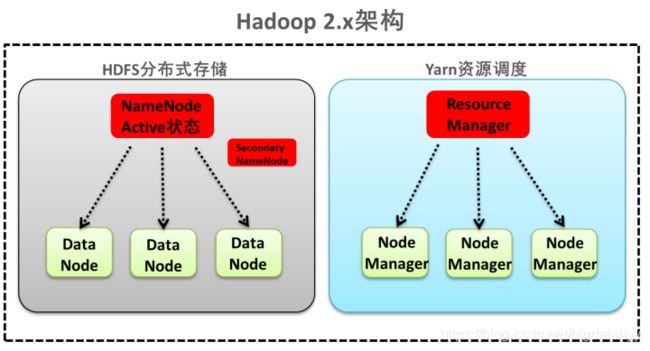
文件系统核心模块:
NameNode:集群当中的主节点,主要用于管理集群当中的各种元数据
secondaryNameNode:主要能用于Hadoop当中元数据信息的辅助管理
DataNode:集群当中的从节点,主要用于存储集群当中的各种数据
数据计算核心模块:
ResourceManager:接收用户的计算请求任务,并负责集群的资源分配
NodeManager:负责执行主节点APPmaster分配的任务
第二种:NameNode单节点与ResourceManager高可用架构模型

文件系统核心模块:
NameNode:集群当中的主节点,主要用于管理集群当中的各种数据
secondaryNameNode:主要能用于Hadoop当中元数据信息的辅助管理
DataNode:集群当中的从节点,主要用于存储集群当中的各种数据
数据计算核心模块:
ResourceManager:接收用户的计算请求任务,并负责集群的资源分配,以及计算任务的划分,通过zookeeper实现ResourceManager的高可用
NodeManager:负责执行主节点ResourceManager分配的任务
第三种:NameNode高可用与ResourceManager单节点架构模型

文件系统核心模块:
NameNode:集群当中的主节点,主要用于管理集群当中的各种数据,其中nameNode可以有两个,形成高可用状态
DataNode:集群当中的从节点,主要用于存储集群当中的各种数据
JournalNode:文件系统元数据信息管理
数据计算核心模块:
ResourceManager:接收用户的计算请求任务,并负责集群的资源分配,以及计算任务的划分
NodeManager:负责执行主节点ResourceManager分配的任务
第四种:NameNode与ResourceManager高可用架构模型

文件系统核心模块:
NameNode:集群当中的主节点,主要用于管理集群当中的各种数据,一般都是使用两个,实现HA高可用
JournalNode:元数据信息管理进程,一般都是奇数个
DataNode:从节点,用于数据的存储
数据计算核心模块:
ResourceManager:Yarn平台的主节点,主要用于接收各种任务,通过两个,构建成高可用
NodeManager:Yarn平台的从节点,主要用于处理ResourceManager分配的任务
10、CDH版本Hadoop重新编译
目标:重新编译CDH版本的Hadoop
为什么要编译Hadoop
由于CDH的所有安装包版本都给出了对应的软件版本,一般情况下是不需要自己进行编译的,但是由于CDH给出的Hadoop的安装包没有提供带C程序访问的接口,所以我们在使用本地库(本地库可以用来做压缩,以及支持C程序等等)的时候就会出问题,好了废话不多说,接下来看如何编译
由于后续课程需要使用snappy进行压缩数据,而CDH给出的Hadoop的安装包没有提供带C程序访问的接口,无法使用snappy,所以使用本地库(本地库可以用来做压缩,以及支持C程序等等)的时候就会出问题,所系需要重新编译使其支持snappy。
准备编译环境linux环境
准备一台linux环境,内存4G或以上,硬盘40G或以上,我们这里使用的是Centos6.9 64位的操作系统(注意:一定要使用64位的操作系统)
虚拟机联网,关闭防火墙,关闭selinux
关闭防火墙命令:
service iptables stop
chkconfig iptables off
关闭selinux
vim /etc/selinux/config

(注意:如果你安装jdk1.7或jdk1.8的话必须要编译,除非你的jdk是编译好的,不然必须要走这一步)
注意:亲测证明hadoop-2.6.0-cdh5.14.0 这个版本的编译,只能使用jdk1.7,如果使用jdk1.8那么就会报错
查看centos6.9自带的openjdk
rpm -qa | grep java
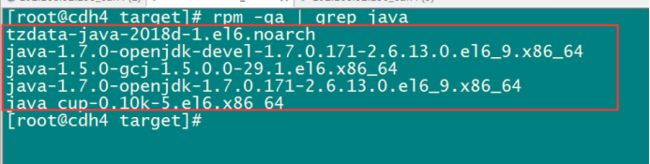
将所有这些openjdk全部卸载掉
rpm -e java-1.6.0-openjdk-1.6.0.41-1.13.13.1.el6_8.x86_64 tzdata-java-2016j-1.el6.noarch java-1.7.0-openjdk-1.7.0.131-2.6.9.0.el6_8.x86_64
注意:这里一定不要使用jdk1.8,亲测jdk1.8会出现错误
将我们jdk的安装包上传到/export/softwares(我这里使用的是jdk1.7.0_71这个版本)
解压我们的jdk压缩包
统一两个路径
mkdir -p /export/servers
mkdir -p /export/softwares
cd /export/softwares
tar zxvf jdk-7u75-linux-x64.tar.gz -C ../servers/
配置环境变量
vim /etc/profile.d/java.sh
在java.sh内添加一下内容,保存退出
export JAVA_HOME=/export/servers/jdk1.7.0_75
export PATH=:$JAVA_HOME/bin:$PATH
注意:
有种办法是将配置信息追加到系统配置文件/etc/profile内的最后,此方法也行,但profile是系统核心配置文件,若修改时不小心损坏了配置文件,会导致系统很多基本功能失效,此方法风险较高,不建议使用。
让修改立即生效
source /etc/profile
安装maven
这里使用maven3.x以上的版本应该都可以,不建议使用太高的版本,强烈建议使用3.0.5的版本即可
将maven的安装包上传到/export/softwares
然后解压maven的安装包到/export/servers
cd /export/softwares/
tar -zxvf apache-maven-3.0.5-bin.tar.gz -C ../servers/
配置maven的环境变量
vim /etc/profile.d/maven.sh
export MAVEN_HOME=/export/servers/apache-maven-3.0.5
export MAVEN_OPTS="-Xms4096m -Xmx4096m"
export PATH=:$MAVEN_HOME/bin:$PATH

让修改立即生效
source /etc/profile
解压maven的仓库,我已经下载好了的一份仓库,用来编译Hadoop会比较快
tar -zxvf mvnrepository.tar.gz -C /export/servers/
修改maven的配置文件
cd /export/servers/apache-maven-3.0.5/conf
vim settings.xml
指定我们本地仓库存放的路径
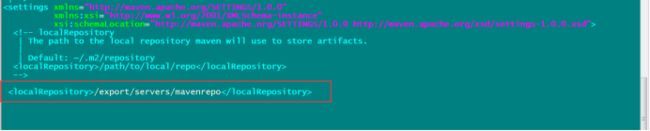
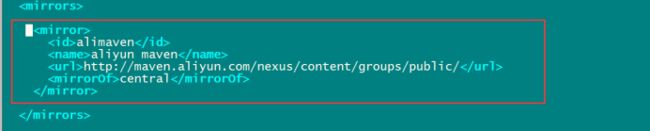
添加一个阿里云的镜像地址,会让我们下载jar包更快
alimaven
aliyun maven
http://maven.aliyun.com/nexus/content/groups/public/
central
安装findbugs
下载findbugs
cd /export/softwares
解压findbugs
tar -zxvf findbugs-1.3.9.tar.gz -C ../servers/
配置findbugs的环境变量
vim /etc/profile.d/findbugs.sh
export FINDBUGS_HOME=/export/servers/findbugs-1.3.9
export PATH=:$FINDBUGS_HOME/bin:$PATH

让修改立即生效
source /etc/profile
在线安装一些依赖包
yum install -y autoconf automake libtool cmake
yum install -y ncurses-devel
yum install -y openssl-devel
yum install -y lzo-devel zlib-devel gcc gcc-c++
bzip2压缩需要的依赖包
yum install -y? bzip2-devel
安装protobuf
protobuf下载百度网盘地址 https://pan.baidu.com/s/1pJlZubT
下载之后上传到 /export/softwares,解压protobuf并进行编译。
cd /export/softwares
tar -zxvf protobuf-2.5.0.tar.gz -C ../servers/
cd /export/servers/protobuf-2.5.0
./configure
make && make install
安装snappy
snappy下载地址:http://code.google.com/p/snappy/
cd /export/softwares/
tar -zxvf snappy-1.1.1.tar.gz -C ../servers/
cd ../servers/snappy-1.1.1/
./configure
make && make install
下载cdh源码准备编译
源码下载地址为: http://archive.cloudera.com/cdh5/cdh/5/Hadoop-2.6.0-cdh5.14.0-src.tar.gz
下载源码进行编译
cd /export/softwares
tar -zxvf hadoop-2.6.0-cdh5.14.0-src.tar.gz -C ../servers/
cd /export/servers/hadoop-2.6.0-cdh5.14.0
编译不支持snappy压缩:
mvn package -Pdist,native -DskipTests –Dtar
编译支持snappy压缩:
mvn package -DskipTests -Pdist,native -Dtar -Drequire.snappy -e -X
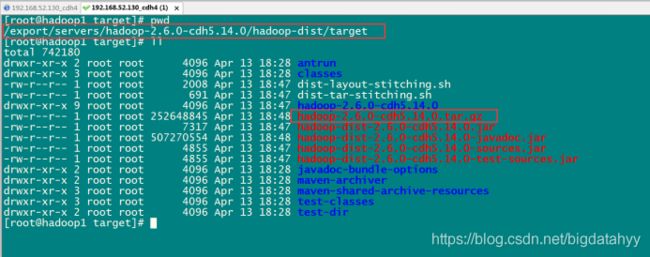
编译完成之后我们需要的压缩包就在下面这个路径里面
/export/servers/hadoop-2.6.0-cdh5.14.0/hadoop-dist/target
常见编译错误
如果编译时候出现这个错误: An Ant BuildException has occured: exec returned: 2
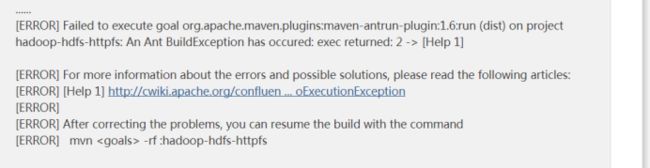
这是因为tomcat的压缩包没有下载完成,需要自己下载一个对应版本的apache-tomcat-6.0.53.tar.gz的压缩包放到指定路径下面去即可
这两个路径下面需要放上这个tomcat的 压缩包
/export/servers/hadoop-2.6.0-cdh5.14.0/hadoop-hdfs-project/hadoop-hdfs-httpfs/downloads
/export/servers/hadoop-2.6.0-cdh5.14.0/hadoop-common-project/hadoop-kms/downloads

11、CDH 分布式环境搭建
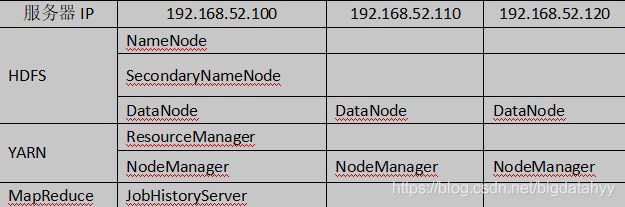
目标:搭建基于CDH的分布式集群
安装环境服务部署规划
第一步:上传压缩包并解压
将我们重新编译之后支持snappy压缩的Hadoop包上传到第一台服务器并解压
第一台机器执行以下命令
cd /export/softwares/
mv hadoop-2.6.0-cdh5.14.0-自己编译后的版本.tar.gz hadoop-2.6.0-cdh5.14.0.tar.gz
tar -zxvf hadoop-2.6.0-cdh5.14.0.tar.gz -C ../servers/
第二步:查看Hadoop支持的压缩方式以及本地库
第一台机器执行以下命令
cd /export/servers/hadoop-2.6.0-cdh5.14.0
bin/hadoop checknative

如果出现openssl为false,那么所有机器在线安装openssl即可,执行以下命令,虚拟机联网之后就可以在线进行安装了
yum -y install openssl-devel

第三步:修改配置文件
修改core-site.xml
第一台机器执行以下命令
cd /export/servers/hadoop-2.6.0-cdh5.14.0/etc/hadoop
vim core-site.xml
fs.defaultFS
hdfs://node01:8020
hadoop.tmp.dir
/export/servers/hadoop-2.6.0-cdh5.14.0/hadoopDatas/tempDatas
io.file.buffer.size
4096
fs.trash.interval
10080
修改hdfs-site.xml
第一台机器执行以下命令
cd /export/servers/hadoop-2.6.0-cdh5.14.0/etc/hadoop
vim hdfs-site.xml
dfs.namenode.secondary.http-address
node01:50090
dfs.namenode.http-address
node01:50070
dfs.namenode.name.dir
file:///export/servers/hadoop-2.6.0-cdh5.14.0/hadoopDatas/namenodeDatas
dfs.datanode.data.dir
file:///export/servers/hadoop-2.6.0-cdh5.14.0/hadoopDatas/datanodeDatas
dfs.namenode.edits.dir
file:///export/servers/hadoop-2.6.0-cdh5.14.0/hadoopDatas/dfs/nn/edits
dfs.namenode.checkpoint.dir
file:///export/servers/hadoop-2.6.0-cdh5.14.0/hadoopDatas/dfs/snn/name
dfs.namenode.checkpoint.edits.dir
file:///export/servers/hadoop-2.6.0-cdh5.14.0/hadoopDatas/dfs/nn/snn/edits
dfs.replication
2
dfs.permissions
false
dfs.blocksize
134217728
修改Hadoop-env.sh
第一台机器执行以下命令
cd /export/servers/hadoop-2.6.0-cdh5.14.0/etc/hadoop
vim hadoop-env.sh
export JAVA_HOME=/export/servers/jdk1.8.0_141
修改mapred-site.xml
第一台机器执行以下命令
cd /export/servers/hadoop-2.6.0-cdh5.14.0/etc/hadoop
vim mapred-site.xml
mapreduce.framework.name
yarn
mapreduce.job.ubertask.enable
true
mapreduce.jobhistory.address
node01:10020
mapreduce.jobhistory.webapp.address
node01:19888
修改yarn-site.xml
第一台机器执行以下命令
cd /export/servers/hadoop-2.6.0-cdh5.14.0/etc/hadoop
vim yarn-site.xml
yarn.resourcemanager.hostname
node01
yarn.nodemanager.aux-services
mapreduce_shuffle
修改slaves文件
第一台机器执行以下命令(主机名是什么你就写什么)
cd /export/servers/hadoop-2.6.0-cdh5.14.0/etc/hadoop
vim slaves

第四步:创建文件存放目录
第一台机器执行以下命令
node01机器上面创建以下目录
mkdir -p /export/servers/hadoop-2.6.0-cdh5.14.0/hadoopDatas/tempDatas
mkdir -p /export/servers/hadoop-2.6.0-cdh5.14.0/hadoopDatas/namenodeDatas
mkdir -p /export/servers/hadoop-2.6.0-cdh5.14.0/hadoopDatas/datanodeDatas
mkdir -p /export/servers/hadoop-2.6.0-cdh5.14.0/hadoopDatas/dfs/nn/edits
mkdir -p /export/servers/hadoop-2.6.0-cdh5.14.0/hadoopDatas/dfs/snn/name
mkdir -p /export/servers/hadoop-2.6.0-cdh5.14.0/hadoopDatas/dfs/nn/snn/edits
第五步:安装包的分发
第一台机器执行以下命令
cd /export/servers/
scp -r hadoop-2.6.0-cdh5.14.0/ 主机名:$PWD
scp -r hadoop-2.6.0-cdh5.14.0/ 主机名:$PWD
第六步:配置Hadoop的环境变量
三台机器都要进行配置Hadoop的环境变量
三台机器执行以下命令
vim /etc/profile.d/hadoop.sh
export HADOOP_HOME=/export/servers/hadoop-2.6.0-cdh5.14.0
export PATH=:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
配置完成之后生效
source /etc/profile
第七步:集群启动
要启动 Hadoop 集群,需要启动 HDFS 和 YARN 两个集群。
注意:首次启动HDFS时,必须对其进行格式化操作。本质上是一些清理和准备工作,因为此时的 HDFS 在物理上还是不存在的。
bin/hdfs namenode -format或者bin/Hadoop namenode –format (格式化)
单个节点逐一启动
在主节点上使用以下命令启动 HDFS NameNode: hadoop-daemon.sh start namenode
在每个从节点上使用以下命令启动 HDFS DataNode: hadoop-daemon.sh start datanode
在主节点上使用以下命令启动 YARN ResourceManager: yarn-daemon.sh start resourcemanager
在每个从节点上使用以下命令启动 YARN nodemanager: yarn-daemon.sh start nodemanager
以上脚本位于$HADOOP_PREFIX/sbin/目录下。如果想要停止某个节点上某个角色,只需要把命令中的start 改为stop 即可。
脚本一键启动HDFS、Yarn
如果配置了 etc/Hadoop/slaves 和 ssh 免密登录,则可以使用程序脚本启动所有Hadoop 两个集群的相关进程,在主节点所设定的机器上执行。
启动集群
node01节点上执行以下命令
第一台机器执行以下命令
cd /export/servers/hadoop-2.6.0-cdh5.14.0/
sbin/start-dfs.sh
sbin/start-yarn.sh
停止集群:没事儿不要去停止集群
sbin/stop-dfs.sh
sbin/stop-yarn.sh
脚本一键启动所有
一键启动集群
sbin/start-all.sh
一键关闭集群
sbin/stop-all.sh
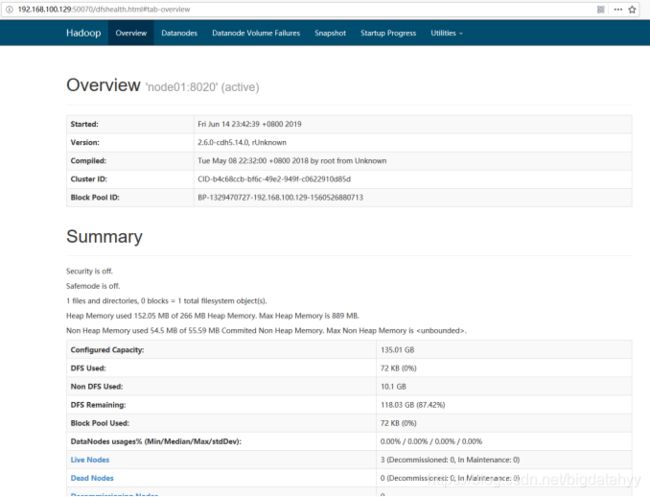
浏览器查看启动页面
hdfs集群访问地址: http://192.168.52.100:50070/dfshealth.html#tab-overview
yarn集群访问地址: http://192.168.52.100:8088/cluster