摘要:本文对anchor-free的目标检测RepPoints系列算法进行梳理,具体包含RepPoints, RepPoints V2, Dense RepPoints。
背景介绍
近两年来,anchor-free作为目标检测算法的新思路,已经得到越来越多的关注。在典型anchor-based的算法中,模型的效果往往受限于anchor的配置参数,如anchor大小、正负样本采样、anchor的宽高比等,要求开发者要十分了解数据,才能配置好anchor参数,从而训练得到一个好的模型。anchor-free的算法无需配置anchor参数,即可训练得到一个好的检测模型,减少了训练前对数据复杂的分析过程。
anchor-free 算法又可分为基于anchor-point的算法和基于key-point的算法。anchor-point算法本质上和anchor-based算法相似,通过预测目标中心点(x,y)及边框距中心点的距离(w,h)来检测目标,典型的此类算法有FSAF,FCOS等;而key-point方法是通过检测目标的边界点(如:角点),再将边界点配对组合成目标的检测框,此类算法包括CornerNet, RepPoints等。本文将介绍RepPoints系列算法工作。
RepPoints是ICCV2019的一篇文章,新颖地提出使用点集的方式来表示目标,该方法在不使用anchor的基础上取得了非常好的效果。如图1所示,a)表示一般目标检测算法使用水平包围框来表示目标位置信息,b)则表示了RepPoints使用点集来表示目标位置的方法。RepPoints系列工作其实就是以点集表示为核心,从不同的角度去进一步提升该算法精度而做出改进:1)将验证(即分割)的过程融入RepPoints,进一步提升结果,得到RepPoints V2; 2) 将点集的监督方式进行改进,病扩充点集的点数,实现了目标实力分割任务的统一范式,即Dense RepPoints.

RepPoints
RepPoints算法的框架如图2 所示。总体上,该方法是基于全卷积网络实现的,但是不同于其他的one-stage方法(e.g. RetinaNet)使用一次回归和一次分类得到最终的目标位置,RepPoints使用了两次回归和一次分类,并且分类和最后一次回归使用的不是普通卷积,而是可形变卷积。可形变卷积的偏移量是通过第一次回归得到,也就意味着偏移量在训练过程中是有监督的。采用这种方式,后续的分类和回归特征均是沿着目标选取的,特征质量更高。
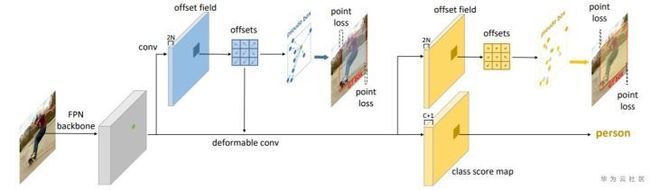
图2 RepPoints框架图
RepPoints的结果如表1 所示,在单阶段方法中表现很好,并且借助多尺度训练和多尺度测试能够进一步提升精度,远超先前的two-stage方法。
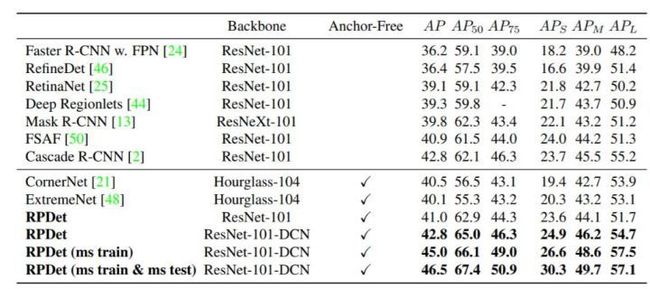
表1 RepPoint与SOTA算法对比
RepPoints V2
验证(即分割)和回归是神经网络两类通用的任务,有着各自的优势:验证更容易学习并且准确,回归通常很高效并且能预测连续变化。因此,采用一定的方式将两者组合起来能充分利用它们的优势。RepPoints V2就是在RepPoints的基础上增加了验证模块,实现了性能的进一步提升。本文的工作有一定的可拓展性,在基于回归的方法上都可以加上这个模块以提升结果。

表2. 基于验证和回归的几种方法性能对比
表2为在COCO Val上几种方法的结果分析,可见有验证分支的方法在AP90上的指标较高,表明其检测结果的准确度更高。
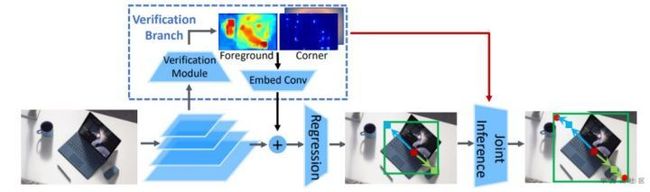
图3 RepPoints V2流程图
RepPoints V2在RepPoints方法基础上添加了一个分割分支,该分割主要包含两部分,一部分是角点预测的分割,另一部分是目标前景的分割。如图3所示,得到分割图后,一方面这个分割图和原始特征相加,作为回归特征的补充;另一方面在推理阶段,在回归分支获取到目标位置后,利用该分割图可对结果进行进一步修正。总的来说,这个任务的添加可从三个层面对结果进行提升:多任务一般会直接提升总体结果;利用分割图增强特征提升回归效果,推理过程回归结果和分割结果进行综合也有提升。作者用实验证明了这三个方面的提升,如表3所示。
表3. Ablation Study
Dense RepPoints
Dense RepPoints在RepPoints的基础上,将任务从目标检测扩充到实例分割,使用了更密集的点来表示目标,从而达到实例分割的目标。
RepPoints是一种针对目标检测的表示方法,只采用9个点来表示目标,
这些点只包含了位置信息,无法表示物体更精细的结构,难以应用于实例分割任务。相比于RepPoints, Dense RepPoints使用更多的点表示物体,并增加了每个点的属性信息:
![]()
在刻画细粒度的物体几何定位时,有多重表示方式,见图4。其中,基于轮廓的方法(图4 b)对物体的表达更紧凑,需要更多的信息,且由于更关注对物体边缘的分割,有望德大更精确的边缘。而基于网格掩码的方式(图4 c)通过对网格点做前景/背景分类的方式实现物体分割,更易于学习。基于这两种表达的有点,Dense RepPoints采用图4d的边缘掩码方式来表示物体。和轮廓表示类似,边缘掩码表示将点集主要放在物体边缘附近,从而可以更精细地表示物体边缘;另一方面,和网格掩码表示类似,这一方法采用了代表点前景/背景分类的方法来实现物体分割,更利于学习。
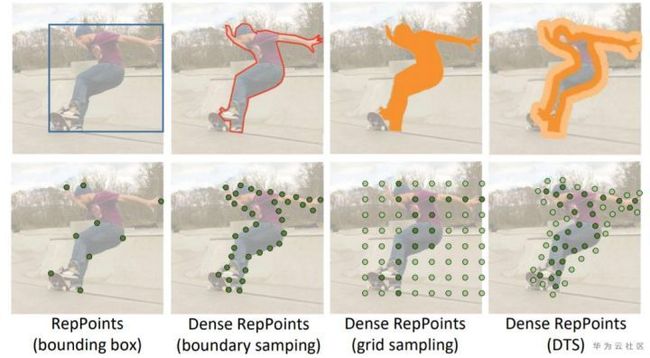
图4. 不同边界表达和采样方式
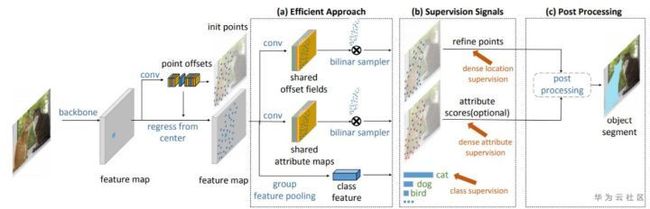
图5. Dense RepPoints框架
RepPoints对目标的表示采用一个点集R来表示,
对于分类和二次回归的特征便是通过上述点集采样(deformable conv)获取,得到F(R),将点数进行提升,F(R)的深度将直线增加。在RepPoint初始版本中,采样点数为9尚可用于目标检测。为了准确描述不规则目标时,往往需要上百个点,
Dense RepPoints使用了更密集的点集表示物体,也增加了所需的计算量,影响实现效率。Dense RepPoints采用三种技术来解决计算量增加的问题:Group pooling; Shared offset fields; shared attribute map.
Group Pooling如图6所示,主要解决分类过程中的复杂度。如果实验中采用n点来描述目标,那么将其分成k组,对每组进行池化操作,然后进行预测,最终分类部分的复杂度有O(n)降低到O(k)。
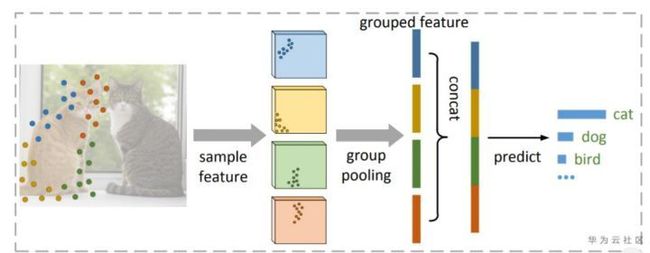
图6. Group Pooling
RepPoints对物体轮廓点的偏移量进行修正时(图2),是先基于初始预测的N个轮廓点,通过N个Deformable Conv 算子分别对每个轮廓点进行修正预测,所需复杂度为O(n^2)。该方法对于预测密集点的Dense RepPoints算法而言,在推理效率上就不适用了。Dense RepPoint提出Shared offset fields方法,认为对每个轮廓点的偏移修正特征只需从原始预测的轮廓点信息,即每个轮廓点各自进行独立的修正,从而将复杂度降低到O(n)。具体如图7所示,对每个轮廓点通过bilinear线性插值方法提取特征进行轮廓点修正。
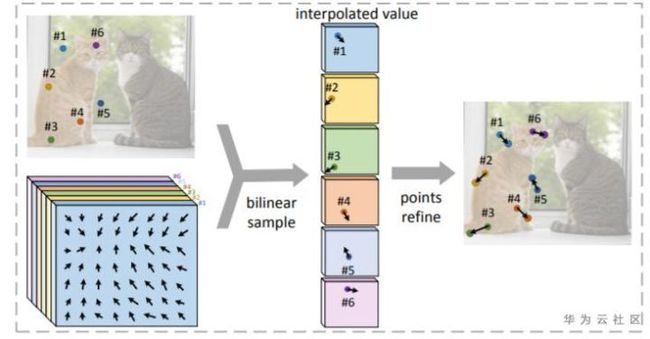
图7. Shared offset fields
对于Shared Attribute Map,如图8所示。由于要进行分割,需要对前景进行打分。打分的过程根据点的位置分成上下左右四个区域,将不同的区域分配到不同的通道上。推理过程中,为了获取某个点的得分,首先根据点在目标中的相对位置找到对应的通道,而后对该通道的得分进行采样即可得到该点的得分。
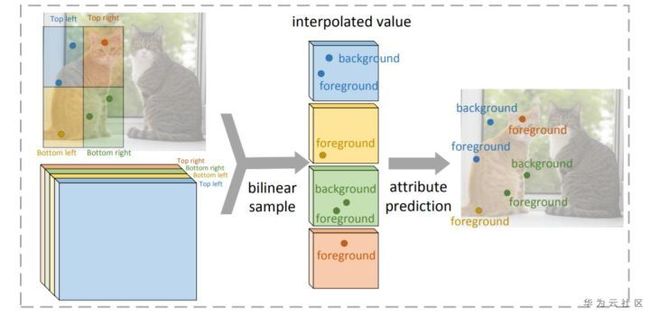
图8. Shared Attribute Map
作者通过对比试验验证了这些操作的有效性,在增加点数时基本不增加计算量,并且有效提升了结果。
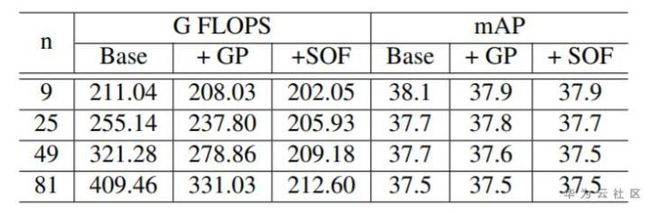
表3. Ablation Study.GP表示Group Pooling, SOF表示shared offset fields.
除了通过一系列的操作将计算量进行降低,Dense RepPoints论文还探索了点的不同分布方式和损失函数的计算方式对结果带来的影响。对于点集的分布,依距离对目标边缘进行采样在实例分割任务中拥有最好的性能。对于损失函数,计算点集与点集之间的损失值要优于点对点的损失值。
小结
以点集(RepPoints)这种方式来表示目标能在精度和计算量上取得非常好的平衡,并且后处理简单。在使用点集的基础上,在部分任务上,还可以引入V2中的验证分支,来实现更精细的检测,同样也可参考Dense RepPoints,将Deformable Conv换成更加通用的点采样来实现,让模型更具拓展能力和表达能力。