Flink 1.11 最重要的 Feature —— Hive Streaming 之前已经和大家分享过了,今天就和大家来聊一聊另一个特别重要的功能 —— CDC。
CDC概述
何为CDC?Change Data Capture,将数据库中的’增’、’改’、’删’操作记录下来。在很早之前是通过触发器来完成记录,现在通过 binlog+同步中间件来实现。常用的 binlog 同步中间件有很多,比如 Alibaba 开源的 canal[1],Red Hat 开源的debezium[2],Zendesk 开源的 Maxwell[3] 等等。
这些中间件会负责 binlog 的解析,并同步到消息中间件中,我们只需要消费对应的 Topic 即可。
回到 Flink 上,CDC 似乎和我们没有太大的关联?其实不然,让我们更加抽象地来看这个世界。
当我们用 Flink 去消费数据比如 Kafka 时,我们就仿佛在读一张表,什么表?一张不断有记录被插入的表,我们将每一条被插入的数据取出来,完成我们的逻辑。
当插入的每条数据都没有问题时,一切都很美好。关联、聚合、输出。
但当我们发现,某条已经被计算过的数据有问题时,麻烦大了。我们直接改最后的输出值其实是没有用的,这次改了,当再来数据触发计算时,结果还是会被错误的数据覆盖,因为中间计算结果没有被修改,它仍然是一个错误的值。怎么办?撤回流似乎能解决这个问题,这也确实是解决这个问题的手段,但是问题来了,撤回流怎么确定读取的数据是要被撤回的?另外,怎么去触发一次撤回?
CDC 解决了这些:将消息中间件的数据反序列化后,根据 Type 来识别数据是 Insert 还是 Delete;另外,如果大家看过 Flink 源码,会发现反序列化后的数据类型变了,从 Row 升级为 RowData,RowData 能够将数据标记为撤回还是插入,这就意味着每个算子能够判断出数据到底是需要下发还是撤回。
CDC 的重要性就先说这么多,之后有机会的话,出一篇实时 DQC 的视频,告诉大家 CDC 的出现,对于实时 DQC 的帮助有多大。下面让我们回到正题。
既然有那么多 CDC 同步中间件,那么一定会有各种各样的格式存放在消息中间件中,我们必然需要去解析它们。于是 Flink 1.11 提供了 canal-json 和 debezium-json,但我们用的是 Maxwell 怎么办?只能等官方出或者说是等有人向社区贡献吗?那如果我们用的是自研的同步中间件怎么办?
所以就有了今天的分享:如何去自定义实现一个 Maxwell format。大家也可以基于此文的思路去实现其他 CDC format,比如 OGG, 或是自研 CDC 工具产生的数据格式。
如何实现
当我们提交任务之后,Flink 会通过 SPI 机制将 classpath 下注册的所有工厂类加载进来,包括 DynamicTableFactory、DeserializationFormatFactory 等等。而对于 Format 来说,到底使用哪个 DeserializationFormatFactory,是根据 DDL 语句中的 Format 来决定的。通过将 Format 的值与工厂类的 factoryIdentifier() 方法的返回值进行匹配 来确定。
再通过 DeserializationFormatFactory 中的 createDecodingFormat(...) 方法,将反序列化对象提供给 DynamicTableSource。
通过图来了解整个过程(仅从反序列化数据并消费的角度来看):
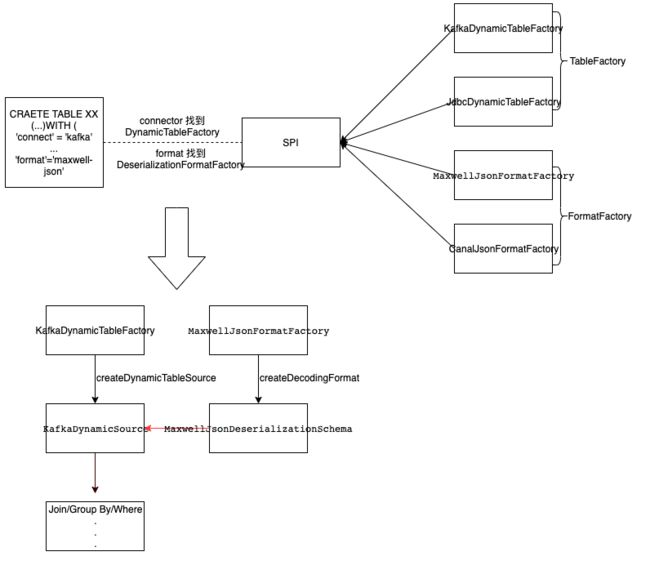
想要实现 CDC Format 去解析某种 CDC 工具产生的数据其实很简单,核心组件其实就三个:
- 工厂类(DeserializationFormatFactory):负责编译时根据 ‘format’ = ‘maxwell-json’创建对应的反序列化器。即 MaxwellJsonFormatFactory。
- 反序列化类(DeserializationSchema):负责运行时的解析,根据固定格式将 CDC 数据转换成 Flink 系统能认识的 INSERT/DELETE/UPDATE 消息,如 RowData。即 MaxwellJsonDeserializationSchema。
- Service 注册文件:需要添加 Service 文件 META-INF/services/org.apache.flink.table.factories.Factory ,并在其中增加一行我们实现的 MaxwellJsonFormatFactory 类路径。
再通过代码,来看看反序列化中的细节:
public void deserialize(byte[] message, Collectorout) throws IOException {
try {
RowData row = jsonDeserializer.deserialize(message);
String type = row.getString(2).toString(); // "type" field
if (OP_INSERT.equals(type)) {
RowData insert = row.getRow(0, fieldCount);
insert.setRowKind(RowKind.INSERT);
out.collect(insert);
} else if (OP_UPDATE.equals(type)) {
GenericRowData after = (GenericRowData) row.getRow(0, fieldCount); // "data" field
GenericRowData before = (GenericRowData) row.getRow(1, fieldCount); // "old" field
for (int f = 0; f < fieldCount; f++) {
if (before.isNullAt(f)) {
before.setField(f, after.getField(f));
}
}
before.setRowKind(RowKind.UPDATE_BEFORE);
after.setRowKind(RowKind.UPDATE_AFTER);
out.collect(before);
out.collect(after);
} else if (OP_DELETE.equals(type)) {
RowData delete = row.getRow(0, fieldCount);
delete.setRowKind(RowKind.DELETE);
out.collect(delete);
} else {
if (!ignoreParseErrors) {
throw new IOException(format(
"Unknown \"type\" value \"%s\". The Maxwell JSON message is '%s'", type, new String(message)));
}
}
} catch (Throwable t) {
if (!ignoreParseErrors) {
throw new IOException(format(
"Corrupt Maxwell JSON message '%s'.", new String(message)), t);
}
}
}其实并不复杂:先通过 jsonDeserializer 将字节数组根据 [data: ROW, old: ROW, type: String] 的 schema 反序列化成 RowData,然后根据 “type” 列的值来判断数据是什么类型:增、改、删;再根据数据类型取出 “data” 或者 “old” 区的数据,来组装成 Flink 认识的 INSERT/DELETE/UPDATE 数据并下发。
对象 jsonDeserializer 即 JSON 格式的反序列化器,它可以通过指定的 RowType 类型,读取 JSON 的字节数组中指定的字段并反序列化成 RowData。在我们的场景中,我们需要去读取如下 Maxwell 数据的 “data”, “old” 和 “type” 部分的数据。
{"database":"test","table":"product","type":"update","ts":1596684928,"xid":7291,"commit":true,"data":{"id":102,"name":"car battery","description":"12V car battery","weight":5.17},"old":{"weight":8.1}}因此 MaxwellJsonDeserializationSchema 中定义的 JSON 的 RowType 如下所示。
private RowType createJsonRowType(DataType databaseSchema) {
// Maxwell JSON contains other information, e.g. "database", "ts"
// but we don't need them
return (RowType) DataTypes.ROW(
DataTypes.FIELD("data", databaseSchema),
DataTypes.FIELD("old", databaseSchema),
DataTypes.FIELD("type", DataTypes.STRING())).getLogicalType();
}databaseSchema 是用户通过 DDL 定义的 schema 信息,也对应着数据库中表的 schema。结合上面的 JSON 和代码,我们能够得知 jsonDeserializer 只会取走 byte[] 中 data、old、type 这三个字段对应的值,其中 data 和old 还是个嵌套JSON,它们的 schema 信息和 databaseSchema 一致。由于 Maxwell 在同步数据时,“old”区不包含未被更新的字段,所以 jsonDeserializer 返回后,我们会通过 “data” 区的 RowData 将 old 区的缺失字段补齐。
得到 RowData 之后,会取出 type 字段,然后根据对应的值,会有三种分支:
- insert:取出 data 中的值,也就是我们通过DDL定义的字段对应的值,再将其标记为 RowKind.INSERT 类型数据,最后下发。
- update:分别取出 data 和 old 的值,然后循环 old 中每个字段,字段值如果为空说明是未修改的字段,那就用 data 中对应位置字段的值替代;之后将 old 标记为 RowKind.UPDATE_BEFORE 也就意味着 Flink 引擎需要将之前对应的值撤回,data 标记为 RowKind.UPDATE_AFTER 正常下发。
- delete:取出 data 中的值,标记为 RowKind.DELETE,代表需要撤回。
处理的过程中,如果抛出异常,会根据 DDL 中maxwell-json.ignore-parse-errors的值来确定是忽视这条数据继续处理下一条数据,还是让任务报错。
笔者在 maxwell-json 反序列化功能的基础之上,还实现了序列化的功能,即能将 Flink 产生的 changelog 以 Maxwell 的 JSON 格式输出到外部系统中。其实现思路与反序列化器的思路正好相反,更多细节可以参考 Pull Request 中的实现。
PR 实现详情链接:
https://github.com/apache/fli...
功能演示
给大家演示一下从 Kafka 中读取 Maxwell 推送来的 maxwell json 格式数据,并将聚合后的数据再次写入 Kafka 后,重新读出来验证数据是否正确。
- Kafka 数据源表
CREATE TABLE topic_products (
-- schema is totally the same to the MySQL "products" table
id BIGINT,
name STRING,
description STRING,
weight DECIMAL(10, 2)
) WITH (
'connector' = 'kafka',
'topic' = 'maxwell',
'properties.bootstrap.servers' = 'localhost:9092',
'properties.group.id' = 'testGroup',
'format' = 'maxwell-json');- Kafka 数据结果表&数据源表
CREATE TABLE topic_sink (
name STRING,
sum_weight DECIMAL(10, 2)
) WITH (
'connector' = 'kafka',
'topic' = 'maxwell-sink',
'properties.bootstrap.servers' = 'localhost:9092',
'properties.group.id' = 'testGroup',
'format' = 'maxwell-json'
);- MySQL 表
-- 注意,这部分 SQL 在 MySQL 中执行,不是 Flink 中的表
CREATE TABLE product (
id INTEGER NOT NULL AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(255),
description VARCHAR(512),
weight FLOAT
);
truncate product ;
ALTER TABLE product AUTO_INCREMENT = 101;
INSERT INTO product
VALUES (default,"scooter","Small 2-wheel scooter",3.14),
(default,"car battery","12V car battery",8.1),
(default,"12-pack drill bits","12-pack of drill bits with sizes ranging from #40 to #3",0.8),
(default,"hammer","12oz carpenter's hammer",0.75),
(default,"hammer","14oz carpenter's hammer",0.875),
(default,"hammer","16oz carpenter's hammer",1.0),
(default,"rocks","box of assorted rocks",5.3),
(default,"jacket","water resistent black wind breaker",0.1),
(default,"spare tire","24 inch spare tire",22.2);
UPDATE product SET description='18oz carpenter hammer' WHERE id=106;
UPDATE product SET weight='5.1' WHERE id=107;
INSERT INTO product VALUES (default,"jacket","water resistent white wind breaker",0.2);
INSERT INTO product VALUES (default,"scooter","Big 2-wheel scooter ",5.18);
UPDATE product SET description='new water resistent white wind breaker', weight='0.5' WHERE id=110;
UPDATE product SET weight='5.17' WHERE id=111;
DELETE FROM product WHERE id=111;
UPDATE product SET weight='5.17' WHERE id=102 or id = 101;
DELETE FROM product WHERE id=102 or id = 103;先看看能不能正常读取 Kafka 中的 maxwell json 数据。
select * from topic_products;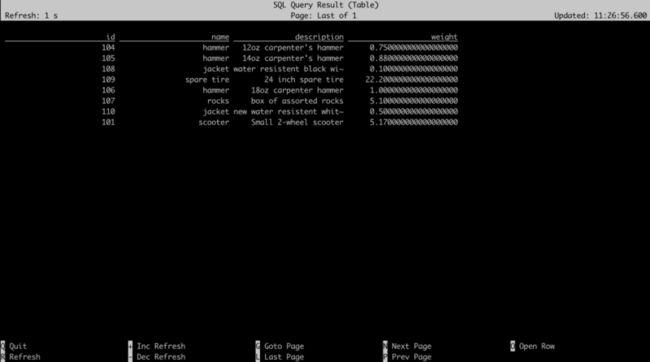
可以看到,所有字段值都变成了 Update 之后的值,同时,被 Delete 的数据也没有出现。
接着让我们再将聚合数据写入 Kafka。
insert into topic_sink select name,sum(weight) as sum_weight from topic_products group by name;在 Flink 集群的 Web 页面也能够看到任务正确提交,接下来再让我们把聚合数据查出来。
select * from topic_sink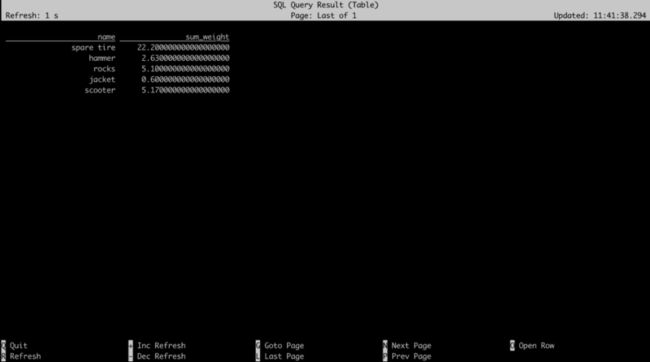
最后,让我们查询一下 MySQL 中的表,来验证数据是否一致;因为在 Flink 中,我们将 weight 字段定义成 Decimal(10,2),所以我们在查询 MySQL 的时候,需要将 weight 字段进行类型转换。
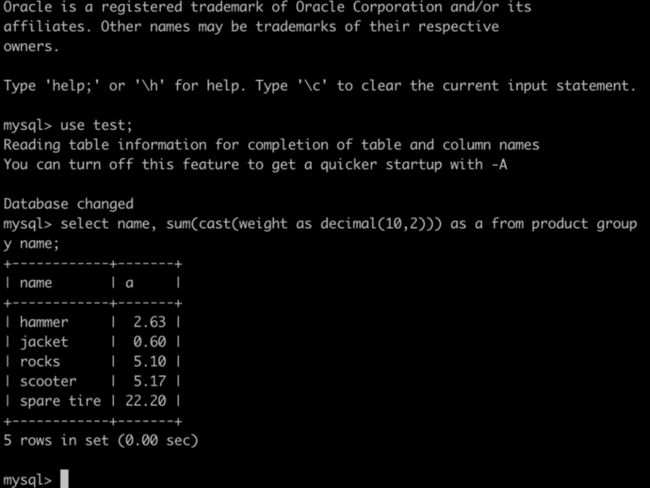
没有问题,我们的 maxwell json 解析很成功。
写在最后
根据笔者实现 maxwell-json format 的经验,Flink 对于接口的定义、对于模块职责的划分还是很清晰的,所以实现一个自定义 CDC format 非常简单(核心代码只有200多行)。因此,如果你是用的 OGG,或是自研的同步中间件,可以通过本文的思路快速实现一个 CDC format,一起解放你的 CDC 数据!
参考链接:
[1]https://github.com/alibaba/canal
[2]https://debezium.io/
[3]https://maxwells-daemon.io/