高性能的Mysql读书笔记系列之六(查询性能优化)
前言:
即使设计了最优的库表结构、建立了最好的索引,如果没有的合理的查询sql,也是无法实现高性能的。所以除了对索引优化、库表结构优化,查询优化也是需要齐头并进的。
正文:
一、为什么查询速度会变慢
在尝试编写快速的查询之前,需要清楚一点,真正重要是响应时间。如果把查询看作是一个任务,那么它由一系列子任务组成,每个子任务都会消耗一定的时间。如果要优化查询,实际上要优化其子任务,要么消除其中一些子任务,要么减少子任务的执行次数,要么让子任务运行得更快。
MySQL在执行查询的时候有哪些子任务,哪些子任务运行的速度很慢?通常来说,查询的生命周期大致可以按照顺序来看:从客户端,到服务器,然后在服务器上进行解析,生成执行计划,执行,并返回结果给客户端。其中“执行”可以认为是整个生命周期中最重要的阶段,这其中包括了大量为了检索数据到存储引擎的调用以及调用后的数据处理,包括排序、分组等。
在完成这些任务的时候,查询需要在不同的地方花费时间,包括网络,CPU计算,生成统计信息和执行计划、锁等待(互斥等待)等操作,尤其是向底层存储引擎检索数据的调用操作,这些调用需要在内存操作、CPU操作和内存不足时导致的I/O操作上消耗时间。根据存储引擎不同,可能还会产生大量的上下文切换以及系统调用。
在每一个消耗大量时间的查询案例中,我们都能看到一些不必要的额外操作、某些操作被额外地重复了很多次、某些操作执行得太慢等。优化查询的目的就是减少和消除这些操作所花费的时间。
再次申明一点,对于一个查询的全部生命周期,上面列的并不完整。这里我们只是想说明:了解查询的生命周期、清楚查询的时间消耗情况对于优化查询有很大的意义。有了这些概念,我们再一起来看看如何优化查询。
二、MySQL执行一个查询的过程是怎么样的?MySQL到底做了什么?
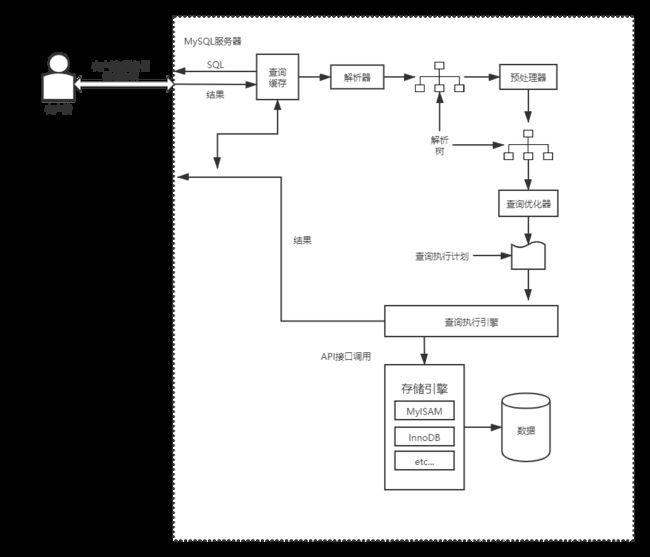 查询执行路径
查询执行路径
1.客户端发送一条查询给服务器。
2.服务器先检查查询缓存,如果命中了缓存,则立刻返回存储在缓存中的结果。否则进入下一阶段。
3.服务器端进行SQL解析、预处理,再由优化器生成对应的执行计划。
4.MySQl根据优化器生成的执行计划,调用存储引擎的API来执行查询。
5.将结果返回给客户端。
三、优化查询可以从三个角度出发
1.优化数据访问
①是否向数据库请求了不需要的数据
查询不需要的记录
一个常见的错误是常常会误以为MySQL会只返回需要的数据,实际上MySQL却是先返回全部结果集再进行计算。我们经常会看到一些了解其他数据库系统的人会设计出这类应用程序。这些开发者习惯使用这样的技术,先使用SELECT语句查询大量的结果,然后获取前面的N行后关闭结果集(例如在新闻网站中取出100条记录,但是只是在页面上显示前面10条)。他们认为MySQL会执行查询,并只返回他们需要的10条数据,然后停止查询。实际情况是MySQL会查询出全部的结果集,客户端的应用程序会接收全部的结果集数据,然后抛弃其中大部分数据。最简单有效的解决方法就是在这样的查询后面加上LIMIT。
多表关联时返回全部列
如果你想查询所有在电影Academy Dinosaur中出现的演员,千万不要按下面的写法编写查询:
mysql> SELECT * FROM sakila.actor
-> INNER JOIN sakila.film_actor USING(actor_id)
-> INNER JOIN sakila.film USING(film_id)
-> WHERE sakila.film.title = 'Academy Dinosaur';
这将返回这三个表的全部数据列。正确的方式应该是像下面这样只取需要的列:
mysql> SELECT sakila.actor.* FROM sakila.actor...;
总是取出全部列
每次看到SELECT *的时候都需要用怀疑的眼光审视,是不是真的需要返回全部的列?很可能不是必需的。取出全部列,会让优化器无法完成索引覆盖扫描这类优化,还会为服务器带来额外的I/O、内存和CPU的消耗。因此,一些DBA是严格禁止SELECT *的写法的,这样做有时候还能避免某些列被修改带来的问题。
当然,查询返回超过需要的数据也不总是坏事。在我们研究过的许多案例中,人们会告诉我们说这种有点浪费数据库资源的方式可以简化开发,因为能提高相同代码片段的复用性,如果清楚这样做的性能影响,那么这种做法也是值得考虑的。如果应用程序使用了某种缓存机制,或者有其他考虑,获取超过需要的数据也可能有其好处,但不要忘记这样做的代价是什么。获取并缓存所有的列的查询,相比多个独立的只获取部分列的查询可能就更有好处。
重复查询相同的数据
如果你不太小心,很容易出现这样的错误——不断地重复执行相同的查询,然后每次都返回完全相同的数据。例如,在用户评论的地方需要查询用户头像的URL,那么用户多次评论的时候,可能就会反复查询这个数据。比较好的方案是,当初次查询的时候将这个数据缓存起来,需要的时候从缓存中取出,这样性能显然会更好。
②MySQL是否在扫描额外的记录
在确定查询只返回需要的数据以后,接下来应该看看查询为了返回结果是否扫描了过多的数据。对于MySQL,最简单的衡量查询开销的三个指标如下:
- 响应时间
- 扫描的行数
- 返回的行数
在EXPLAIN语句中的type列反应了访问的类型。访问类型有很多种,从全表扫描到索引扫描、范围扫描、唯一索引查询、常数引用等。这里列的这些,速度是从慢到快,扫描的行数也是小到大。你不需要记住这些访问类型,但是要明白扫描表,扫描索引,范围访问和单值访问的概念。如果查询没有办法找到合适的访问类型,那么最好的办法通常就是增加一个合适的索引。
一般MySQL能够使用如下三种应用WHERE条件,从好到坏依次为:
- 在索引中使用WHERE条件来过滤不匹配的记录。这是在存储引擎层完成的。
- 使用索引覆盖扫描来返回记录,直接从索引中过滤不需要的记录并返回命中的结果。这是在MySQL服务器层完成的,但无须在回表查询记录。
- 从数据表中返回数据,然后过滤不满足条件的记录。这是在MySQL服务器层完成,MySQL需要先从数据表读出记录然后过滤。
如果说发现查询需要扫描大量的数据但只返回少数的行,那么通常可以尝试下面的技巧去优化它:
- 使用索引覆盖扫描,把所有需要用到的列都放到索引中,这样存储引擎无须回表获取对应行就可以返回结果
- 改变库表结构。例如使用单独的汇总表
- 重写这个复杂的查询,让MySQL优化器能够以更优化的方式执行这个查询
2.重构查询方式
①切分查询
有时候对于一个大查询我们需要“分而治之”,将大查询切分成小查询,每个查询功能完全一样,只完成一小部分,每次只返回一小部分查询结果。
删除旧的数据就是一个很好的例子。定期地清除大量数据时,如果用一个大的语句一次性完成的话,则可能需要一次锁住很多数据、占满整个事务日志、耗尽系统资源、阻塞很多小的但重要的查询。将一个大的DELETE语句切分成多个较小的查询可以尽可能小地影响MySQL性能,同时还可以减少MySQL复制的延迟。例如,我们需要每个月运行一次下面的查询:
mysql> DELETE FROM messages WHERE created < DATE_SUB(NOW(),INTERVAL 3 MONTH);
那么可以用类似下面的办法来完成同样的工作:
rows_affected = 0
do {
rows_affected = do_query(
"DELETE FROM messages WHERE created < DATE_SUB(NOW(),INTERVAL 3 MONTH)
LIMIT 10000")
} while rows_affected > 0
一次删除一万行数据一般来说是一个比较高效而且对服务器(5)影响也最小的做法(如果是事务型引擎,很多时候小事务能够更高效)。同时,需要注意的是,如果每次删除数据后,都暂停一会儿再做下一次删除,这样也可以将服务器上原本一次性的压力分散到一个很长的时间段中,就可以大大降低对服务器的影响,还可以大大减少删除时锁的持有时间。
②分解关联查询
很多高性能的应用都会对关联查询进行分解。简单地,可以对每一个表进行一次单表查询,然后将结果在应用程序中进行关联。例如,下面这个查询:
mysql> SELECT * FROM tag
-> JOIN tag_post ON tag_post.tag_id=tag.id
-> JOIN post ON tag_post.post_id=post.id
-> WHERE tag.tag='mysql';
可以分解成下面这些查询来代替:
mysql> SELECT * FROM tag_post WHERE tag_id=1';
mysql> SELECT * FROM tag_post WHERE tag_id=1234;
mysql> SELECT * FROM post WHERE post.id in (123,456,567,9098,8904);
到底为什么要这样做?乍一看,这样做并没有什么好处,原本一条查询,这里却变成多条查询,返回的结果又是一模一样的。事实上,用分解关联查询的方式重构查询有如下的优势:
- 让缓存的效率更高。许多应用程序可以方便地缓存单表查询对应的结果对象。例如,上面查询中的tag已经被缓存了,那么应用就可以跳过第一个查询。再例如,应用中已经缓存了ID为123、567、9098的内容,那么第三个查询的IN()中就可以少几个ID。另外,对MySQL的查询缓存来说,如果关联中的某个表发生了变化,那么就无法使用查询缓存了,而拆分后,如果某个表很少改变,那么基于该表的查询就可以重复利用查询缓存结果了。
- 将查询分解后,执行单个查询可以减少锁的竞争。
- 在应用层做关联,可以更容易对数据库进行拆分,更容易做到高性能和可扩展。
- 查询本身效率也可能会有所提升。这个例子中,使用IN()代替关联查询,可以让MySQL按照ID顺序进行查询,这可能比随机的关联要更高效。
- 可以减少冗余记录的查询。在应用层做关联查询,意味着对于某条记录应用只需要查询一次,而在数据库中做关联查询,则可能需要重复地访问一部分数据。从这点看,这样的重构还可能会减少网络和内存的消耗。
- 更进一步,这样做相当于在应用中实现了哈希关联,而不是使用MySQL的嵌套循环关联。某些场景哈希关联的效率要高很多。
- 在很多场景下,通过重构查询将关联放到应用程序中将会更加高效,这样的场景有很多,比如:当应用能够方便地缓存单个查询的结果的时候、当可以将数据分布到不同的MySQL服务器上的时候、当能够使用IN()的方式代替关联查询的时候、当查询中使用同一个数据表的时候。
3.查看mysql的查询优化器对sql的优化,从而优化sql
很多时候我们写的sql,和被查询优化器优化后的sql的执行顺序是不一致的,所以当我们遇到sql效率很低下的时候,我们可以试着使用EXPLAIN EXTENDED来查看这个查询被改写成了什么样子。当然在mysql8.0的版本这个命令是会报错的,只需要先执行
explain,然后可以通过mysql的show warnings命令得到。
比如下面的例子就是没有按照我们预想执行的:
MySQL的子查询实现得非常糟糕。最糟糕的一类查询是WHERE条件中包含IN()的子查询语句。例如,我们希望找到Sakila数据库中,演员Penelope Guiness(他的actor_id为1)参演过的所有影片信息。很自然的,我们会按照下面的方式用子查询实现:
mysql> SELECT * FROM sakila.film
-> WHERE film_id IN(
-> SELECT film_id FROM sakila.film_actor WHERE actor_id = 1);
因为MySQL对IN()列表中的选项有专门的优化策略,一般会认为MySQL会先执行子查询返回所有包含actor_id为1的film_id。一般来说,IN()列表查询速度很快,所以我们会认为上面的查询会这样执行:
-- SELECT * FROM sakila.film-- SELECT GROUP_CONCAT(film_id) FROM sakila.film_actor WHERE actor_id = 1;
-- Result: 1,23,25,106,140,166,277,361,438,499,506,509,605,635,749,832,939,970,980
SELECT * FROM sakila.film
WHERE film_id
IN(1,23,25,106,140,166,277,361,438,499,506,509,605,635,749,832,939,970,980);
很不幸,MySQL不是这样做的。MySQL会将相关的外层表压到子查询中,它认为这样可以更高效率地查找到数据行。也就是说,MySQL会将查询改写成下面的样子:
SELECT * FROM sakila.film
WHERE EXISTS (
SELECT * FROM sakila.film_actor WHERE actor_id = 1
AND film_actor.film_id = film.film_id);
这时,子查询需要根据film_id来关联外部表film,因为需要film_id字段,所以MySQL认为无法先执行这个子查询。通过EXPLAIN我们可以看到子查询是一个相关子查询(DEPENDENT SUBQUERY)(可以使用EXPLAIN EXTENDED来查看这个查询被改写成了什么样子):
根据EXPLAIN的输出我们可以看到,MySQL先选择对file表进行全表扫描,然后根据返回的flm_id逐个执行子查询。如果是一个很小的表,这个查询糟糕的性能可能还不会引起注意,但是如果外层的表是一个非常大的表,那么这个查询的性能会非常糟糕。当然我们很容易用下面的办法来重写这个查询:
mysql> SELECT film.* FROM sakila.film
-> INNER JOIN sakila.film_actor USING(film_id)
-> WHERE actor_id = 1;
另一个优化的办法是使用函数GROUP_CONCAT()在IN()中构造一个由逗号分隔的列表。有时这比上面的使用关联改写更快。因为使用IN()加子查询,性能经常会非常糟,所以通常建议使用EXISTS()等效的改写查询来获取更好的效率。
总结:
mysql的查询优化是一个需要长期实践和总结的过程,不是几天就可以速成的,所以大家一家要把自己每次优化sql的经验都形成自己的笔记和心得,长期下来就会越来越得心应手。
我是阿达,一名喜欢分享知识的程序员,时不时的也会荒腔走板的聊一聊电影、电视剧、音乐、漫画,这里已经有12300位小伙伴在等你们啦,感兴趣的就赶紧来点击关注我把,哪里有不明白或有不同观点的地方欢迎留言!