根据我的经验,大多数人(使用Helm或手动yaml)将应用程序部署到Kubernetes上,然后认为他们就可以一直稳定运行。
然而并非如此,实际使用过程还是遇到了一些“陷阱”,我希望在此处列出这些“陷阱”,以帮助您了解在Kubernetes上启动应用程序之前需要注意的一些问题。
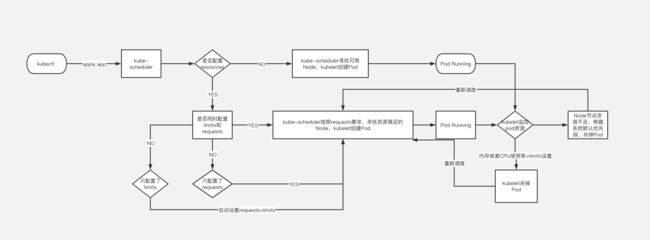
Kubernetes调度简介
调度器通过 kubernetes 的 watch 机制来发现集群中新创建且尚未被调度到 Node 上的 Pod。调度器会将发现的每一个未调度的 Pod 调度到一个合适的 Node 上来运行。kube-scheduler作为集群的默认调度器,对每一个新创建的 Pod 或者是未被调度的 Pod,kube-scheduler会选择一个最优的 Node 去运行这个 Pod。然而,Pod 内的每一个容器对资源都有不同的需求,而且 Pod 本身也有不同的资源需求。因此,Pod 在被调度到 Node 上之前,根据这些特定的资源调度需求,需要对集群中的 Node 进行一次过滤。
在一个集群中,满足一个 Pod 调度请求的所有 Node 称之为 可调度节点。如果没有任何一个 Node 能满足 Pod 的资源请求,那么这个 Pod 将一直停留在未调度状态直到调度器能够找到合适的 Node。
在做调度决定时需要考虑的因素包括:单独和整体的资源请求、硬件/软件/策略限制、亲和以及反亲和要求、数据局域性、负载间的干扰等等。关于调度更多信息请官网自行查阅
Pod Requests and Limits
来看个简单例子,这里只截取yaml部分信息
apiVersion: v1
kind: Pod
metadata:
name: nginx
spec:
containers:
- name: nginx-demo
image: nginx
resources:
limits:
memory: "100Mi"
cpu: 100m
requests:
memory: "1000Mi"
cpu: 100m默认情况下,咱们创建服务部署文件,如果不写resources字段,Kubernetes集群会使用默认策略,不对Pod做任何资源限制,这就意味着Pod可以随意使用Node节点的内存和CPU资源。但是这样就会引发一个问题:资源争抢。
例如:一个Node节点有8G内存,有两个Pod在其上运行。
刚开始运行,两个Pod都只需要2G内存就足够运行,这时候都没有问题,但是如果其中一个Pod因为内存泄漏或者流程突然增加到导致内存用到了7G,这时候Node的8G内存显然就不够用了。这就会导致服务服务极慢或者不可用。
所以,一般情况下,我们再部署服务时,需要对pod的资源进行限制,以避免发生类似的问题。
如示例文件所示,需要加上resources;
requests: 表示运行服务所需要的最少资源,本例为需要内存100Mi,CPU 100m
limits: 表示服务能使用的最大资源,本例最大资源限制在内存1000Mi,CPU 100m什么意思呢?一图胜千言吧。
Liveness and Readiness Probes
Kubernetes社区中经常讨论的另一个热点话题。 掌握Liveness和Readiness探针非常重要,因为它们提供了一种运行容错软件并最大程度减少停机时间的机制。 但是,如果配置不正确,它们可能会对您的应用程序造成严重的性能影响。 以下是这两个探测的概要以及如何推理它们:
Liveness Probe:探测容器是否正在运行。 如果活动性探针失败,则kubelet将杀死Container,并且Container将接受其重新启动策略。 如果“容器”不提供活动性探针,则默认状态为“成功”。
因为Liveness探针运行频率比较高,设置尽可能简单,比如:将其设置为每秒运行一次,那么每秒将增加1个请求的额外流量,因此需要考虑该请求所需的额外资源。通常,我们会为Liveness提供一个健康检查接口,该接口返回响应代码200表明您的进程已启动并且可以处理请求。
Readiness Probe:探测容器是否准备好处理请求。 如果准备就绪探针失败,则Endpoint将从与Pod匹配的所有服务的端点中删除Pod的IP地址。
Readiness探针的检查要求比较高,因为它表明整个应用程序正在运行并准备好接收请求。对于某些应用程序,只有从数据库返回记录后,才会接受请求。 通过使用经过深思熟虑的准备情况探针,我们能够实现更高水平的可用性以及零停机部署。
Liveness and Readiness Probes检测方法一致,有三种
- 定义存活命令:
如果命令执行成功,返回值为零,Kubernetes 则认为本次探测成功;如果命令返回值非零,本次 Liveness 探测失败。 - 定义一个存活态 HTTP 请求接口;
发送一个HTTP请求,返回任何大于或等于 200 并且小于 400 的返回代码表示成功,其它返回代码都标示失败。 - 定义 TCP 的存活探测
向执行端口发送一个tcpSocket请求,如果能够连接表示成功,否则失败。
来看个例子,这里以常用的 TCP存活探测为例
apiVersion: v1
kind: Pod
metadata:
name: nginx
spec:
containers:
- name: nginx-demo
image: nginx
livenessProbe:
tcpSocket:
port: 80
initialDelaySeconds: 10
periodSeconds: 10
readinessProbe:
tcpSocket:
port: 80
initialDelaySeconds: 10
periodSeconds: 10livenessProbe 部分定义如何执行 Liveness 探测:
1. 探测的方法是:通过tcpSocket连接nginx的80端口。如果执行成功,返回值为零,Kubernetes 则认为本次 Liveness 探测成功;如果命令返回值非零,本次 Liveness 探测失败。
2. initialDelaySeconds: 10 指定容器启动 10 之后开始执行 Liveness 探测,一般会根据应用启动的准备时间来设置。比如应用正常启动要花 30 秒,那么 initialDelaySeconds 的值就应该大于 30。
3. periodSeconds: 10 指定每 10 秒执行一次 Liveness 探测。Kubernetes 如果连续执行 3 次 Liveness 探测均失败,则会杀掉并重启容器。
readinessProbe 探测一样,但是 readiness 的 READY 状态会经历了如下变化:
1. 刚被创建时,READY 状态为不可用。
2. 20 秒后(initialDelaySeconds + periodSeconds),第一次进行 Readiness 探测并成功返回,设置 READY 为可用。
3. 如果Kubernetes连续 3 次 Readiness 探测均失败后,READY 被设置为不可用。为Pod设置默认的网络策略
Kubernetes使用一种“扁平”的网络拓扑,默认情况下,所有Pod都可以直接相互通信。 但是在某些情况下我们不希望这样,甚至是不必要的。 会存在一些潜在的安全隐患,例如一个易受的应用程序被利用,则可以为者提供完全访问权限,以将流量发送到网络上的所有pod。 像在许多安全领域中一样,最小访问策略也适用于此,理想情况下,将创建网络策略以明确指定允许哪些容器到容器的连接。
举例,以下是一个简单的策略,该策略将拒绝特定名称空间的所有入口流量
---
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: deny-ingress-flow
spec:
podSelector: {}
policyTypes:
- Ingress此配置的示意图
通过Hooks和init容器的自定义行为
我们使用Kubernetes系统的主要目标之一就是尝试为现成的开发人员提供尽可能零停机的部署。 由于应用程序关闭自身和清理已利用资源的方式多种多样,因此这很困难。 我们遇到特别困难的一个应用是Nginx。 我们注意到,当我们启动这些Pod的滚动部署时,活动连接在成功终止之前被丢弃。 经过广泛的在线研究,事实证明,Kubernetes并没有等待Nginx在终止Pod之前耗尽其连接。 使用停止前挂钩,我们能够注入此功能,并通过此更改实现了零停机时间。
通常情况下,比如我们要对Nginx进行滚动升级,但是Kubernetes在停止Pod之前并不会等待Nginx终止连接。这就会导致被停掉的nginx并没有正确关闭所有连接,这样是不合理的。所以我们需要在停止钱使用钩子,以解决这样的问题。
我们可以在部署文件添加lifecycle
lifecycle:
preStop:
exec:
command: ["/usr/local/bin/nginx-killer.sh"]nginx-killer.sh
#!/bin/bash
sleep 3
PID=$(cat /run/nginx.pid)
nginx -s quit
while [ -d /proc/$PID ]; do
echo "Waiting while shutting down nginx..."
sleep 10
done这样,Kubernetes在关闭Pod之前,会执行nginx-killer.sh脚本,以我们定义的方式关闭nginx
另外一种情况就是使用init容器
Init Container就是用来做初始化工作的容器,可以是一个或者多个,如果有多个的话,这些容器会按定义的顺序依次执行,只有所有的Init Container执行完后,主容器才会被启动
例如:
initContainers:
- name: init
image: busybox
command: ["chmod","777","-R","/var/www/html"]
imagePullPolicy: Always
volumeMounts:
- name: volume
mountPath: /var/www/html
containers:
- name: nginx-demo
image: nginx
ports:
- containerPort: 80
name: port
volumeMounts:
- name: volume
mountPath: /var/www/html我们给nginx的/var/www/html挂载了一块数据盘,在主容器运行前,我们把/var/www/html权限改成777,以便主容器使用时不会存在权限问题。
当然这里只是一个小栗子,Init Container更多强大的功能,比如初始化配置等。。。
Kernel Tuning(内核参数优化)
最后,将更先进的技术留给最后,哈哈
Kubernetes是一个非常灵活的平台,旨在让你以自己认为合适的方式运行服务。通常如果我们有高性能的服务,对资源要求比较严苛,比如常见的redis,启动以后会有如下提示
WARNING: The TCP backlog setting of 511 cannot be enforced because /proc/sys/net/core/somaxconn is set to the lower value of 128.这就需要我们修改系统的内核参数了。好在Kubernetes允许我们运行一个特权容器,该容器可以修改仅适用于特定运行Pod的内核参数。 以下是我们用来修改/proc/sys/net/core/somaxconn参数的示例。
initContainers:
- name: sysctl
image: alpine:3.10
securityContext:
privileged: true
command: ['sh', '-c', "echo 511 > /proc/sys/net/core/somaxconn"]总结
尽管Kubernetes提供了一种开箱即用的解决方案,但是也需要你采取一些关键的步骤来确保程序的稳定运行。在程序上线前,务必进行多次测试,观察关键指标,并实时进行调整。
在我们将服务部署到Kubernetes集群前,我们可以问自己几个问题:
- 我们的程序需要多少资源,例如内存,CPU等?
- 服务的平均流量是多少,高峰流量是多少?
- 我们希望服务多长时间进行扩张,需要多长时间新的Pod可以接受流量?
- 我们的Pod是正常的停止了吗?怎么做不影响线上服务?
- 怎么保证我们的服务出问题不会影响其他服务,不会造成大规模的服务宕机?
- 我们的权限是否过大?安全吗?
终于写完了,呜呜呜~真滴好难呀~