HEVC中低复杂度量化技术
本文提出了一种HEVC中的低复杂度量化技术,并希望对新一代视频编码标准VVC有一定的启发。
文章目录
- 摘要
- 一、引言
- 二、HEVC中采用的量化技术
- 三、FAST RDOQ
-
- 1.STATISTICS-BASED FAST RDOQ
- 2.RATE DISTORTION MODELS FOR FAST RDOQ
- 四、全零块检测
- 五、率失真性能和编码复杂度
- 六、讨论
- 总结
摘要
在HEVC中,率失真优化量化(RDOQ)在rate和distortion之间有着很好的折衷,这使得它在率失真性能方面有着很不错的发展前景。但是,RDOQ在如今视频编码下的大量使用导致的结果就是大幅提升了复杂度。因此,基于这一点,本文对HEVC中的fast RDOQ和全零块检测进行了回顾,希望将来可以将两者应用于VVC,从而减少其编码复杂度,实现低复杂度量化。
提示:本文从以下几个方面对低复杂度量化进行了全面剖析,主要从fast RDOQ和全零块检测两个方面。
一、引言
相比于H.264,HEVC标准采用了更加有效的编码工具。具体来说,HEVC采用灵活的块树结构来更好地适应视频的局部特征,比如编码单元、预测单元和变换单元。而且,HEVC的帧内预测模式从9种扩展到35种,来更好解释复杂的纹理方向;同时采用一系列先进的帧间预测技术来消除时间冗余。量化方面,硬决策量化(hard-decision quantization)慢慢演变成软决策量化(soft-decision quantization),而且把率失真优化(RDO)准则加入到量化部分,由此对于各个系数可以得到更优的量化level。除此之外,还用CABAC来消除统计冗余。
在量化方案中,由仅依赖输入变换系数和量化步长的硬决策量化演变成基于RDO优化量化准则的软决策量化。
其中,在早期广泛使用的硬决策量化中,给定一个量化参数(QP),将变换系数映射到相应的量化level。在H.264中采用了带dead-zone的硬决策量化,其中的舍入偏移量由残差系数分布来决定。
在软决策量化中,确定量化level时,还要考虑一个变换块(TB)的量化残差之间的相互依赖性。也就是说,量化候选的RD cost会被认真处理评估,从而以这种软决策量化确定的量化level可以在残差的coding bits和量化失真之间达到极好的平衡。
研究表明,与传统的带有dead-zone的硬决策量化相比,软决策量化在计算复杂度高的情况下可以节省6%~8%的比特率。然而,由于残差coding bits应当是通过熵编码来同步计算的,软决策量化的高复杂度可能会对此带来麻烦。
因此,已经有很多方案来实现视频编码中的软决策量化。例如,在H.263+和H.264中,这种算法可以通过网格搜索的方式来实现,简单来说就是把每个量化候选的RD cost集成到网格分支中,通过动态规划或维特比算法来确定最优路径。但是,在量化中进行全网格搜索具有极高的计算复杂度。鉴于此,网格搜索被简化为RDOQ,通过RDOQ可以实现次优量化。在H.264/AVC、HEVC和AVS2编码器中已经广泛应用了RDOQ,它可以检测有限个数量的量化候选,最终使用ED cost最小的那一个。
本文主要阐述视频编码中的量化问题,这对平衡视频编码的失真程度和编码比特具有重要意义。其中,快量化技术的目的就是以一种最有效的方式来得到最优量化系数。更具体的说,本文主要从两个角度实现低复杂度量化。
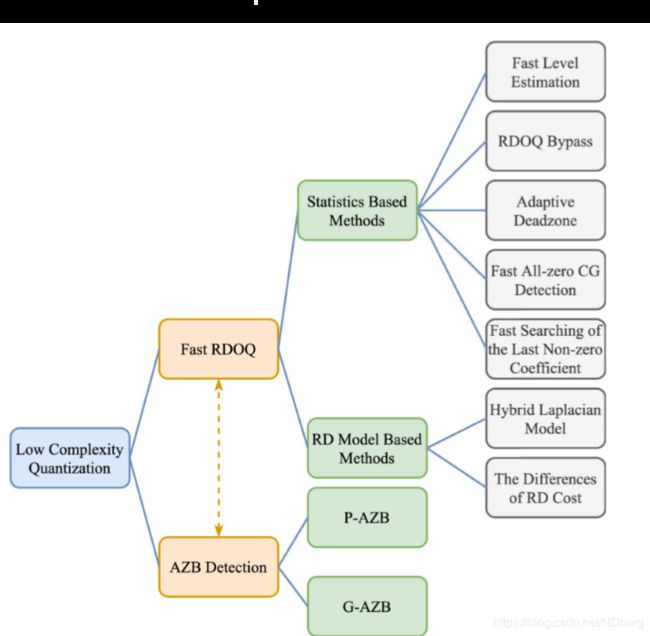
如上图,大的来说,本文将从两个角度研究低复杂度量化技术,也就是fast RDOQ和全零块检测。在fast RDOQ方面,主要介绍基于统计的方法和基于RD模型的方法。在全零块检测方面,主要从真全零块(G-AZB)和伪全零块(P-AZB)的不同检测方法入手来研究。总之,从以上两个大的角度入手来实现低复杂度量化,从而期望对新一代的VVC标准的量化优化方案有一定的帮助。
二、HEVC中采用的量化技术
这部分主要回顾HEVC标准中的量化技术。
硬决策量化可以表示如下,
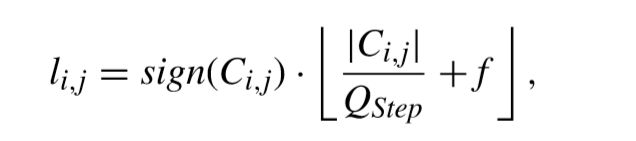
其中f表示舍入偏移量,一般根据slice类型设置。
软决策量化中的RDOQ中,利用RDO准则来寻找最优量化系数。具体来说,RDO的目标就是在coding bits budget(R^)的约束下让失真D尽可能的小,可以用下面的式子来表示,
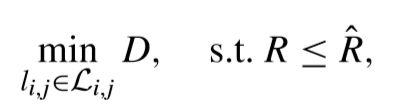
可以看出,上面的式子是在一定的约束条件下的,可以引入λ多项式来把这样的有约束问题转换为无约束问题,这样上面的式子就变成了,
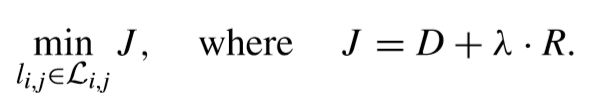
这样,RDOQ可以根据上面式子来选择最优量化level。再具体一点,在RDOQ中主要有两个过程。
第一,对变换系数进行预量化,量化候选值如下,

至此,最优量化可写成,
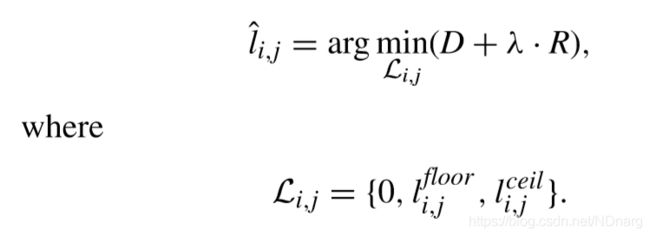
要知道的是,RDOQ和残差熵编码是基于CG(一个TB下的4x4的组)来实现的。
RDOQ的第二步,就是计算RD cost来确定当前CG能否量化为全零CG,同时,确定最后一个非零系数的位置,将之后位置的系数置零。
可以看出,RDOQ过程还是比较繁琐的,为了加速RDOQ过程,一种方式就是加速量化过程,另一种方式就是检测出全零块,以跳过繁琐的变换、量化、熵编码、反量化和反变换过程。这也就是本文研究的两个主要角度。
三、FAST RDOQ
RDOQ的目的就是确定一组最佳量化结果,使得TB的RD cost最小,这种方式尽管增加了计算复杂度,但是无疑会带来压缩性能方面的收益。本文主要有两种方式来实现低复杂度RDOQ,一种是基于统计的方法,另一种是基于RD模型的方法。
1.STATISTICS-BASED FAST RDOQ
这种基于统计的方法主要是根据统计分析来跳过RDOQ过程来避免不必要的计算。
有一种比较特殊的块即不包含DC系数的全量化零块(AQZB-DC)可以被检测,它占据了非零块的20%左右。再者,统计结果表明,在AQZB-DC块中,超过30%的DC系数仍旧维持了l(i,j)ceil。因此,研究一种对于AQZB-DC块的预测模型,它可以自适应调节DC系数的量化level。这样的话,对于这种类型的TB,RDOQ过程可以直接跳过。
在递归TB划分结构下重复调用RDOQ,这无疑会加重量化的计算负担。因此,有研究提出将硬决策量化直接应用于TB,在获得最佳TB大小后采用RDOQ。这种方法在low delay P配置下,BD-Rate仅损失0.25%就达到了27%量化复杂度的减少。
虽然RDOQ对于HEVC来说取得了极大性能的提升,但是,比起硬决策量化,它不能一直变化量化level。比如,如果当前TB在预量化之后是一个全零块,那么RDOQ就显得没有必要。再者,如果硬决策量化的量化结果和RDOQ的结果相同,那么计算RD cost是相当浪费的。因此又有研究提出了基于变换系数统计的RDOQ bypass方案。根据统计实验发现,当一个TB的所有变换系数比阈值(量化步长大小决定)小时,无需RDOQ,当前TB可以直接被认为是零块。而且,当一个TB的绝对量化系数和比给定的阈值小时,表明非零系数占据了比较小的一部分,那么RDOQ将被跳过,并且硬决策量化将来优化编码时间。
有研究提出了一种简化RDOQ候选的选择和最后非零系数搜索的方案。特别地,来评估条件概率![]() 其中,L可能为1、2、3或者大于3。具有不同QP的随机访问配置下的统计结果得出,当L>3时,这个条件概率平均值为4%,这表明,量化level在预量化的结果下很容易保持不变,因此可以跳过RDOQ。除此之外,对最后非零系数搜索的简化是在4x4TB上进行的,在此之上,其搜索范围缩小到了前四个非零系数。
其中,L可能为1、2、3或者大于3。具有不同QP的随机访问配置下的统计结果得出,当L>3时,这个条件概率平均值为4%,这表明,量化level在预量化的结果下很容易保持不变,因此可以跳过RDOQ。除此之外,对最后非零系数搜索的简化是在4x4TB上进行的,在此之上,其搜索范围缩小到了前四个非零系数。
另有研究提出了一种早期量化level决策的方案,因为观察到对于较大TB中位于高频域的系数,RDOQ倾向于将量化level从“1”调整到“0”。这种方案让量化level为0,而且没有RDOQ过程,如下面式子所示,
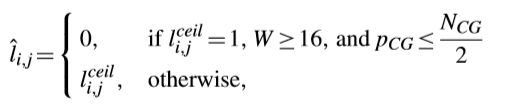
这种方案在all intra(AI)配置下节省了12.84%的量化时间,并且BD-Rate损失仅0.21%。另外,考虑到某些序列需要调整![]()
为70%以下,因此,相关人员建议在预量化阶段采用自适应舍入偏移量来计算l(i,j)ceil。对于舍入偏移量f可以调整如下,
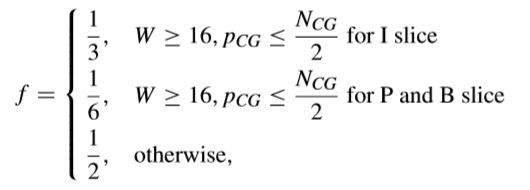
提出的这种自适应舍入偏移量在all intra配置下,实现了15.29%的量化时间节省,并且BD-Rate损失非常小(平均0.01%)。
2.RATE DISTORTION MODELS FOR FAST RDOQ
达到低复杂度RDOQ的关键就是建立一个精确的RD模型来估计RD cost。考虑到RDOQ是通过比较l(i,j)ceil和l(i,j)floor的RD cost来调整量化level,从而得到关于不同量化候选的RD cost差异。特别地,有研究用ΔJ估计模型制定了一种简化的level调整方法,如下所示,
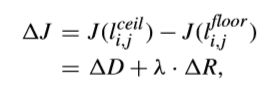
这里ΔD表示如下,
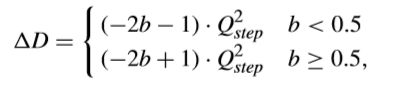
其中,b是l(i,j)float的小数部分。通过这种方式,可以放心大胆地移除反量化过程。而对于ΔR,可以表示如下,
![]()
可以根据l(i,j)ceil的值推导出前三个语法元素的ΔR。这四个语法元素的explicit值可以通过在HEVC测试模型中定义的查找表来获得。
有研究还为低复杂度RDOQ建立了ΔJ模型。通常,符号标志的编码位和用于表示最后有效系数的编码位还包括在ΔR估计中。随后,将之前等式中的ΔJ设置为0,可以得出阈值,
![]()
这样的话,最佳量化level可以确定,如下所示,
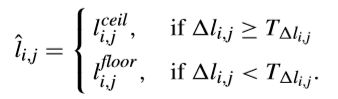
还有研究提出了针对HEVC编码器的并行RDOQ方案,利用该方案可以在GPU上并行执行RDO程序,从而实现实时编码4K序列。
除此之外,还有人提出用混合拉普拉斯分布对变换系数进行建模。在HEVC中,使用四叉树结构,这使得TB大小从4x4到32x32变化,从而变换系数的分布也截然不同。而提出的混合拉普拉斯分布包含一系列具有不同参数的模型,这可以来适应不同TB尺寸的特征。此外,在建模中考虑了4x4TU的变换类型,绿如DCT-II、DST-VII和变换跳过。混合拉普拉斯分布可以用下式来表示,
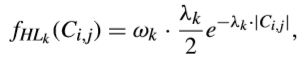
其中k表示TB层索引。第0层到第3层分别表示TB尺寸从32x32到4x4变化。第4层表示采用DST-VII变换。第5层表示采用变换跳过。
在量化失真建模方面,采用了硬决策量化的量化level,将反量化系数和原变换系数之间的SSE视为量化失真。以这种方式,可以得到每个量化候选的RD cost。最终,估算的最优量化结果可以将不同量化候选的RD cost最小化来得出,如下所示,
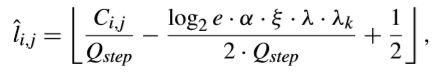
其中α是可以用于调整模型精度的训练参数。
全零CG也可以根据下面的阈值来有效得出,

如果一个CG的所有变换系数都满足上式,那这样的CG也可以被认为是全零CG。
四、全零块检测
试想,在变换或量化之前尽早的检测出全零块对于优化编码具有重要意义,因为检测出全零块可以省去像变换、量化、残差编码、反量化和反变换这样的繁琐步骤,到那个时候,这些步骤可以直接跳过,无疑减少了编码复杂度。
对于全零块的检测,已经有很多方案。例如在H.264中,有一种方案就是用一种混合模型来检测零系数。稍微具体来说,就是用高斯分布对空间域残差进行建模,然后用SAD来确定用于检测零系数的阈值,为适应哈达玛变换,用SATD代替SAD。
对于HEVC中全零块的检测,由于HEVC引入了大尺寸的TB(如16x16和32x32),这使得其全零块的检测更具有挑战性,也就是说,H.264/AVC用于全零块检测的方法也许不能用于HEVC。
在HEVC中为了更好地与RDOQ过程协同,有一些研究专注于两种类型全零块的检测,即真全零块(G-AZB)和伪全零块(P-AZB)。解释一下,所谓真全零块,是指通过硬决策量化可以直接将TB量化成全零块;伪全零块指那些通过RDOQ有可能量化成全零块的TB。
下面仔细来介绍一下G-AZB和P-AZB的检测。
对于G-AZB的检测:
首先,之前提到的硬决策量化也可以写成下面这样的式子,
![]()
其中,M是与QP有关的多项式系数,offset是与slice类型有关的舍入偏移量,Qsh取决于QP、TB尺寸和编码bit-depth。在G-AZB中,|li,j|应当是小于1的。因此,给出TB尺寸W和量化参数QP,对于某一个DCT系数Ci,j的检测阈值可以写成下面式子,
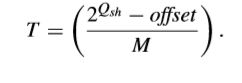
阈值T也被广泛用于检测全零块。
还有相关人员提出了一种用于HEVC的混合全零块检测方法。起初,为减少计算复杂度,对于4x4和8x8的TU,用Walsh-order的哈达玛变换来代替DCT变换,对于16x16和32x32的TU,用DCT变换。由此,提取不同TB大小的SATD*,可以得到两个真全零块的检测阈值。
第一个检测阈值,即在之前提到的阈值基础上增加了一个系数W^2(W即TB尺寸),表示如下,
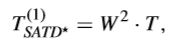
第二个对于G-AZB的检测阈值可以通过用拉普拉斯分布对预测残差建模得到,表示如下,
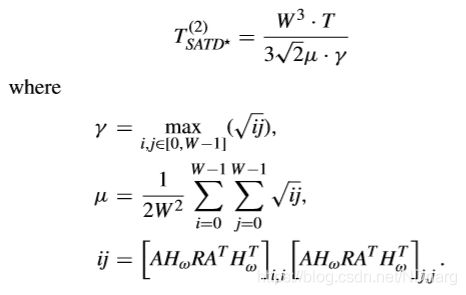
这样,G-AZB的检测阈值就可以取上面提到两个阈值中较小的那一个来得到,即
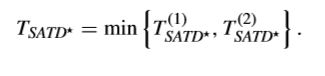
除此之外,还有人提出,基于全零块检测修改哈达玛变换去更好适应HEVC的变换量化特征。也就是说,对于不同尺寸大小的TB,G-AZB的检测阈值也不同,即
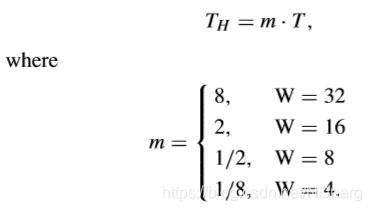
这样的话,在HM平台上,哈达玛变换将被默认用于4x4和8x8的TU,即使更小的TU也不会额外带来计算cost。然而,对于像16x16和32x32这样大尺寸的TU,哈达玛变换的计算cost是非常大的。因此,对于大尺寸的TU,哈达玛变换系数应当统一一下。首先,把16x16和32x32的TU分成8x8的子块,在每个这样的子块上用8x8的哈达玛变换。然后,提取8x8子块左上部分的DC系数,得到2x2和4x4的DC块,再在DC块上再一次使用哈达玛变换(DC哈达玛变换)。值得注意的是,每个8x8子块的DC系数可以通过在空间域增加残差来有效获得。如果所有的系数均小于TH,那么这个TB可以认为是一个全零块。
基于之前提到的真全零块的检测阈值,又有人额外提出了一种较低和较高的SAD阈值来对全零块和非全零块进行分类。较低的阈值被设定为(d/100)·T,如果一个TB的SAD比这个较低的阈值小,那么这个TB可以认为是真全零块。而较高的阈值如下所示,
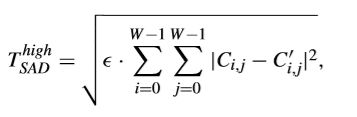
其中,€根据经验定义如下,

至此,真全零块的检测就告一段落。
伪全零块的检测是在“非真全零块”上进行的。本质上,P-AZB检测的关键就是AZB的RD cost是否低于NAZB。RD cost可以表示如下,
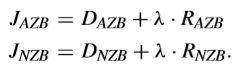
JAZB也可以写成这样,
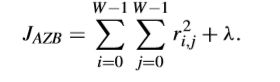
而对于DNZB可以写成这样,
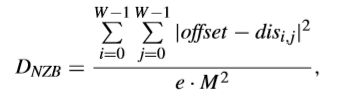
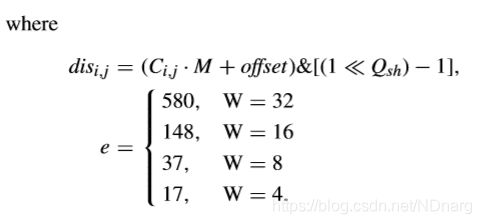
对于P-AZB的检测,为更好地适应较大TU的特征,TB将根据QP和QPmax分为高频区域和低频区域。低频区域尺寸如下,
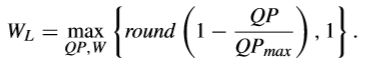
P-AZB的检测实际上是在低频区域进行的,如果低频区域的最大变化系数比下面的阈值还要小,那么这个TB可以认为是P-AZB,

其中,kfei一般为2.2。
为更进一步研究P-AZB,需要进一步比较关于JAZB和JNZB的率失真性能。特别地,JAZB可以通过下面式子得到,
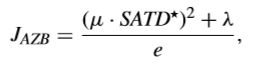
DAZB可以同通过训练来得到,由此,导出两个确定区间来预测P-AZB。
五、率失真性能和编码复杂度
这一部分主要讨论fast RDOQ和全零块检测在RD性能和编码复杂度方面所实现的效果。
其中,fast RDOQ在all intra(AI)、random access(RA)和low delay(LD)配置下进行评估。由于在AI配置下对于全零块检测性能评估较少,所以全零块检测性能评估主要在RA和LD配置下进行。
基于fast RDOQ的混合拉普拉斯分布算法在编码性能和计算复杂度上达到了很好的折衷,与传统的RDOQ相比,它在仅增加0.3%BD-Rate的情况下节省了70%的量化时间。之前提到过的基于统计的fast RDOQ可以带来30%到40%量化时间的减少。包括之前提到的对于 G-AZB的混合模型检测的方法可以很精确地预测全零块,在性能损失仅0.06%的情况下,达到了超过20%的时间节省的效果,据研究,这种混合模型检测全零块的方法在4K序列上以AI配置的方式也表现突出,量化时间节省了20%~26%,这对于4K视频的量化有积极重要的意义!
六、讨论
fast RDOQ和全零快检测之间有着微妙的联系。他们的目的都是为了在找出最优量化level的前提下,实现减少RD cost计算复杂度的目的。由于前者是在系数上进行,后者在块上进行,因此,它们必须一起协同起来,才能实现低复杂度量化优化的目的。
可以相信,用在HEVC上的fast RDOQ和全零块检测,在不久的将来,在VVC中也可以用到低复杂度的量化方式。提出几点憧憬,第一,系数应该是低复杂度,对实际应用友好的;第二,对于VVC来说,这种低复杂度量化优化算法应当可以更好地适应网格结构;第三,RD模型应当是可以重复建立的;最后一点,希望在RD建模过程中也可以考虑多变换核选择(MTS)。
总结
量化在现今视频编码中对于平衡码率和失真扮演着极其重要的作用。本文主要回顾了HEVC中的低复杂度量化技术,并且对与将来VVC中的量化优化做了简单憧憬。本质上,快速量化技术依赖于最佳量化指标,从而不需要经过变化、量化、熵编码、反量化和反变换这些繁琐的步骤。有理由相信,近年来机器学习的兴起,可以以一种低复杂度高效的方法来实现智能地得到量化系数,这也会在率失真复杂度cost上大展宏图。
注:本文是博主在研读了一篇IEEE上Low Complexity Quantization in High Efficiency Video Coding论文后,自行总结,希望对大家有所帮助,谢谢!